資訊專欄INFORMATION COLUMN

摘要:近日,來自華盛頓大學的和提出的版本。而那些評分較高的區域就可以視為檢測結果。此外,相對于其它目標檢測方法,我們使用了完全不同的方法。從圖中可以看出準確率高,速度也快。對于的圖像,可以達到的檢測速度,獲得的性能,與的準確率相當但是速度快倍。
近日,來自華盛頓大學的 Joseph Redmon 和 Ali Farhadi 提出 YOLO 的版本 YOLOv3。通過在 YOLO 中加入設計細節的變化,這個新模型在取得相當準確率的情況下實現了檢測速度的很大提升,一般它比 R-CNN 快 1000 倍、比 Fast R-CNN 快 100 倍。
代碼地址:https://pjreddie.com/yolo/.
1. 引言
有時,你一整年全在敷衍了事而不自知。比如今年我就沒做太多研究,在推特上揮霍光陰,置 GANs 于不顧。憑著上年余留的一點動力,我成功對 YOLO 做了一些升級。但實話講,沒什么超有趣的東西,只不過是些小修小補。同時我對其他人的研究也盡了少許綿薄之力。
于是就有了今天的這篇論文。我們有一個最終截稿日期,需要隨機引用 YOLO 的一些更新,但是沒有資源。因此請留意技術報告。
技術報告的優勢在于其不需要介紹,你自然知道來由。因此簡介的最后將為余文提供路標。首先我將介紹 YOLOv3 的結局方案;接著是其實現。我們也會介紹一些失敗案例。最后是本文的總結與思考。
2. 解決方案
這一部分主要介紹了 YOLOv3 的解決方案,我們從其他研究員那邊獲取了非常多的靈感。我們還訓練了一個非常優秀的分類網絡,因此原文章的這一部分主要從邊界框的預測、類別預測和特征抽取等方面詳細介紹整個系統。
簡而言之,YOLOv3 的先驗檢測(Prior detection)系統將分類器或定位器重新用于執行檢測任務。他們將模型應用于圖像的多個位置和尺度。而那些評分較高的區域就可以視為檢測結果。
此外,相對于其它目標檢測方法,我們使用了完全不同的方法。我們將一個單神經網絡應用于整張圖像,該網絡將圖像劃分為不同的區域,因而預測每一塊區域的邊界框和概率,這些邊界框會通過預測的概率加權。
我們的模型相比于基于分類器的系統有一些優勢。它在測試時會查看整個圖像,所以它的預測利用了圖像中的全局信息。與需要數千張單一目標圖像的 R-CNN 不同,它通過單一網絡評估進行預測。這令 YOLOv3 非常快,一般它比 R-CNN 快 1000 倍、比 Fast R-CNN 快 100 倍。
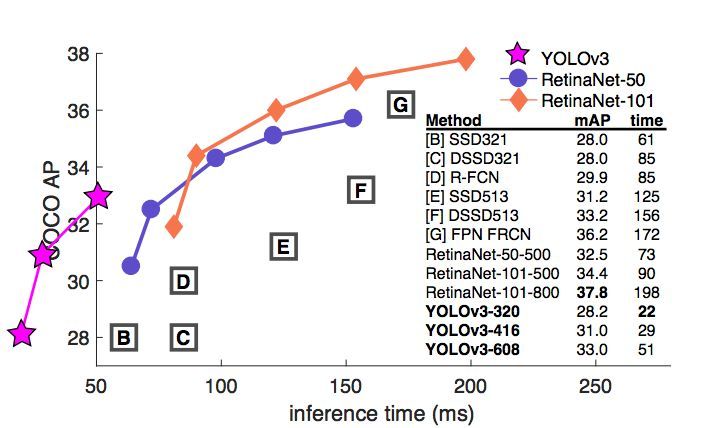
圖 1:我們從 Focal Loss 論文 [7] 中采用了這張圖。YOLOv3 在實現相同準確度下要顯著地比其它檢測方法快。時間都是在采用 M40 或 Titan X 等相同 GPU 下測量的。

圖 2:帶有維度先驗和定位預測的邊界框。我們邊界框的寬和高以作為離聚類中心的位移,并使用 Sigmoid 函數預測邊界框相對于濾波器應用位置的中心坐標。
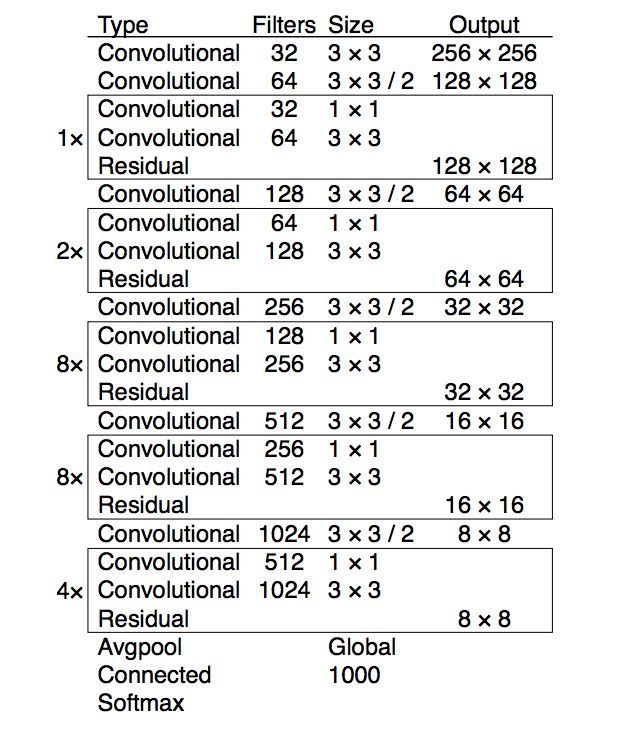
表 1:Darknet-53 網絡架構。
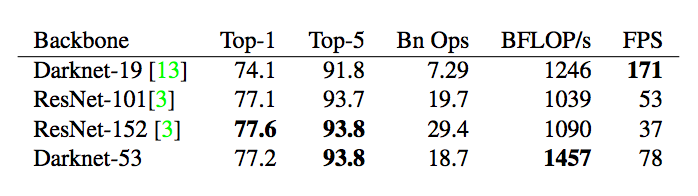
表 2:主干架構的性能對比:準確率(top-1 誤差、top-5 誤差)、運算次數(/十億)、每秒浮點數運算次數(/十億),以及 FPS 值。
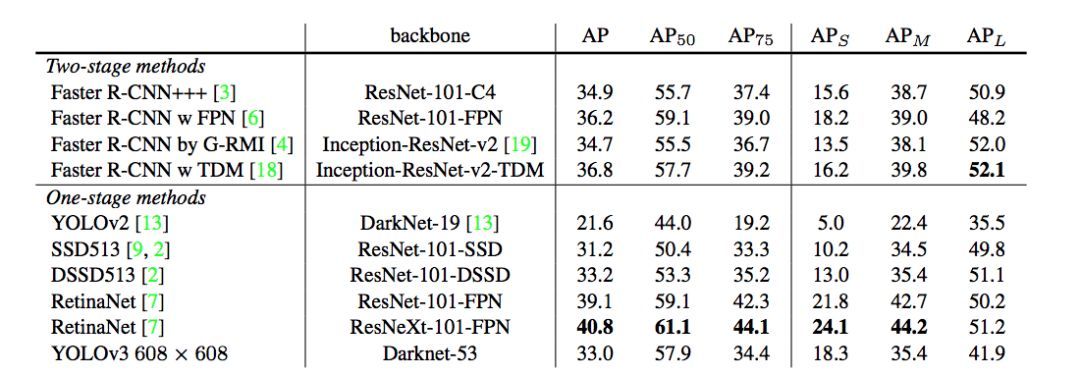
表 3:該表來自 [7]。從中看出,YOLOv3 表現得不錯。RetinaNet 需要大約 3.8 倍的時間來處理一張圖像,YOLOv3 相比 SSD 變體要好得多,并在 AP_50 指標上和當前較佳模型有得一拼。

圖 3:也是借用了 [7] 中的圖,展示了以.5 IOU 指標的速度/準確率權衡過程(mAP vs 推斷時間)。從圖中可以看出 YOLOv3 準確率高,速度也快。
最后,機器之心也嘗試使用預訓練的 YOLOv3 執行目標檢測,在推斷中,模型需要花 1s 左右加載模型與權重,而后面的預測與圖像本身的像素大小有非常大的關系。因此,吃瓜小編真的感覺 YOLOv3 很快哦。
論文:YOLOv3: An Incremental Improvement

論文鏈接:https://pjreddie.com/media/files/papers/YOLOv3.pdf
摘要:我們在本文中提出 YOLO 的版本 YOLOv3。我們對 YOLO 加入了許多設計細節的變化,以提升其性能。這個新模型相對更大但準確率更高。不用擔心,它依然非常快。對于 320x320 的圖像,YOLOv3 可以達到 22ms 的檢測速度,獲得 28.2mAP 的性能,與 SSD 的準確率相當但是速度快 3 倍。當我們使用舊版.5 IOU mAP 檢測指標時,YOLOv3 是非常不錯的。它在一塊 TitanX 上以 51ms 的速度達到了 57.9 AP_50 的性能,而用 RetinaNet 則以 198ms 的速度獲得 57.5 AP_50 的性能,性能相近但快了 3 倍。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4751.html
摘要:基于候選區域的目標檢測器滑動窗口檢測器自從獲得挑戰賽冠軍后,用進行分類成為主流。一種用于目標檢測的暴力方法是從左到右從上到下滑動窗口,利用分類識別目標。這些錨點是精心挑選的,因此它們是多樣的,且覆蓋具有不同比例和寬高比的現實目標。 目標檢測是很多計算機視覺任務的基礎,不論我們需要實現圖像與文字的交互還是需要識別精細類別,它都提供了可靠的信息。本文對目標檢測進行了整體回顧,第一部分從RCNN...
摘要:我們可以通過在特征圖上滑動窗口來檢測目標。以前的滑動窗口方法的致命錯誤在于使用窗口作為最終的邊界框,這就需要非常多的形狀來覆蓋大部分目標。更有效的方法是將窗口當做初始猜想,這樣我們就得到了從當前滑動窗口同時預測類別和邊界框的檢測器。 單次檢測器Faster R-CNN 中,在分類器之后有一個專用的候選區域網絡。Faster R-CNN 工作流基于區域的檢測器是很準確的,但需要付出代價。Fas...
摘要:摘要本文介紹使用和完成視頻流目標檢測,代碼解釋詳細,附源碼,上手快。將應用于視頻流對象檢測首先打開文件并插入以下代碼同樣,首先從導入相關數據包和命令行參數開始。 摘要:?本文介紹使用opencv和yolo完成視頻流目標檢測,代碼解釋詳細,附源碼,上手快。 在上一節內容中,介紹了如何將YOLO應用于圖像目標檢測中,那么在學會檢測單張圖像后,我們也可以利用YOLO算法實現視頻流中的目標檢...
摘要:表示類別為,坐標是的預測熱點圖,表示相應位置的,論文提出變體表示檢測目標的損失函數由于下采樣,模型生成的熱點圖相比輸入圖像分辨率低。模型訓練損失函數使同一目標的頂點進行分組,損失函數用于分離不同目標的頂點。 本文由極市博客原創,作者陳泰紅。 1.目標檢測算法概述 CornerNet(https://arxiv.org/abs/1808.01244)是密歇根大學Hei Law等人在發表E...
摘要:來自原作者,快如閃電,可稱目標檢測之光。實現教程去年月就出現了,實現一直零零星星。這份實現,支持用自己的數據訓練模型。現在可以跑腳本了來自原作者拿自己的數據集訓練快速訓練這個就是給大家一個粗略的感受,感受的訓練過程到底是怎樣的。 來自YOLOv3原作者YOLOv3,快如閃電,可稱目標檢測之光。PyTorch實現教程去年4月就出現了,TensorFlow實現一直零零星星。現在,有位熱心公益的程...

閱讀 3094·2021-08-03 14:05
閱讀 2140·2019-08-29 15:35
閱讀 678·2019-08-29 13:30
閱讀 3168·2019-08-29 13:20
閱讀 2530·2019-08-23 18:15
閱讀 1796·2019-08-23 14:57
閱讀 2213·2019-08-23 13:57
閱讀 1309·2019-08-23 12:10






