資訊專欄INFORMATION COLUMN

摘要:正如我們可以看到的那樣,降低了人類表現與機器表現之間的差異,在英語和中文上都將差距縮小了以上。對于中文和英語,谷歌當下的系統被認為是世界上較好的,所以用一個模型對二者進行提高是一個很大的成就。
本文介紹的是WaveNet——一個原始音頻波形深度模型。我們展示了,Wavenet能夠生成模仿人類的語音,聽起來要比現有較好的文本到語音轉化系統更自然,將與人類表現的差距縮減了50%以上。
在我們的展示中,相同的網絡能被用于合成其他的音頻信號,比如,音樂。在這里,我們提供了一些樣本——自動生成的鋼琴曲。
會說話的機器
讓人能與機器對話是人機交互長期以來的一個夢想。近年來,隨著深度神經網絡的應用(比如,谷歌的語音搜索),計算機理解自然語音的能力取得了革命性的進展。但是,用計算機生成語音仍然大量地依賴于所謂的 TTS (文本到語音)拼接技術,在這個過程中,首先要記錄一個說話人的聲音片段,并基于此構建超大型的數據庫,隨后,經過再次結合過程,形成完整的表達。這樣一來,在不紀錄一個完整的新數據庫的情況下,要修飾聲音就會變得很困難(比如,轉化到不同的說話者,或者轉化語音中的情感和語氣)。
這導致了對參數的 TTS 的大量需求,在這里面,所有生成數據所需要的信息都被存儲到模型的參數中,并且,語音中的內容和個性可以通過模型的輸入進行控制。但是,目前為止,參數的TTS聽起來更多的是不自然的,而是合成的,至少對于音節語音,比如英語來說是這樣。現有的參數模型一般是信號處理算法Vocoders得到輸出,生成語音信號。
通過直接對原始聲音信號的聲浪建模,WaveNet改變了這種舊范式,每次對一個樣本進行建模。和生成更加自然的語音一樣,使用原始的聲波意味著WaveNet能對任何音頻建模,其中包括音樂。


研究者一般都會避免對原始音頻進行建模,因為音頻跳轉得太快了:一般情況下,每秒轉變的樣本達到16000個或更多,在許多時間點上,都需要設置重要的結構。建立一個完全自動回歸的模型顯然是一個充滿挑戰的任務,在這個模型中,對每一個樣本的預測都會受到此前樣本的影響(在statistics-speak中,每一個預測的分布都受到此前觀察的限制)。
但是,我們在今年早些時候發布的PixelRNN 和 PixelCNN 模型,證明使用不止一個像素一次性生成復雜的自然圖像是可能的,但是一次生成 一個顏色通道,每張圖像都要求成千上萬個預測。這給了我們靈感,進而把二維的PixelNet 運用到 一維的WaveNet中。?

上面的動畫展示了WaveNet的組織結構。這是一個全卷積的神經網絡,當中的卷積層有多個擴張因素,允許它的接收域在深度上呈指數級的增長,覆蓋數千個時間步長。
在訓練時,輸入序列是從人類說話者記錄的真實聲音波形。訓練結束后,我們可以把網絡作為樣本,產生合成的表達。在取樣的每一個步驟中,值是由網絡計算的概率分布繪制。然后該值被反饋到輸入,用于下一個步驟的預測得以制成。這樣按部就班地建立樣品計算成本高昂,但我們發現,在生成復雜的、逼真的音頻上,這是至關重要的。
對現狀的提升
我們使用谷歌的TTS數據庫來訓練WaveNet,這樣我們就能評估它的表現,下面的表格展示了從1到5的量級上,WaveNet 的質量與谷歌現在較好的TTS系統(參數的和合成的)的對比,還有一個對比是與人類使用MOS。
MOS是一個用于衡量主觀聲音質量測試的標準,以人類為對象的盲測中獲得(對100個測試句子的500個評級)。正如我們可以看到的那樣,WaveNets降低了人類表現與機器表現之間的差異,在英語和中文上都將差距縮小了50%以上。
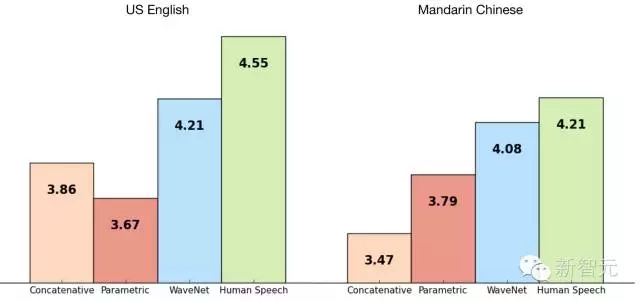
對于中文和英語,谷歌當下的TTS系統被認為是世界上較好的,所以用一個模型對二者進行提高是一個很大的成就。
以下wavenet 在中文上的表現:
知道說的是什么
為了使用WaveNet 把文本轉變成語音,我們必須告訴它文本是什么。我們通過把文本轉化成一個語言與聲學特征序列(這個序列包含了當下的聲音、字母、詞匯等),以及,把這一序列喂到WaveNet中,我們可以做到讓模型了解要說什么。這意味著,網絡的預測不僅取決于前期的聲音樣本,也取決于我們希望它說的內容。
如果我們在沒有文本序列的情況下訓練這一網絡,它仍然能生成語音,但是這樣的話它需要辨別要說的是什么。正如你可以在下面的例子中聽到的那樣,結果有點像在說胡話,其中真實的單詞被類似發音的聲音打亂。
WaveNets在有些時間還可以生成例如呼吸和嘴部運動這樣的非語言聲音,這也反映了一個原始的音頻模型所擁有的更大的自由度。
如你在這些樣本中所能聽到的一樣,一個單一的WaveNet可以學習很多種聲音的特點,不論是男性還是女性。為了確認WaveNet知道在任意的情景下它知道用什么聲音,我們去控制演講人的身份。有意思的是,我們發布用很多的演講者是訓練這個系統,使得它能夠更好的去給單個演講者建模。這比只用一個演講者去訓練要強。這是一種形式的遷移學習。
同樣的,我們也可以在模型的輸入端給予更多的東西,例如情感或噪音,這樣使得生成的語音可以更多樣化,也更有趣。
生成音樂
既然WaveNets可以用來能任意的音頻信息進行建模,我們就想如果能讓他來生成音樂的話,這樣就更有意思了。和TTS實驗不同,我們沒有給網絡一個輸入序列,告訴它要去播放什么(例如一個譜子)。相反的,我們只是讓它去生成任意它想生成的東西。當我們將它在一個古典鋼琴音樂的數據集上進行訓練時,它聽上去的效果確定還不錯。
WaveNets為TTS、音樂合成以及音頻建模開啟了更多的可能性。我們已經迫不及待地想要去探索更多WaveNets能做的事。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4402.html
摘要:文本谷歌神經機器翻譯去年,谷歌宣布上線的新模型,并詳細介紹了所使用的網絡架構循環神經網絡。目前唇讀的準確度已經超過了人類。在該技術的發展過程中,谷歌還給出了新的,它包含了大量的復雜案例。谷歌收集該數據集的目的是教神經網絡畫畫。 1. 文本1.1 谷歌神經機器翻譯去年,谷歌宣布上線 Google Translate 的新模型,并詳細介紹了所使用的網絡架構——循環神經網絡(RNN)。關鍵結果:與...
摘要:深度學習現在被視為能夠超越那些更加直接的機器學習的關鍵一步。的加入只是谷歌那一季一系列重大聘任之一。當下谷歌醉心于深度學習,顯然是認為這將引發下一代搜索的重大突破。移動計算的出現已經迫使谷歌改變搜索引擎的本質特征。 Geoffrey Hiton說:我需要了解一下你的背景,你有理科學位嗎?Hiton站在位于加利福尼亞山景城谷歌園區辦公室的一塊白板前,2013年他以杰出研究者身份加入這家公司。H...

閱讀 3723·2021-11-24 09:39
閱讀 1870·2021-11-16 11:45
閱讀 616·2021-11-16 11:45
閱讀 1028·2021-10-11 10:58
閱讀 2475·2021-09-09 11:51
閱讀 1941·2019-08-30 15:54
閱讀 687·2019-08-29 13:13
閱讀 3465·2019-08-26 12:18




