資訊專欄INFORMATION COLUMN

摘要:在這篇文章中我們嘗試了用分類類圖像。實際上我們將每張訓練集中的圖像認為成一類。我們采用了一個簡單的方法在最后分類前,讓文本和圖像使用一個,那么在過程中會用一個軟的約束,這就完成了詳見論文。類似圖像的操作吧。
Motivation
在這篇文章中我們嘗試了 用CNN分類113,287類圖像(MSCOCO)。
實際上我們將每張訓練集中的圖像認為成一類。(當然, 如果只用一張圖像一類,CNN肯定會過擬合)。同時,我們利用了5句圖像描述(文本),加入了訓練。所以每一類相當于 有6個樣本 (1張圖像+5句描述)。
文章想解決的問題是instance-level的retrieval,也就是說 如果你在5000張圖的image pool中,要找“一個穿藍色衣服的金發女郎在打車。” 實際上你只有一個正確答案。不像class-level 或category-level的 要找“女性“可能有很多個正確答案。所以這個問題更細粒度,也更需要detail的視覺和文本特征。

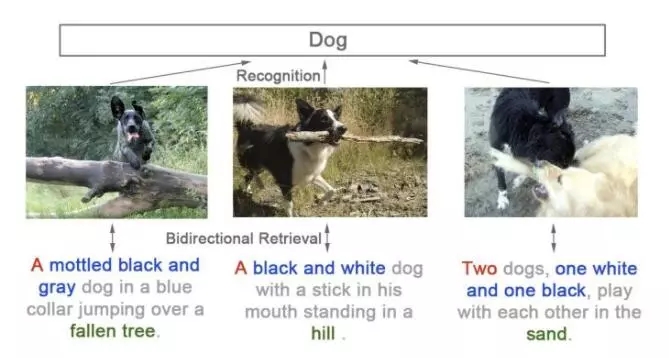
同時我們又觀察到好多之前的工作都直接使用 class-level的 ImageNet pretrained 網絡。但這些網絡實際上損失了信息(數量/顏色/位置)。以下三張圖在imagenet中可能都會使用Dog的標簽,而事實上我們可以用自然語言給出更精準的描述。也就是我們這篇論文所要解決的問題(instance-level的圖文互搜)。
Method
1.對于自然語言描述,我們采用了相對不那么常用的CNN 結構,而不是LSTM結構。來并行訓練,finetune整個網絡。結構如圖。結構其實很簡單。
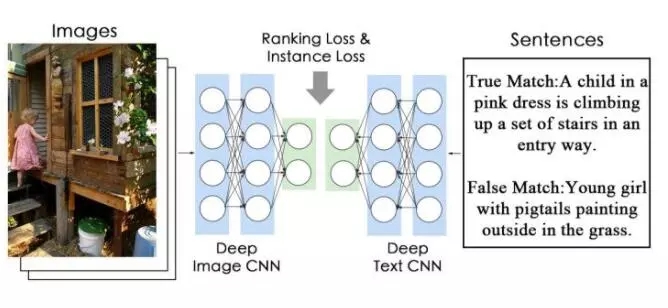
對于TextCNN,我們是用了類似ResNet的block。注意到句子是一維的,在實際使用中,我們用的是 1X2的conv。

2. Instance loss。我們注意到,最終的目的是讓每一個圖像都有區分(discriminative)的特征,自然語言描述也是。所以,為什么不嘗試把每一張圖像看成一類呢。(注意這個假設是無監督的,不需要任何標注。)
這種少樣本的分類其實在之前做行人重識別就常用,但行人重識別(1467類,每類9.6張圖像,有人為ID的標注。)沒有像我們這么極端。
Flickr30k:31,783類 (1圖像+5描述), 其中訓練圖像為 29,783類
MSCOCO:123,287類 (1圖像 + ~5描述), 其中訓練圖像為 113,287類

注意到 Flickr30k中其實有挺多挺像的狗的圖像。不過我們仍舊將他們處理為不同的類,希望也能學到細粒度的差別。(而對于CUHK-PEDES,因為同一個人的描述都差不多。我們用的是同一個人看作一個類,所以每一類訓練圖片多一些。CUHK-PEDES用了ID annotation,而MSCOCO和Flickr30k我們是沒有用的。)
3. 如何結合 文本和圖像一起訓練?
其實,文本和圖像很容易各學各的,來做分類。所以我們需要一個限制,讓他們映射到同一個高層語義空間。
我們采用了一個簡單的方法:在最后分類fc前,讓文本和圖像使用一個W,那么在update過程中會用一個軟的約束,這就完成了(詳見論文 4.2)。 在實驗中我們發現光用這個W軟約束,結果就很好了。(見論文中StageI的結果)
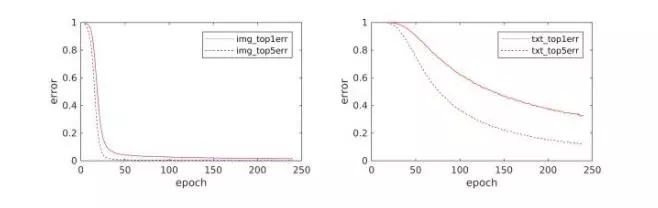
4.訓練收斂么?
收斂的。歡迎大家看代碼。就是直接softmax loss,沒有trick。
圖像分類收斂的快一些。文本慢一些。在Flickr30k上,ImageCNN收斂的快,
TextCNN是重新開始學的,同時是5個訓練樣本,所以相對慢一些。
5. instance loss 是無監督的么?
instance loss的假設是無監督的,因為我們沒有用到額外的信息 (類別標注等等)。而是用了 “每張圖就是一類” 這種信息。
6. 使用其他無監督方法,比如kmeans 先聚類,能不能達到類似instance loss的結果?我們嘗試使用預訓練ResNet50提取pool5特征,分別聚了3000和10000個類。(聚類很慢,雖然開了多線程,聚10000個類花了1個多小時,當中還怕內存不足,死機。大家請慎重。)

在MSCOCO采用instance loss的結果更好一些。我們認為聚類其實沒有解決,黑狗/灰狗/兩條狗都是 狗,可能會忽略圖像細節的問題。
7. 比結果的時候比較難。因為大家的網絡都不太相同(不公平),甚至train/test劃分也不同(很多之前的論文都不注明,直接拿來比)。所以在做表格的時候,我們盡量將所有方法都列了出來。注明不同split。
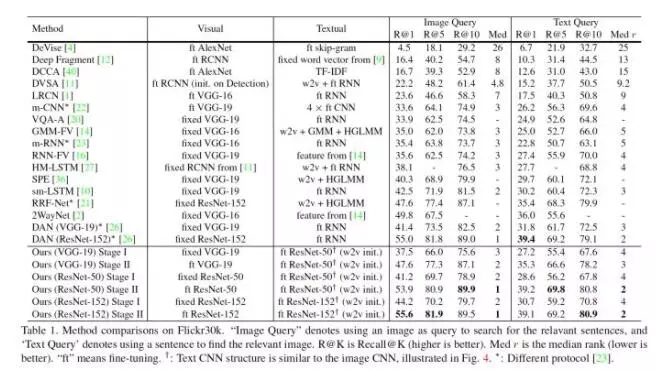
盡量VGG-19 和 VGG-19來比, ResNet-152 和ResNet-152比。歡迎大家詳見論文。
和我們這篇論文相關的,很多是魯老師的工作,真的推薦大家去看。
Multimodal convolutional neural networks for matching image and sentence(http://openaccess.thecvf.com/content_iccv_2015/papers/Ma_Multimodal_Convolutional_Neural_ICCV_2015_paper.pdf)
Convolutional Neural Network Architectures for Matching Natural Language Sentences(http://papers.nips.cc/paper/5550-convolutional-neural-network-architectures-for-matching-natural-language-sentences.pdf)
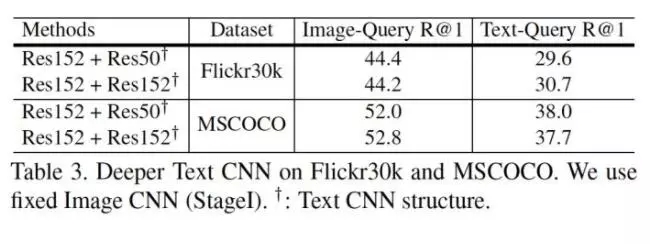
8. 更深的TextCNN一定更好么?
這個問題是Reviewer提出的。
相關論文是 Do Convolutional Networks need to be Deep for Text Classification ?確實,在我們額外的實驗中也發現了這一點。在兩個較大的數據集上,將文本那一路的Res50提升到Res152并沒有顯著提升。
9. 一些trick(在其他任務可能不work)
因為看過bidirectional LSTM一個自然的想法就是 bidirectional CNN,我自己嘗試了,發現不work。插曲:當時在ICML上遇到fb CNN翻譯的poster,問了,他們說,當然可以用啊,只是他們也沒有試之類的。
本文中使用的Position Shift 就是把CNN輸入的文本,隨機前面空幾個位置。類似圖像jitter的操作吧。還是有明顯提升的。詳見論文。
比較靠譜的數據增強 可能是用同義詞替換句子中一些詞。雖然當時下載了libre office的詞庫,但是最后還是沒有用。最后采用的是word2vec來初始化CNN的第一個conv層。某種程度上也含有了近義詞的效果。(相近詞,word vector也相近)
可能數據集中每一類的樣本比較均衡(基本都是1+5個),也是一個我們效果好的原因。不容易過擬合一些“人多”的類。
Results
TextCNN 有沒有學出不同詞,不同的重要程度?(文章附錄)
我們嘗試了從句子中移除一些詞,看移除哪些對匹配score影響較大。

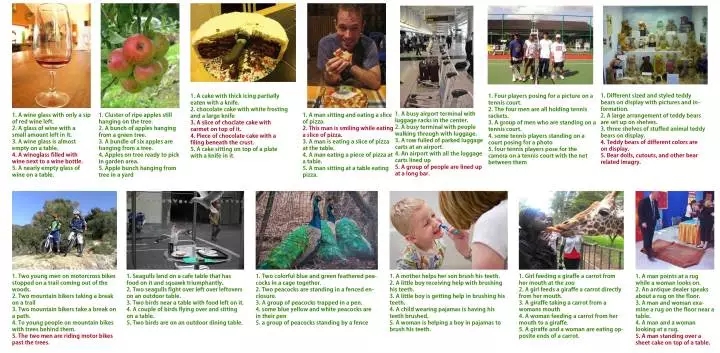
一些圖文互搜結果(文章附錄)

自然語言找行人

細粒度的結果
 歡迎加入本站公開興趣群
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4711.html
摘要:我們在已經準備好的圖像數據集上,使用庫訓練一個卷積神經網絡。示例包含用于測試卷積神經網絡的圖像。訓練,繪制準確性損耗函數,然后將卷積神經網絡和類標簽二進制文件序列化到磁盤。第和行將訓練集和測試集按照的比例進行分割。 showImg(https://segmentfault.com/img/bV9lqk?w=698&h=698); 為了讓文章不那么枯燥,我構建了一個精靈圖鑒數據集(Pok...

閱讀 2381·2021-10-09 09:41
閱讀 3172·2021-09-26 09:46
閱讀 835·2021-09-03 10:34
閱讀 3151·2021-08-11 11:22
閱讀 3364·2019-08-30 14:12
閱讀 711·2019-08-26 11:34
閱讀 3344·2019-08-26 11:00
閱讀 1749·2019-08-26 10:26


