資訊專欄INFORMATION COLUMN

摘要:我們先看看的初始化函數(shù)的完整定義,看構(gòu)造一個模型可以輸入哪些參數(shù)我們可以將類的構(gòu)造函數(shù)中的參數(shù)分為以下幾組基礎(chǔ)參數(shù)我們訓(xùn)練的模型存放到指定的目錄中。看完模型的構(gòu)造函數(shù)后,我們大概知道和端的模型各對應(yīng)什么樣的模型,模型需要輸入什么樣的參數(shù)。
Wide and deep 模型是 TensorFlow 在 2016 年 6 月左右發(fā)布的一類用于分類和回歸的模型,并應(yīng)用到了 Google Play 的應(yīng)用推薦中 [1]。wide and deep 模型的核心思想是結(jié)合線性模型的記憶能力(memorization)和 DNN 模型的泛化能力(generalization),在訓(xùn)練過程中同時優(yōu)化 2 個模型的參數(shù),從而達(dá)到整體模型的預(yù)測能力最優(yōu)。
結(jié)合我們的產(chǎn)品應(yīng)用場景同 Google Play 的推薦場景存在較多的類似之處,在經(jīng)過調(diào)研和評估后,我們也將 wide and deep 模型應(yīng)用到產(chǎn)品的推薦排序模型,并搭建了一套線下訓(xùn)練和線上預(yù)估的系統(tǒng)。鑒于網(wǎng)上對 wide and deep 模型的相關(guān)描述和講解并不是特別多,我們將這段時間對 TensorFlow1.1 中該模型的調(diào)研和相關(guān)應(yīng)用經(jīng)驗分享出來,希望對相關(guān)使用人士帶來幫助。
wide and deep 模型的框架在原論文的圖中進(jìn)行了很好的概述。wide 端對應(yīng)的是線性模型,輸入特征可以是連續(xù)特征,也可以是稀疏的離散特征,離散特征之間進(jìn)行交叉后可以構(gòu)成更高維的離散特征。線性模型訓(xùn)練中通過 L1 正則化,能夠很快收斂到有效的特征組合中。deep 端對應(yīng)的是 DNN 模型,每個特征對應(yīng)一個低維的實數(shù)向量,我們稱之為特征的 embedding。DNN 模型通過反向傳播調(diào)整隱藏層的權(quán)重,并且更新特征的 embedding。wide and deep 整個模型的輸出是線性模型輸出與 DNN 模型輸出的疊加。
如原論文中提到的,模型訓(xùn)練采用的是聯(lián)合訓(xùn)練(joint training),模型的訓(xùn)練誤差會同時反饋到線性模型和 DNN 模型中進(jìn)行參數(shù)更新。相比于 ensemble learning 中單個模型進(jìn)行獨立訓(xùn)練,模型的融合僅在最終做預(yù)測階段進(jìn)行,joint training 中模型的融合是在訓(xùn)練階段進(jìn)行的,單個模型的權(quán)重更新會受到 wide 端和 deep 端對模型訓(xùn)練誤差的共同影響。因此在模型的特征設(shè)計階段,wide 端模型和 deep 端模型只需要分別專注于擅長的方面,wide 端模型通過離散特征的交叉組合進(jìn)行 memorization,deep 端模型通過特征的 embedding 進(jìn)行 generalization,這樣單個模型的大小和復(fù)雜度也能得到控制,而整體模型的性能仍能得到提高。
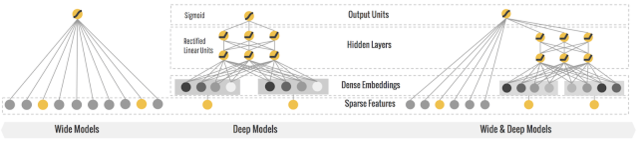
圖 1 Wide and deep 模型示意圖
Wide And Deep 模型定義
定義 wide and deep 模型是比較簡單的,tutorial 中提供了比較完整的模型構(gòu)建實例:
獲取輸入
模型的輸入是一個 python 的 dataframe。如 tutorial 的實例代碼,可以通過 pandas.read_csv 從 CSV 文件中讀入數(shù)據(jù)構(gòu)建 data frame。
定義 feature columns
tf.contrib.layers 中提供了一系列的函數(shù)定義不同類型的 feature columns:
tf.contrib.layers.sparse_column_with_XXX 構(gòu)建低維離散特征?
sparse_feature_a = sparse_column_with_hash_bucket(…)?
sparse_feature_b = sparse_column_with_hash_bucket(…)
tf.contrib.layers.crossed_column 構(gòu)建離散特征的組合?
sparse_feature_a_x_sparse_feature_b = crossed_column([sparse_feature_a, sparse_feature_b], …)
tf.contrib.layers.real_valued_column 構(gòu)建連續(xù)型實數(shù)特征?
real_feature_a = real_valued_column(…)
tf.contrib.layers.embedding_column 構(gòu)建 embedding 特征?
sparse_feature_a_emb = embedding_column(sparse_id_column=sparse_feature_a, )
定義模型
定義分類模型:
m = tf.contrib.learn.DNNLinearCombinedClassifier(
?n_classes = n_classes, // 分類數(shù)目
?weight_column_name = weight_column_name, // 訓(xùn)練實例的權(quán)重
?model_dir = model_dir, // 模型目錄
?linear_feature_columns = wide_columns, // 輸入線性模型的 feature columns
?linear_optimizer = tf.train.FtrlOptimizer(...), // 線性模型權(quán)重更新的 optimizer
?dnn_feature_columns = deep_columns, // 輸入 DNN 模型的 feature columns
?dnn_hidden_units=[100, 50],// DNN 模型的隱藏層單元數(shù)目
?dnn_optimizer=tf.train.AdagradOptimizer(...) // DNN 模型權(quán)重更新的 optimizer
?)
需要指出的是:模型的 model_dir 同下面會提到的 export 模型的目錄是 2 個不同的目錄,model_dir 存放模型的 graph 和 summary 數(shù)據(jù),如果 model_dir 存放了上一次訓(xùn)練的模型數(shù)據(jù),訓(xùn)練時會從 model_dir 恢復(fù)上一次訓(xùn)練的模型并在此基礎(chǔ)上進(jìn)行訓(xùn)練。我們用 tensorboard 加載顯示的模型數(shù)據(jù)也是從該目錄下生成的。模型 export 的目錄則主要是用于 tensorflow server 啟動時加載模型的 servable 實例,用于線上預(yù)測服務(wù)。
如果要使用回歸模型,可以如下定義:
?m = tf.contrib.learn.DNNLinearCombinedRegressor(
?weight_column_name = weight_column_name,
?linear_feature_columns = wide_columns,?
?linear_optimizer = tf.train.FtrlOptimizer(...),?
?dnn_feature_columns = deep_columns,?
?dnn_hidden_units=[100, 50],
?dnn_optimizer=tf.train.AdagradOptimizer(...)
?)
訓(xùn)練評測
訓(xùn)練模型可以使用 fit 函數(shù):m.fit(input_fn=input_fn(df_train)),評測使用 evaluate 函數(shù):m.evaluate(input_fn=input_fn(df_test))。Input_fn 函數(shù)定義如何從輸入的 dataframe 構(gòu)建特征和標(biāo)記:
?def input_fn(df)
?// tf.constant 構(gòu)建 constant tensor,df[k].values 是對應(yīng) feature column 的值構(gòu)成的 list
?continuous_cols = {k: tf.constant(df[k].values) for k in CONTINUOUS_COLUMNS}
?// tf.SparseTensor 構(gòu)建 sparse tensor,SparseTensor 由 indices,values, dense_shape 三
?// 個 dense tensor 構(gòu)成,indices 中記錄非零元素在 sparse tensor 的位置,values 是
?// indices 中每個位置的元素的值,dense_shape 指定 sparse tensor 中每個維度的大小
?// 以下代碼為每個 category column 構(gòu)建一個 [df[k].size,1] 的二維的 SparseTensor。
?categorical_cols = {?
?k: tf.SparseTensor( indices=[[i, 0] for i in range(df[k].size)],
?values=df[k].values,
?dense_shape=[df[k].size, 1])
?for k in CATEGORICAL_COLUMNS
?}
?// 可以用以下示意圖來表示以上代碼構(gòu)建的 sparse tensor

?// label 是一個 constant tensor,記錄每個實例的 label
?label = tf.constant(df[LABEL_COLUMN].values)
?// features 是 continuous_cols 和 categorical_cols 的 union 構(gòu)成的 dict
?// dict 中每個 entry 的 key 是 feature column 的 name,value 是 feature column 值的 tensor
?return features, label
輸出
模型通過 export 輸出到一個指定目錄,tensorflow serving 從該目錄加載模型提供在線預(yù)測服務(wù):m.export(export_dir=export_dir,input_fn = export._default_input_fn?
use_deprecated_input_fn=True,signature_fn=signature_fn)?
input_fn 函數(shù)定義生成模型 servable 實例的特征,signature_fn 函數(shù)定義模型輸入輸出的 signature。?
由于在 TensorFlow1.0 之后 export 已經(jīng) deprecate,需要用 export_savedmodel 來替代,所以本文就不對 export 進(jìn)行更多講解,只在文末給出我們是如何使用它的,建議所有使用者以后切換到的 API。
模型詳解
wide and deep 模型是基于 TF.learn API 來實現(xiàn)的,其源代碼實現(xiàn)主要在 tensorflow.contrib.learn.python.learn.estimators 中。以分類模型為例,wide 與 deep 結(jié)合的分類模型對應(yīng)的類是 DNNLinearCombinedClassifier,實現(xiàn)在源文件 dnn_linear_combined.py。我們先看看 DNNLinearCombinedClassifier 的初始化函數(shù)的完整定義,看構(gòu)造一個 wide and deep 模型可以輸入哪些參數(shù):
def __init__(self, model_dir=None, n_classes=2, weight_column_name=None, linear_feature_columns=None,
?linear_optimizer=None, joint_linear_weights=False, dnn_feature_columns=None,?
?dnn_optimizer=None, dnn_hidden_units=None, dnn_activation_fn=nn.relu, dnn_dropout=None,
?gradient_clip_norm=None, enable_centered_bias=False, config=None,
?feature_engineering_fn=None, embedding_lr_multipliers=None):
我們可以將類的構(gòu)造函數(shù)中的參數(shù)分為以下幾組
基礎(chǔ)參數(shù)
model_dir?
我們訓(xùn)練的模型存放到 model_dir 指定的目錄中。如果我們需要用 tensorboard 來 DEBUG 模型,將 tensorboard 的 logdir 指向該目錄即可:tensorboard –logdir=$model_dir
n_classes?
分類數(shù)。默認(rèn)是二分類,>2 則進(jìn)行多分類。
weight_column_name?
定義每個訓(xùn)練樣本的權(quán)重。訓(xùn)練時每個訓(xùn)練樣本的訓(xùn)練誤差乘以該樣本的權(quán)重然后用于權(quán)重更新梯度的計算。如果需要為每個樣本指定權(quán)重,input_fn 返回的 features 里需要包含一個以 weight_column_name 為列名的列,該列的長度為訓(xùn)練樣本的數(shù)目,列中每個元素對應(yīng)一個樣本的權(quán)重,數(shù)據(jù)類型是 float,如以下偽代碼:
weight = tf.constant(df[WEIGHT_COLUMN_NAME].values, dtype=float32);
?features[weight_column_name] = weight
config?
指定運行時配置參數(shù)
eature_engineering_fn?
對輸入函數(shù) input_fn 輸出的 (features, label) 進(jìn)行后處理生成新的 (features』, label』) 然后輸入給模型訓(xùn)練函數(shù) model_fn 使用。
call_model_fn():
?feature, labels = self._feature_engineering_fn(feature, labels)?
線性模型相關(guān)參數(shù)
linear_feature_columns?
線性模型的輸入特征
linear_optimizer?
線性模型的優(yōu)化函數(shù),定義權(quán)重的梯度更新算法,默認(rèn)采用 FTRL。所有默認(rèn)支持的 linear_optimizer 和 dnn_optimizer 可以在 optimizer.py 的 OPTIMIZER_CLS_NAMES 變量中找到相關(guān)定義。
join_linear_weights?
按照代碼中的注釋,如果 join_linear_weights= true,線性模型的權(quán)重會存放在一個 tf.Variable 中,可以加快訓(xùn)練,但是 linear_feature_columns 中的特征列必須都是 sparse feature column 并且每個 feature column 的 combiner 必須是“sum”。經(jīng)過自己線下的對比試驗,對模型的預(yù)測能力似乎沒有太大影響,對訓(xùn)練速度有所提升,最終訓(xùn)練模型時我們保持了默認(rèn)值。
DNN 模型相關(guān)參數(shù)
dnn_feature_columns?
DNN 模型的輸入特征
dnn_optimizer?
DNN 模型的優(yōu)化函數(shù),定義各層權(quán)重的梯度更新算法,默認(rèn)采用 Adagrad。
dnn_hidden_units?
每個隱藏層的神經(jīng)元數(shù)目
dnn_activation_fn?
隱藏層的激活函數(shù),默認(rèn)采用 RELU
dnn_dropout?
模型訓(xùn)練中隱藏層單元的 drop_out 比例
gradient_clip_norm?
定義 gradient clipping,對梯度的變化范圍做出限制,防止 gradient vanishing 或 gradient explosion。wide and deep 中默認(rèn)采用 tf.clip_by_global_norm。
embedding_lr_multipliers?
embedding_feature_column 到 float 的一個 mapping。對指定的 embedding feature column 在計算梯度時乘以一個常數(shù)因子,調(diào)整梯度的變化速率。
看完模型的構(gòu)造函數(shù)后,我們大概知道 wide 和 deep 端的模型各對應(yīng)什么樣的模型,模型需要輸入什么樣的參數(shù)。為了更深入了解模型,以下我們對 wide and deep 模型的相關(guān)代碼進(jìn)行了分析,力求解決如下疑問: (1) 分別用于線性模型和 DNN 模型訓(xùn)練的特征是如何定義的,其內(nèi)部如何實現(xiàn);(2) 訓(xùn)練中線性模型和 DNN 模型如何進(jìn)行聯(lián)合訓(xùn)練,訓(xùn)練誤差如何反饋給 wide 模型和 deep 模型?下面我們重點針對特征和模型訓(xùn)練這兩方面進(jìn)行解讀。
特征
wide and deep 模型訓(xùn)練一般是以多個訓(xùn)練樣本作為 1 個批次 (batch) 進(jìn)行訓(xùn)練,訓(xùn)練樣本在行維度上定義,每一行對應(yīng)一個訓(xùn)練樣本實例,包括特征(feature column),標(biāo)注(label)以及權(quán)重(weight),如圖 2。特征在列維度上定義,每個特征對應(yīng) 1 個 feature column,feature column 由在列維度上的 1 個或者若干個張量 (tensor) 組成,tensor 中的每個元素對應(yīng)一個樣本在該 feature column 上某個維度的值。feature column 的定義在可以在源代碼的 feature_column.py 文件中找到,對應(yīng)類為_FeatureColumn,該類定義了基本接口,是 wide and deep 模型中所有特征類的抽象父類。
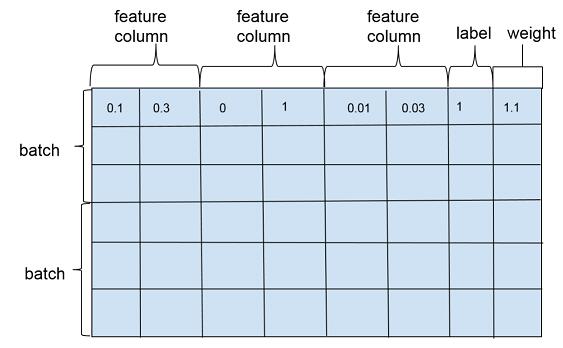
圖 2 feature_column, label, weight 示意圖
wide and deep 模型中使用的特征包括兩大類: 一類是連續(xù)型特征,主要用于 deep 模型的訓(xùn)練,包括 real value 類型的特征以及 embedding 類型的特征等;一類是離散型特征,主要用于 wide 模型的訓(xùn)練,包括 sparse 類型的特征以及 cross 類型的特征等。以下是所有特征的一個匯總圖
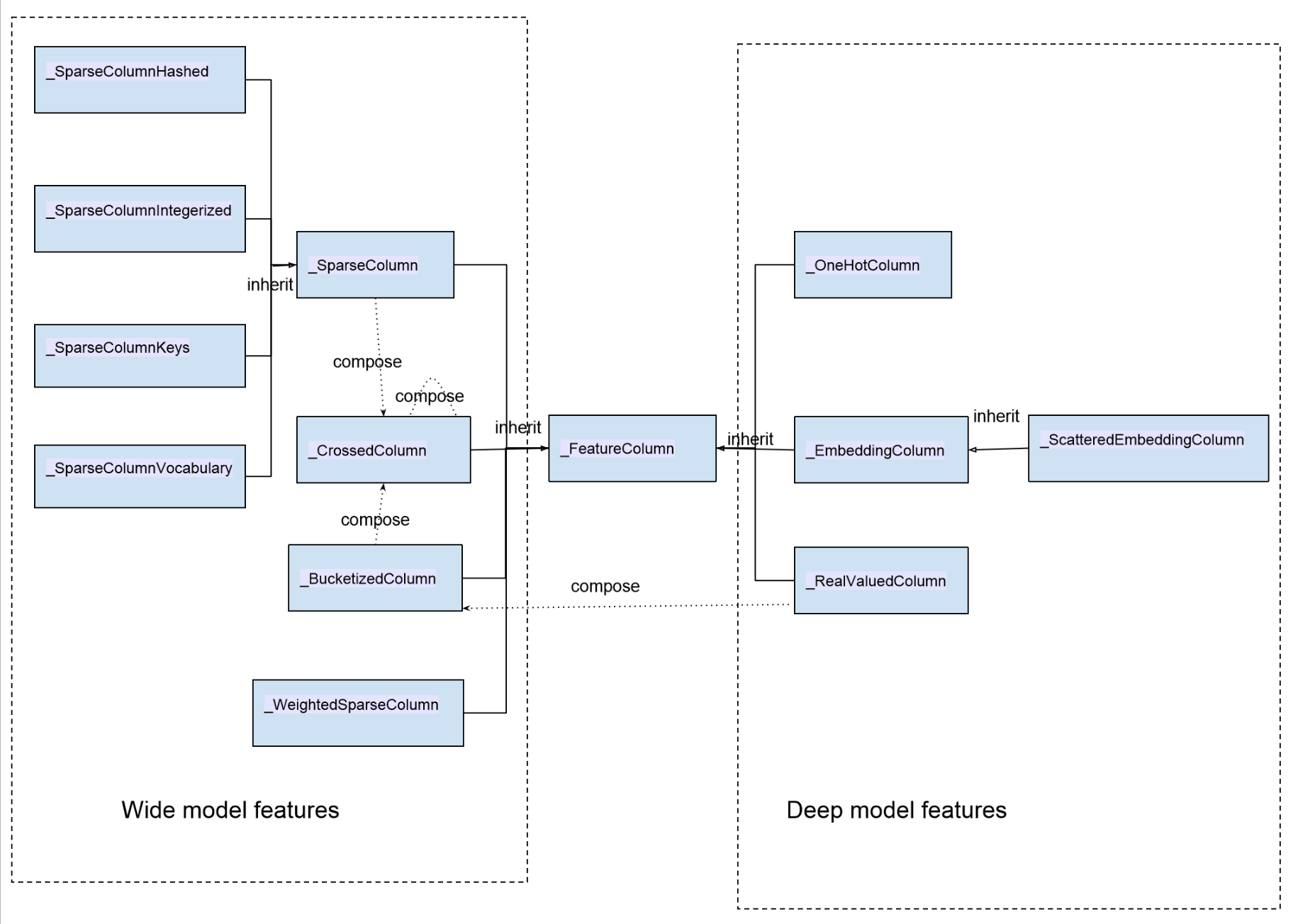
圖 3 wide and deep 模型特征類圖
圖中類與類的關(guān)系除了 inherit(繼承)之外,同時我們也標(biāo)出了特征類之間的構(gòu)成關(guān)系:_BucketizedColumn 由_RealValueColumn 通過對連續(xù)值域進(jìn)行分桶構(gòu)成,_CrossedColumn 由若干_SparseColumn 或者_(dá)BucketizedColumn 或者_(dá)CrossedColumn 經(jīng)過交叉組合構(gòu)成。圖中左邊部分特征屬于離散型特征,右邊部分特征屬于連續(xù)型特征。
我們在實際使用的時候,通常情況下是調(diào)用 TensorFlow 提供的接口來構(gòu)建特征的。以下是構(gòu)建各類特征的接口:
sparse_column_with_integerized_feature() --> _SparseColumnIntegerized
sparse_column_with_hash_bucket() --> _SparseColumnHashed
sparse_column_with_keys() --> _SparseColumnKeys
sparse_column_with_vocabulary_file() --> _SparseColumnVocabulary
weighted_sparse_column() --> _WeightedSparseColumn
one_hot_column() --> _OneHotColumn
embedding_column() --> _EmbeddingColumn
shared_embedding_columns() --> List[_EmbeddingColumn]
scattered_embedding_column() --> _ScatteredEmbeddingColumn
real_valued_column() --> _RealValuedColumn
bucketized_column() -->_BucketizedColumn
crossed_column() --> _CrossedColumn
FeatureColumn 為模型訓(xùn)練定義了幾個基本接口用于提取和轉(zhuǎn)換特征,在后面講解具體 feature 時會有具體描述:
def insert_transformed_feature(self, columns_to_tensors):?
“”“Apply transformation and inserts it into columns_to_tensors.?
FeatureColumn 的特征輸出和轉(zhuǎn)換函數(shù)。columns_to_tensor 是 FeatureColumn 到 tensors 的映射。
def _to_dnn_input_layer(self, input_tensor, weight_collection=None, trainable=True, output_rank=2):?
“”“Returns a Tensor as an input to the first layer of neural network.”“”?
構(gòu)建 DNN 的 float tensor 輸入,參見后面對 RealValuedColumn 的講解。
def _deep_embedding_lookup_arguments(self, input_tensor):?
“”“Returns arguments to embedding lookup to build an input layer.”“”?
構(gòu)建 DNN 的 embedding 輸入,參見后面對 EmbeddingColumn 的講解。
def _wide_embedding_lookup_arguments(self, input_tensor):?
“”“Returns arguments to look up embeddings for this column.”“”?
構(gòu)建線性模型的輸入,參見后面對 SparseColumn 的講解。
我們從離散型的特征(sparse 特征)開始分析。離散型特征可以看做由若干鍵值構(gòu)成的特征,比如用戶的性別。在實際實現(xiàn)中,每一個鍵值在 sparse column 內(nèi)部對應(yīng)一個整數(shù) id。離散特征的基類是_SparseColumn:
class _SparseColumn(_FeatureColumn,
?collections.namedtuple("_SparseColumn",
?["column_name", "is_integerized",
?"bucket_size", "lookup_config",
?"combiner", "dtype"])):
collections.namedtuple 中的字符串?dāng)?shù)組是_SparseColumn 從對應(yīng)的創(chuàng)建接口函數(shù)中接收的輸入?yún)?shù)的名稱。
def __new__(cls,
?column_name,
?is_integerized=False,
?bucket_size=None,
?lookup_config=None,
?combiner="sum",
?dtype=dtypes.string):
SparseFeature 是如何存放這些離散取值的呢?這個跟 bucket_size 和 lookup_config 這兩個參數(shù)相關(guān)。在實際定義中,有且只定義其中一個參數(shù)。通過使用哪一個參數(shù)我們可以把 sparse feature 分成兩類,定義 lookup_config 參數(shù)的特征使用一個 in memory 的字典存儲 feature 的所有取值,包括后面會講到的_SparseColumnKeys,_SparseColumnVocabulary;定義 bucket_size 參數(shù)的特征使用一個哈希表來存儲特征值,特征值通過哈希函數(shù)散列到各個桶,包括_SparseColumnHashed 和_SparseColumnIntegerized(is_integerized = True)。
dtype 指定特征值的類型,除了字符串類型 (dtypes.string)之外,spare feature column 還支持 64 位整數(shù)類型(dtypes.int64),默認(rèn)我們認(rèn)為輸入的離散特征是字符串,如果我們定義了 is_integerized = True,那么我們認(rèn)為特征是一個整型的 id 型特征,我們可以直接用特征的取值作為特征的 id,而不需要建立一個專門的映射。
combiner 參數(shù)對應(yīng)的是樣本維度特征的歸一化,如果特征列在單個樣本上有多個取值,combiner 參數(shù)指定如何對單個樣本上特征的多個取值進(jìn)行歸一化。源代碼注釋中是這樣寫的:「combiner: A string specifying how to reduce if the sparse column is multivalent」,multivalent 的具體含義在 crossed feature column 的定義中有一個稍微清楚的解釋(combiner: A string specifying how to reduce if there are multiple entries in a single row)。combiner 可以指定 3 種歸一化方式:sum 對應(yīng)無歸一化,sqrtn 對應(yīng) L2 歸一化,mean 對應(yīng) L1 歸一化。通常情況下采用 L2 歸一化,模型的準(zhǔn)確度相對會更高。
SparseColumn 不能直接作為 DNN 的輸入,它只能用于直接構(gòu)建線性模型的輸入:
?def _wide_embedding_lookup_arguments(self, input_tensor):
?return _LinearEmbeddingLookupArguments( input_tensor=self.id_tensor(input_tensor),
?weight_tensor=self.weight_tensor(input_tensor),
?vocab_size=self.length,
?initializer=init_ops.zeros_initializer(),
?combiner=self.combiner)
_LinearEmbeddingLookupArguments 是一個 namedtuple(A new subclass of tuple with named fields)。input_tensor 是訓(xùn)練樣本集中特征的 id 構(gòu)成的數(shù)組,weight_tensor 中每個元素對應(yīng)一個樣本中該特征的權(quán)重,vocab_size 是特征取值的個數(shù),intiializer 是特征初始化的函數(shù),默認(rèn)初始化為 0。
不過看源代碼中_SparseColumn 及其子類并沒有使用特征權(quán)重:
?def weight_tensor(self, input_tensor):
?"""Returns the weight tensor from the given transformed input_tensor."""
?return None
如果需要為_SparseColumn 的特征賦予權(quán)重,可以使用_WeightedSparseColumn,構(gòu)造接口函數(shù)為 weighted_sparse_column(Create a _SparseColumn by combing sparse_id_column and weight_column)
class _WeightedSparseColumn(_FeatureColumn, collections.namedtuple(
?"_WeightedSparseColumn",["sparse_id_column", "weight_column_name", "dtype"])):
?def __new__(cls, sparse_id_column, weight_column_name, dtype):
?return super(_WeightedSparseColumn, cls).__new__(cls, sparse_id_column, weight_column_name, dtype)
_WeightedSparseColumn 需要 3 個參數(shù):sparse_id_column 對應(yīng) sparse feature column,是_SparseColumn 類型的對象,weight_column_name 為輸入中對應(yīng) sparse_id_column 的 weight column(input_fn 返回的 features dict 中需要有一個 weight_column_name 的 tensor)dtype 是 weight column 中每個元素的數(shù)據(jù)類型。這里有幾個隱含要求:
(1)dtype 需要能夠轉(zhuǎn)換成浮點數(shù)類型,否則會拋 TypeError;?
(2)weight_column_name 對應(yīng)的 weight column 可以是一個 SparseTensor,也可以是一個常規(guī)的 dense tensor,程序會將 dense tensor 轉(zhuǎn)換成 SparseTensor,但是要求 weight column 最終對應(yīng)的 SparseTensor 與 sparse_id_column 的 SparseTensor 有相同的索引 (indices) 和維度 (dense_shape)。
_WeightedSparseColumn 輸出特征的 id tensor 和 weight tensor 的函數(shù)如下:
def insert_transformed_feature(self, columns_to_tensors):
?"""Inserts a tuple with the id and weight tensors."""
?if self.sparse_id_column not in columns_to_tensors:
?self.sparse_id_column.insert_transformed_feature(columns_to_tensors)
?weight_tensor = columns_to_tensors[self.weight_column_name]
?if not isinstance(weight_tensor, sparse_tensor_py.SparseTensor):
?# The weight tensor can be a regular Tensor. In such case, sparsify it.
?// 我們輸入的 weight tensor 可以是一個常規(guī)的 Tensor,如通過 tf.Constants 構(gòu)建的 tensor,
?// 這種情況下,會調(diào)用 dense_to_sparse_tensor 將 weight_tensor 轉(zhuǎn)換成 SparseTensor。
?weight_tensor = contrib_sparse_ops.dense_to_sparse_tensor(weight_tensor)
?// 最終使用的 weight_tensor 的數(shù)據(jù)類型是 float
?if not self.dtype.is_floating:
?weight_tensor = math_ops.to_float(weight_tensor)
?// 返回中對應(yīng)該 WeightedSparseColumn 的一個二元組,二元組的第一個元素是 SparseFeatureColumn 調(diào)用?
?// insert_transformed_feature 后的 id_tensor,第二個元素是 weight tensor。
?columns_to_tensors[self] = tuple([columns_to_tensors[self.sparse_id_column],weight_tensor])
def id_tensor(self, input_tensor):
?"""Returns the id tensor from the given transformed input_tensor."""
?return input_tensor[0]
def weight_tensor(self, input_tensor):
?"""Returns the weight tensor from the given transformed input_tensor."""
?return input_tensor[1]
(1)sparse column from keys
這個是最簡單的離散特征,類比于枚舉類型,一般用于枚舉的值不是太多的情況。創(chuàng)建基于 keys 的 sparse 特征的接口是 sparse_column_with_keys(column_name, keys, default_value=-1, combiner=None),對應(yīng)類是 SparseColumnKeys,構(gòu)造函數(shù)為:
def __new__(cls, column_name, keys, default_value=-1, combiner="sum"):
?return super(_SparseColumnKeys, cls).__new__(cls, column_name, combiner=combiner,
?lookup_config=_SparseIdLookupConfig(keys=keys, vocab_size=len(keys),
?default_value=default_value), dtype=dtypes.string)
keys 為一個字符串列表,定義了所有的枚舉值。構(gòu)造特征輸入的 keys 最后存儲在 lookup_config 里面,每個 key 的類型是 string,并且對應(yīng) 1 個 id,id 是該 key 在輸入的 keys 數(shù)組中的下標(biāo)。在模型實際訓(xùn)練中使用的是每個 key 對應(yīng)的 id。
SparseColumnKeys 輸入到模型前需要將枚舉值的 key 轉(zhuǎn)換到相應(yīng)的 id,這個轉(zhuǎn)換工作在函數(shù) insert_transformed_feature 中實現(xiàn):
def insert_transformed_feature(self, columns_to_tensors):
?"""Handles sparse column to id conversion."""
?input_tensor = self._get_input_sparse_tensor(columns_to_tensors)
?""""Returns a lookup table that converts a string tensor into int64 IDs.This operation constructs a lookup table?
?to convert tensor of strings into int64 IDs. The mapping can be initialized from a string `mapping` 1-D?
?tensor where each element is a key and corresponding index within the tensor is the
?value.
?"""
?table = lookup.index_table_from_tensor(mapping=tuple(self.lookup_config.keys),
?default_value=self.lookup_config.default_value, dtype=self.dtype, name="lookup")
?columns_to_tensors[self] = table.lookup(input_tensor)
(2)sparse column from vocabulary file
sparse column with keys 一般枚舉都能滿足,如果枚舉的值多了就不合適了,所以提供了一個從文件加載枚舉變量的接口:
sparse_column_with_vocabulary_file((column_name, vocabulary_file, num_oov_buckets=0, vocab_size=None,
default_value=-1, combiner="sum",dtype=dtypes.string)
對應(yīng)的構(gòu)造函數(shù)為:
def __new__(cls, column_name, vocabulary_file, num_oov_buckets=0, vocab_size=None, default_value=-1,
?combiner="sum", dtype=dtypes.string):
那么從文件中讀入的特征值是存哪里呢?看看這個構(gòu)造函數(shù)最后返回的類實例:
return super(_SparseColumnVocabulary, cls).__new__(cls, column_name,combiner=combiner,
lookup_config=_SparseIdLookupConfig(vocabulary_file=vocabulary_file,num_oov_buckets=num_oov_buckets,
vocab_size=vocab_size,default_value=default_value), dtype=dtype)
如同_SparseColumnKeys,這個特征也使用了_SparseIdLookupConfig 來存儲特征值,vocabulary_file 指向定義枚舉值的文件,vocabulary_file 每一行對應(yīng)一個枚舉值,每個枚舉值的 id 是該枚舉值所在行號(注意,行號是從 0 開始的),vocab_size 定義枚舉值的個數(shù)。_SparseIdLookupConfig 從特征文件中構(gòu)建一個特征值到 id 的哈希表,我們看看 SparseColumnVocabulary 進(jìn)行 vocabulary 到 id 的轉(zhuǎn)換時如何使用_SparseIdLookupConfig 對象。
def insert_transformed_feature(self, columns_to_tensors):
?"""Handles sparse column to id conversion."""
?st = self._get_input_sparse_tensor(columns_to_tensors)
?if self.dtype.is_integer:
?// 輸入的整數(shù)數(shù)值型特征轉(zhuǎn)換成字符串形式
?sparse_string_values = string_ops.as_string(st.values)
?sparse_string_tensor = sparse_tensor_py.SparseTensor(st.indices,sparse_string_values, st.dense_shape)
?else:
?sparse_string_tensor = st
?"""Returns a lookup table that converts a string tensor into int64 IDs.This operation constructs a lookup table?
?to convert tensor of strings into int64 IDs. The mapping can be initialized from a vocabulary file specified in
?`vocabulary_file`, where the whole line is the key and the zero-based line number is the ID.
?table = lookup.index_table_from_file(vocabulary_file=self.lookup_config.vocabulary_file,?
?num_oov_buckets=self.lookup_config.num_oov_buckets,vocab_size=self.lookup_config.vocab_size,
?default_value=self.lookup_config.default_value, name=self.name + "_lookup")
?columns_to_tensors[self] = table.lookup(sparse_string_tensor)
index_table_from_file 函數(shù)從 lookup_config 的字典文件中構(gòu)建 table。Table 變量是一個 string 到 int64 的 HashTable,如果定義了 num_oov_buckets,table 是 IdTableWithHashBuckets 對象(a string to id wrapper that assigns out-of-vocabulary keys to buckets)。
(3)sparse column with hash bucket
如果沒有 vocab 文件定義枚舉特征,我們可以使用 hash bucket 特征,使用該特征的接口是?
sparse_column_with_hash_bucket(column_name,hash_bucket_size, combiner=None,dtype=dtypes.string)?
對應(yīng)類_SparseColumnHashed 的構(gòu)造函數(shù)為:def new(cls, column_name, hash_bucket_size, combiner=”sum”, dtype=dtypes.string):
ash_bucket_size 定義哈希桶的個數(shù),用于哈希值取模。dtype 支持整數(shù)和字符串。實際計算哈希值的時候是將整數(shù)轉(zhuǎn)換成對應(yīng)的字符串表示形式,用字符串計算哈希值然后取模,轉(zhuǎn)換后的特征值是 0 到 hash_bucket_size 的一個整數(shù)。
def insert_transformed_feature(self, columns_to_tensors):
?"""Handles sparse column to id conversion."""
?input_tensor = self._get_input_sparse_tensor(columns_to_tensors)
?if self.dtype.is_integer:
?// 整數(shù)類型的輸入轉(zhuǎn)換成字符串類型
?sparse_values = string_ops.as_string(input_tensor.values)
?else:
?sparse_values = input_tensor.values
?sparse_id_values = string_ops.string_to_hash_bucket_fast(sparse_values, self.bucket_size, name="lookup")
?// Sparse 特征的哈希值作為特征值對應(yīng)的 id 返回
?columns_to_tensors[self] = sparse_tensor_py.SparseTensor(input_tensor.indices, sparse_id_values,
?input_tensor.dense_shape)
(4)integerized sparse column
hash bucket 的 sparse 特征取哈希值的時候是將整數(shù)看做字符串處理的,如果我們希望用整數(shù)本身的數(shù)值作為哈希值,可以使用_SparseColumnIntegerized,對應(yīng)的接口是
sparse_column_with_integerized_feature:
?def sparse_column_with_integerized_feature(column_name,hash_bucket_size,combiner="sum",
?dtype=dtypes.int64)
對應(yīng)的類是_SparseColumnIntegerized:?
def __new__(cls, column_name, bucket_size, combiner="sum", dtype=dtypes.int64)
特征的轉(zhuǎn)換函數(shù)定義:
def insert_transformed_feature(self, columns_to_tensors):
?"""Handles sparse column to id conversion."""
?input_tensor = self._get_input_sparse_tensor(columns_to_tensors)
?// 直接對特征值取模,取模后的值作為特征值的 id
?sparse_id_values = math_ops.mod(input_tensor.values, self.bucket_size, name="mod")
?columns_to_tensors[self] = sparse_tensor_py.SparseTensor( input_tensor.indices, sparse_id_values,?
?input_tensor.dense_shape)
(5)crossed column
Crossed column 支持 1 個以上的離散型 feature column 進(jìn)行笛卡爾積,組成高維度的交叉特征。特征之間進(jìn)行交叉,可以將特征之間的相關(guān)性引入模型,增強模型的表達(dá)能力。crossed column 僅支持以下 3 種離散特征的交叉組合: _SparsedColumn, _BucketizedColumn 和_CrossedColumn,其接口定義為:
def crossed_column(columns,hash_bucket_size, combiner=」sum」,ckpt_to_load_from=None,
?tensor_name_in_ckpt=None, hash_key=None)
對應(yīng)類為_CrossedColumn:
def __new__(cls, columns,hash_bucket_size,hash_key, combiner="sum",ckpt_to_load_from=None,?
?tensor_name_in_ckpt=None):
columns 對應(yīng)一個 feature column 的集合,如 tutorial 中的例子:[age_buckets, education, occupation];hash_bucket_size 參數(shù)指定 hash bucket 的桶個數(shù),特征交叉的組合個數(shù)越多,hash_bucket_size 也應(yīng)相應(yīng)增加,從而減小哈希沖突。
交叉特征生成模型輸入的邏輯可以分為如下兩步:
def insert_transformed_feature(self, columns_to_tensors):
?"""Handles cross transformation."""
?def _collect_leaf_level_columns(cross):
?"""Collects base columns contained in the cross."""
?leaf_level_columns = []
?for c in cross.columns:
?// 對 CrossedColumn 類型的 feature column 進(jìn)行遞歸展開
?if isinstance(c, _CrossedColumn):
?leaf_level_columns.extend(_collect_leaf_level_columns(c))
?else:
?// SparseColumn 和 BucketizedColumn 作為葉子節(jié)點
?leaf_level_columns.append(c)
?return leaf_level_columns
?// 步驟 1: 將 crossed column 中的所有特征進(jìn)行遞歸展開,展開后的特征值存放在 feature_tensors 數(shù)組中
?feature_tensors = []
?for c in _collect_leaf_level_columns(self):
?if isinstance(c, _SparseColumn):
?feature_tensors.append(columns_to_tensors[c.name])
?else:
?if c not in columns_to_tensors:
?c.insert_transformed_feature(columns_to_tensors)
?if isinstance(c, _BucketizedColumn):
?feature_tensors.append(c.to_sparse_tensor(columns_to_tensors[c]))
?else:
?feature_tensors.append(columns_to_tensors[c])
// 步驟 2: 生成 cross feature 的 tensor,sparse_feature_cross 通過動態(tài)庫調(diào)用 SparseFeatureCross 函數(shù),函數(shù)接
//口可參見 sparse_feature_cross_op.cc
?columns_to_tensors[self] = sparse_feature_cross_op.sparse_feature_cross(feature_tensors,?
?hashed_output=True,num_buckets=self.hash_bucket_size,hash_key=self.hash_key, name="cross")
在源代碼該部分的注釋中有一個例子說明 feature column 進(jìn)行 cross 后的效果,我們用 1 個圖來將這部分注釋展示的更明確點:
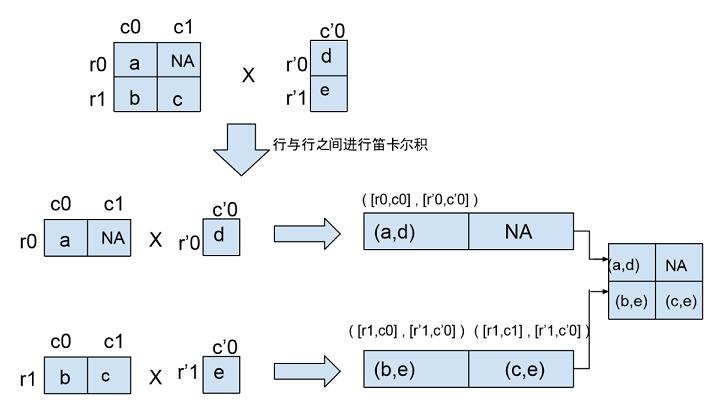
圖 4 feature column 進(jìn)行 cross 后的效果圖
需要指出的一點是:交叉特征是沒有權(quán)重定義的。
對離散特征進(jìn)行交叉組合在預(yù)測模型中使用比較廣泛,但是該類特征的一個局限性是它對訓(xùn)練數(shù)據(jù)中沒有見過的特征組合泛化能力有限,后面我們談到的 embedding column 則是通過構(gòu)建離散特征的低維向量表示,強化離散特征的泛化能力。
(6)real valued column
real valued feature column 對應(yīng)連續(xù)型數(shù)值特征,接口為
real_valued_column(column_name, dimension=1, default_value=None, dtype=dtypes.float32,normalizer=None):
對應(yīng)類為_RealValuedColumn:
_RealValuedColumn(column_name, dimension, default_value, dtype,normalizer)
dimension 指定 feature column 的維度,默認(rèn)值為 1,即 1 維浮點數(shù)數(shù)組。dimension 也可以取大于 1 的整數(shù),對應(yīng)多維數(shù)組。rea valued column 的特征取值類型可以是 float32 或者 int,int 類型在輸入到模型之前會轉(zhuǎn)換成 float 類型。normalizer 定義在一批訓(xùn)練樣本實例中,特征在列維度的歸一化,相當(dāng)于 column-level normalization。這個同 sparse feature column 的 combiner 不同,combiner 定義的是離散特征在單個樣本維度的歸一化(example-level normalization),以下示意圖舉了個例子來說明兩者的區(qū)別:
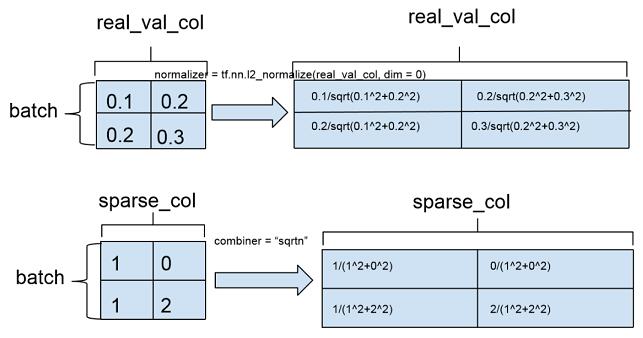
圖 5 combiner 與 normalizer 的區(qū)別
normalizer 在 real valued feature column 輸入 DNN 時調(diào)用:
def insert_transformed_feature(self, columns_to_tensors):
?# Transform the input tensor according to the normalizer function.
?// _normalized_input_tensor 調(diào)用的是構(gòu)造 real valued colum 時傳入的 normalizer 函數(shù)
?input_tensor = self._normalized_input_tensor(columns_to_tensors[self.name])
?columns_to_tensors[self] = math_ops.to_float(input_tensor)
real valued column 調(diào)用_to_dnn_input_layer 轉(zhuǎn)換為 DNN 的輸入。_to_dnn_input_layer 生成一個二維數(shù)組,數(shù)組的每一行是一個訓(xùn)練樣本的 real valued column 的特征值,該特征值與其他連續(xù)型特征拼接后構(gòu)成 DNN 的輸入層。
def _to_dnn_input_layer(self,input_tensor,weight_collections=None,trainable=True,output_rank=2):
?// DNN 的輸入必須是 dense tensor,sparse tensor 需要調(diào)用 to_dense_tensor 轉(zhuǎn)換成 dense tensor
?input_tensor = self._to_dense_tensor(input_tensor)
?if input_tensor.dtype != dtypes.float32:
?input_tensor = math_ops.to_float(input_tensor)
?// 調(diào)用 dense_inner_flatten(input_tensor, output_rank)。
?// output_rank = 2,輸出 [batch_size, real value column』s input dimension]
?return _reshape_real_valued_tensor(input_tensor, output_rank, self.name)
def _to_dense_tensor(self, input_tensor):
?if isinstance(input_tensor, sparse_tensor_py.SparseTensor):
?default_value = (self.default_value[0] if self.default_value is not None else 0)
?// Sparse tensor 轉(zhuǎn)換成 dense tensor
?return sparse_ops.sparse_tensor_to_dense(input_tensor, default_value=default_value)
?// real valued column 直接返回 input tensor
?return input_tensor
(7)bucketized column
連續(xù)型特征通過 bucketization 生成離散特征,連續(xù)特征離散化的優(yōu)點在網(wǎng)上有一些相關(guān)討論,比如餐館的距離對用戶選擇的影響,我們通常會將距離劃分為若干個區(qū)間,如 100 米以內(nèi),1 公里以內(nèi)等,這樣小幅度的距離差異不會對我們最終模型的預(yù)測造成太大影響,除非距離差異跨域了區(qū)間邊界。bucketized column 的接口定義為:def bucketized_column(source_column, boundaries) 對應(yīng)類為_BucketizedColumn,構(gòu)造函數(shù)定義:def new(cls, source_column, boundaries):source_column 必須是 real_valued_column,boundaries 是一個浮點數(shù)的列表,而且列表必須是遞增序的,比如 boundaries = [0, 100, 200] 定義了以下一組區(qū)間:(-INF,0),[0,100),[100,200),[200, INF)。
def insert_transformed_feature(self, columns_to_tensors):
?# Bucketize the source column.
?if self.source_column not in columns_to_tensors:
?self.source_column.insert_transformed_feature(columns_to_tensors)
?columns_to_tensors[self] = bucketization_op.bucketize(columns_to_tensors[self.source_column],
?boundaries=list(self.boundaries), name="bucketize")
bucketize 函數(shù)調(diào)用 tensorflow c++ core library 中的 BucketizeOp 類完成 feature 的 bucketization 功能。
(8)embedding column
sparse feature column 通過 embedding 轉(zhuǎn)換成連續(xù)型向量后可以作為 deep model 的輸入,前面談到了 cross column 的一個不足之處是在測試集合的泛化能力,通過 embedding column 將離散特征連續(xù)化,根據(jù)標(biāo)注學(xué)習(xí)特征的向量形式,如同矩陣分解中學(xué)習(xí)物品的隱含因子向量或者詞向量模型中單詞的詞向量。embedding column 的接口形式是:
def embedding_column(sparse_id_column, dimension, combiner=None, initializer=None,?
?ckpt_to_load_from=None,tensor_name_in_ckpt=None, max_norm=None, trainable=True)
對應(yīng)類為_EmbeddingColumn:
def __new__(cls,sparse_id_column,dimension,combiner="mean",initializer=None, ckpt_to_load_from=None,
?tensor_name_in_ckpt=None,shared_embedding_name=None, shared_vocab_size=None,max_norm=None,
?trainable = True):
sparse_id_column 是 SparseColumn 對象或者 WeightedSparseColumn 對象,dimension 是 embedding column 的向量維度。SparseColumn 的每個特征取值對應(yīng)一個整數(shù) id,該整數(shù) id 在 embedding column 中對應(yīng)一個 dimension 維度的浮點數(shù)向量。combiner 參數(shù)指定在單個樣本上對特征向量歸一化的方式,initializer 參數(shù)指定特征向量的初始化函數(shù),默認(rèn)按 truncated normal distribution 初始化 (mean = 0, stddev = 1/ sqrt(length of sparse id column))。max_norm 限定每個樣本特征向量做 L2 歸一化后的較大值:embedding_vector = embedding_vector * max_norm / L2_norm(embedding_vector)。
為了進(jìn)一步理解 embedding column,我們可以畫一個簡易圖:
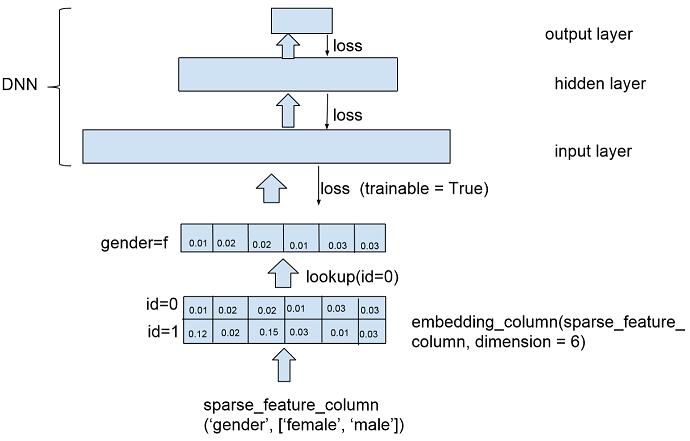
圖 6 embedding feature column 示意圖
作者簡介:汪劍,現(xiàn)在在出門問問負(fù)責(zé)推薦與個性化。曾在微軟雅虎工作,從事過搜索和推薦相關(guān)工作。?
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價值的辦法,實際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/4609.html
摘要:機器學(xué)習(xí)深度學(xué)習(xí)與自然語言處理領(lǐng)域推薦的書籍列表人工智能深度學(xué)習(xí)與相關(guān)書籍課程示例列表是筆者系列的一部分對于其他的資料集錦模型開源工具與框架請參考。 showImg(https://segmentfault.com/img/remote/1460000014946199); DataScienceAI Book Links | 機器學(xué)習(xí)、深度學(xué)習(xí)與自然語言處理領(lǐng)域推薦的書籍列表 sho...

閱讀 1922·2021-10-11 10:59
閱讀 1032·2021-09-07 09:59
閱讀 2225·2021-08-27 16:17
閱讀 2782·2019-08-30 15:54
閱讀 2273·2019-08-30 12:58
閱讀 1772·2019-08-30 12:53
閱讀 1464·2019-08-28 18:13
閱讀 732·2019-08-26 13:35


