資訊專欄INFORMATION COLUMN

摘要:要理解網絡中的單個特征,比如特定位置的某個神經元或者一整個通道,就可以找讓這個特征產生很高的值的樣本。另一方面,也能看到一些神經元同時對多個沒什么關系的概念產生響應。實際操作經驗中,我們也認為是一組神經元的組合共同表征了一張圖像。
深度神經網絡解釋性不好的問題一直是所有研究人員和商業應用方案上方懸著的一團烏云,現代CNN網絡固然有強大的特征抽取能力,但沒有完善的理論可以描述這個抽取過程的本質,人類也很難理解網絡學到的表征。
當然了,研究人員們從來都不會放棄嘗試。IMCL 2017的較佳論文獎就頒給了 Pang Wei Koh 和 Percy Liang的「Understanding Black-box Predictions via Influence Functions」,探究訓練數據對模型訓練過程的影響;近期引發全面關注的 Geoffery Hinton的膠囊論文也通過多維激活向量帶來了更好的解釋性,不同的維度表征著不同的屬性。
近日,來自谷歌大腦和谷歌研究院的一篇技術文章又從一個新的角度拓展了人類對神經網絡的理解,得到的可視化結果也非常亮眼、非常魔性,比如下面這樣,文中的結果也在Twitter上引發了許多關注和討論。
用優化方法形成可視化
作者們的目標是可視化呈現讓網絡激活的那些特征,也就是回答“模型都在圖像中找什么特征”這個問題。他們的思路是新生成一些會讓網絡激活的圖像,而不是看那些數據集中已有的能讓網絡激活的圖像,因為已有圖像中的特征很可能只是“有相關性”,在分析的時候可能只不過是“人類從許多特征中選出了自己認為重要的”,而下面的優化方法就能真正找到圖像特征和網絡行為中的因果性。
總體來說,神經網絡是關于輸入可微的。如果要找到引發網絡某個行為的輸入,不管這個行為只是單個神經元的激活還是最終的分類器輸出,都可以借助導數迭代地更新輸入,最終確認輸入圖像和選定特征之間的因果關系。(實際執行中當然還有一些技巧,見下文“特征可視化的實現過程”節)

從隨機噪音開始,迭代優化一張圖像讓它激活指定的某一個神經元(以4a層的神經元11為例)
作者們基于帶有 Inception 模塊的 GoogLeNet展開了研究,這是一個2014年的模型 (https://arxiv.org/pdf/1409.4842.pdf ),當年也以6.67%的前5位錯誤率拿下了 ILSVRC 2014圖像分類比賽的冠軍。模型結構示意圖如下;訓練數據集是 ImageNet。
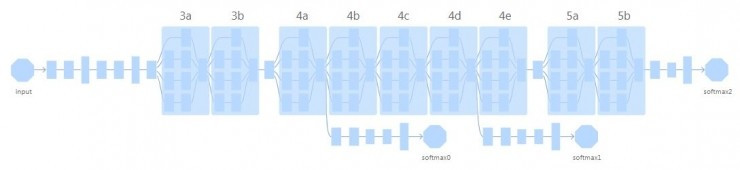
GoogLeNet 結構示意圖。共有9個Inception模塊;3a模塊前有兩組前后連接的卷積層和較大池化層;3b和4a、4e和5a之間各還有一個較大池化層。
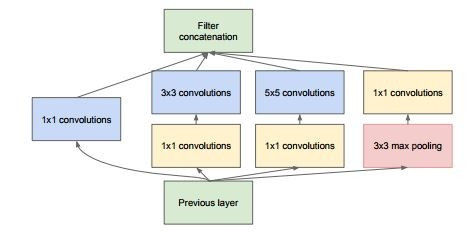
帶有降維的 Inception 模塊(單個模塊)
優化目標
有了思路和網絡之后就要考慮以網絡的哪部分結構作為輸入優化的目標;即便對于在數據集中找樣本的方法也需要考慮這個。這里就有很多種選擇,是單個神經元、某個通道、某一層、softmax前的類別值還是softmax之后的概率。不同的選擇自然會帶來不同的可視化結果,如下圖

以不同的網絡結構為目標可以找到不同的輸入圖像。這里 n 為層序號,x,y 為空間位置, z 為通道序號,k 為類別序號。
要理解網絡中的單個特征,比如特定位置的某個神經元、或者一整個通道,就可以找讓這個特征產生很高的值的樣本。文中多數的圖像都是以通道作為目標生成的。
要理解網絡中的完整一層,就可以用 DeepDream的目標,找到整個層覺得“有興趣”的圖像。
要從分類器的階段出發找到輸入樣本的話,會遇到兩個選擇,優化softmax前的類別值還是優化softmax后的類別概率。softmax前的類別值其實可以看作每個類別出現的證據確鑿程度,softmax后的類別概率就是在給定的證據確鑿程度之上的似然值。不過不幸的是,增大softmax后的某一類類別概率的最簡單的辦法不是讓增加這一類的概率,而是降低別的類的概率。所以根據作者們的實驗,以softmax前的類別值作為優化目標可以帶來更高的圖像質量。
可視化結果一:不同的層優化得到不同的圖像
3a層

第一個Inception層就已經顯示出了一些有意思的紋理。由于每個神經元只有一個很小的感受野,所以整個通道的可視化結果就像是小塊紋理反復拼貼的結果。
3b層

紋理變得復雜了一些,但還都是比較局部的特征
4a層

4a層跟在了一個較大池化層之后,所以可以看到復雜性大幅度增加。圖像中開始出現更復雜的模式,甚至有物體的一部分。
4b層

可以明顯看到物體的某些部分了,檢測臺球的例子中就能清楚看到球的樣子。這時的可視化結果也開始帶有一些環境信息,比如樹的例子中就能看到樹背后的藍天和樹腳下的地面。
4c層

這一層的結果已經足夠復雜了,只看幾個神經元的優化結果可以比看整個通道更有幫助。有一些神經元只關注拴著的小狗,有的只關注輪子,也有很多其它的有意思的神經元。這也是作者們眼中最有收獲的一層。
4d層

這一層中有更復雜的概念,比如第一張圖里的某種動物的口鼻部分。另一方面,也能看到一些神經元同時對多個沒什么關系的概念產生響應。這時需要通過優化結果的多樣性和數據集中的樣本幫助理解神經元的行為。
4e層

在這一層,許多神經元已經可以分辨不同的動物種類,或者對多種不同的概念產生響應。不過它們視覺上還是很相似,就會產生對圓盤天線和墨西哥寬邊帽都產生反應的滑稽情況。這里也能看得到關注紋理的檢測器,不過這時候它們通常對更復雜的紋理感興趣,比如冰激凌、面包和花椰菜。這里的第一個例子對應的神經元正如大家所想的那樣對可以烏龜殼產生反應,不過好玩的是它同樣也會對樂器有反應。
5a層

這里的可視化結果已經很難解釋了,不過它們針對的語義概念都還是比較特定的
5b層

這層的可視化結果基本都是找不到任何規律的拼貼組合。有可能還能認得出某些東西,但基本都需要多樣性的優化結果和數據集中的樣本幫忙。這時候能激活神經元的似乎并不是有什么特定語義含義的結構。
可視化結果二:樣本的多樣性
其實得到可視性結果之后就需要回答一個問題:這些結果就是全部的答案了嗎?由于過程中存在一定的隨機性和激活的多重性,所以即便這些樣本沒什么錯誤,但它們也只展示了特征內涵的某一些方面。
不同激活程度的樣本
在這里,作者們也拿數據集中的真實圖像樣本和生成的樣本做了比較。真實圖像樣本不僅可以展現出哪些樣本可以極高程度地激活神經元,也能在各種變化的輸入中看到神經元分別激活到了哪些程度。如下圖



可以看到,對真實圖像樣本來說,多個不同的樣本都可以有很高的激活程度。
多樣化樣本
作者們也根據相似性損失或者圖像風格轉換的方法產生了多樣化的樣本。如下圖

多樣化的特征可視化結果可以更清晰地看到是哪些結構能夠激活神經元,而且可以和數據集中的照片樣本做對比,確認研究員們的猜想的正確性(這反過來說就是上文中理解每層網絡的優化結果時有時需要依靠多樣化的樣本和數據集中的樣本)。

比如這張圖中,多帶帶看第一排第一張簡單的優化結果,我們很容易會認為神經元激活需要的是“狗頭的頂部”這樣的特征,因為優化結果中只能看到眼睛和向下彎曲的邊緣。在看過第二排的多樣化樣本之后,就會發現有些樣本里沒有包含眼睛,有些里包含的是向上彎曲的邊緣。這樣,我們就需要擴大我們的期待范圍,神經元的激活靠的可能主要是皮毛的紋理。帶著這個結論再去看看數據集中的樣本的話,很大程度上是相符的;可以看到有一張勺子的照片也讓神經元激活了,因為它的紋理和顏色都和狗的皮毛很相似。
對更高級別的神經元來說,多種不同類別的物體都可以激活它,優化得到的結果里也就會包含這各種不同的物體。比如下面的圖里展示的就是能對多種不同的球類都產生響應的情況。

這種簡單的產生多樣化樣本的方法有幾個問題:首先,產生互有區別的樣本的壓力會在圖像中增加無關的瑕疵;而且這個優化過程也會讓樣本之間以不自然的方式產生區別。比如對于上面這張球的可視化結果,我們人類的期待是看到不同的樣本中出現不同種類的球,但實際上更像是在不同的樣本中出現了各有不同的特征。
多樣性方面的研究也揭露了另一個更基礎的問題:上方的結果中展示的都還算是總體上比較相關、比較連續的,也有一些神經元感興趣的特征是一組奇怪的組合。比如下面圖中的情況,這個神經元對兩種動物的面容感興趣,另外還有汽車車身。

類似這樣的例子表明,想要理解神經網絡中的表義過程時,神經元可能不一定是合適的研究對象。
可視化結果三:神經元間的互動
如果神經元不是理解神經網絡的正確方式,那什么才是呢?作者們也嘗試了神經元的組合。實際操作經驗中,我們也認為是一組神經元的組合共同表征了一張圖像。單個神經元就可以看作激活空間中的單個基礎維度,目前也沒發現證據證明它們之間有主次之分。
作者們嘗試了給神經元做加減法,比如把表示“黑白”的神經元加上一個“馬賽克”神經元,優化結果就是同一種馬賽克的黑白版本。這讓人想起了Word2Vec中詞嵌入的語義加減法,或者生成式模型中隱空間的加減法。
聯合優化兩個神經元,可以得到這樣的結果。


也可以在兩個神經元之間取插值,便于更好理解神經元間的互動。這也和生成式模型的隱空間插值相似。


不過這些也僅僅是神經元間互動關系的一點點皮毛。實際上作者們也根本不知道如何在特征空間中選出有意義的方向,甚至都不知道到底有沒有什么方向是帶有具體的含義的。除了找到方向之外,不同反向之間如何互動也還存在疑問,比如剛才的差值圖展示出了寥寥幾個神經元之間的互動關系,但實際情況是往往有數百個神經元、數百個方向之間互相影響。
特征可視化的實現過程
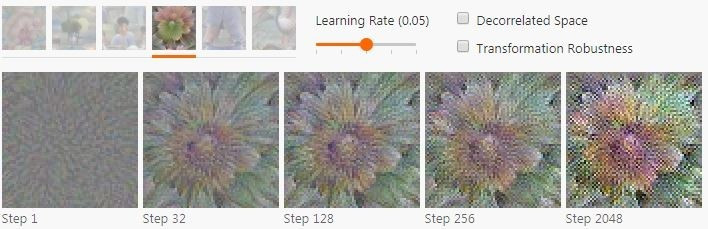
如前文所說,作者們此次使用的優化方法的思路很簡單,但想要真的產生符合人類觀察習慣的圖像就需要很多的技巧和嘗試了。直接對圖像進行優化可能會產生一種神經網絡的光學幻覺 —— 人眼看來是一副全是噪聲、帶有看不出意義的高頻圖樣的圖像,但網絡卻會有強烈的響應。即便仔細調整學習率,還是會得到明顯的噪聲。(下圖學習率0.05)

這些圖樣就像是作弊圖形,用現實生活中不存在的方式激活了神經元。如果優化的步驟足夠多,最終得到的東西是神經元確實有響應,但人眼看來全都是高頻圖樣的圖像。這種圖樣似乎和對抗性樣本的現象之間有緊密的關系。
作者們也不清楚這些高頻圖樣的具體產生原因,他們猜想可能和帶有步幅的卷積和較大池化操作有關系,兩者都可以在梯度中產生高頻率的圖樣。

通過反向傳播過程作者們發現,每次帶有步幅的卷積或者較大池化都會在梯度維度中產生棋盤般的圖樣
這些高頻圖樣說明,雖然基于優化方法的可視化方法不再受限于真實樣本,有著極高的自由性,它卻也是一把雙刃劍。如果不對圖像做任何限制,最后得到的就是對抗性樣本。這個現象確實很有意思,但是作者們為了達到可視化的目標,就需要想辦法克服這個現象。
不同規范化方案的對比
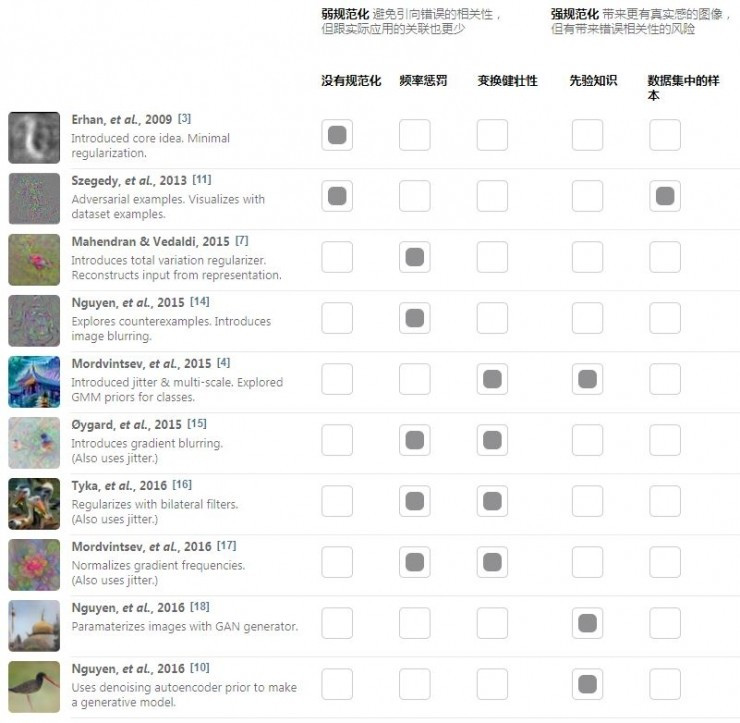
在特征可視化的研究中,高頻噪音一直以來都是主要的難點和重點攻關方向。如果想要得到有用的可視化結果,就需要通過某些先驗知識、規范化或者添加限制來產生更自然的圖像結構。
實際上,如果看看特征可視化方面最著名的論文,它們最主要的觀點之一通常都是使用某種規范化方法。不同的研究者們嘗試了許多不同的方法。
文章作者們根據對模型的規范化強度把所有這些方法看作一個連續的分布。在分布的一端,是完全不做規范化,得到的結果就是對抗性樣本;在另一端則是在現有數據集中做搜索,那么會出現的問題在開頭也就講過了。在兩者之間就有主要的三大類規范化方法可供選擇。
頻率懲罰直接針對的就是高頻噪音。它可以顯式地懲罰相鄰像素間出現的高變化,或者在每步圖像優化之后增加模糊,隱式地懲罰了高頻噪音。然而不幸的是,這些方法同時也會限制合理的高頻特征,比如噪音周圍的邊緣。如果增加一個雙邊過濾器,把邊緣保留下來的話可以得到一些改善。如下圖。

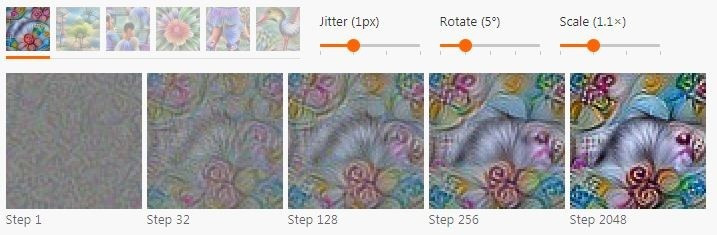
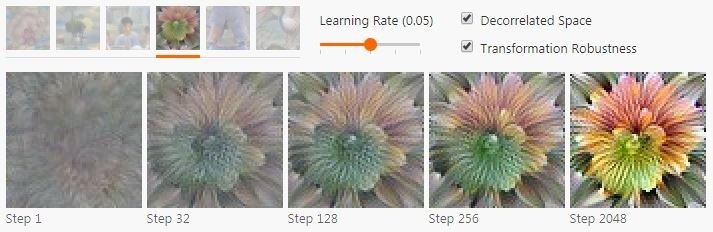
變換健壯性會嘗試尋找那些經過小的變換以后仍然能讓優化目標激活的樣本。對于圖像的例子來說,細微的一點點變化都可以起到明顯的作用,尤其是配合使用一個更通用的高頻規范器之后。具體來說,這就代表著可以隨機對圖像做抖動、宣傳或者縮放,然后把它應用到優化步驟中。如下圖。
先驗知識。作者們一開始使用的規范化方法都只用到了非常簡單的啟發式方法來保持樣本的合理性。更自然的做法是從真實數據學出一個模型,讓這個模型迫使生成的樣本變得合理。如果有一個強力的模型,得到的效果就會跟搜索整個數據集類似。這種方法可以得到最真實的可視化結果,但是就很難判斷結果中的哪些部分來自研究的模型本身的可視化,哪些部分來自后來學到的模型中的先驗知識。
有一類做法大家都很熟悉了,就是學習一個生成器,讓它的輸出位于現有數據樣本的隱空間中,然后在這個隱空間中做優化。比如GAN或者VAE。也有個替代方案是學習一種先驗知識,通過它控制概率梯度;這樣就可以讓先驗知識和優化目標共同優化。為先驗知識和類別的可能性做優化是,就同步形成了一個限制在這個特定類別數據下的生成式模型。
預處理與參數化
前面介紹的幾種方法都降低了梯度中的高頻成分,而不是直接去除可視化效果中的高頻;它們仍然允許高頻梯度形成,只不過隨后去減弱它。
有沒有辦法不讓梯度產生高頻呢?這里就有一個強大的梯度變換工具:優化中的“預處理”。可以把它看作同一個優化目標的最速下降法,但是要在這個空間的另一個參數化形式下進行,或者在另一種距離下進行。這會改變最快速的那個下降方向,以及改變每個方向中的優化速度有多快,但它并不會改變最小值。如果有許多局部極小值,它還可以拉伸、縮小它們的范圍大小,改變優化過程會掉入哪些、不掉入哪些。
最終的結果就是,如果用了正確的預處理方法,就可以讓優化問題大大簡化。
那么帶有這些好處的預處理器如何選擇呢?首先很容易想到的就是讓數據去相關以及白化的方法。對圖像來說,這就意味著以Fourier變換做梯度下降,同時要縮放頻率的大小這樣它們可以都具有同樣的能量。
不同的距離衡量方法也會改變最速下降的方向。L2范數梯度就和L∞度量或者去相關空間下的方向很不一樣。
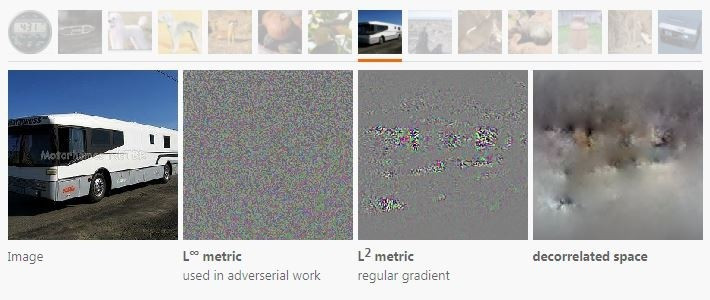
所有這些方向都是同一個優化目標下的可選下降方向,但是視覺上看來它們的區別非常大。可以看到在去相關空間中做優化能夠減少高頻成分的出現,用L∞則會增加高頻。
選用去相關的下降方向帶來的可視化結果也很不一樣。由于超參數的不同很難做客觀的比較,但是得到的結果看起來要好很多,而且形成得也要快得多。這篇文章中的多數圖片就都是用去相關空間的下降和變換健壯性方法一起生成的(除特殊標明的外)。

那么,是不是不同的方法其實都能下降到同一個點上,是不是只不過正常的梯度下降慢一點、預處理方法僅僅加速了這個下降過程呢?還是說預處理方法其實也規范化(改變)了最終達到的局部極小值點?目前還很難說得清。一方面,梯度下降似乎能一直讓優化過程進行下去,只要增加優化過程的步數 —— 它往往并沒有真的收斂,只是在非常非常慢地移動。另一方面,如果關掉所有其它的規范化方法的話,預處理方法似乎也確實能減少高頻圖案的出現。
結論
文章作者們提出了一種新的方法創造令人眼前一亮的可視化結果,在呈現了豐富的可視化結果同時,也討論了其中的重大難點和如何嘗試解決它們。
在嘗試提高神經網絡可解釋性的漫漫旅途中,特征可視化是最有潛力、得到了最多研究的方向之一。不過多帶帶來看,特征可視化也永遠都無法帶來完全讓人滿意的解釋。作者們把它看作這個方向的基礎研究之一,雖然現在還有許多未能解釋的問題,但我們也共同希望在未來更多工具的幫助下,人們能夠真正地理解深度學習系統。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4675.html
摘要:從到,計算機視覺領域和卷積神經網絡每一次發展,都伴隨著代表性架構取得歷史性的成績。在這篇文章中,我們將總結計算機視覺和卷積神經網絡領域的重要進展,重點介紹過去年發表的重要論文并討論它們為什么重要。這個表現不用說震驚了整個計算機視覺界。 從AlexNet到ResNet,計算機視覺領域和卷積神經網絡(CNN)每一次發展,都伴隨著代表性架構取得歷史性的成績。作者回顧計算機視覺和CNN過去5年,總結...

閱讀 1890·2021-11-24 09:39
閱讀 2535·2021-10-14 09:43
閱讀 3318·2021-10-08 10:10
閱讀 2266·2021-09-22 15:54
閱讀 2339·2019-08-29 17:20
閱讀 1573·2019-08-28 18:14
閱讀 2374·2019-08-26 13:28
閱讀 1111·2019-08-26 12:16



