資訊專欄INFORMATION COLUMN

摘要:英偉達作為的開發合作者,計劃對的深度學習應用推出一系列博客文章。可使用的英偉達深度學習庫和來實現高性能多加速訓練和推理。最近的訓練基準使用了塊的英偉達和神經網絡架構。
昨天,Facebook 推出了 Caffe2,一個兼具表現力、速度和模塊性的開源深度學習框架。它沿襲了大量的 Caffe 設計,可解決多年來在 Caffe 的使用和部署之中發現的瓶頸問題。最終,Caffe2 打開了算法實驗和新產品的大門。通過在內部用于各種深度學習和增強現實任務,Caffe2 已經在 Facebook 對于規模和性能的需求上得到了鍛造。同時,它為移動端應用提供了令人印象深刻的新功能,例如高級相機和即時通訊功能。英偉達作為 Caffe2 的開發合作者,計劃對 Caffe2 的深度學習應用推出一系列博客文章。本文即是該系列博文的第一篇,將介紹 Caffe2 的深度學習基礎知識,證明其靈活性和速度;本文還將介紹為什么你想要使用 Caffe2、是什么使 Caffe2 區別于 Caffe,最后還會通過一個預訓練的目標分類模型給出一個 Caffe2 使用案例。
一次編碼,任意運行
在保有擴展性和高性能的同時,Caffe2 也強調了便攜性。「便攜性」通常使人想起 overhead——它如何在諸多不同的平臺上工作?overhead 如何影響擴展的能力?Caffe2 當然已把這些考慮在內,其從一開始就以性能、擴展、移動端部署作為主要設計目標。Caffe2 的核心 C++ 庫能提供速度和便攜性,而其 Python 和 C++ API 使你可以輕松地在 Linux、Windows、iOS、Android 甚至 Raspberry Pi 和 NVIDIA Tegra 上進行原型設計、訓練和部署。也許你會問:物聯網呢?Caffe2 將適用于大量設備。盡管你并不想在物聯網設備上訓練網絡,但你可以在其上面部署訓練好的模型。
當 GPU 可用時,Caffe2 也不會錯失這個良機。在 Facebook 和英偉達的合作下,Caffe2 已經可以充分利用英偉達 GPU 深度學習平臺。Caffe2 可使用的英偉達深度學習 SDK 庫——cuDNN、cuBLAS 和 NCCL——來實現高性能、多 GPU 加速訓練和推理。
絕大多數內置函數都可根據運行狀態在 CPU 模式和 GPU 模式之間無縫切換。這意味著無需額外編程即可享用深度學習超級加速的便利。這引出了 Caffe2 激動人心的另一個方面:多 GPU 和多主機處理。Caffe2 使并行化網絡訓練變得簡單,現在實驗和擴展對你而言也非常簡單。
最近的 ImageNet 訓練基準使用了 64 塊的英偉達 GPU 和 ResNet-50 神經網絡架構。Facebook 工程師實現的 Caffe2 的 data_parallel_model(https://github.com/caffe2/caffe2/blob/master/caffe2/python/data_parallel_model.py)能夠在 Facebook 的 8 個 Big Basin 人工智能服務器(每個服務器配有 8 個英偉達 Tesla P100 GPU 加速器,8 個服務器共有 64 塊 GPU)上進行分布式神經網絡訓練。圖 1 是這些系統的擴展結果:近乎直線的深度學習訓練擴展,帶有 57 倍的吞吐量加速。
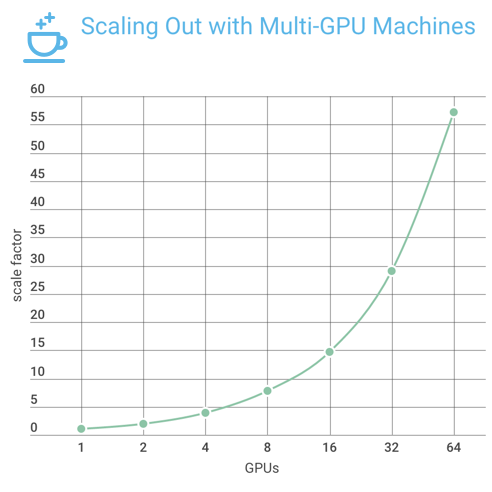
圖 1: 通過 Resnet-50 模型在多達 64 個英偉達 Tesla P100 GPU 加速器上訓練的 Caffe2 擴展系數
Caffe2 的新功能
你也許記得在 Caffe 中一切都表征為一個「網」(Net),它由「層」組成,這些層是以神經網絡中心化方式來定義計算。然而,這創建了一種非常剛性的計算模式,并帶來了很多硬編碼例程,尤其在深度神經網絡訓練方面。
Caffe2 采用了更現代的計算圖(computation graph)來表征神經網絡或者包括集群通信和數據壓縮在內的其它計算。這一計算圖采用「算子」(operator)的概念:在給定輸入的適當數量和類型以及參數的情況下,每個算子都包含了計算輸所必需的邏輯。盡管 Caffe 中的層總是采用張量(矩陣或多維數組),但 Caffe2 中的算子可采用并產生包含隨意對象的「blob」,這一設計使得很多過去在 Caffe 中不可實現的事情成為可能:
CNN 分布式訓練可由單個計算圖表征,不管是在一個或多個 GPU 還是在多臺機器上訓練。這對 Facebook 規模的深度學習應用很關鍵。
在專業硬件上輕松進行異構計算。例如,在 iOS 上,Caffe2 計算圖可從 CPU 獲取圖像,將其轉化為 Metal GPU 緩存對象,并將計算完全保留在 GPU 上,以獲得較大吞吐量。
更好地管理運行時間資源,比如使用 memonger 優化靜態內存,或者預打包訓練網絡以獲得較佳性能。
float、float16、int8 混合精度和其他量化模型的計算。
Caffe2 有超過 400 個算子,具備廣泛的功能。你可以瀏覽算子目錄(http://caffe2.ai/docs/operators-catalogue.html)、查看稀疏操作(http://caffe2.ai/docs/sparse-operations.html)并學習如何編寫自定義算子(http://caffe2.ai/docs/custom-operators.html)。
安裝與設置
你要做的第一件事就是查看 Caffe2 的 GitHub 主頁,clone 或 fork 該項目的 Github repo。
git clone https://github.com/caffe2/caffe2.git
如果你安裝不了 Caffe2,你可以查看以下安裝指南:http://caffe2.ai/docs/getting-started.html,嘗試這個 Docker 鏡像:https://hub.docker.com/r/caffe2ai/caffe2/,或者在你選擇的云提供商上運行。其文檔也為每個選項提供了指令。然而,我們建議你通過建立 GPU 支持的云實例,來驗證 GPU 的處理速度。以下是使用 Docker 建立 GPU 支持的 Caffe2 的快速方式:
docker pull caffe2ai/caffe2 && docker run -it caffe2ai/caffe2:latest
python -m caffe2.python.operator_test.relu_op_test
嘗試一個預訓練的模型
現在讓我們實際上手試一試!在這第一個教程中,我會教你如何輕松使用 Caffe2 的 Model Zoo 和模型下載器(model downloader),以幫你自己動手實驗一些其它模型。Model Zoo 鏈接:http://caffe2.ai/docs/zoo.html
使用 Caffe2 的模型下載器
這是一個下載模塊(https://github.com/caffe2/caffe2/blob/master/caffe2/python/models/download.py),你可以使用它來獲取預訓練好的網絡。你可以將該模塊整合到你的腳本中,或者在命令行中使用它:
python -m caffe2.python.models.download
比如,這行命令可以下載 squeezenet 預訓練模型:
python -m caffe2.python.models.download squeezenet
下載了 squeezenet 之后,你可以加載它。這個模型下載器模塊有一個安裝(install)選項,你可以使用 -i 開啟。否則你就需要在下載文件后自己移動它。一旦安裝完成,你也可以直接將這些模型導入到你的 Python 腳本:
python -m caffe2.python.models.download -i squeezenet
運行一個預訓練模型:目標分類
讓我們試試用 Caffe2 做一次目標分類。如果你已經下載了一個預訓練模型,這做起來就很簡單。如果你還沒有下載 squeezenet,你可以使用上述方法下載,也可從 S3 下載 init_net.pb 和 predict_net.pb 文件。
init_net.pb:https://s3.amazonaws.com/caffe2/models/squeezenet/init_net.pb
predict_net.pb:https://s3.amazonaws.com/caffe2/models/squeezenet/predict_net.pb
將下載好的文件放到 $PYTHONPATH/caffe2/python/models/squeezenet 文件夾。你的 Python 代碼需要 Caffe2 的 workspace 來存放該模型的 protobuf 負載和權重,并將它們加載到 blob、init_net 和 predict_net 中。你將需要 workspace.Predictor 來接收這兩個 protobuf,然后剩下的就交給 Caffe2 處理了。Caffe2 有一個簡單的 run 函數,可以輸入圖像并進行分析,然后返回一個帶有結果的張量。
# load up the caffe2 workspace
from caffe2.python import workspace
# choose your model here (use the downloader first)
from caffe2.python.models import squeezenet as mynet
# helper image processing functions
import caffe2.python.tutorials.helpers as helpers
# load the pre-trained model
init_net = mynet.init_net
predict_net = mynet.predict_net
# you must name it something
predict_net.name = "squeezenet_predict"
workspace.RunNetOnce(init_net)
workspace.CreateNet(predict_net)
p = workspace.Predictor(init_net.SerializeToString(), predict_net.SerializeToString())
# use whatever image you want (local files or urls)
img =「https://upload.wikimedia.org/wikipedia/commons/thumb/7/7b/Orange-Whole-%26-Split.jpg/1200px-Orange-Whole-%26-Split.jpg」
img = "https://upload.wikimedia.org/wikipedia/commons/a/ac/Pretzel.jpg"
img = "https://cdn.pixabay.com/photo/2015/02/10/21/28/flower-631765_1280.jpg"
# average mean to subtract from the image
mean = 128
# the size of images that the model was trained with
input_size = 227
# use the image helper to load the image and convert it to NCHW
img = helpers.loadToNCHW(img, mean, input_size)
# submit the image to net and get a tensor of results
results = p.run([img])
response = helpers.parseResults(results)
# and lookup our result from the list
print response
該結果是一個概率的張量(一個多維數組)。本質上來看,每一行都表示了目標與神經網絡所識別出的內容相匹配的幾率。
注意,當該 workspace 的 Predictor 函數被調用來加載該預訓練的模型時,下一步就是調用 .run 并給該函數傳遞一個圖像數組。
p = workspace.Predictor(init_net, predict_net)
results = p.run([img])
圖像預處理
為了更快的處理速度和傳統上的原因,圖像在被送入 Caffe2 之前還需要經過兩步轉換:
1. 將顏色從 RGB 轉換成 BGR
2. 將圖像封裝成像素數組,并提供批(batch)中圖像的數量(在這案例中是 1)、通道(按 BGR 排列的像素)的數量、高度和寬度,它們分別被稱為:NCHW for Number、Channels、Height 和 Width。
這些圖像預處理函數由一個助手模塊(helper module)進行處理,所以你可以僅關注特定于 Caffe2 的交互。要更深入地了解圖像預處理,請參閱相關 IPython 筆記:https://github.com/caffe2/caffe2/blob/master/caffe2/python/tutorials/Image_Pre-Processing_Pipeline.ipynb
獲得結果
當模型完成圖像數組的處理時,你會獲得一個多維數組,其形式為(1, 1, 1000, 1, 1)
results = np.asarray(results)
print "results shape: ", results.shape
results shape: (1, 1, 1000, 1, 1)
看到 results.shape 中的那個 1000 了嗎?如果該批中不止一張圖片,那么這個數組就會更大,但在中間仍然有 1000 個單元。其存放了該預訓練模型中每個類別的概率。所以當你查看結果時,就好像是在說:「計算機,這是一個鈹(Beryllium)球的概率是多少?」還是說這是一只毒蜥或其它 998 種該模型被訓練用來識別的類別。
這是一個從 1000 長度的張量中提取出的前 3 個結果,已經過收縮和排序。這些結果按照匹配的概率進行了排序,0.98222 (98%) 是較高的。
[array([985.0, 0.9822268486022949], dtype=object), array([309.0, 0.011943698860704899], dtype=object), array([946.0, 0.004810151644051075], dtype=object)]
這是按照概率排列的前三個類別,說明了被檢測的目標屬于某個類別的概率。你可以使用這個 gist 來查看結果:https://gist.githubusercontent.com/aaronmarkham/cd3a6b6ac071eca6f7b4a6e40e6038aa/raw/9edb4038a37da6b5a44c3b5bc52e448ff09bfe5b/alexnet_codes。每次你運行這個示例時,你都會得到有輕微差別的結果。運行一張有一些雛菊的圖片,該模型會得到:

除了較高概率的正確答案之外,第二和第三分別是蜜蜂和刺棘薊,鑒于蜜蜂常常和花出現在同一張照片中,所以這樣的結果也有點道理。

輸入一張切開的橘子照片,可以得到:橘子(95.3%)、檸檬(4.6%)、草莓(0.006%)。
Caffe2 的合作與共享
Caffe2 發展的基石是對深度學習感興趣并使用過 Caffe 以及其它開源機器學習工具的開發者、研究人員和公司組成的社區。通過在 Caffe2 上的開源以及在 Model Zoo 上的創新協作,我們希望能夠推進人工智能科學的進步,并促進各個產業的收益。Caffe2 開源項目的成員能直接在列舉所有模型的 Caffe2 Github Wiki 頁面做貢獻:https://github.com/caffe2/caffe2/wiki。
我們也邀請了開發者、研究人員以及任何對創造或精調模型感興趣的人在 Caffe2 GitHub 的「issue」頁面進行分享:https://github.com/caffe2/caffe2/issues,也可以要求把問題添加到 Zoo 中。此外,Github 的「issue」部分不只是面向 Caffe2 的開發者。如果你創建 Caffe2 模型、改進預訓練模型,甚至只是使用預訓練模型,你也能在該部分對此資源和 Model Zoo 進行輸入、建議與貢獻。關于 Caffe2 和 Model Zoo 合作(http://caffe2.ai/docs/zoo.html)的進一步信息請移步 http://caffe2.ai。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4519.html
摘要:賈揚清現身說法發布后,作者賈揚清在上連發四記解答。,賈揚清一上來就表明了身份。正式發布新框架有何不同賈揚清親自解答有人問搞出意義何在現在已經有等諸多框架。賈揚清說和團隊緊密合作。 ?圖左為Caffe2作者賈揚清今天凌晨召開的F8大會上,Facebook正式發布Caffe2~隨著人工智能的發展,在訓練深度神經網絡和大規模人工智能模型以及部署各機器的計算量時,通常要在大量數據中心或超級計算機的支...
摘要:這一新程序被稱為,是一個完整的深度學習系統,它的架構已經嵌入手機中。因此,移動設備環境對機器學習系統提出了機遇和挑戰。展望下一步,加上這樣的研究工具鏈,是的機器學習產品的核心。 風格遷移一直是機器學習領域內的一項重要任務,很多研究機構和研究者都在努力打造速度更快、計算成本更低的風格遷移機器學習系統,比如《怎么讓你的照片帶上藝術大師風格?李飛飛團隊開源快速神經網絡風格遷移代碼 》、《谷歌增強型...
摘要:表示,的賈揚清對他的這一項目給予了很多幫助,賈揚清告訴他,的好幾個網絡,較大瓶頸都是,如果想要實現一流的性能,賈揚清建議較好使用異步,這樣會有很大的幫助。,和則是默認啟用這項功能。 微軟數據科學家Ilia Karmanov做了一個項目,使用高級API測試8種常用深度學習框架的性能(因為Keras有TF,CNTK和Theano,所以實際是10種)。Karmanov希望這個項目能夠幫助數據科學家...
摘要:下圖總結了絕大多數上的開源深度學習框架項目,根據項目在的數量來評級,數據采集于年月初。然而,近期宣布將轉向作為其推薦深度學習框架因為它支持移動設備開發。該框架可以出色完成圖像識別,欺詐檢測和自然語言處理任務。 很多神經網絡框架已開源多年,支持機器學習和人工智能的專有解決方案也有很多。多年以來,開發人員在Github上發布了一系列的可以支持圖像、手寫字、視頻、語音識別、自然語言處理、物體檢測的...
摘要:部署旨在幫助開發人員和研究人員訓練大規模機器學習模型,并在移動應用中提供驅動的用戶體驗。現在,開發人員可以獲取許多相同的工具,能夠在大規模分布式場景訓練模型,并為移動設備創建機器學習應用。 AI 模型的訓練和部署通常與大量數據中心或超級計算機相關聯,原因很簡單。從大規模的圖像、視頻、文本和語音等各種信息中持續處理、創建和改進模型的能力不是小型計算擅長的。在移動設備上部署這些模型,使其快速輕量...

閱讀 7579·2023-04-25 14:36
閱讀 1747·2021-11-22 09:34
閱讀 2136·2019-08-30 15:55
閱讀 3138·2019-08-30 11:19
閱讀 1301·2019-08-29 15:17
閱讀 544·2019-08-29 12:47
閱讀 2984·2019-08-26 13:38
閱讀 2621·2019-08-26 11:00






