資訊專欄INFORMATION COLUMN

摘要:上一篇文章網(wǎng)絡(luò)爬蟲實(shí)戰(zhàn)數(shù)據(jù)爬取下一篇文章網(wǎng)絡(luò)爬蟲實(shí)戰(zhàn)動態(tài)渲染頁面抓取本節(jié)我們以今日頭條為例來嘗試通過分析請求來抓取網(wǎng)頁數(shù)據(jù)的方法,我們這次要抓取的目標(biāo)是今日頭條的街拍美圖,抓取完成之后將每組圖片分文件夾下載到本地保存下來。
上一篇文章:Python3網(wǎng)絡(luò)爬蟲實(shí)戰(zhàn)---35、 Ajax數(shù)據(jù)爬取
下一篇文章:Python3網(wǎng)絡(luò)爬蟲實(shí)戰(zhàn)---37、動態(tài)渲染頁面抓取:Selenium
本節(jié)我們以今日頭條為例來嘗試通過分析 Ajax 請求來抓取網(wǎng)頁數(shù)據(jù)的方法,我們這次要抓取的目標(biāo)是今日頭條的街拍美圖,抓取完成之后將每組圖片分文件夾下載到本地保存下來。
1. 準(zhǔn)備工作在本節(jié)開始之前請確保已經(jīng)安裝好了 Requests 庫,如沒有安裝可以參考第一章的安裝說明。
2. 抓取分析在抓取之前我們首先要分析一下抓取的邏輯,首先打開今日頭條的首頁:http://www.toutiao.com/,如圖 6-15 所示:
圖 6-15 首頁內(nèi)容
在右上角有一個搜索入口,在這里我們嘗試抓取街拍美圖,所以輸入“街拍”二字搜索一下,結(jié)果圖 6-16 所示:
圖 6-16 搜索結(jié)果
這樣我們就跳轉(zhuǎn)到了搜索結(jié)果頁面。
這時打開開發(fā)者工具,查看一下所有網(wǎng)絡(luò)請求,我們首先打開第一個網(wǎng)絡(luò)請求,這個請求的 URL 就是當(dāng)前的鏈接:http://www.toutiao.com/search...,打開 Preview 選項(xiàng)卡查看 Response Body,如果頁面中的內(nèi)容是直接請求直接加載出來的,那么這第一個請求的源代碼中必然包含了頁面結(jié)果中的文字,為了驗(yàn)證,我們可以嘗試嘗試搜索一下搜索結(jié)果的標(biāo)題,比如“路人”二字,如圖 6-17 所示:
圖 6-17 搜索結(jié)果
然而發(fā)現(xiàn)網(wǎng)頁源代碼中并沒有包含這兩個字,搜索匹配結(jié)果數(shù)目為 0。
所以我們就可以初步判斷出這些內(nèi)容是由 Ajax 加載然后用JavaScript 渲染出來的,所以接下來我們可以切換到 XHR過濾選項(xiàng)卡查看一下有沒有 Ajax 請求。
不出所料,此處出現(xiàn)了一個比較常規(guī)的 Ajax 請求,觀察一下它的結(jié)果是否包含了頁面中的相關(guān)數(shù)據(jù)。
點(diǎn)擊 data 字段展開,發(fā)現(xiàn)這里有許多條數(shù)據(jù),我們點(diǎn)擊第一條繼續(xù)展開,可以發(fā)現(xiàn)有一個 title 字段,它的值正好就是頁面中的第一條數(shù)據(jù)的標(biāo)題,再檢查一下其他的數(shù)據(jù)也正好是一一對應(yīng)的,如圖 6-18 所示:
圖 6-18 對比結(jié)果
那這就確定了這些數(shù)據(jù)確實(shí)是由 Ajax 加載的。
我們的目的是要抓取其中的美圖,這里一組圖就對應(yīng)上文中的 data 字段中的一條數(shù)據(jù),每條數(shù)據(jù)還有一個image_detail 字段,它是一個列表形式,這其中就包含了組圖的所有圖片列表,如圖 6-19 所示:
圖 6-19 圖片列表信息
所以我們只需要將列表中的 url 字段提取出來并下載下來就好了,每一組圖都建立一個文件夾,文件夾的名稱就命名為組圖的標(biāo)題。
接下來我們就可以直接用 Python 來模擬這個 Ajax 請求,然后提取出相關(guān)美圖鏈接并下載即可。但是在這之前我們還需要分析一下 URL 的規(guī)律。
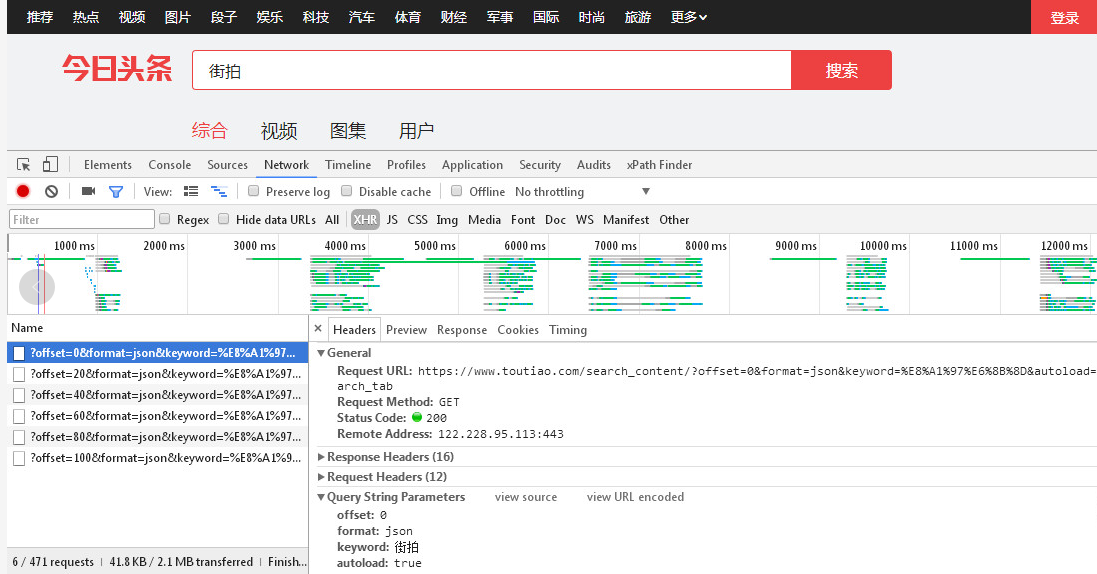
切換回 Headers 選項(xiàng)卡,我們觀察一下它的請求 URL 和 Headers 信息,如圖 6-20 所示:
圖 6-20 請求信息
可以看到這是一個 GET 請求,請求 URL 的參數(shù)有 offset、format、keyword、autoload、count、cur_tab,我們需要找出這些參數(shù)的規(guī)律才方便用程序構(gòu)造出來。
接下來我們可以滑動頁面,多加載一些新的結(jié)果,在加載的同時可以發(fā)現(xiàn) Network 中又出現(xiàn)了許多 Ajax 請求,如圖 6-21 所示:
evernotecid://D603D29C-DFBA-4C04-85E9-CCA3C33763F6/appyinxiangcom/23852268/ENResource/p193
圖 6-21 Ajax 請求
在這里觀察一下后續(xù)鏈接的參數(shù),可以發(fā)現(xiàn)變化的參數(shù)只有offset,其他的都沒有變化,而且第二次請求的 offset 值為 20,第三次為 40,第四次為 60,所以可以發(fā)現(xiàn)規(guī)律,這個 offset 值就是偏移量,而進(jìn)而可以推斷出 count 參數(shù)就是一次性獲取的數(shù)據(jù)條數(shù),所以我們可以用 offset 參數(shù)來控制數(shù)據(jù)分頁,這樣一來,我們就可以通過接口批量獲取數(shù)據(jù)了,然后將數(shù)據(jù)解析,將圖片下載下來就大功告成了。
我們剛才已經(jīng)分析了一下 Ajax 請求的邏輯,下面我們就用程序來實(shí)現(xiàn)美圖下載吧。
首先我們實(shí)現(xiàn)一個方法用于加載單個 Ajax 請求的結(jié)果,叫做 get_page(),其中唯一變化的參數(shù)就是 offset,所以我們將 offset 當(dāng)作參數(shù)傳遞,方法實(shí)現(xiàn)如下:
import requests
from urllib.parse import urlencode
def get_page(offset):
??? params = {
??????? "offset": offset,
??????? "format": "json",
??????? "keyword": "街拍",
??????? "autoload": "true",
??????? "count": "20",
??????? "cur_tab": "1",
??? }
??? url = "http://www.toutiao.com/search_content/?" + urlencode(params)
??? try:
??????? response = requests.get(url)
??????? if response.status_code == 200:
??????????? return response.json()
??? except requests.ConnectionError:
??????? return None
在這里我們用 urlencode() 方法構(gòu)造了請求的 GET 參數(shù),然后用 Requests 請求這個鏈接,如果返回狀態(tài)碼為 200,則調(diào)用 response 的 json() 方法將結(jié)果轉(zhuǎn)為 Json 格式,然后返回。
接下來我們再實(shí)現(xiàn)一個解析方法,提取每條數(shù)據(jù)的 image_detail 字段中的每一張圖片鏈接,將圖片鏈接和圖片所屬的標(biāo)題一并返回,構(gòu)造一個生成器,代碼如下:
def get_images(json):
??? if json.get("data"):
??????? for item in json.get("data"):
??????????? title = item.get("title")
??????????? images = item.get("image_detail")
??????????? for image in images:
??????????????? yield {
??????????????????? "image": image.get("url"),
??????????????????? "title": title
??????????????? }
接下來我們實(shí)現(xiàn)一個保存圖片的方法,item 就是剛才get_images() 方法返回的一個字典,在方法中我們首先根據(jù) item 的 title 來創(chuàng)建文件夾,然后請求這個圖片鏈接,獲取圖片的二進(jìn)制數(shù)據(jù),以二進(jìn)制的形式寫入文件,圖片的名稱可以使用其內(nèi)容的 MD5 值,這樣可以去除重復(fù)。
import os
from hashlib import md5
def save_image(item):
??? if not os.path.exists(item.get("title")):
??????? os.mkdir(item.get("title"))
??? try:
??????? response = requests.get(item.get("image"))
??????? if response.status_code == 200:
??????????? file_path = "{0}/{1}.{2}".format(item.get("title"), md5(response.content).hexdigest(), "jpg")
??????????? if not os.path.exists(file_path):
??????????????? with open(file_path, "wb") as f:
??????????????????? f.write(response.content)
??????????? else:
??????????????? print("Already Downloaded", file_path)
??? except requests.ConnectionError:
??????? print("Failed to Save Image")
最后我們只需要構(gòu)造一個 offset 數(shù)組,遍歷 offset,提取圖片鏈接,并將其下載即可。
from multiprocessing.pool import Pool def main(offset): ??? json = get_page(offset) ??? for item in get_images(json): ??????? print(item) ??????? save_image(item) GROUP_START = 1 GROUP_END = 20 if __name__ == "__main__": ??? pool = Pool() ??? groups = ([x * 20 for x in range(GROUP_START, GROUP_END + 1)]) ??? pool.map(main, groups) ??? pool.close() ??? pool.join()
在這里定義了分頁的起始和終止頁數(shù),分別為 GROUP_START 和 GROUP_END,還利用了多線程的線程池,調(diào)用其 map() 方法實(shí)現(xiàn)多線程下載。
這樣整個程序都就完成了,運(yùn)行之后可以發(fā)現(xiàn)街拍美圖都分文件夾保存下來了,如圖 6-22 所示:
圖 6-22 保存結(jié)果
4. 本節(jié)代碼本節(jié)代碼地址:https://github.com/oldmarkfac...
5. 結(jié)語以上便是抓取今日頭條街拍美圖的過程,通過本節(jié)我們可以了解 Ajax 分析的流程、Ajax 分頁的模擬以及圖片的下載過程。
本節(jié)的內(nèi)容需要熟練掌握,在后面的實(shí)戰(zhàn)中我們還會用到很多次這樣的分析和抓取。
上一篇文章:Python3網(wǎng)絡(luò)爬蟲實(shí)戰(zhàn)---35、 Ajax數(shù)據(jù)爬取
下一篇文章:Python3網(wǎng)絡(luò)爬蟲實(shí)戰(zhàn)---37、動態(tài)渲染頁面抓取:Selenium
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/44113.html
摘要:所以說,我們所看到的微博頁面的真實(shí)數(shù)據(jù)并不是最原始的頁面返回的,而是后來執(zhí)行后再次向后臺發(fā)送了請求,拿到數(shù)據(jù)后再進(jìn)一步渲染出來的。結(jié)果提取仍然是拿微博為例,我們接下來用來模擬這些請求,把馬云發(fā)過的微博爬取下來。 上一篇文章:Python3網(wǎng)絡(luò)爬蟲實(shí)戰(zhàn)---34、數(shù)據(jù)存儲:非關(guān)系型數(shù)據(jù)庫存儲:Redis下一篇文章:Python3網(wǎng)絡(luò)爬蟲實(shí)戰(zhàn)---36、分析Ajax爬取今日頭條街拍美圖 ...
摘要:前言利用爬取的是今日頭條中的街拍美圖。詳細(xì)瀏覽器信息獲取文章鏈接相關(guān)代碼街拍獲取失敗這里需要提一下模塊的報錯在對象上調(diào)用方法如果下載文件出錯會拋出異常需要使用和語句將代碼行包裹起來處理這一錯誤不讓程序崩潰。 ...
摘要:不過動態(tài)渲染的頁面不止這一種。再有淘寶這種頁面,它即使是獲取的數(shù)據(jù),但是其接口含有很多加密參數(shù),我們難以直接找出其規(guī)律,也很難直接分析來抓取。我們用一個實(shí)例來感受一下在這里們依然是先打開知乎頁面,然后獲取提問按鈕這個節(jié)點(diǎn),再將其 上一篇文章:Python3網(wǎng)絡(luò)爬蟲實(shí)戰(zhàn)---36、分析Ajax爬取今日頭條街拍美圖下一篇文章:Python3網(wǎng)絡(luò)爬蟲實(shí)戰(zhàn)---38、動態(tài)渲染頁面抓取:Spla...
摘要:今天給大家分享的是爬蟲,寫得不好的大家多關(guān)照,指出背景交代,以下寫的都是參照網(wǎng)絡(luò)爬蟲開發(fā)實(shí)戰(zhàn)用實(shí)現(xiàn)的,所以的具體思路什么的,大家可以去看書上的介紹,感興趣的,可以去了解一波。 今天給大家分享的是node爬蟲,寫得不好的大家多關(guān)照,指出 背景交代,以下寫的demo都是參照《python3網(wǎng)絡(luò)爬蟲開發(fā)實(shí)戰(zhàn)》用node實(shí)現(xiàn)的,所以demo的具體思路什么的,大家可以去看書上的介紹,感興趣的,可...
摘要:所以如果對爬蟲有一定基礎(chǔ),上手框架是一種好的選擇。缺少包,使用安裝即可缺少包,使用安裝即可上一篇文章網(wǎng)絡(luò)爬蟲實(shí)戰(zhàn)爬取相關(guān)庫的安裝的安裝下一篇文章網(wǎng)絡(luò)爬蟲實(shí)戰(zhàn)爬蟲框架的安裝 上一篇文章:Python3網(wǎng)絡(luò)爬蟲實(shí)戰(zhàn)---9、APP爬取相關(guān)庫的安裝:Appium的安裝下一篇文章:Python3網(wǎng)絡(luò)爬蟲實(shí)戰(zhàn)---11、爬蟲框架的安裝:ScrapySplash、ScrapyRedis 我們直接...

閱讀 1535·2023-04-26 02:08
閱讀 3127·2021-10-14 09:42
閱讀 7177·2021-09-22 15:34
閱讀 3236·2019-08-30 13:16
閱讀 2718·2019-08-26 13:49
閱讀 1341·2019-08-26 11:59
閱讀 1251·2019-08-26 10:31
閱讀 2170·2019-08-23 17:19






