資訊專欄INFORMATION COLUMN

摘要:為了更好地為機器學習或深度學習提供先驗知識,知識圖譜的表示學習仍是一項任重道遠的研究課題。
肖仰華:復旦大學計算機科學技術學院,副教授,博士生導師,上海市互聯網大數據工程技術中心副主任。主要研究方向為大數據管理與挖掘、知識庫等。
大數據時代的到來,為人工智能的飛速發展帶來前所未有的數據紅利。在大數據的“喂養”下,人工智能技術獲得了前所未有的長足進步。其進展突出體現在以知識圖譜為代表的知識工程以及深度學習為代表的機器學習等相關領域。隨著深度學習對于大數據的紅利消耗殆盡,深度學習模型效果的天花板日益迫近。另一方面大量知識圖譜不斷涌現,這些蘊含人類大量先驗知識的寶庫卻尚未被深度學習有效利用。融合知識圖譜與深度學習,已然成為進一步提升深度學習模型效果的重要思路之一。以知識圖譜為代表的符號主義、以深度學習為代表的聯結主義,日益脫離原先各自獨立發展的軌道,走上協同并進的新道路。
知識圖譜與深度學習融合的歷史背景
大數據為機器學習,特別是深度學習帶來前所未有的數據紅利。得益于大規模標注數據,深度神經網絡能夠習得有效的層次化特征表示,從而在圖像識別等領域取得優異效果。但是隨著數據紅利消失殆盡,深度學習也日益體現出其局限性,尤其體現在依賴大規模標注數據和難以有效利用先驗知識等方面。這些局限性阻礙了深度學習的進一步發展。另一方面在深度學習的大量實踐中,人們越來越多地發現深度學習模型的結果往往與人的先驗知識或者專家知識相沖突。如何讓深度學習擺脫對于大規模樣本的依賴?如何讓深度學習模型有效利用大量存在的先驗知識?如何讓深度學習模型的結果與先驗知識一致已成為了當前深度學習領域的重要問題。
當前,人類社會業已積累大量知識。特別是,近幾年在知識圖譜技術的推動下,對于機器友好的各類在線知識圖譜大量涌現。知識圖譜本質上是一種語義網絡,表達了各類實體、概念及其之間的語義關系。相對于傳統知識表示形式(諸如本體、傳統語義網絡),知識圖譜具有實體/概念覆蓋率高、語義關系多樣、結構友好(通常表示為RDF格式)以及質量較高等優勢,從而使得知識圖譜日益成為大數據時代和人工智能時代更為主要的知識表示方式。能否利用蘊含于知識圖譜中的知識指導深度神經網絡模型的學習從而提升模型的性能,成為了深度學習模型研究的重要問題之一。
現階段將深度學習技術應用于知識圖譜的方法較為直接。大量的深度學習模型可以有效完成端到端的實體識別、關系抽取和關系補全等任務,進而可以用來構建或豐富知識圖譜。本文主要探討知識圖譜在深度學習模型中的應用。從當前的文獻來看,主要有兩種方式。一是將知識圖譜中的語義信息輸入到深度學習模型中;將離散化知識圖譜表達為連續化的向量,從而使得知識圖譜的先驗知識能夠成為深度學習的輸入。二是利用知識作為優化目標的約束,指導深度學習模型的學習;通常是將知識圖譜中知識表達為優化目標的后驗正則項。前者的研究工作已有不少文獻,并成為當前研究熱點。知識圖譜向量表示作為重要的特征在問答以及推薦等實際任務中得到有效應用。后者的研究才剛剛起步,本文將重點介紹以一階謂詞邏輯作為約束的深度學習模型。
知識圖譜作為深度學習的輸入
知識圖譜是人工智能符號主義近期進展的典型代表。知識圖譜中的實體、概念以及關系均采用了離散的、顯式的符號化表示。而這些離散的符號化表示難以直接應用于基于連續數值表示的神經網絡。為了讓神經網絡有效利用知識圖譜中的符號化知識,研究人員提出了大量的知識圖譜的表示學習方法。知識圖譜的表示學習旨在習得知識圖譜的組成元素(節點與邊)的實值向量化表示。這些連續的向量化表示可以作為神經網絡的輸入,從而使得神經網絡模型能夠充分利用知識圖譜中大量存在的先驗知識。這一趨勢催生了對于知識圖譜的表示學習的大量研究。本章首先簡要回顧知識圖譜的表示學習,再進一步介紹這些向量表示如何應用到基于深度學習模型的各類實際任務中,特別是問答與推薦等實際應用。
1.知識圖譜的表示學習
知識圖譜的表示學習旨在學習實體和關系的向量化表示,其關鍵是合理定義知識圖譜中關于事實(三元組< h,r,t >)的損失函數 ?r(h,t),其中和是三元組的兩個實體h和t的向量化表示。通常情況下,當事實 < h,r,t > 成立時,期望最小化 ?r(h,t)。考慮整個知識圖譜的事實,則可通過最小化
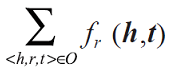
來學習實體以及關系的向量化表示,其中 O 表示知識圖譜中所有事實的集合。不同的表示學習可以使用不同的原則和方法定義相應的損失函數。這里以基于距離和翻譯的模型介紹知識圖譜表示的基本思路[1]。
基于距離的模型。其代表性工作是 SE 模型[2]。基本思想是當兩個實體屬于同一個三元組 < h,r,t > 時,它們的向量表示在投影后的空間中也應該彼此靠近。因此,損失函數定義為向量投影后的距離
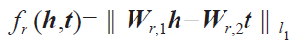
其中矩陣 Wr,1 和 Wr,2 用于三元組中頭實體 h 和尾實體 t 的投影操作。但由于 SE 引入了兩個多帶帶的投影矩陣,導致很難捕獲實體和關系之間的語義相關性。Socher 等人針對這一問題采用三階張量替代傳統神經網絡中的線性變換層來刻畫評分函數。Bordes 等人提出能量匹配模型,通過引入多個矩陣的 Hadamard 乘積來捕獲實體向量和關系向量的交互關系。
基于翻譯的表示學習。其代表性工作 TransE 模型通過向量空間的向量翻譯來刻畫實體與關系之間的相關性[3]。該模型假定,若 < h,r,t > 成立則尾部實體 t 的嵌入表示應該接近頭部實體 h 加上關系向量 r 的嵌入表示,即 h+r≈t。因此,TransE 采用
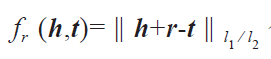
作為評分函數。當三元組成立時,得分較低,反之得分較高。TransE 在處理簡單的 1-1 關系(即關系兩端連接的實體數比率為 1:1)時是非常有效的,但在處理 N-1、1-N 以及 N-N 的復雜關系時性能則顯著降低。針對這些復雜關系,Wang 提出了 TransH 模型通過將實體投影到關系所在超平面,從而習得實體在不同關系下的不同表示。Lin 提出了 TransR 模型通過投影矩陣將實體投影到關系子空間,從而習得不同關系下的不同實體表示。
除了上述兩類典型知識圖譜表示學習模型之外,還有大量的其他表示學習模型。比如,Sutskever 等人使用張量因式分解和貝葉斯聚類來學習關系結構。Ranzato 等人引入了一個三路的限制玻爾茲曼機來學習知識圖譜的向量化表示,并通過一個張量加以參數化。
當前主流的知識圖譜表示學習方法仍存在各種各樣的問題,比如不能較好刻畫實體與關系之間的語義相關性、無法較好處理復雜關系的表示學習、模型由于引入大量參數導致過于復雜,以及計算效率較低難以擴展到大規模知識圖譜上等等。為了更好地為機器學習或深度學習提供先驗知識,知識圖譜的表示學習仍是一項任重道遠的研究課題。
2. 知識圖譜向量化表示的應用
應用 1 問答系統。自然語言問答是人機交互的重要形式。深度學習使得基于問答語料的生成式問答成為可能。然而目前大多數深度問答模型仍然難以利用大量的知識實現準確回答。Yin 等人針對簡單事實類問題,提出了一種基于 encoder-decoder 框架,能夠充分利用知識圖譜中知識的深度學習問答模型[4]。在深度神經網絡中,一個問題的語義往往被表示為一個向量。具有相似向量的問題被認為是具有相似語義。這是聯結主義的典型方式。另一方面,知識圖譜的知識表示是離散的,即知識與知識之間并沒有一個漸變的關系。這是符號主義的典型方式。通過將知識圖譜向量化,可以將問題與三元組進行匹配(也即計算其向量相似度),從而為某個特定問題找到來自知識庫的較佳三元組匹配。匹配過程如圖 1 所示。對于問題 Q:“How tallis Yao Ming?”,首先將問題中的單詞表示為向量數組 HQ。進一步尋找能與之匹配的知識圖譜中的候選三元組。最后為這些候選三元組,分別計算問題與不同屬性的語義相似度。其由以下相似度公式決定:
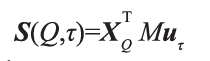
這里,S(Q,τ) 表示問題Q 與候選三元組τ 的相似度;xQ 表示問題的向量( 從HQ計算而得),uτ 表示知識圖譜的三元組的向量,M是待學習參數。
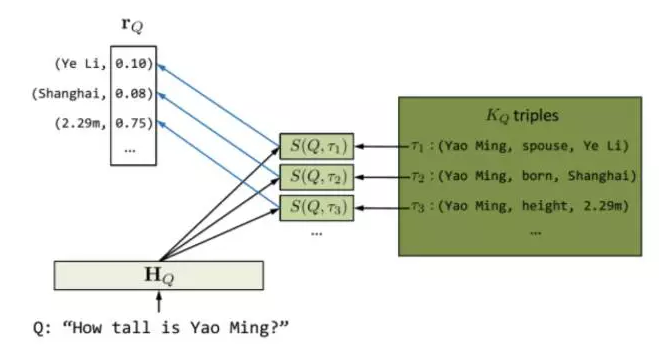
圖1 基于知識圖譜的神經生成問答模型
應用 2 推薦系統。
個性化推薦系統是互聯網各大社交媒體和電商網站的重要智能服務之一。隨著知識圖譜的應用日益廣泛,大量研究工作意識到知識圖譜中的知識可以用來完善基于內容的推薦系統中對用戶和項 ? ?目的內容(特征)描述,從而提升推薦效果。另一方面,基于深度學習的推薦算法在推薦效果上日益優于基于協同過濾的傳統推薦模型[5]。但是,將知識圖譜集成到深度學習的框架中的個性化推薦的研究工作,還較為少見。Zhang 等人做出了這樣的嘗試。作者充分利用了結構化知識(知識圖譜)、文本知識和可視化知識(圖片)[6]等三類典型知識。作者分別通過網絡嵌入(network embedding)獲得結構化知識的向量化表示,然后分別用SDAE(Stacked Denoising Auto-Encoder)和層疊卷積自編碼器(stackedconvolution-autoencoder)抽取文本知識特征和圖片知識特征;并最終將三類特征融合進協同集成學習框架,利用三類知識特征的整合來實現個性化推薦。作者針對電影和圖書數據集進行實驗,證明了這種融合深度學習和知識圖譜的推薦算法具有較好性能。
知識圖譜作為深度學習的約束
Hu 等人提出了一種將一階謂詞邏輯融合進深度神經網絡的模型,并將其成功用于解決情感分類和命名實體識別等問題[7]。邏輯規則是一種對高階認知和結構化知識的靈活表示形式,也是一種典型的知識表示形式。將各類人們已積累的邏輯規則引入到深度神經網絡中,利用人類意圖和領域知識對神經網絡模型進行引導具有十分重要的意義。其他一些研究工作則嘗試將邏輯規則引入到概率圖模型,這類工作的代表是馬爾科夫邏輯網絡[8],但是鮮有工作能將邏輯規則引入到深度神經網絡中。
Hu 等人所提出的方案框架可以概括為“teacher-student network”,如圖 2 所示,包括兩個部分 teacher network q(y|x) 和 student network pθ(y|x)。其中 teacher network 負責將邏輯規則所代表的知識建模,student network 利用反向傳播方法加上teacher network的約束,實現對邏輯規則的學習。這個框架能夠為大部分以深度神經網絡為模型的任務引入邏輯規則,包括情感分析、命名實體識別等。通過引入邏輯規則,在深度神經網絡模型的基礎上實現效果提升。
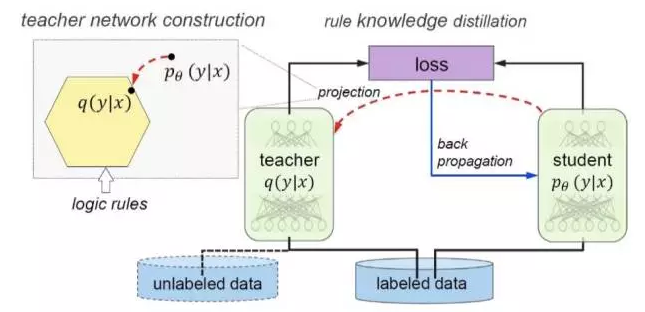
圖2 將邏輯規則引入到深度神經網絡的
“teacher-student network”模型
其學習過程主要包括如下步驟:
利用 soft logic 將邏輯規則表達為 [0, 1] 之間的連續數值。?
基于后驗正則化(posterior regularization)方法,利用邏輯規則對 teacher network 進行限制,同時保證 teacher network 和 student network 盡量接近。最終優化函數為:
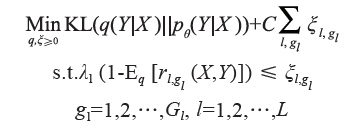
其中,ξl,gl是松弛變量,L 是規則個數,Gl 是第 l 個規則的 grounding 數。KL 函數(Kullback-Leibler Divergence)部分保證 teacher network 和student network 習得模型盡可能一致。后面的正則項表達了來自邏輯規則的約束。
對 student network 進行訓練,保證 teacher network 的預測結果和 student network 的預測結果都盡量地好,優化函數如下:
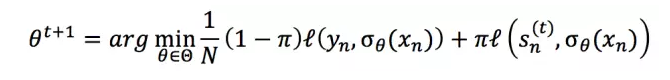
其中,t 是訓練輪次,l 是不同任務中的損失函數(如在分類問題中,l 是交叉熵),σθ 是預測函數,sn(t) 是 teacher network 的預測結果。
重復 1~3 過程直到收斂。
結束語
隨著深度學習研究的進一步深入,如何有效利用大量存在的先驗知識,進而降低模型對于大規模標注樣本的依賴,逐漸成為主流的研究方向之一。知識圖譜的表示學習為這一方向的探索奠定了必要的基礎。近期出現的將知識融合進深度神經網絡模型的一些開創性工作也頗具啟發性。但總體而言,當前的深度學習模型使用先驗知識的手段仍然十分有限,學術界在這一方向的探索上仍然面臨巨大的挑戰。這些挑戰主要體現在兩個方面:
如何獲取各類知識的高質量連續化表示。當前知識圖譜的表示學習,不管是基于怎樣的學習原則,都不可避免地產生語義損失。符號化的知識一旦向量化后,大量的語義信息被丟棄,只能表達十分模糊的語義相似關系。如何為知識圖譜習得高質量的連續化表示仍然是個開放問題。
如何在深度學習模型中融合常識知識。大量的實際任務(諸如對話、問答、閱讀理解等等)需要機器理解常識。常識知識的稀缺嚴重阻礙了通用人工智能的發展。如何將常識引入到深度學習模型將是未來人工智能研究領域的重大挑戰,同時也是重大機遇。
參考文獻
[1] 劉知遠, 孫茂松, 林衍凱, 等. 知識表示學習研究進展[J]. 計算機研究與發展, 2016, 53(2):247-261.
[2] Bordes A, Weston J, Collobert R, et al. Learning Structured Embeddings of KnowledgeBases[C]// AAAI Conference on Artificial Intelligence, AAAI 2011, SanFrancisco, California, Usa, August. DBLP, 2011.
[3] Bordes A, Usunier N, Garcia-Duran A, et al. Translating Embeddings for ModelingMulti-relational Data[J]. Advances in Neural Information Processing Systems,2013:2787-2795.
[4] Jun Yin, Xin Jiang, Zhengdong Lu,Lifeng Shang, Hang Li, Xiaoming Li, NeuralGenerative Question Answering. IJCAI2016.
[5] Giovanni Semeraro , Pasquale Lops , Pierpaolo Basile, Knowledge infusion intocontent-based recommender systems: ACM Conference on Recommender Systems, 2009.
[6] Fuzheng Zhang, Nicholas Jing Yuan, Defu Lian, Xing Xie, Wei-Ying Ma, Collaborative Knowledge Base Embedding for Recommender Systems, in Proc. of KDD, 2016.
[7] Hu, Z., Ma, X., Liu, Z., Hovy, E., & Xing, E. (2016). Harnessing deep neural networks with logic rules. arXiv preprint arXiv:1603.06318.
[8] Matthew Richardson and Pedro Domingos. 2006. Markov logic networks. Machine learning,62(1-2):107–136.
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4546.html
某熊的技術之路指北 ? 當我們站在技術之路的原點,未來可能充滿了迷茫,也存在著很多不同的可能;我們可能成為 Web/(大)前端/終端工程師、服務端架構工程師、測試/運維/安全工程師等質量保障、可用性保障相關的工程師、大數據/云計算/虛擬化工程師、算法工程師、產品經理等等某個或者某幾個角色。某熊的技術之路系列文章/書籍/視頻/代碼即是筆者蹣跚行進于這條路上的點滴印記,包含了筆者作為程序員的技術視野、...
摘要:康納爾大學數學博士博士后則認為,圖神經網絡可能解決圖靈獎得主指出的深度學習無法做因果推理的核心問題。圖靈獎得主深度學習的因果推理之殤年初,承接有關深度學習煉金術的辯論,深度學習又迎來了一位重要的批評者。 作為行業的標桿,DeepMind的動向一直是AI業界關注的熱點。最近,這家世界最較高級的AI實驗室似乎是把他們的重點放在了探索關系上面,6月份以來,接連發布了好幾篇帶關系的論文,比如:關系歸...

閱讀 3973·2021-11-16 11:44
閱讀 5209·2021-10-09 09:54
閱讀 2034·2019-08-30 15:44
閱讀 1682·2019-08-29 17:22
閱讀 2756·2019-08-29 14:11
閱讀 3393·2019-08-26 13:25
閱讀 2328·2019-08-26 11:55
閱讀 1599·2019-08-26 10:37



