資訊專欄INFORMATION COLUMN

摘要:而訓練的好壞,以及逆映射的好壞對實驗結果影響會比較大,經過幾個階段的訓練,圖像的內容損失會比較嚴重,實際中我們也可以觀察到的實驗效果比較差。
這是一篇總結文,總結我看過的幾篇用GAN做圖像翻譯的文章的“套路”。
首先,什么是圖像翻譯?
為了說清楚這個問題,下面我給出一個不嚴謹的形式化定義。我們先來看兩個概念。第一個概念是圖像內容(content) ?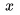 ,它是圖像的固有內容,是區分不同圖像的依據。第二個概念是圖像域(domain),域內的圖像可以認為是圖像內容被賦予了某些相同的屬性。舉個例子,我們看到一張貓的圖片,圖像內容就是那只特定的喵,如果我們給圖像賦予彩色,就得到了現實中看到的喵;如果給那張圖像賦予鉛筆畫屬性,就得到了一只“鉛筆喵”。喵~
,它是圖像的固有內容,是區分不同圖像的依據。第二個概念是圖像域(domain),域內的圖像可以認為是圖像內容被賦予了某些相同的屬性。舉個例子,我們看到一張貓的圖片,圖像內容就是那只特定的喵,如果我們給圖像賦予彩色,就得到了現實中看到的喵;如果給那張圖像賦予鉛筆畫屬性,就得到了一只“鉛筆喵”。喵~


當然,還有一種圖像翻譯,在翻譯的時候會把圖像內容也換掉,下面介紹的方法也適用于這種翻譯,這種翻譯除了研究圖像屬性的變化,還可以研究圖像內容的變化,在這里就不做討論了。
常見的GAN圖像翻譯方法
下面簡單總結幾種GAN的圖像翻譯方法。
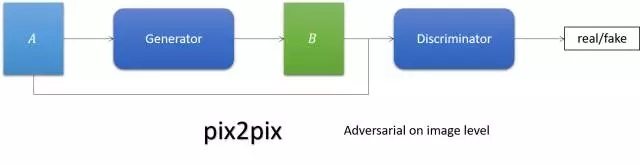
pix2pix
簡單來說,它就是跟cGAN。Generator的輸入不再是noise,而是圖像。
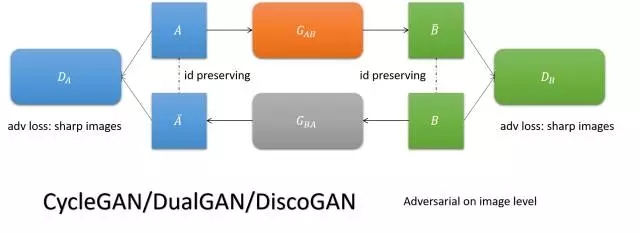
CycleGAN/DualGAN/DiscoGAN
要求圖像翻譯以后翻回來還是它自己,實現兩個域圖像的互轉。
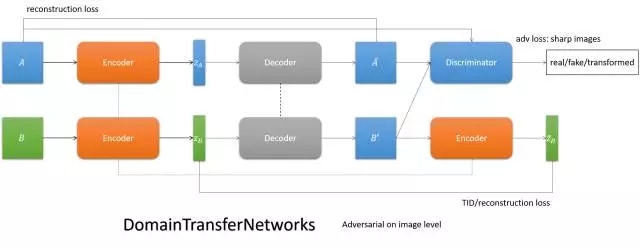
DTN
用一個encoder實現兩個域的共性編碼,通過特定域的decoder解碼,實現圖像翻譯。
FaderNets
用encoder編碼圖像的內容,通過喂給它不同的屬性,得到內容的不同表達。
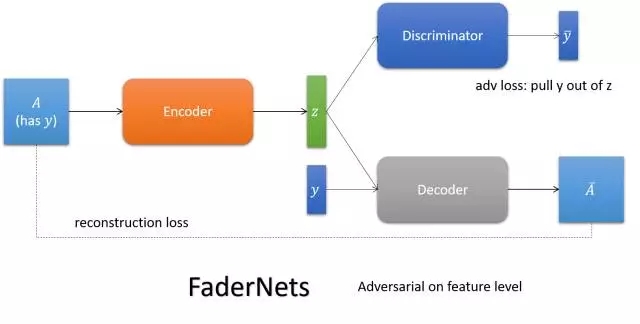
IcGAN
依靠cGAN喂給它不同屬性得到不同表達的能力,學一個可逆的cGAN以實現圖想到圖像的翻譯(傳統的cGAN是編碼+屬性到圖像的翻譯)。
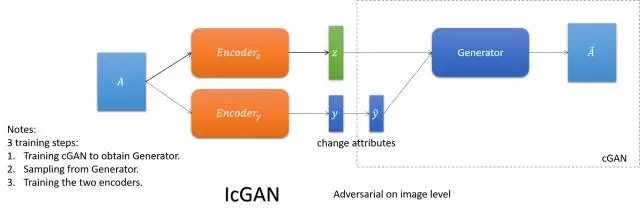
GeneGAN
將圖像編碼成內容和屬性,通過交換兩張圖的屬性,實現屬性的互轉。
Face Age-cGAN
這篇是做同個人不同年齡的翻譯。依靠cGAN喂給它不同屬性(年齡)得到不同年齡的圖像的能力,學cGAN的逆變換以得到圖像內容的編碼,再通過人臉識別系統糾正編碼,實現保id。

圖像翻譯方法的完備性
我認為一個圖像翻譯方法要取得成功,需要能夠保證下面兩個一致性(必要性):
Content consistency(內容一致性)
Domain consistency(論域一致性)
此外,我們也似乎也可以認為,滿足這兩點的圖像翻譯方法是能work的(充分性)。
我把上述兩點稱為圖像翻譯方法的完備性,換句話說,只要一個方法具備了上述兩個要求,它就應該能work。關于這個完備性的詳細論述,我會在以后給出。
下面,我們來看一下上述幾種方法是如何達成這兩個一致性的。
內容一致性
我把它們實現內容一致性的手段列在下面的表格里了。

這里有兩點需要指出。
其一,有兩個方法(IcGAN和Face Age-cGAN)依靠cGAN的能力,學cGAN的逆映射來實現圖像換屬性,它們會有多個訓練階段,不是端到端訓練的方法。而cGAN訓練的好壞,以及逆映射的好壞對實驗結果影響會比較大,經過幾個階段的訓練,圖像的內容損失會比較嚴重,實際中我們也可以觀察到 IcGAN 的實驗效果比較差。Face Age-cGAN通過引入人臉識別系統識別結果相同的約束,能夠對內容的編碼進行優化,可以起到一些緩解作用。
其二,DTN主要依靠TID loss來實現內容的一致性,而編碼一般來說是有損的,編碼相同只能在較大程度上保證內容相同。從DTN的emoji和人臉互轉的實驗我們也可以看出,emoji保id問題堪憂,參看下圖。

論域一致性
論域一致性是指,翻譯后的圖像得是論域內的圖像,也就是說,得有目標論域的共有屬性。用GAN實現的方法,很自然的一個實現論域一致性的方法就是,通過discriminator判斷圖像是否屬于目標論域。
上述幾種圖像翻譯的方法,它們實現論域一致性的手段可以分為兩種,參見下表。

此外,可以看到,FaderNets實現兩個一致性的方法都是剝離屬性和內容,而實現剝離手段則是對抗訓練。編碼層面的對抗訓練我認為博弈雙方不是勢均力敵,一方太容易贏得博弈,不難預料到它的訓練會比較tricky,訓練有效果應該不難達成,要想得到好的結果是比較難的。目前還沒有看到能夠完美復現的代碼。文章的效果太好,好得甚至讓人懷疑。
最后的最后,放一個歌單,聽說聽這個歌單煉丹會更快哦。
參考文獻
1. Isola P, Zhu J Y, Zhou T, et al. Image-to-image translation with conditional adversarial networks[J]. arXiv preprint arXiv:1611.07004, 2016.
2. Zhu J Y, Park T, Isola P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[J]. arXiv preprint arXiv:1703.10593, 2017.
3. Yi Z, Zhang H, Gong P T. DualGAN: Unsupervised Dual Learning for Image-to-Image Translation[J]. arXiv preprint arXiv:1704.02510, 2017.
4. Kim T, Cha M, Kim H, et al. Learning to discover cross-domain relations with generative adversarial networks[J]. arXiv preprint arXiv:1703.05192, 2017.
5. Taigman Y, Polyak A, Wolf L. Unsupervised cross-domain image generation[J]. arXiv preprint arXiv:1611.02200, 2016.
6. Zhou S, Xiao T, Yang Y, et al. GeneGAN: Learning Object Transfiguration and Attribute Subspace from Unpaired Data[J]. arXiv preprint arXiv:1705.04932, 2017.
7. Lample G, Zeghidour N, Usunier N, et al. Fader Networks: Manipulating Images by Sliding Attributes[J]. arXiv preprint arXiv:1706.00409, 2017.
8. Brock A, Lim T, Ritchie J M, et al. Neural photo editing with introspective adversarial networks[J]. arXiv preprint arXiv:1609.07093, 2016.
9. Antipov G, Baccouche M, Dugelay J L. Face Aging With Conditional Generative Adversarial Networks[J]. arXiv preprint arXiv:1702.01983, 2017.
10. Perarnau G, van de Weijer J, Raducanu B, et al. Invertible Conditional GANs for image editing[J]. arXiv preprint arXiv:1611.06355, 2016.
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4637.html
摘要:這篇就介紹利用生成式對抗網絡的兩個基本駕駛技能去除愛情動作片中的馬賽克給愛情動作片中的女孩穿衣服生成式模型上一篇用生成二維樣本的小例子中已經簡單介紹了,這篇再簡要回顧一下生成式模型,算是補全一個來龍去脈。 作為一名久經片場的老司機,早就想寫一些探討駕駛技術的文章。這篇就介紹利用生成式對抗網絡(GAN)的兩個基本駕駛技能:1) 去除(愛情)動作片中的馬賽克2) 給(愛情)動作片中的女孩穿(tu...
摘要:的研究興趣涵蓋大多數深度學習主題,特別是生成模型以及機器學習的安全和隱私。與以及教授一起造就了年始的深度學習復興。目前他是僅存的幾個仍然全身心投入在學術界的深度學習教授之一。 Andrej Karpathy特斯拉 AI 主管Andrej Karpathy 擁有斯坦福大學計算機視覺博士學位,讀博期間師從現任 Google AI 首席科學家李飛飛,研究卷積神經網絡在計算機視覺、自然語言處理上的應...

閱讀 2089·2021-11-23 09:51
閱讀 3697·2021-10-20 13:49
閱讀 1706·2021-09-06 15:13
閱讀 1816·2021-09-06 15:02
閱讀 3154·2021-09-02 15:11
閱讀 890·2019-08-29 15:37
閱讀 1731·2019-08-29 13:24
閱讀 2274·2019-08-29 11:28




