資訊專欄INFORMATION COLUMN

摘要:最近,谷歌發布了一種把低分辨率圖像復原為高分辨率圖像的方法,參見機器之心文章學界谷歌新論文提出像素遞歸超分辨率利用神經網絡消滅低分辨率圖像馬賽克。像素遞歸超分辨率像素獨立超分辨率方法被指出有局限性之后,它的解釋被逐漸給出。
最近,谷歌發布了一種把低分辨率圖像復原為高分辨率圖像的方法,參見機器之心文章《學界 | 谷歌新論文提出像素遞歸超分辨率:利用神經網絡消滅低分辨率圖像馬賽克》。與較先進的方法相比,這篇論文提出了一種端到端的框架來完成超分辨率任務。它由兩個卷積神經網絡組成,一個是描述低分辨率圖像骨架的優先網絡(prior network),一個是用于優化細節特征的調節網絡(conditioning network)。這種方法強調了細節特征恢復上的提升,并以概率范式(probabilistic paradigm)的形式提升了其理論。機器之心在本文中對相關研究《Pixel Recursive Super Resolution》的核心算法進行了分析解讀,具體將從抽樣策略、模型架構和方法分析方面進行敘述。
論文地址:https://arxiv.org/pdf/1702.00783.pdf?
相關報道:https://news.ycombinator.com/item?id=13583476

引言&相關工作
超分辨率問題(Super Resolution Problem)的含義在于恢復圖像的分辨率。可用的解決方案能夠修復和補充細節補丁來重建高分辨率圖像。然而,對于原始圖像中不存在的缺失特征,則需要恢復模型來生成它們。因此,較佳的超分辨率恢復模型必須考慮對象、視點、照明和遮擋的復雜變化。它還應該能夠畫出銳利的邊緣,并決定圖像不同部分中的紋理、形狀和圖案呈現類型,因此產生逼真的高分辨率圖像是非常困難的。
超分辨率問題在計算機視覺研究中具有悠久的歷史。有多種可行的方法來恢復高分辨率圖像。其中插值方法易于實現且廣泛使用,它基本采用的是對所有合理的細節特征值取均值的策略。然而這類方法的缺點也很明顯,因為線性模型不能正確表示輸入信息和輸出結果之間復雜的依賴關系,所以得到的圖像往往是模糊的。
為了獲得生動合理的圖像細節,研究者已經提出了詳細的去模糊(de-blurr)方法。該方法類似于詞典構造(dictionary construction,一種相當簡單而基本的方法),更進一步是可以在 CNN 中提取多個抽象(CNN 層中存在的特征)的濾波器核(filter kernel)的學習層,然后通過測量被插值的低分辨率圖像和高分辨率圖像間的像素損失來調整網絡權重。基本上這種基于多層過濾器的方法的特征層越多,其表現就越好。因此,該 SRResNet 通過從許多 ResNet 模塊中學習來實現預期的性能。這篇論文應用了類似的條件網絡設計來更好地處理高頻特征。
除了設計高頻特征模擬外,下面提出的超分辨率網絡模型稱為 PixelCNN。PixelCNN 旨在生成低分辨率和高分辨率圖像之間的先驗知識(prior knowledge)。與另一種生成模型 GAN 相比,當訓練樣本缺乏分布的多樣性時,它們都將受到影響。但超參數更改時,PixelCNN 有更高的穩健性。而 GAN 相當脆弱,只需要足夠的重復學習就能愚弄一個不穩定的鑒別器,這樣的策略是相當棘手的,于是谷歌超分辨率網絡萌芽了。參考下圖:
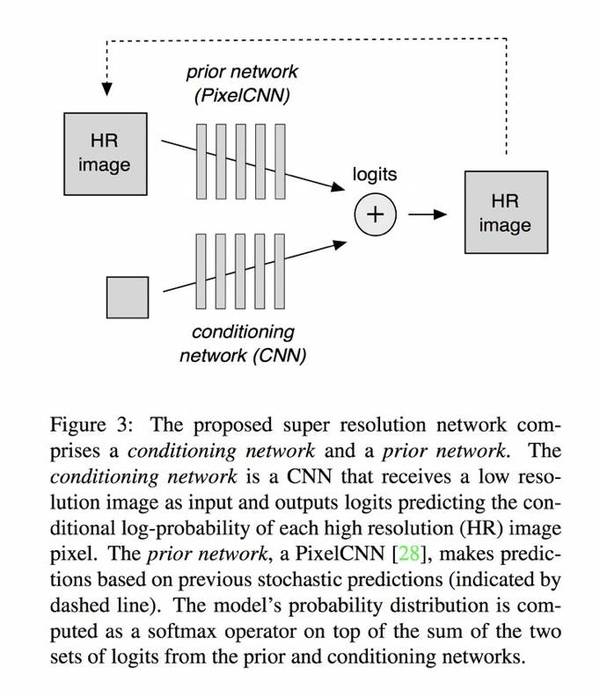
圖 3:我們提出的超分辨率網絡包含了一個調節網絡(conditioning network)和一個優先網絡(prior network)。其中調節網絡是一個 CNN,其接收低分辨率圖像作為輸入,然后輸出 logits——預測了每個高分辨率(HR)圖像像素的條件對數概率(conditional log-probability)。而優先網絡則是一個 PixelCNN,其基于之前的隨機預測進行預測(用虛線表示)。該模型的概率分布的計算是在來自優先網絡和調節網絡的兩個 logits 集之和上作為 softmax operator 而實現的。
端到端模型由兩個網絡組成:1. 使用 PixelCNN 的優先網絡 2. 使用 ResNet 的 Res 塊的調節網絡。
方法和實驗
在后面的章節中,該論文介紹了像素遞歸超分辨率(pixel recursive super resolution)框架的優勢和像素獨立超分辨率(pixel independent super resolution)的潛在問題,并在相應數據集上對這些理論進行了驗證,比較了自定義度量。
?
為了說明部署遞歸超分辨率方法的必要性,本文首先闡述了像素獨立超分辨率方法的理論>下一節將演示這樣的理論會在條件圖像建模中失敗。不理想的實驗結果促使谷歌的這個遞歸模型產生。
?
基本工作流程顯示為:

為了模擬超分辨率問題,其概率目標(probabilistic goal)是學習一個參數模型:

其中 x 和 y 分別表示低分辨率和高分辨率圖像。一旦我們獲得像素值的調節概率,就可以用高分辨率重建整個圖像。我們可以在數據集中應用上述設置,用 y*表示真實的高分辨率圖像,從而能在數學上表示成目標函數。優化目標是使條件對數似然度目標(conditional log-likelihood objective)較大化,如下:
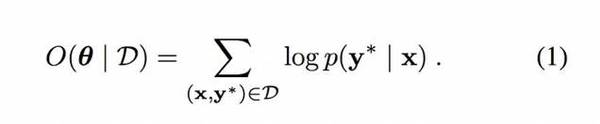
關鍵因素是構建最合適的輸出像素值分布。這樣我們才能夠用銳利的細節得到最生動的高分辨率圖像。
像素獨立的超分辨率
簡單的方式是假設每個預測像素值 y 有條件地獨立于其他值,因此總概率 p(y | x)是每個獨立估計值的乘積。
?
假設一幅給定的 RGB 圖像具有三個顏色通道,并且每個通道擁有 M 個像素。兩邊同時取對數得到:

如果我們假設估計的輸出值 y 連續,則公式(2)可以在高斯分布模型下重構為:

其中 y_i 表示通過卷積神經網絡模型得到的非線性映射輸出 ,表示第 i 個輸出像素的估計平均值。
,表示第 i 個輸出像素的估計平均值。
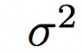 表示方差,一般來說方差是已知的,而不是通過學習獲得的,因此需要學習的是均值和估計值之間的 L2 范數。然后,較大化對數似然(在(1)中表示)可以轉化為 y 和 C 之間的 MSE(均方誤差)最小化。最后,CNN 能夠學習一組高斯參數以獲得較佳平均值 C。
表示方差,一般來說方差是已知的,而不是通過學習獲得的,因此需要學習的是均值和估計值之間的 L2 范數。然后,較大化對數似然(在(1)中表示)可以轉化為 y 和 C 之間的 MSE(均方誤差)最小化。最后,CNN 能夠學習一組高斯參數以獲得較佳平均值 C。
對于連續值,我們使用高斯模型,對于離散值,我們使用多項分布來模擬分布(數據集注明為 D),那么預測概率可以描述為:
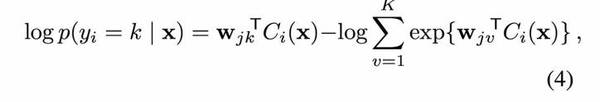
因此我們的目標是學習以從預測模型中獲得最優的 softmax 權值,
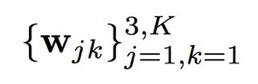 是三個通道下 K 個可能的離散像素值的 softmax 權值。
是三個通道下 K 個可能的離散像素值的 softmax 權值。
然而,該論文稱,上述獨立模型無法處理多模式(multi-modality)的情況,因此在某些特定任務中它的性能不如多模態能力方法,例如著色、超分辨率。其次它遵循 MNIST corner dataset 的實驗演示(數字僅在左上角或右下角定位對象時相同)。

圖 2:上圖:圖片表示了試驗數據集(toy dataset)中輸入輸出對的一種創建方式****。下圖:在這個數據集上訓練的幾個算法的預測示例。像素獨立的 L2 回歸和交叉熵模型沒有表現出多模態預測。PixelCNN 輸出是隨機的,且多個樣本時出現在每個角的概率各為 50%。
參考 MNIST 實驗圖,不同方法下的數字生成結果是不同的。像素交叉熵方法可以捕獲脆性圖像,但無法捕獲隨機雙模態,因此數字對象出現在兩個角落。類似的情況發生在 L2 回歸方法上。最終在一個高分辨率輸出圖像中給出兩個模糊數字。只有 PixelCNN 可以捕獲位置信息和清晰的圖像信息,這進一步說明了在所提出的模型中使用 PixelCNN 的優越性。
像素遞歸超分辨率
像素獨立超分辨率方法被指出有局限性之后,它的解釋被逐漸給出。新理論仍旨將給定樣本 x 的對數似然度較大化。遞歸模型部分假定輸出像素之間存在條件依賴關系。最后,為了近似這種聯合分布,該遞歸方法使用鏈式法則來分解其條件分布:
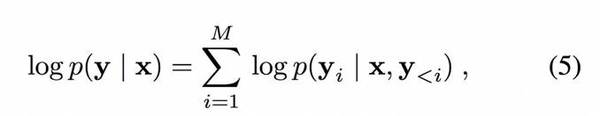
其中每個輸出有條件地依賴于輸入和先前的輸出像素:
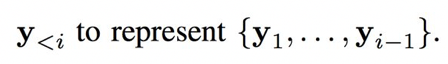
那么嵌入 CNN 的像素遞歸超分辨率框架(參考以前的架構)可以說明如下:
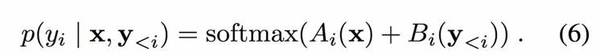
輸入 x,讓?
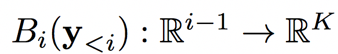
表示調節網絡,得到一個對數值組成的向量,這些值是第 i 個輸出像素的 K 個可能值的對數。
類似的,讓

表示先前網絡,得到由第 i 個輸出像素的對數值組成的向量。
該方法聯合優化兩個網絡,通過隨機梯度上升(stochastic gradient ascend)法更新并獲得較大對數似然。也就是說,優化 (6) 中模型預測值與離散的真實值標簽之間的交叉熵損失
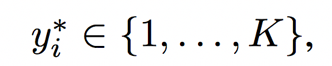
然后其成本函數為:
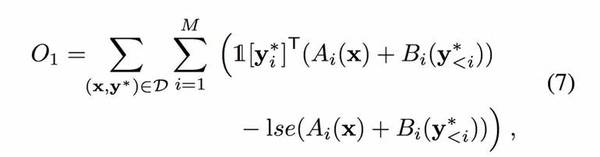
其中 lse(·)是 softmax 分母的對數和的指數運算符(log-sum-exp operator),1 [k] 表示一個 K 維 one-hot 指示符向量的第 k 維度設置為 1。
然而,當在實驗中使用成本函數時,訓練的模型往往忽略調節網絡。因此,范式包括一個新的損失項,用于衡量調節網絡中預測值和真實值之間的交叉熵,表示為:
從而得到新公式:
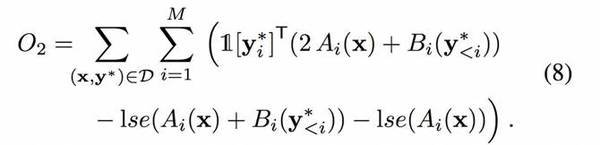
除了定義訓練的范式,為了控制樣本分布的密度,我們引入額外的溫度參數(temperature parameter),從而得到了貪婪解碼機制(greedy decoding mechanism):總是選擇概率較大的像素值和合適的 softmax 中的樣本。因此,分布 P 被調整為:
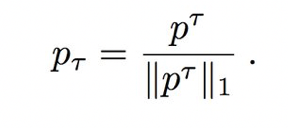
隨著所有理論準備工作的完成,本文進入實施階段。實驗在 TensorFlow 框架下完成,使用 8 個帶有 SGD 更新的 GPU。對于調節網絡,我們建立了前饋卷積神經網絡。它使用從一系列 ResNet 塊得到的 8×8 RGB 圖像和轉置卷積層,同時每層保持 32 個通道。最后一層使用 1×1 卷積將信道增加到 256×3,并且使用所得到結果、通過 softmax 算子預測超過 256 個可能子像素值的多項分布。
?
對于現有網絡,通常為像素 CNN,實驗使用了每層有 32 個通道的 20 個選通 PixelCNN 層。
結果和評估
為了驗證所提框架的性能,本文選擇了兩類對象:人臉和臥室場景。所有訓練圖像均來自 CelebA 數據集和 LSUN 臥室數據集。為了滿足網絡輸入的要求,作者還對每個數據集進行了必要的預處理:裁剪 CelebA 數據集的名人臉和 LSUN 臥室數據集的中心圖像。此外他們還通過雙三次插值(bicubic interpolation)將兩個數據集得到的圖像大小調整為 32×32,進而為 8×8,構成訓練和評估階段的輸出和輸入對。
?
訓練后,將遞歸模型與兩個基準網絡進行比較:像素獨立的 L2 回歸(「回歸」)和最近鄰搜索(「NN」)。視覺效果如下圖所示:

觀測不同方法之間的結果,能看出 NN 方法可以給出清晰的圖像,但是與真實情況的差距相當大,回歸模型給出了一個粗略的草圖,像素遞歸超分辨率方法的效果似乎處于兩個基準方法之間。它捕獲了一些詳細的信息,但沒有比其他方法好很多。
?
另外不同的溫度參數下,結果略有不同如下圖所示:

為了測量性能,我們使用 pSNR 和 MS-SSIM(表 1)量化了訓練模型對真實情況的預測精度,除傳統測量之外,結果還涉及人類識別研究。
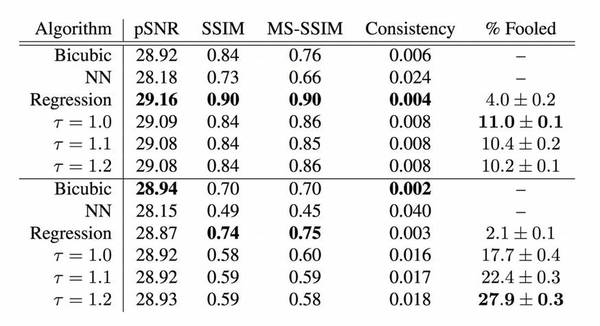
表 1:頂部:在裁切過的 CelebA 測試數據集上,從 8×8 放大到 32×32 后的測試結果。底部:LSUN 臥室。pSNR、SSIM 和 MS-SSIM 測量了樣本和 ground truth 之間的圖像相似度。Consistency(一致性)表示輸入低分辨率圖像和下采樣樣本之間在 [0,1] 尺度上的均方誤差(MSE)。% Fooled 表示了在一個眾包研究中,算法樣本騙過一個人類的常見程度;50% 表示造成了完美的混淆。
從結果表中可以看出,遞歸模型在 pSNR 和 SSIM 測量中表現不佳。雖然文章還引用了另外兩個測量來進行驗證。然而,目前在添加合成信息時似乎缺乏強烈的說服力,或者可能需要進一步的工作來測試驗證。從逃過人們眼睛的百分比來看,該模型比其它方法更優越,因此可以說生成的圖像更加逼真。
?
總之,像素遞歸超分辨率方法提出了一個創新的框架來平衡粗略骨架與細節捕獲。但是我個人認為,結果不能有力地說明該模型在復原低分辨率圖像方面真正有效。雖然不同的分辨率設置使方法難以比較,但它確實能夠為人類的判斷提供良好表現。因此在未來可能具有良好的工業應用。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4509.html
摘要:這篇就介紹利用生成式對抗網絡的兩個基本駕駛技能去除愛情動作片中的馬賽克給愛情動作片中的女孩穿衣服生成式模型上一篇用生成二維樣本的小例子中已經簡單介紹了,這篇再簡要回顧一下生成式模型,算是補全一個來龍去脈。 作為一名久經片場的老司機,早就想寫一些探討駕駛技術的文章。這篇就介紹利用生成式對抗網絡(GAN)的兩個基本駕駛技能:1) 去除(愛情)動作片中的馬賽克2) 給(愛情)動作片中的女孩穿(tu...
摘要:基于深度學習的,主要是基于單張低分辨率的重建方法,即。而基于深度學習的通過神經網絡直接學習分辨率圖像到高分辨率圖像的端到端的映射函數。 超分辨率技術(Super-Resolution)是指從觀測到的低分辨率圖像重建出相應的高分辨率圖像,在監控設備、衛星圖像和醫學影像等領域都有重要的應用價值。SR可分為兩類:從多張低分辨率圖像重建出高分辨率圖像和從單張低分辨率圖像重建出高分辨率圖像。基于深度學...
摘要:在這種場景下網易云信可以在接收的終端上通過超分辨率技術,恢復視頻質量,極大地提升了移動端用戶的體驗。云信通過人工智能深度學習將低分辨率視頻重建成高分辨率視頻模糊圖像視頻瞬間變高清,為移動端為用戶帶來極致視頻體驗。 泛娛樂應用成為主流,社交與互動性強是共性,而具備這些特性的產品往往都集中在直播、短視頻、圖片分享社區等社交化娛樂產品,而在這些產品背后的黑科技持續成為關注重點,網易云信在網易...

閱讀 2351·2021-11-25 09:43
閱讀 2864·2021-11-24 09:39
閱讀 2925·2019-08-30 11:10
閱讀 1130·2019-08-29 16:34
閱讀 595·2019-08-29 13:25
閱讀 3358·2019-08-29 11:21
閱讀 2861·2019-08-26 11:39
閱讀 2394·2019-08-26 11:34




