資訊專欄INFORMATION COLUMN

摘要:可以參見以下相關閱讀創(chuàng)造更多數(shù)據(jù)上一小節(jié)說到了有了更多數(shù)據(jù),深度學習算法通常會變的更好。
導語
我經(jīng)常被問到諸如如何從深度學習模型中得到更好的效果的問題,類似的問題還有:
我如何提升準確度
如果我的神經(jīng)網(wǎng)絡模型性能不佳,我能夠做什么?
對于這些問題,我經(jīng)常這樣回答,“我并不知道確切的答案,但是我有很多思路”,接著我會列出了我所能想到的所有或許能夠給性能帶來提升的思路。
為避免一次次羅列出這樣一個簡單的列表,我決定把所有想法詳細寫在這篇博客里。
這些思路應該是通用的,不僅能在深度學習領域幫助你,還能適用于任何機器學習算法。
這篇博文略長,你可以將其加入書簽(之后再看)。

如何提升深度學習性能?
照片來源:Pedro Ribeiro Sim?es?
提升算法性能思路
這個列表里提到的思路并完全,但是一個好的開始。?
我的目的是給出很多可以嘗試的思路,希望其中的一或兩個你之前沒有想到。你經(jīng)常只需要一個好的想法就能得到性能提升。
如果你能從其中一個思路中得到結(jié)果,請在評論區(qū)告訴我。我很高興能得知這些好消息。
如果你有更多的想法,或者是所列思路的拓展,也請告訴我,我和其他讀者都將受益!有時候僅僅是一個想法或許就能使他人得到突破。
我將此博文分為四個部分:?
1. 通過數(shù)據(jù)提升性能?
2. 通過算法提升性能?
3. 通過算法調(diào)參提升性能?
4. 通過嵌套模型提升性能
通常來講,隨著列表自上而下,性能的提升也將變小。例如,對問題進行新的架構(gòu)或者獲取更多的數(shù)據(jù),通常比調(diào)整最優(yōu)算法的參數(shù)能帶來更好的效果。雖然并不總是這樣,但是通常來講是的。
我已經(jīng)把相應的鏈接加入了博客的教程中,相應網(wǎng)站的問題中,以及經(jīng)典的Neural Net FAQ中。
部分思路只適用于人工神經(jīng)網(wǎng)絡,但是大部分是通用的。通用到足夠你用來配合其他技術來碰撞出提升模型性能的方法。
OK,現(xiàn)在讓我們開始吧。
1. 通過數(shù)據(jù)提升性能
對你的訓練數(shù)據(jù)和問題定義進行適當改變,你能得到很大的性能提升。或許是較大的性能提升。
以下是我將要提到的思路:
獲取更多數(shù)據(jù)
創(chuàng)造更多數(shù)據(jù)
重放縮你的數(shù)據(jù)
轉(zhuǎn)換你的數(shù)據(jù)
特征選取
重架構(gòu)你的問題
1) 獲取更多數(shù)據(jù)
你能獲取更多訓練數(shù)據(jù)嗎??
你的模型的質(zhì)量通常受到你的訓練數(shù)據(jù)質(zhì)量的限制。為了得到較好的模型,你首先應該想辦法獲得較好的數(shù)據(jù)。你也想盡可能多的獲得那些較好的數(shù)據(jù)。
有更多的數(shù)據(jù),深度學習和其他現(xiàn)代的非線性機器學習技術有更全的學習源,能學得更好,深度學習尤為如此。這也是機器學習對大家充滿吸引力的很大一個原因(世界到處都是數(shù)據(jù))。如下圖所示:
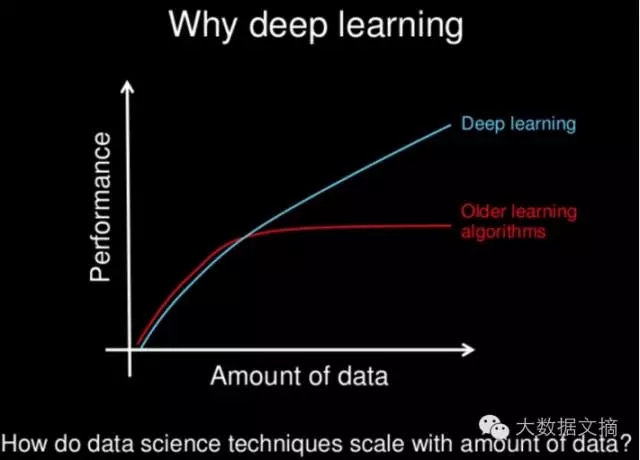
為什么選擇深度學習??
圖片由Andrew Ng提供,版權(quán)所有?
更多的數(shù)據(jù)并不是總是有用,但是確實有幫助。于我而言,如果可以,我會選擇獲取更多的數(shù)據(jù)。
可以參見以下相關閱讀:?
Datasets Over Algorithms(www.edge.org/response-detail/26587)
2) 創(chuàng)造更多數(shù)據(jù)
上一小節(jié)說到了有了更多數(shù)據(jù),深度學習算法通常會變的更好。有些時候你可能無法合理地獲取更多數(shù)據(jù),那你可以試試創(chuàng)造更多數(shù)據(jù)。
如果你的數(shù)據(jù)是數(shù)值型向量,可以隨機構(gòu)造已有向量的修改版本。
如果你的數(shù)據(jù)是圖片,可以隨機構(gòu)造已有圖片的修改版本(平移、截取、旋轉(zhuǎn)等)。
如果你的數(shù)據(jù)是文本,類似的操作……
這通常被稱作數(shù)據(jù)擴增(data augmentation)或者數(shù)據(jù)生成(data generation)。
你可以利用一個生成模型。你也可以用一些簡單的技巧。例如,針對圖片數(shù)據(jù),你可以通過隨機地平移或旋轉(zhuǎn)已有圖片獲取性能的提升。如果新數(shù)據(jù)中包含了這種轉(zhuǎn)換,則提升了模型的泛化能力。
這也與增加噪聲是相關的,我們習慣稱之為增加擾動。它起到了與正則化方法類似的作用,即抑制訓練數(shù)據(jù)的過擬合。
以下是相關閱讀:
Image Augmentation for Deep Learning With Keras(http://machinelearningmastery.com/image-augmentation-deep-learning-keras/)
What is jitter? (Training with noise)(ftp://ftp.sas.com/pub/neural/FAQ3.html#A_jitter)
3) 重縮放(rescale)你的數(shù)據(jù)
這是一個快速獲得性能提升的方法。?
當應用神經(jīng)網(wǎng)絡時,一個傳統(tǒng)的經(jīng)驗法則是:重縮放(rescale)你的數(shù)據(jù)至激活函數(shù)的邊界。
如果你在使用sigmoid激活函數(shù),重縮放你的數(shù)據(jù)到0和1的區(qū)間里。如果你在使用雙曲正切(tanh)激活函數(shù),重縮放數(shù)據(jù)到-1和1的區(qū)間里。
這種方法可以被應用到輸入數(shù)據(jù)(x)和輸出數(shù)據(jù)(y)。例如,如果你在輸出層使用sigmoid函數(shù)去預測二元分類的結(jié)果,應當標準化y值,使之成為二元的。如果你在使用softmax函數(shù),你依舊可以通過標準化y值來獲益。
這依舊是一個好的經(jīng)驗法則,但是我想更深入一點。我建議你可以參考下述方法來創(chuàng)造一些訓練數(shù)據(jù)的不同的版本:
歸一化到0和1的區(qū)間。
重放縮到-1和1的區(qū)間
標準化(譯者注:標準化數(shù)據(jù)使之成為零均值,單位標準差)
然后對每一種方法,評估你的模型的性能,選取較好的進行使用。如果你改變了你的激活函數(shù),重復這一過程。
在神經(jīng)網(wǎng)絡中,大的數(shù)值累積效應(疊加疊乘)并不是好事,除上述方法之外,還有其他的方法來控制你的神經(jīng)網(wǎng)絡中數(shù)據(jù)的數(shù)值大小,譬如歸一化激活函數(shù)和權(quán)重,我們會在以后討論這些技術。
以下為相關閱讀:
Should I standardize the input variables (column vectors)?(ftp://ftp.sas.com/pub/neural/FAQ2.html#A_std)
How To Prepare Your Data For Machine Learning in Python with Scikit-Learn(http://machinelearningmastery.com/prepare-data-machine-learning-python-scikit-learn/)
4) 數(shù)據(jù)變換
這里的數(shù)據(jù)變換與上述的重縮放方法類似,但需要更多工作。?
你必須非常熟悉你的數(shù)據(jù)。通過可視化來考察離群點。
猜測每一列數(shù)據(jù)的單變量分布。
列數(shù)據(jù)看起來像偏斜的高斯分布嗎?考慮用Box-Cox變換調(diào)整偏態(tài)。
列數(shù)據(jù)看起來像指數(shù)分布嗎?考慮用對數(shù)變換。
列數(shù)據(jù)看起來有一些特征,但是它們被一些明顯的東西遮蓋了,嘗試取平方或者開平方根來轉(zhuǎn)換數(shù)據(jù)
你能離散化一個特征或者以某種方式組合特征,來更好地突出一些特征嗎?
依靠你的直覺,嘗試以下方法。
你能利用類似PCA的投影方法來預處理數(shù)據(jù)嗎?
你能綜合多維特征至一個單一數(shù)值(特征)嗎?
你能用一個新的布爾標簽去發(fā)現(xiàn)問題中存在一些有趣的方面嗎?
你能用其他方法探索出目前場景下的其他特殊結(jié)構(gòu)嗎?
神經(jīng)網(wǎng)層擅長特征學習(feature engineering)。它(自己)可以做到這件事。但是如果你能更好的發(fā)現(xiàn)問題到網(wǎng)絡中的結(jié)構(gòu),神經(jīng)網(wǎng)層會學習地更快。你可以對你的數(shù)據(jù)就不同的轉(zhuǎn)換方式進行抽樣調(diào)查,或者嘗試特定的性質(zhì),來看哪些有用,哪些沒用。
以下是相關閱讀:
How to Define Your Machine Learning Problem(http://machinelearningmastery.com/how-to-define-your-machine-learning-problem/)
Discover Feature Engineering, How to Engineer Features and How to Get Good at It(http://machinelearningmastery.com/discover-feature-engineering-how-to-engineer-features-and-how-to-get-good-at-it/)
How To Prepare Your Data For Machine Learning in Python with Scikit-Learn(http://machinelearningmastery.com/prepare-data-machine-learning-python-scikit-learn/)
5) 特征選擇
一般說來,神經(jīng)網(wǎng)絡對不相關的特征是具有魯棒的(校對注:即不相關的特征不會很大影響神經(jīng)網(wǎng)絡的訓練和效果)。它們會用近似于0的權(quán)重來弱化那些沒有預測能力的特征的貢獻。
盡管如此,這些無關的數(shù)據(jù)特征,在訓練周期依舊要耗費大量的資源。所以你能去除數(shù)據(jù)里的一些特征嗎?
有許多特征選擇的方法和特征重要性的方法,這些方法能夠給你提供思路,哪些特征該保留,哪些特征該剔除。最簡單的方式就是對比所有特征和部分特征的效果。?
同樣的,如果你有時間,我建議在同一個網(wǎng)絡中嘗試選擇不同的視角來看待你的問題,評估它們,來看看分別有怎樣的性能。
或許你利用更少的特征就能達到同等甚至更好的性能。而且,這將使模型變得更快!
或許所有的特征選擇方法都剔除了同樣的特征子集。很好,這些方法在沒用的特征上達成了一致。
或許篩選過后的特征子集,能帶給特征工程的新思路。
以下是相關閱讀:
An Introduction to Feature Selection(http://machinelearningmastery.com/an-introduction-to-feature-selection/)
Feature Selection For Machine Learning in Python(http://machinelearningmastery.com/feature-selection-machine-learning-python/)
6) 重新架構(gòu)你的問題
有時候要試試從你當前定義的問題中跳出來,想想你所收集到的觀察值是定義你問題的方式嗎?或許存在其他方法。或許其他構(gòu)建問題的方式能夠更好地揭示待學習問題的結(jié)構(gòu)。
我真的很喜歡這個嘗試,因為它迫使你打開自己的思路。這確實很難,尤其是當你已經(jīng)對當前的方法投入了大量的時間和金錢時。
但是咱們這么想想,即使你列出了3-5個可供替代的建構(gòu)方案,而且最終還是放棄了它們,但這至少說明你對當前的方案更加自信了。
看看能夠在一個時間窗(時間周期)內(nèi)對已有的特征/數(shù)據(jù)做一個合并。
或許你的分類問題可以成為一個回歸問題(有時候是回歸到分類)。
或許你的二元輸出可以變成softmax輸出?
或許你可以轉(zhuǎn)而對子問題進行建模。
仔細思考你的問題,較好在你選定工具之前就考慮用不同方法構(gòu)建你的問題,因為此時你對解決方案并沒有花費太多的投入。除此之外,如果你在某個問題上卡住了,這樣一個簡單的嘗試能釋放更多新的想法。
而且,這并不代表你之前的工作白干了,關于這點你可以看看后續(xù)的模型嵌套部分。
以下為相關閱讀:
How to Define Your Machine Learning Problem(http://machinelearningmastery.com/how-to-define-your-machine-learning-problem/)
2. 通過算法提升性能
機器學習當然是用算法解決問題。
所有的理論和數(shù)學都是描繪了應用不同的方法從數(shù)據(jù)中學習一個決策過程(如果我們這里只討論預測模型)。
你已經(jīng)選擇了深度學習來解釋你的問題。但是這真的是較好的選擇嗎?在這一節(jié)中,我們會在深入到如何較大地發(fā)掘你所選擇的深度學習方法之前,接觸一些算法選擇上的思路。
下面是一個簡要列表:
對算法進行抽樣調(diào)查
借鑒已有文獻
重采樣方法
下面我解釋下上面提到的幾個方法。
1) 對算法進行抽樣調(diào)查
其實你事先無法知道,針對你的問題哪個算法是最優(yōu)的。如果你知道,你可能就不需要機器學習了。那有沒有什么數(shù)據(jù)(辦法)可以證明你選擇的方法是正確的?
讓我們來解決這個難題。當從所有可能的問題中平均來看各算法的性能時,沒有哪個算法能夠永遠勝過其他算法。所有的算法都是平等的,下面是在no free lunch theorem中的一個總結(jié)。
或許你選擇的算法不是針對你的問題最優(yōu)的那個?
我們不是在嘗試解決所有問題,算法世界中有很多新熱的方法,可是它們可能并不是針對你數(shù)據(jù)集的最優(yōu)算法。
我的建議是收集(證據(jù))數(shù)據(jù)指標。接受更好的算法或許存在這一觀點,并且給予其他算法在解決你的問題上“公平競爭”的機會。
抽樣調(diào)查一系列可行的方法,來看看哪些還不錯,哪些不理想。
首先嘗試評估一些線性方法,例如邏輯回歸(logistic regression)和線性判別分析(linear discriminate analysis)。
評估一些樹類模型,例如CART, 隨機森林(Random Forest)和Gradient Boosting。
評估一些實例方法,例如支持向量機(SVM)和K-近鄰(kNN)。
評估一些其他的神經(jīng)網(wǎng)絡方法,例如LVQ, MLP, CNN, LSTM, hybrids等
選取性能較好的算法,然后通過進一步的調(diào)參和數(shù)據(jù)準備來提升。尤其注意對比一下深度學習和其他常規(guī)機器學習方法,對上述結(jié)果進行排名,比較他們的優(yōu)劣。
很多時候你會發(fā)現(xiàn)在你的問題上可以不用深度學習,而是使用一些更簡單,訓練速度更快,甚至是更容易理解的算法。
以下為相關閱讀:
A Data-Driven Approach to Machine Learning(http://machinelearningmastery.com/a-data-driven-approach-to-machine-learning/)
Why you should be Spot-Checking Algorithms on your Machine Learning Problems(http://machinelearningmastery.com/why-you-should-be-spot-checking-algorithms-on-your-machine-learning-problems/)
Spot-Check Classification Machine Learning Algorithms in Python with scikit-learn(http://machinelearningmastery.com/spot-check-classification-machine-learning-algorithms-python-scikit-learn/)
2) 借鑒已有文獻
方法選擇的一個捷徑是借鑒已有的文獻資料。可能有人已經(jīng)研究過與你的問題相關的問題,你可以看看他們用的什么方法。
你可以閱讀論文,書籍,博客,問答網(wǎng)站,教程,以及任何能在谷歌搜索到的東西。
寫下所有的想法,然后用你的方式把他們研究一遍。
這不是復制別人的研究,而是啟發(fā)你想出新的想法,一些你從沒想到但是卻有可能帶來性能提升的想法。
發(fā)表的研究通常都是非常贊的。世界上有非常多聰明的人,寫了很多有趣的東西。你應當好好挖掘這個“圖書館”,找到你想要的東西。
以下為相關閱讀:
How to Research a Machine Learning Algorithm(http://machinelearningmastery.com/how-to-research-a-machine-learning-algorithm/)
Google Scholar(http://scholar.google.com/)
3) 重采樣方法
你必須知道你的模型效果如何。你對模型性能的估計可靠嗎?
深度學習模型在訓練階段非常緩慢。這通常意味著,我們無法用一些常用的方法,例如k層交叉驗證,去估計模型的性能。
或許你在使用一個簡單的訓練集/測試集分割,這是常規(guī)套路。如果是這樣,你需要確保這種分割針對你的問題具有代表性。單變量統(tǒng)計和可視化是一個好的開始。
或許你能利用硬件來加速估計的過程。例如,如果你有集群或者AWS云端服務(Amazon Web Services)賬號,你可以并行地訓練n個模型,然后獲取結(jié)果的均值和標準差來得到更魯棒的估計。
或許你可以利用hold-out驗證方法來了解模型在訓練后的性能(這在早停法(early stopping)中很有用,后面會講到)。
或許你可以先隱藏一個完全沒用過的驗證集,等到你已經(jīng)完成模型選擇之后再使用它。
而有時候另外的方式,或許你能夠讓數(shù)據(jù)集變得更小,以及使用更強的重采樣方法。
有些情況下你會發(fā)現(xiàn)在訓練集的一部分樣本上訓練得到的模型的性能,和在整個數(shù)據(jù)集上訓練得到的模型的性能有很強的相關性。也許你可以先在小數(shù)據(jù)集上完成模型選擇和參數(shù)調(diào)優(yōu),然后再將最終的方法擴展到全部數(shù)據(jù)集上。
或許你可以用某些方式限制數(shù)據(jù)集,只取一部分樣本,然后用它進行全部的建模過程。
以下為相關閱讀:
Evaluate the Performance Of Deep Learning Models in Keras(http://machinelearningmastery.com/evaluate-performance-deep-learning-models-keras/)
Evaluate the Performance of Machine Learning Algorithms in Python using Resampling(http://machinelearningmastery.com/evaluate-performance-machine-learning-algorithms-python-using-resampling/)
3. 通過算法調(diào)參提升性能
這通常是工作的關鍵所在。你經(jīng)常可以通過抽樣調(diào)查快速地發(fā)現(xiàn)一個或兩個性能優(yōu)秀的算法。但是如果想得到最優(yōu)的算法可能需要幾天,幾周,甚至幾個月。
為了獲得更優(yōu)的模型,以下是對神經(jīng)網(wǎng)絡算法進行參數(shù)調(diào)優(yōu)的幾點思路:
診斷(Diagnostics)
權(quán)重初始化(Weight Initialization)
學習速率(Learning Rate)
激活函數(shù)
網(wǎng)絡拓撲(Network Topology)
批次和周期(Batches and Epochs)
正則化
優(yōu)化和損失
早停法
你可能需要訓練一個給定“參數(shù)配置”的神經(jīng)網(wǎng)絡模型很多次(3-10次甚至更多),才能得到一個估計性能不錯的參數(shù)配置。這一點幾乎適用于這一節(jié)中你能夠調(diào)參的所有方面。
關于超參數(shù)優(yōu)化請參閱博文:
How to Grid Search Hyperparameters for Deep Learning Models in Python With Keras(http://machinelearningmastery.com/grid-search-hyperparameters-deep-learning-models-python-keras/)
1) 診斷
如果你能知道為什么你的模型性能不再提高了,你就能獲得擁有更好性能的模型。?
你的模型是過擬合還是欠擬合?永遠牢記這個問題。永遠。?
模型總是會遇到過擬合或者欠擬合,只是程度不同罷了。一個快速了解模型學習行為的方法是,在每個周期,評估模型在訓練集和驗證集上的表現(xiàn),并作出圖表。
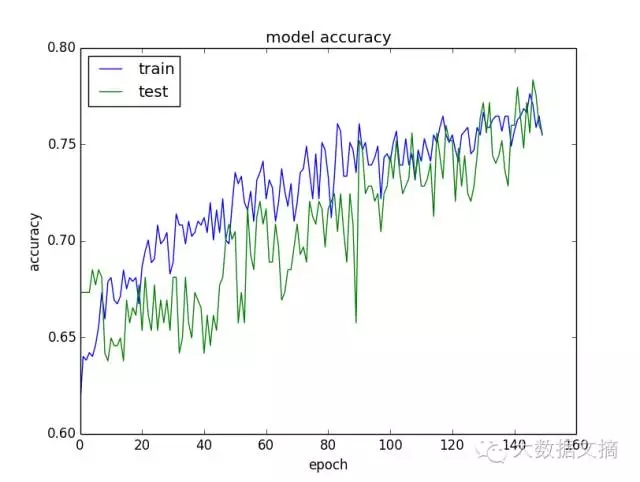
如果訓練集上的模型總是優(yōu)于驗證集上的模型,你可能遇到了過擬合,你可以使用諸如正則化的方法。
如果訓練集和驗證集上的模型都很差,你可能遇到了欠擬合,你可以提升網(wǎng)絡的容量,以及訓練更多或者更久。
如果有一個拐點存在,在那之后訓練集上的模型開始優(yōu)于驗證集上的模型,你可能需要使用早停法。
經(jīng)常畫一畫這些圖表,學習它們來了解不同的方法,你能夠提升模型的性能。這些圖表可能是你能創(chuàng)造的最有價值的(模型狀態(tài))診斷信息。
另一個有用的診斷是網(wǎng)絡模型判定對和判定錯的觀察值。
對于難以訓練的樣本,或許你需要更多的數(shù)據(jù)。
或許你應該剔除訓練集中易于建模的多余的樣本。
也許可以嘗試對訓練集劃分不同的區(qū)域,在特定區(qū)域中用更專長的模型。
以下為相關閱讀:
Display Deep Learning Model Training History in Keras(http://machinelearningmastery.com/display-deep-learning-model-training-history-in-keras/)
Overfitting and Underfitting With Machine Learning Algorithms(http://machinelearningmastery.com/overfitting-and-underfitting-with-machine-learning-algorithms/)
2) 權(quán)重初始化
經(jīng)驗法則通常是:用小的隨機數(shù)進行初始化。
在實踐中,這可能依舊效果不錯,但是對于你的網(wǎng)絡來說是較佳的嗎?對于不同的激活函數(shù)也有一些啟發(fā)式的初始化方法,但是在實踐應用中并沒有太多不同。
固定你的網(wǎng)絡,然后嘗試多種初始化方式。
記住,權(quán)重是你的模型真正的參數(shù),你需要找到他們。有很多組權(quán)重都能有不錯的性能表現(xiàn),但我們要盡量找到較好的。
嘗試所有不同的初始化方法,考察是否有一種方法在其他情況不變的情況下(效果)更優(yōu)。
嘗試用無監(jiān)督的方法,例如自動編碼(autoencoder),來進行預先學習。
嘗試使用一個已經(jīng)存在的模型,只是針對你的問題重新訓練輸入層和輸出層(遷移學習(transfer learning))
需要提醒的一點是,改變權(quán)重初始化方法和激活函數(shù),甚至優(yōu)化函數(shù)/損失函數(shù)緊密相關。
以下為相關閱讀:
Initialization of deep networks(http://deepdish.io/2015/02/24/network-initialization/)
3) 學習率
調(diào)整學習率很多時候也是行之有效的時段。
以下是可供探索的一些想法:
實驗很大和很小的學習率
格點搜索文獻里常見的學習速率值,考察你能學習多深的網(wǎng)絡。
嘗試隨周期遞減的學習率
嘗試經(jīng)過固定周期數(shù)后按比例減小的學習率。
嘗試增加一個動量項(momentum term),然后對學習速率和動量同時進行格點搜索。
越大的網(wǎng)絡需要越多的訓練,反之亦然。如果你添加了太多的神經(jīng)元和層數(shù),適當提升你的學習速率。同時學習率需要和訓練周期,batch size大小以及優(yōu)化方法聯(lián)系在一起考慮。
以下為相關閱讀:
Using Learning Rate Schedules for Deep Learning Models in Python with Keras(http://machinelearningmastery.com/using-learning-rate-schedules-deep-learning-models-python-keras/)
What learning rate should be used for backprop?(ftp://ftp.sas.com/pub/neural/FAQ2.html#A_learn_rate)
4) 激活函數(shù)
你或許應該使用修正激活函數(shù)(rectifier activation functions)。他們也許能提供更好的性能。
在這之前,最早的激活函數(shù)是sigmoid和tanh,之后是softmax, 線性激活函數(shù),或者輸出層上的sigmoid函數(shù)。我不建議嘗試更多的激活函數(shù),除非你知道你自己在干什么。
嘗試全部三種激活函數(shù),并且重縮放你的數(shù)據(jù)以滿足激活函數(shù)的邊界。
顯然,你想要為輸出的形式選擇正確的傳遞函數(shù),但是可以考慮一下探索不同表示。例如,把在二元分類問題上使用的sigmoid函數(shù)切換到回歸問題上使用的線性函數(shù),然后后置處理你的輸出。這可能需要改變損失函數(shù)使之更合適。詳情參閱數(shù)據(jù)轉(zhuǎn)換那一節(jié)。
以下為相關閱讀:
Why use activation functions?(ftp://ftp.sas.com/pub/neural/FAQ2.html#A_act)
5) 網(wǎng)絡拓撲
網(wǎng)絡結(jié)構(gòu)的改變能帶來好處。
你需要多少層以及多少個神經(jīng)元?抱歉沒有人知道。不要問這種問題...
那怎么找到適用你的問題的配置呢?去實驗吧。
嘗試一個隱藏層和許多神經(jīng)元(廣度模型)。
嘗試一個深的網(wǎng)絡,但是每層只有很少的神經(jīng)元(深度模型)。
嘗試上述兩種方法的組合。
借鑒研究問題與你的類似的論文里面的結(jié)構(gòu)。
嘗試拓撲模式(扇出(fan out)然后扇入(fan in))和書籍論文里的經(jīng)驗法則(下有鏈接)
選擇總是很困難的。通常說來越大的網(wǎng)絡有越強的代表能力,或許你需要它。越多的層數(shù)可以提供更強的從數(shù)據(jù)中學到的抽象特征的能力。或許需要它。
深層的神經(jīng)網(wǎng)絡需要更多的訓練,無論是訓練周期還是學習率,都應該相應地進行調(diào)整。
以下為相關閱讀:?
這些鏈接會給你很多啟發(fā)該嘗試哪些事情,至少對我來說是的。
How many hidden layers should I use?(ftp://ftp.sas.com/pub/neural/FAQ3.html#A_hl)
How many hidden units should I use?(ftp://ftp.sas.com/pub/neural/FAQ3.html#A_hu)
6) Batches和周期
batch size大小會決定最后的梯度,以及更新權(quán)重的頻度。一個周期(epoch)指的是神經(jīng)網(wǎng)絡看一遍全部訓練數(shù)據(jù)的過程。
你是否已經(jīng)試驗了不同的批次batch size和周期數(shù)??
之前,我們已經(jīng)討論了學習率,網(wǎng)絡大小和周期之間的關系。
在很深的網(wǎng)絡結(jié)構(gòu)里你會經(jīng)常看到:小的batch size配以大的訓練周期。
下面這些或許能有助于你的問題,也或許不能。你要在自己的數(shù)據(jù)上嘗試和觀察。
嘗試選取與訓練數(shù)據(jù)同大小的batch size,但注意一下內(nèi)存(批次學習(batch learning))
嘗試選取1作為batch size(在線學習(online learning))
嘗試用格點搜索不同的小的batch size(8,16,32,…)
分別嘗試訓練少量周期和大量周期。
考慮一個接近無窮的周期值(持續(xù)訓練),去記錄到目前為止能得到的較佳的模型。
一些網(wǎng)絡結(jié)構(gòu)對batch size更敏感。我知道多層感知器(Multilayer Perceptrons)通常對batch size是魯棒的,而LSTM和CNNs比較敏感,但是這只是一個說法(僅供參考)。
以下為相關閱讀:
What are batch, incremental, on-line … learning?(ftp://ftp.sas.com/pub/neural/FAQ2.html#A_styles)
Intuitively, how does mini-batch size affect the performance of (stochastic) gradient descent?(https://www.quora.com/Intuitively-how-does-mini-batch-size-affect-the-performance-of-stochastic-gradient-descent)
7) 正則化
正則化是一個避免模型在訓練集上過擬合的好方法。
神經(jīng)網(wǎng)絡里最熱的正則化技術是dropout方法,你是否試過?dropout方法在訓練階段隨機地跳過一些神經(jīng)元,驅(qū)動這一層其他的神經(jīng)元去捕捉松弛。簡單而有效。你可以從dropout方法開始。
格點搜索不同的丟失比例。
分別在輸入,隱藏層和輸出層中試驗dropout方法
dropout方法也有一些拓展,比如你也可以嘗試drop connect方法。
也可以嘗試其他更傳統(tǒng)的神經(jīng)網(wǎng)絡正則化方法,例如:
權(quán)重衰減(Weight decay)去懲罰大的權(quán)重
激活約束(Activation constraint)去懲罰大的激活值
你也可以試驗懲罰不同的方面,或者使用不同種類的懲罰/正則化(L1, L2, 或者二者同時)
以下是相關閱讀:
Dropout Regularization in Deep Learning Models With Keras(http://machinelearningmastery.com/dropout-regularization-deep-learning-models-keras/)
What is Weight Decay?(ftp://ftp.sas.com/pub/neural/FAQ3.html#A_decay)
8) 優(yōu)化和損失
最常見是應用隨機梯度下降法(stochastic gradient descent),但是現(xiàn)在有非常多的優(yōu)化器。你試驗過不同的優(yōu)化(方法)過程嗎??
隨機梯度下降法是默認的選擇。先好好利用它,配以不同的學習率和動量。
許多更高級的優(yōu)化方法有更多的參數(shù),更復雜,也有更快的收斂速度。 好與壞,是不是需要用,取決于你的問題。
為了更好的利用好一個給定的(優(yōu)化)方法,你真的需要弄明白每個參數(shù)的意義,然后針對你的問題通過格點搜索不同的的取值。困難,消耗時間,但是值得。
我發(fā)現(xiàn)了一些更新更流行的方法,它們可以收斂的更快,并且針對一個給定網(wǎng)絡的容量提供了一個快速了解的方式,例如:
ADAM
RMSprop
你還可以探索其他優(yōu)化算法,例如,更傳統(tǒng)的(Levenberg-Marquardt)和不那么傳統(tǒng)的(genetic algorithms)。其他方法能夠為隨機梯度下降法和其他類似方法提供好的出發(fā)點去改進。
要被優(yōu)化的損失函數(shù)與你要解決的問題高度相關。然而,你通常還是有一些余地(可以做一些微調(diào),例如回歸問題中的均方誤(MSE)和平均誤差(MAE)等),有時候變換損失函數(shù)還有可能獲得小的性能提升,這取決于你輸出數(shù)據(jù)的規(guī)模和使用的激活函數(shù)。
以下是相關閱讀:
An overview of gradient descent optimization algorithms(http://sebastianruder.com/optimizing-gradient-descent/)
What are conjugate gradients, Levenberg-Marquardt, etc.?(ftp://ftp.sas.com/pub/neural/FAQ2.html#A_numanal)
On Optimization Methods for Deep Learning, 2011 PDF(http://ai.stanford.edu/~ang/papers/icml11-OptimizationForDeepLearning.pdf)
9) Early Stopping/早停法
一旦訓練過程中出現(xiàn)(驗證集)性能開始下降,你可以停止訓練與學習。這可以節(jié)省很多時間,而且甚至可以讓你使用更詳盡的重采樣方法來評估你的模型的性能。
早停法是一種用來避免模型在訓練數(shù)據(jù)上的過擬合的正則化方式,它需要你監(jiān)測模型在訓練集以及驗證集上每一輪的效果。一旦驗證集上的模型性能開始下降,訓練就可以停止。
如果某個條件滿足(衡量準確率的損失),你還可以設置檢查點(Checkpointing)來儲存模型,使得模型能夠繼續(xù)學習。檢查點使你能夠早停而非真正的停止訓練,因此在最后,你將有一些模型可供選擇。
以下是相關閱讀:
How to Check-Point Deep Learning Models in Keras(http://machinelearningmastery.com/check-point-deep-learning-models-keras/)
What is early stopping?(ftp://ftp.sas.com/pub/neural/FAQ3.html#A_stop)
4. 通過嵌套模型提升性能
你可以組合多個模型的預測能力。剛才提到了算法調(diào)參可以提高最后的性能,調(diào)參之后這是下一個可以提升的大領域。
事實上,你可以經(jīng)常通過組合多個“足夠好的”模型來得到優(yōu)秀的預測能力,而不是通過組合多個高度調(diào)參的(脆弱的)模型。
你可以考慮以下三個方面的嵌套方式:
組合模型
組合視角
堆疊(Stacking)
1) 組合模型
有時候我們干脆不做模型選擇,而是直接組合它們。
如果你有多個不同的深度學習模型,在你的研究問題上每一個都表現(xiàn)的還不錯,你可以通過取它們預測的平均值來進行組合。
模型差異越大,最終效果越好。例如,你可以應用非常不同的網(wǎng)絡拓撲或者不同的技術。
如果每個模型都效果不錯但是不同的方法/方式,嵌套后的預測能力將更加魯棒。
每一次你訓練網(wǎng)絡,你初始化不同的權(quán)重,然后它會收斂到不同的最終權(quán)重。你可以多次重復這一過程去得到很多網(wǎng)絡,然后把這些網(wǎng)絡的預測值組合在一起。
它們的預測將會高度相關,但是在那些難以預測的特征上,它會給你一個意外的小提升。
以下是相關閱讀:
Ensemble Machine Learning Algorithms in Python with scikit-learn(http://machinelearningmastery.com/ensemble-machine-learning-algorithms-python-scikit-learn/)
How to Improve Machine Learning Results(http://machinelearningmastery.com/how-to-improve-machine-learning-results/)
2) 組合視角
同上述類似,但是從不同視角重構(gòu)你的問題,訓練你的模型。
同樣,目標得到的是效果不錯但是不同的模型(例如,不相關的預測)。得到不同的模型的方法,你可以依賴我們在數(shù)據(jù)那一小節(jié)中羅列的那些非常不同的放縮和轉(zhuǎn)換方法。
你用來訓練模型的轉(zhuǎn)換方法越不同,你構(gòu)建問題的方式越不同,你的結(jié)果被提升的程度就越高。
簡單使用預測的均值將會是一個好的開始。
3) stacking/堆疊
你還可以學習如何較佳地組合多個模型的預測。這稱作堆疊泛化(stacked generalization),或者簡短來說就叫堆疊。
通常上,你使用簡單線性回歸方法就可以得到比取預測平均更好的結(jié)果,像正則化的回歸(regularized regression),就會學習如何給不同的預測模型賦權(quán)重。基線模型是通過取子模型的預測均值得到的,但是應用學習了權(quán)重的模型會提升性能。
Stacked Generalization (Stacking)(http://machine-learning.martinsewell.com/ensembles/stacking/)
其余的可參考資源
別的地方有很多很好的資源,但是幾乎沒有能將所有想法串聯(lián)在一起的。如果你想深入研究,我列出了如下資源和相應的博客,你能發(fā)現(xiàn)很多有趣的東西。
Neural Network FAQ(ftp://ftp.sas.com/pub/neural/FAQ.html)
How to Grid Search Hyperparameters for Deep Learning Models in Python With Keras(http://machinelearningmastery.com/grid-search-hyperparameters-deep-learning-models-python-keras/)
Must Know Tips/Tricks in Deep Neural Networks(http://lamda.nju.edu.cn/weixs/project/CNNTricks/CNNTricks.html)
How to increase validation accuracy with deep neural net?(http://stackoverflow.com/questions/37020754/how-to-increase-validation-accuracy-with-deep-neural-net)
后 記
這是一篇很長的博客,我們講述了很多內(nèi)容。你并不需要去做所有事,也許這里面的某一點就足以給你好的想法去提升性能。簡單說來大概包括下面這些:
選取一個方向?
數(shù)據(jù)
算法
調(diào)參
嵌套模型
在某一方向里選取一種方法
在選取的方法中選取一件事情去嘗試
比較結(jié)果,如果性能有提升,則保留
不斷重復
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/4422.html
摘要:基準測試我們比較了和三款,使用的深度學習庫是和,深度學習網(wǎng)絡是和。深度學習庫基準測試同樣,所有基準測試都使用位系統(tǒng),每個結(jié)果是次迭代計算的平均時間。 購買用于運行深度學習算法的硬件時,我們常常找不到任何有用的基準,的選擇是買一個GPU然后用它來測試。現(xiàn)在市面上性能較好的GPU幾乎都來自英偉達,但其中也有很多選擇:是買一個新出的TITAN X Pascal還是便宜些的TITAN X Maxwe...
摘要:目錄一引言二輕量化模型三網(wǎng)絡對比一引言自年以來,卷積神經(jīng)網(wǎng)絡簡稱在圖像分類圖像分割目標檢測等領域獲得廣泛應用。創(chuàng)新點利用和這兩個操作來設計卷積神經(jīng)網(wǎng)絡模型以減少模型使用的參數(shù)數(shù)量。 本文就近年提出的四個輕量化模型進行學習和對比,四個模型分別是:SqueezeNet、MobileNet、ShuffleNet、Xception。目錄一、引言?二、輕量化模型?? ? 2.1 SqueezeNet?...
摘要:最近,等人對于英偉達的四種在四種不同深度學習框架下的性能進行了評測。本次評測共使用了種用于圖像識別的深度學習模型。深度學習框架和不同網(wǎng)絡之間的對比我們使用七種不同框架對四種不同進行,包括推理正向和訓練正向和反向。一直是深度學習方面最暢銷的。 最近,Pedro Gusm?o 等人對于英偉達的四種 GPU 在四種不同深度學習框架下的性能進行了評測。本次評測共使用了 7 種用于圖像識別的深度學習模...
摘要:小米直達服務探秘,如何保證移動體驗小米直達服務是小米推出的混合開發(fā)框架,它可以實現(xiàn)秒開,同時可以在瀏覽器短信微信等地方打開。本文即是小米直達服務體驗保障方面的實踐分享,討論了目前移動體驗的瓶頸小米直達服務的機制與核心關鍵等內(nèi)容。 推薦 1. Node.js 8.5.0 發(fā)布 https://nodejs.org/en/blog/re... 已經(jīng)發(fā)布的 Node.js 8.5.0 版本中...

閱讀 3062·2021-11-24 10:34
閱讀 3322·2021-11-22 13:53
閱讀 2630·2021-11-22 12:03
閱讀 3598·2021-09-26 09:47
閱讀 3005·2021-09-23 11:21
閱讀 4772·2021-09-22 15:08
閱讀 3289·2021-07-23 10:59
閱讀 1258·2019-08-29 18:31






