資訊專欄INFORMATION COLUMN

摘要:現為谷歌軟件工程師。盡管存在這兩個問題,目前仍是最常用的,在搭建人工神經網絡的時候推薦優先嘗試函數人們為了解決,提出了將的前半段設為而非。
夏飛,清華大學計算機軟件學士,卡內基梅隆大學人工智能碩士。現為谷歌軟件工程師。
TLDR (or the take-away)
優先使用ReLU (Rectified Linear Unit) 函數作為神經元的activation function:
背景
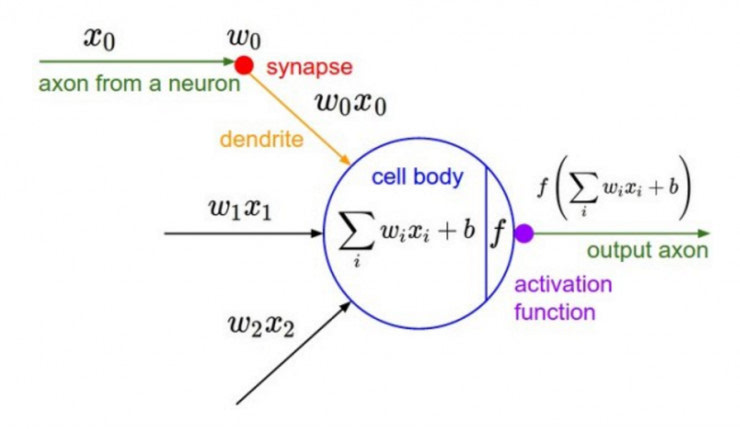
深度學習的基本原理是基于人工神經網絡,信號從一個神經元進入,經過非線性的activation function,傳入到下一層神經元;再經過該層神經元的activate,繼續往下傳遞,如此循環往復,直到輸出層。正是由于這些非線性函數的反復疊加,才使得神經網絡有足夠的capacity來抓取復雜的pattern,在各個領域取得state-of-the-art的結果。顯而易見,activation function在深度學習中舉足輕重,也是很活躍的研究領域之一。目前來講,選擇怎樣的activation function不在于它能否模擬真正的神經元,而在于能否便于優化整個深度神經網絡。
下面我們簡單聊一下各類函數的特點以及為什么現在優先推薦ReLU函數。
Sigmoid函數
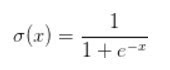
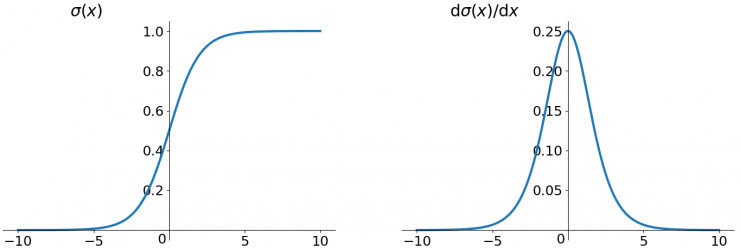
Sigmoid函數是深度學習領域開始時使用頻率較高的activation function。它是便于求導的平滑函數,其導數為,這是優點。然而,Sigmoid有三大缺點:
容易出現gradient vanishing
函數輸出并不是zero-centered
冪運算相對來講比較耗時
Gradient Vanishing
優化神經網絡的方法是Back Propagation,即導數的后向傳遞:先計算輸出層對應的loss,然后將loss以導數的形式不斷向上一層網絡傳遞,修正相應的參數,達到降低loss的目的。 Sigmoid函數在深度網絡中常常會導致導數逐漸變為0,使得參數無法被更新,神經網絡無法被優化。
原因在于兩點:
在上圖中容易看出,當中較大或較小時,導數接近0,而后向傳遞的數學依據是微積分求導的鏈式法則,當前層的導數需要之前各層導數的乘積,幾個小數的相乘,結果會很接近0
Sigmoid導數的較大值是0.25,這意味著導數在每一層至少會被壓縮為原來的1/4,通過兩層后被變為1/16,…,通過10層后為1/1048576。請注意這里是“至少”,導數達到較大值這種情況還是很少見的。
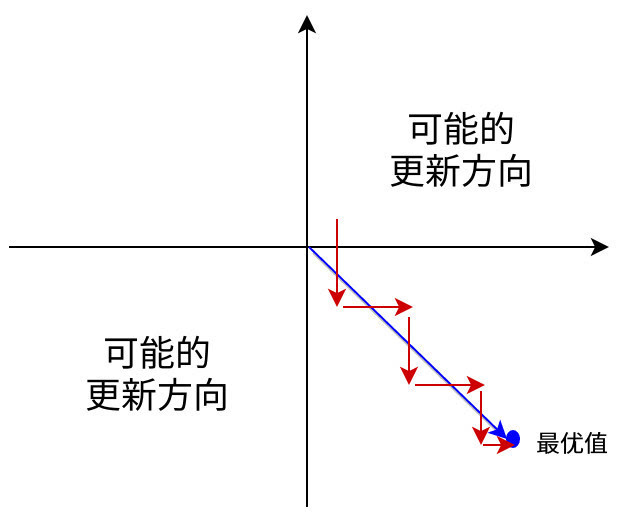
輸出不是zero-centered
Sigmoid函數的輸出值恒大于0,這會導致模型訓練的收斂速度變慢。
舉例來講,對,如果所有均為正數或負數,那么其對的導數總是正數或負數,這會導致如下圖紅色箭頭所示的階梯式更新,這顯然并非一個好的優化路徑。深度學習往往需要大量時間來處理大量數據,模型的收斂速度是尤為重要的。所以,總體上來講,訓練深度學習網絡盡量使用zero-centered數據 (可以經過數據預處理實現) 和zero-centered輸出。
冪運算相對耗時
相對于前兩項,這其實并不是一個大問題,我們目前是具備相應計算能力的,但面對深度學習中龐大的計算量,較好是能省則省 :-)。之后我們會看到,在ReLU函數中,需要做的僅僅是一個thresholding,相對于冪運算來講會快很多。
tanh函數

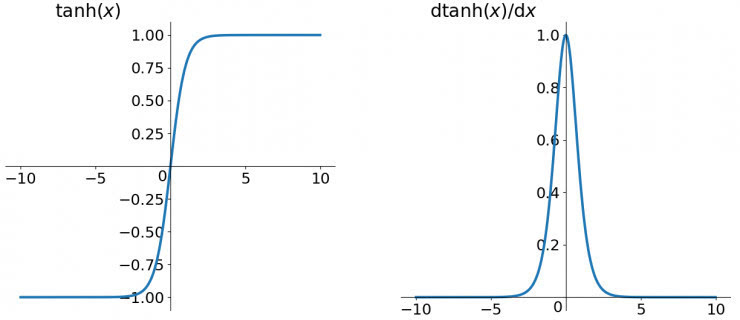
tanh讀作Hyperbolic Tangent,如上圖所示,它解決了zero-centered的輸出問題,然而,gradient vanishing的問題和冪運算的問題仍然存在。
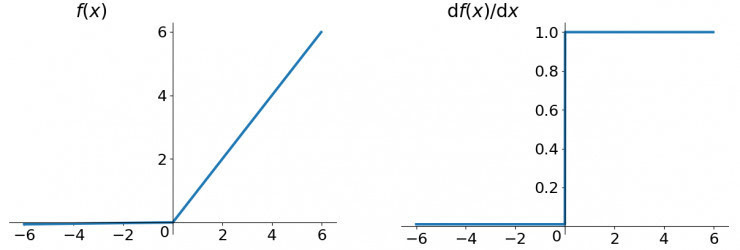
ReLU函數
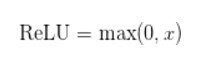
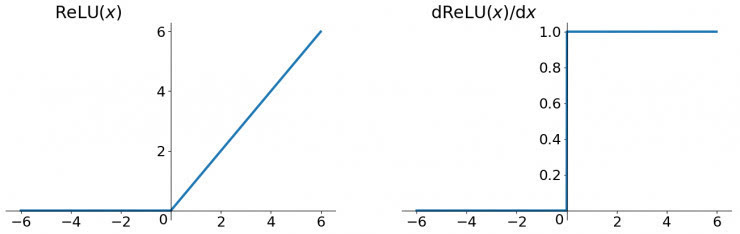
ReLU函數其實就是一個取較大值函數,注意這并不是全區間可導的,但是我們可以取sub-gradient,如上圖所示。ReLU雖然簡單,但卻是近幾年的重要成果,有以下幾大優點:
解決了gradient vanishing問題 (在正區間)
計算速度非常快,只需要判斷輸入是否大于0
收斂速度遠快于sigmoid和tanh
ReLU也有幾個需要特別注意的問題:
ReLU的輸出不是zero-centered
Dead ReLU Problem,指的是某些神經元可能永遠不會被激活,導致相應的參數永遠不能被更新。有兩個主要原因可能導致這種情況產生: (1) 非常不幸的參數初始化,這種情況比較少見 (2) learning rate太高導致在訓練過程中參數更新太大,不幸使網絡進入這種狀態。解決方法是可以采用Xavier初始化方法,以及避免將learning rate設置太大或使用adagrad等自動調節learning rate的算法。
盡管存在這兩個問題,ReLU目前仍是最常用的activation function,在搭建人工神經網絡的時候推薦優先嘗試!
Leaky ReLU函數
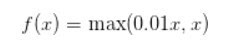
人們為了解決Dead ReLU Problem,提出了將ReLU的前半段設為而非0。另外一種直觀的想法是基于參數的方法,即Parametric ReLU:,其中可由back propagation學出來。理論上來講,Leaky ReLU有ReLU的所有優點,外加不會有Dead ReLU問題,但是在實際操作當中,并沒有完全證明Leaky ReLU總是好于ReLU。
ELU (Exponential Linear Units) 函數
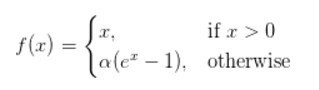

ELU也是為解決ReLU存在的問題而提出,顯然,ELU有ReLU的基本所有優點,以及:
不會有Dead ReLU問題
輸出的均值接近0,zero-centered
它的一個小問題在于計算量稍大。類似于Leaky ReLU,理論上雖然好于ReLU,但在實際使用中目前并沒有好的證據ELU總是優于ReLU。
小結
建議使用ReLU函數,但是要注意初始化和learning rate的設置;可以嘗試使用Leaky ReLU或ELU函數;不建議使用tanh,尤其是sigmoid函數。
參考資料
Udacity Deep Learning Courses
Stanford CS231n Course
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4496.html
摘要:當云平臺出現網絡故障系統故障等問題,這對云租戶用戶有時甚至是致命的,所以不少是由高級別開發人員轉型而來。目前國內各大云廠商也基本都提供了應用運維平臺,包括騰訊藍鯨阿里華為等。 DevOps 全鏈路 下圖是我們熟知的軟件研發環節,在迭代頻率高的研發組織里,一天可能要經歷多次如下循環。對于用戶群體龐大或者正在經歷大幅業務擴張的企業研發組織,除了重點關注應用的快速上線之外,如何保障應用的高可...
摘要:被稱為亞馬遜的新服務提供了強大的功能,如圖像分析,文本到語音轉換和自然語言處理。換句話說,其任務是將谷歌的機器學習功能產品化。亞馬遜平臺推出的這些新服務中的第一個是名為的圖像識別服務。 亞馬遜一直在其零售業務中使用深度學習和人工智能來提高客戶體驗。該公司聲稱,它有數千名工程師專門從事人工智能相關開發,以改善搜索、物流、產品推薦和庫存管理。亞馬遜現在正在將相同的專業知識帶給云,展示了開發人員可...
摘要:在低端領域,在上訓練模型的價格比便宜兩倍。硬件定價價格變化頻繁,但目前提供的實例起價為美元小時,以秒為增量計費,而更強大且性能更高的實例起價為美元小時。 隨著越來越多的現代機器學習任務都需要使用GPU,了解不同GPU供應商的成本和性能trade-off變得至關重要。初創公司Rare Technologies最近發布了一個超大規模機器學習基準,聚焦GPU,比較了幾家受歡迎的硬件提供商,在機器學...
摘要:本文內容節選自由主辦的第七屆,北京一流科技有限公司首席科學家袁進輝老師木分享的讓簡單且強大深度學習引擎背后的技術實踐實錄。年創立北京一流科技有限公司,致力于打造分布式深度學習平臺的事實工業標準。 本文內容節選自由msup主辦的第七屆TOP100summit,北京一流科技有限公司首席科學家袁進輝(老師木)分享的《讓AI簡單且強大:深度學習引擎OneFlow背后的技術實踐》實錄。 北京一流...

閱讀 2312·2021-11-15 11:38
閱讀 2440·2021-11-15 11:37
閱讀 2543·2021-08-24 10:00
閱讀 2901·2019-08-30 15:56
閱讀 1260·2019-08-30 15:53
閱讀 3695·2019-08-29 18:43
閱讀 2930·2019-08-29 17:01
閱讀 3255·2019-08-29 16:25





