資訊專欄INFORMATION COLUMN

摘要:后來成,就沒有內存錯誤了,但是代碼運行了一晚上都不結束,因此使用貓狗大戰圖片無法復現效果,這里轉發另外一個博客使用復現出的結果,如下圖。圖當然了,在貓狗大戰數據集當中不適合使用,因為一般沒有倒過來的動物。
圖像深度學習任務中,面對小數據集,我們往往需要利用Image Data Augmentation圖像增廣技術來擴充我們的數據集,而keras的內置ImageDataGenerator很好地幫我們實現圖像增廣。但是面對ImageDataGenerator中眾多的參數,每個參數所得到的效果分別是怎樣的呢?本文針對Keras中ImageDataGenerator的各項參數數值的效果進行了詳細解釋,為各位深度學習研究者們提供一個參考。
我們先來看看ImageDataGenerator的官方說明(https://keras.io/preprocessing/image/):
keras.preprocessing.image.ImageDataGenerator(featurewise_center=False,
? ?samplewise_center=False,
? ?featurewise_std_normalization=False,
? ?samplewise_std_normalization=False,
? ?zca_whitening=False,
? ?zca_epsilon=1e-6,
? ?rotation_range=0.,
? ?width_shift_range=0.,
? ?height_shift_range=0.,
? ?shear_range=0.,
? ?zoom_range=0.,
? ?channel_shift_range=0.,
? ?fill_mode="nearest",
? ?cval=0.,
? ?horizontal_flip=False,
? ?vertical_flip=False,
? ?rescale=None,
? ?preprocessing_function=None,
? ?data_format=K.image_data_format())
官方提供的參數解釋因為太長就不貼出來了,大家可以直接點開上面的鏈接看英文原介紹,我們現在就從每一個參數開始看看它會帶來何種效果。
我們測試選用的是kaggle dogs vs cats redux 貓狗大戰的數據集,隨機選取了9張狗狗的照片,這9張均被resize成224×224的尺寸,如圖1:
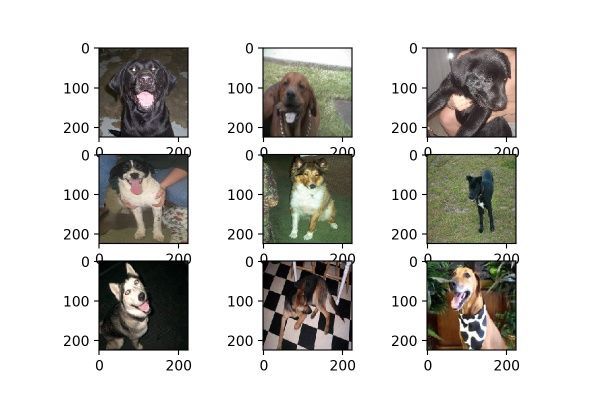
圖1
1. featurewise
datagen = image.ImageDataGenerator(featurewise_center=True,
? ?featurewise_std_normalization=True)
featurewise_center的官方解釋:"Set input mean to 0 over the dataset, feature-wise." 大意為使數據集去中心化(使得其均值為0),而samplewise_std_normalization的官方解釋是“ Divide inputs by std of the dataset, feature-wise.”,大意為將輸入的每個樣本除以其自身的標準差。這兩個參數都是從數據集整體上對每張圖片進行標準化處理,我們看看效果如何:

圖2
與圖1原圖相比,經過處理后的圖片在視覺上稍微“變暗”了一點。
2. samplewise
datagen = image.ImageDataGenerator(samplewise_center=True,
? ?samplewise_std_normalization=True)
samplewise_center的官方解釋為:“ Set each sample mean to 0.”,使輸入數據的每個樣本均值為0;samplewise_std_normalization的官方解釋為:“Divide each input by its std.”,將輸入的每個樣本除以其自身的標準差。這個月featurewise的處理不同,featurewise是從整個數據集的分布去考慮的,而samplewise只是針對自身圖片,效果如圖3:
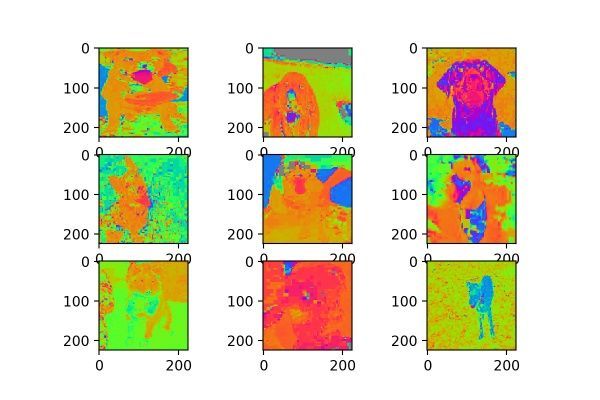
圖3
看來針對自身數據分布的處理在貓狗大戰數據集上沒有什么意義,或許在mnist這類灰度圖上有用?讀者可以試試。
3. zca_whtening
datagen = image.ImageDataGenerator(zca_whitening=True)
zca白化的作用是針對圖片進行PCA降維操作,減少圖片的冗余信息,保留最重要的特征,細節可參看:Whitening transformation--維基百科,Whitening--斯坦福(http://ufldl.stanford.edu/wiki/index.php/Whitening)。
很抱歉的是,本人使用keras的官方演示代碼,并沒有復現出zca_whitening的效果,當我的圖片resize成224×224時,代碼報內存錯誤,應該是在計算SVD的過程中數值太大。后來resize成28×28,就沒有內存錯誤了,但是代碼運行了一晚上都不結束,因此使用貓狗大戰圖片無法復現效果,這里轉發另外一個博客使用mnist復現出的結果,如下圖4。針對mnist的其它DataAugmentation結果可以看這個博客:Image Augmentation for Deep Learning With Keras,有修改意見的朋友歡迎留言。

圖4
4. rotation range
datagen = image.ImageDataGenerator(rotation_range=30)
rotation range的作用是用戶指定旋轉角度范圍,其參數只需指定一個整數即可,但并不是固定以這個角度進行旋轉,而是在 [0, 指定角度] 范圍內進行隨機角度旋轉。效果如圖5:

圖5
5. width_shift_range & height_shift_range
datagen = image.ImageDataGenerator(width_shift_range=0.5,height_shift_range=0.5)
width_shift_range & height_shift_range 分別是水平位置評議和上下位置平移,其參數可以是[0, 1]的浮點數,也可以大于1,其較大平移距離為圖片長或寬的尺寸乘以參數,同樣平移距離并不固定為較大平移距離,平移距離在 [0, 較大平移距離] 區間內。效果如圖6:

圖6
平移圖片的時候一般會出現超出原圖范圍的區域,這部分區域會根據fill_mode的參數來補全,具體參數看下文。當參數設置過大時,會出現圖7的情況,因此盡量不要設置太大的數值。

圖7
6. shear_range
datagen = image.ImageDataGenerator(shear_range=0.5)
shear_range就是錯切變換,效果就是讓所有點的x坐標(或者y坐標)保持不變,而對應的y坐標(或者x坐標)則按比例發生平移,且平移的大小和該點到x軸(或y軸)的垂直距離成正比。
如圖8所示,一個黑色矩形圖案變換為藍色平行四邊形圖案。狗狗圖片變換效果如圖9所示。
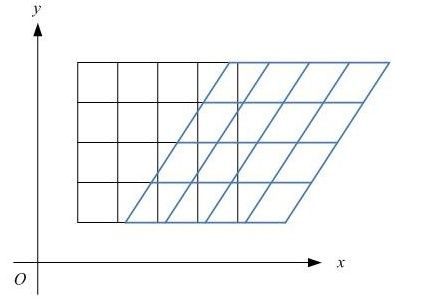
圖8
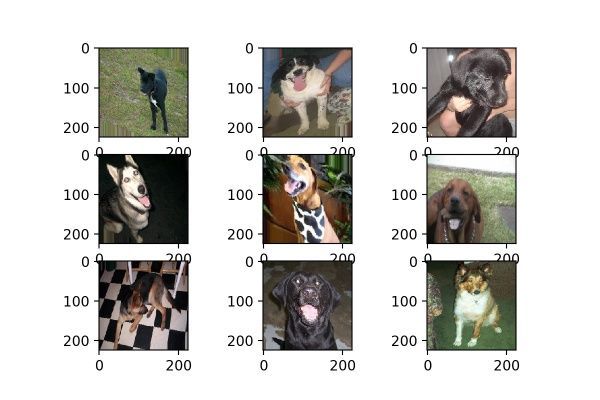
圖9
7. zoom_range
datagen = image.ImageDataGenerator(zoom_range=0.5)
zoom_range參數可以讓圖片在長或寬的方向進行放大,可以理解為某方向的resize,因此這個參數可以是一個數或者是一個list。當給出一個數時,圖片同時在長寬兩個方向進行同等程度的放縮操作;當給出一個list時,則代表[width_zoom_range, height_zoom_range],即分別對長寬進行不同程度的放縮。而參數大于0小于1時,執行的是放大操作,當參數大于1時,執行的是縮小操作。
參數大于0小于1時,效果如圖10:

圖10
參數等于4時,效果如圖11:

圖11
8. channel_shift_range
datagen = image.ImageDataGenerator(channel_shift_range=10)
channel_shift_range可以理解成改變圖片的顏色,通過對顏色通道的數值偏移,改變圖片的整體的顏色,這意味著是“整張圖”呈現某一種顏色,像是加了一塊有色玻璃在圖片前面一樣,因此它并不能多帶帶改變圖片某一元素的顏色,如黑色小狗不能變成白色小狗。當數值為10時,效果如圖12;當數值為100時,效果如圖13,可見當數值越大時,顏色變深的效果越強。
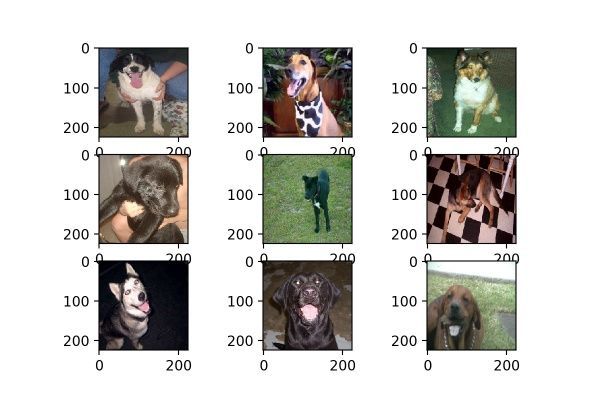
圖12

圖13
9. horizontal_flip & vertical_flip
datagen = image.ImageDataGenerator(horizontal_flip=True)
horizontal_flip的作用是隨機對圖片執行水平翻轉操作,意味著不一定對所有圖片都會執行水平翻轉,每次生成均是隨機選取圖片進行翻轉。效果如圖14。
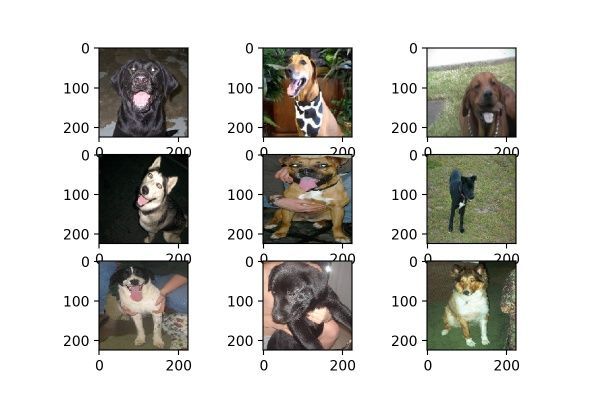
圖14
datagen = image.ImageDataGenerator(vertical_flip=True
vertical_flip是作用是對圖片執行上下翻轉操作,和horizontal_flip一樣,每次生成均是隨機選取圖片進行翻轉,效果如圖15。
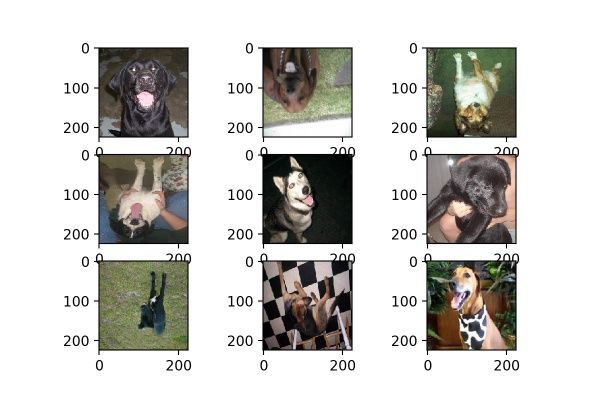
圖15
當然了,在貓狗大戰數據集當中不適合使用vertical_flip,因為一般沒有倒過來的動物。
10. rescale
datagen = image.ImageDataGenerator(rescale= 1/255, width_shift_range=0.1)
rescale的作用是對圖片的每個像素值均乘上這個放縮因子,這個操作在所有其它變換操作之前執行,在一些模型當中,直接輸入原圖的像素值可能會落入激活函數的“死亡區”,因此設置放縮因子為1/255,把像素值放縮到0和1之間有利于模型的收斂,避免神經元“死亡”。
圖片經過rescale之后,保存到本地的圖片用肉眼看是沒有任何區別的,如果我們在內存中直接打印圖片的數值,可以看到以下結果:
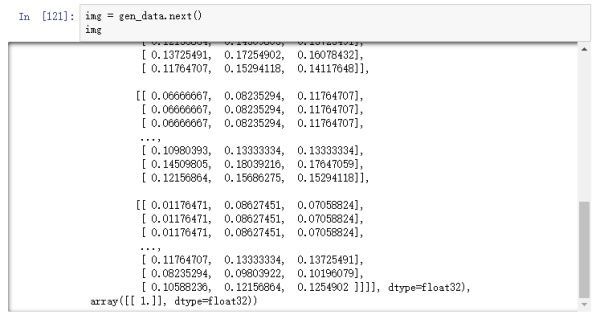
圖16
可以從圖16看到,圖片像素值都被縮小到0和1之間,但如果打開保存在本地的圖片,其數值依然不變,如圖17。
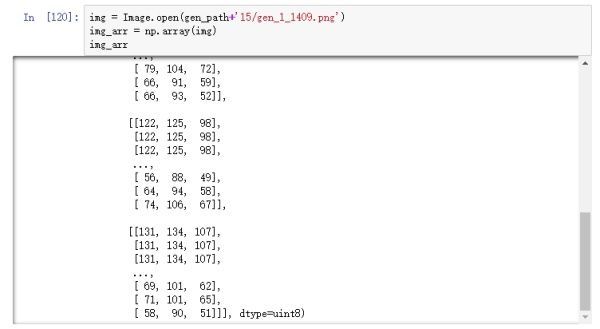
圖17
應該是在保存到本地的時候,keras把圖像像素值恢復為原來的尺度了,在內存中查看則不會。
11. fill_mode
datagen = image.ImageDataGenerator(fill_mode="wrap", zoom_range=[4, 4])
fill_mode為填充模式,如前面提到,當對圖片進行平移、放縮、錯切等操作時,圖片中會出現一些缺失的地方,那這些缺失的地方該用什么方式補全呢?就由fill_mode中的參數確定,包括:“constant”、“nearest”(默認)、“reflect”和“wrap”。這四種填充方式的效果對比如圖18所示,從左到右,從上到下分別為:“reflect”、“wrap”、“nearest”、“constant”。
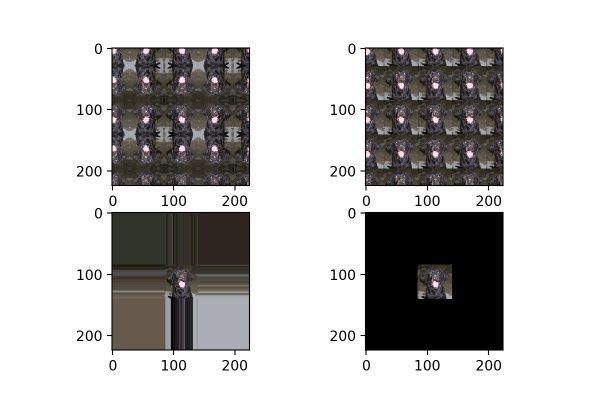
圖18
當設置為“constant”時,還有一個可選參數,cval,代表使用某個固定數值的顏色來進行填充。圖19為cval=100時的效果,可以與圖18右下角的無cval參數的圖對比。

圖19
自己動手來測試?
這里給出一段小小的代碼,作為進行這些參數調試時的代碼,你也可以使用jupyter notebook來試驗這些參數,把圖片結果打印到你的網頁上。
%matplotlib inline
import matplotlib.pyplot as plt
from PIL import Image
from keras.preprocessing import image
import glob
# 設置生成器參數
datagen = image.ImageDataGenerator(fill_mode="wrap", zoom_range=[4, 4])
gen_data = datagen.flow_from_directory(PATH,?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? batch_size=1,?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? shuffle=False,?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? save_to_dir=SAVE_PATH,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? save_prefix="gen",?
? ? ? target_size=(224, 224))
# 生成9張圖
for i in range(9):
? ?gen_data.next()?
# 找到本地生成圖,把9張圖打印到同一張figure上
name_list = glob.glob(gen_path+"16/*")
fig = plt.figure()
for i in range(9):
? ?img = Image.open(name_list[i])
? ?sub_img = fig.add_subplot(331 + i)
? ?sub_img.imshow(img)
plt.show()
結語
面對小數據集時,使用DataAugmentation擴充你的數據集就變得非常重要,但在使用DataAugmentation之前,先要了解你的數據集需不需要這類圖片,如貓狗大戰數據集不需要上下翻轉的圖片,以及思考一下變換的程度是不是合理的,例如把目標水平偏移到圖像外面就是不合理的。多試幾次效果,再最終確定使用哪些參數。上面所有內容已經公布在我的github(https://github.com/JustinhoCHN/keras-image-data-augmentation)上面,附上了實驗時的jupyter notebook文件,大家可以玩一玩,have fun!
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4669.html
摘要:摘要本文對膠囊網絡進行了非技術性的簡要概括,分析了其兩個重要屬性,之后針對手寫體數據集上驗證多層感知機卷積神經網絡以及膠囊網絡的性能。這是一個非結構化的數字圖像識別問題,使用深度學習算法能夠獲得最佳性能。作者信息,數據科學,深度學習初學者。 摘要: 本文對膠囊網絡進行了非技術性的簡要概括,分析了其兩個重要屬性,之后針對MNIST手寫體數據集上驗證多層感知機、卷積神經網絡以及膠囊網絡的性...
摘要:可以參見以下相關閱讀創造更多數據上一小節說到了有了更多數據,深度學習算法通常會變的更好。 導語我經常被問到諸如如何從深度學習模型中得到更好的效果的問題,類似的問題還有:我如何提升準確度如果我的神經網絡模型性能不佳,我能夠做什么?對于這些問題,我經常這樣回答,我并不知道確切的答案,但是我有很多思路,接著我會列出了我所能想到的所有或許能夠給性能帶來提升的思路。為避免一次次羅列出這樣一個簡單的列表...

閱讀 1038·2021-11-15 18:11
閱讀 3161·2021-09-22 15:33
閱讀 3458·2021-09-01 11:42
閱讀 2653·2021-08-24 10:03
閱讀 3614·2021-07-29 13:50
閱讀 2925·2019-08-30 14:08
閱讀 1273·2019-08-28 17:56
閱讀 2258·2019-08-26 13:57



