資訊專欄INFORMATION COLUMN

摘要:深度學習首先發(fā)起于學術界,目前各大互聯(lián)網(wǎng)巨頭也紛紛投入研究,如的貓臉識別以及的深度學習團隊。一家將深度學習用于情緒分析的公司說將詞匯多帶帶分析的方法并不準確,必須將其放入到越來越大的結構中。
深度學習領域是計算機科學一個新興領域,通俗說來就是構建像人腦一樣處理數(shù)據(jù)的計算機程序。深度學習首先發(fā)起于學術界,目前各大互聯(lián)網(wǎng)巨頭也紛紛投入研究,如Google的貓臉識別以及Facebook的深度學習團隊。
每天,數(shù)百萬人在使用Twitter、Facebook和其它社交網(wǎng)絡來就各類熱點話題互相交流。大量的個人信息被匯集到這里,對于Google、Facebook、Amazon和Twitter等大型互聯(lián)網(wǎng)公司來說,如果擁有較為實用的深度學習技術,這些數(shù)據(jù)就可以轉化為財富。但是說起來容易做起來難,對這些數(shù)據(jù)的處理能力很大程度上取決于他們的計算機算法是否成熟。

近日,斯擔福大學的研究生Richard Socher和Andrew Ng(Google深度學習項目工程師之一),以及一位語言學及人工智能領域的專家Chris Manning,共同研究開發(fā)了一個深度學習的新算法,這個算法被稱為Neural Analysis of Sentiment,縮寫為NaSent。NaSent算法從人腦中得到靈感,旨在改善當前書面語言的分析方法。
Socher介紹說NaSent的目的是開發(fā)一種可在無人監(jiān)督的情況下運行的算法。“過去感知分析主要聚焦于模型,忽略了詞序,而且依賴人工干預,并且只適用于簡單的例子,永遠不會達到人類的理解能力。因為詞義會隨語境變化,就算是語言專家也不能準確定義語言中感情的微妙之處。我們的深度學習模型就是為了解決這些問題”。

目前,應用最廣的情緒分析是“詞袋(bag of wodrds)”模型,并沒有將詞序列入考慮范圍。詞袋中的詞匯被標記為正面或負面的,通過計數(shù)來評估整個句子或段落的含義是正面還是負面。
AlchemyAPI(一家將深度學習用于情緒分析的公司)CEO說將詞匯多帶帶分析的方法并不準確,必須將其放入到越來越大的結構中。
Socher和他的團隊從影評網(wǎng)站Rotten Tomatoes抽取了12000個句子,并將其粗略分割為214000個詞組,每個詞組被標記為負面、中立或正面(數(shù)字表示),計算機科學家稱這些數(shù)字化的表述為“特征表示”,類似于人腦理解概念和定義的方式。
如何分析和組織這些被標記的數(shù)據(jù)才是NaSent算法的核心。以下通過對兩個句子的分析來理解這個算法:
Unlike the surreal Leon, this movie is weird but likeable.
Unlike the surreal but likeable Leon, this movie is weird.
這兩個句子中使用的詞匯完全相同,“詞袋”模型分析顯然不會得到正確的結果。NaSent算法首先會為每個句子構造文法樹,如下圖所示:

在分析句子時,紅色的節(jié)點代表這個詞匯或短語帶有負面情緒,例如“weird”雖然是一個負面詞匯,但短語“is weird but likeable”被正確理解為正面情緒。
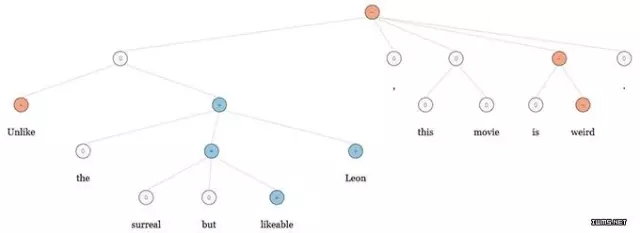
如上圖所示“surreal but likeable Leon”是一個正面詞組,但“this movie is weird”是負面的,整個句子得到的分析結果也是負面的。
相比之前模型80%的準確率,NaSent的準確率達到了85%。這個系統(tǒng)還沒有授權給外部組織,但是據(jù)Socher說已經(jīng)有幾個初創(chuàng)公司聯(lián)系他們表示對NaSent算法很感興趣。
但遇到?jīng)]有被統(tǒng)計的詞匯或短語,這個系統(tǒng)就會失效。Socher和他的團隊已經(jīng)開始通過Twitter和網(wǎng)上的電影數(shù)據(jù)庫,擴充系統(tǒng)的詞匯庫,他們還允許外部人員對這個詞匯庫進行擴充。短短幾周內,就收到了14000份詞匯庫的提交。
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權歸作者所有,未經(jīng)允許請勿轉載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4360.html
摘要:今年月日收購了基于深度學習的計算機視覺創(chuàng)業(yè)公司。這項基于深度學習的計算機視覺技術已經(jīng)開發(fā)完成,正在測試。深度學習的誤區(qū)及產(chǎn)品化浪潮百度首席科學家表示目前圍繞存在著某種程度的夸大,它不單出現(xiàn)于媒體的字里行間,也存在于一些研究者之中。 在過去的三十年,深度學習運動一度被認為是學術界的一個異類,但是現(xiàn)在, Geoff Hinton(如圖1)和他的深度學習同事,包括紐約大學Yann LeCun和蒙特...
摘要:毫無疑問,現(xiàn)在深度學習是主流。所以科技巨頭們包括百度等紛紛通過收購深度學習領域的初創(chuàng)公司來招攬人才。這項基于深度學習的計算機視覺技術已經(jīng)開發(fā)完成,正在測試。 在過去的三十年,深度學習運動一度被認為是學術界的一個異類,但是現(xiàn)在,?Geoff Hinton(如圖1)和他的深度學習同事,包括紐約大學Yann LeCun和蒙特利爾大學的Yoshua Bengio,在互聯(lián)網(wǎng)世界受到前所未有的關注...
摘要:京東更是已經(jīng)實現(xiàn)深度學習的初步運用。目前深度學習推廣的條件已經(jīng)成熟。李成華表示,隨著深度學習的發(fā)展和成熟,的機器學習算法將會被取代。京東研究深度學習的初衷客服對電商發(fā)展的重要性毋庸置疑。隨后深度學習技術的風靡,加深了京東完善的想法。 說深度學習(Deep Learning)算法是當前人工智能皇冠上的明珠并不過分。通過深層神經(jīng)網(wǎng)絡(DNN)模型的運用,深度學習已成為目前最接近人腦的智能學習方法...

閱讀 914·2021-11-22 13:54
閱讀 2843·2021-09-28 09:36
閱讀 2980·2019-08-30 15:55
閱讀 1952·2019-08-30 15:44
閱讀 544·2019-08-29 12:31
閱讀 2564·2019-08-28 18:18
閱讀 1199·2019-08-26 13:58
閱讀 1383·2019-08-26 13:44




