資訊專欄INFORMATION COLUMN

摘要:京東更是已經(jīng)實現(xiàn)深度學(xué)習(xí)的初步運用。目前深度學(xué)習(xí)推廣的條件已經(jīng)成熟。李成華表示,隨著深度學(xué)習(xí)的發(fā)展和成熟,的機器學(xué)習(xí)算法將會被取代。京東研究深度學(xué)習(xí)的初衷客服對電商發(fā)展的重要性毋庸置疑。隨后深度學(xué)習(xí)技術(shù)的風靡,加深了京東完善的想法。
說深度學(xué)習(xí)(Deep Learning)算法是當前“人工智能皇冠上的明珠”并不過分。通過深層神經(jīng)網(wǎng)絡(luò)(DNN)模型的運用,深度學(xué)習(xí)已成為目前最接近人腦的智能學(xué)習(xí)方法,不僅Google、Facebook、百度、騰訊等國內(nèi)外搜索和社交公司為之瘋狂,電商巨頭京東和阿里也已經(jīng)加入競爭。京東更是已經(jīng)實現(xiàn)深度學(xué)習(xí)的初步運用。
深度學(xué)習(xí)技術(shù)在電商運營中的價值如何實現(xiàn)?未來的應(yīng)用趨勢是什么?在近日的京東技術(shù)狂歡節(jié)上,CSDN記者采訪了京東深度神經(jīng)網(wǎng)絡(luò)實驗室(DNN Lab)首席科學(xué)家李成華,就此問題進行了討論,具體的話題涉及京東如何理解深度學(xué)習(xí)、為何要做深度學(xué)習(xí)、如何展開深度學(xué)習(xí)的研究、深度學(xué)習(xí)技術(shù)在京東的應(yīng)用現(xiàn)狀以及京東在研發(fā)過程中的一些心得等。

京東深度神經(jīng)網(wǎng)絡(luò)實驗室(DNN Lab)首席科學(xué)家 李成華
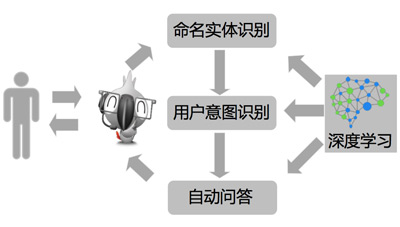
李成華介紹,京東DNN Lab主要專注于人工智能和機器學(xué)習(xí)領(lǐng)域前瞻性的研究,涉及神經(jīng)網(wǎng)絡(luò)、知識層次、異構(gòu)計算等技術(shù)的研發(fā)。DNN Lab目前主要成果包括命名實體識別、用戶意圖識別、用戶畫像和自動問答等,產(chǎn)品化是JIMI智能機器人,已經(jīng)成功應(yīng)用于售前咨詢、售后服務(wù)和生活伴侶三個場景,承擔超過30%的京東客服任務(wù)。作為一個“新生兒”,JIMI會把處理不了的問題轉(zhuǎn)到人工客服,但京東希望未來JIMI可以包攬至少80%的客服工作。
同時,京東也將會探索利用深度學(xué)習(xí)算法提升產(chǎn)品銷量預(yù)測、互聯(lián)網(wǎng)金融、智能硬件、智能搜索、推薦廣告等方面的效果。
大數(shù)據(jù)催熟深度學(xué)習(xí)
深度學(xué)習(xí)是模擬人腦進行分析學(xué)習(xí)的神經(jīng)網(wǎng)絡(luò),它模仿人腦的機制來解釋和處理各種數(shù)據(jù),包括文本數(shù)據(jù)、圖像數(shù)據(jù)和語音數(shù)據(jù)等。
人工神經(jīng)網(wǎng)絡(luò)具有良好的學(xué)習(xí)能力和解決問題的能力,但傳統(tǒng)神經(jīng)網(wǎng)絡(luò)一般只有兩三層的神經(jīng)網(wǎng)絡(luò),其有限的參數(shù)和計算單元,對復(fù)雜函數(shù)的表示能力有限,學(xué)習(xí)能力受到制約,特征的開發(fā)和篩選也極為耗費人力。包含多個隱藏層的深度學(xué)習(xí)模型則不一樣,根據(jù)機器學(xué)習(xí)泰斗、多倫多大學(xué)計算機系教授Geoffery Hinton的論文,它的優(yōu)勢更大:
1、多隱藏層的人工神經(jīng)網(wǎng)絡(luò)具有優(yōu)異的特征學(xué)習(xí)能力,學(xué)習(xí)到的特征對數(shù)據(jù)有更本質(zhì)的刻畫,從而有利于可視化或分類。
2、深度神經(jīng)網(wǎng)絡(luò)在訓(xùn)練上的難度,則可以通過“逐層初始化”(Layer-wise Pre-training)來有效克服。
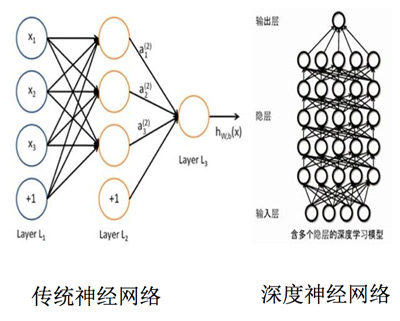
在李成華看來,相比傳統(tǒng)神經(jīng)網(wǎng)絡(luò),深度學(xué)習(xí)更懂用戶、更智能、更精準,更符合京東的業(yè)務(wù)需求。
目前深度學(xué)習(xí)推廣的條件已經(jīng)成熟。一方面,傳統(tǒng)神經(jīng)網(wǎng)絡(luò)在大數(shù)據(jù)量的學(xué)習(xí)上性能較差,不符合大數(shù)據(jù)所需的時效性。另一方面,大數(shù)據(jù)的演進催生了軟硬件系統(tǒng)的進步,分布式架構(gòu)的產(chǎn)生,使得算法的性能已經(jīng)不是瓶頸,并行化框架和訓(xùn)練加速方法,讓深度學(xué)習(xí)的前景變得光明。同時,大數(shù)據(jù)也會讓深度學(xué)習(xí)的效果越來越好。所以,從某種意義上說,深度學(xué)習(xí)是大數(shù)據(jù)的較佳拍檔。
根據(jù)業(yè)界報道,深度學(xué)習(xí)在幾個主要領(lǐng)域都獲得了突破性的進展:
在語音識別領(lǐng)域,深度學(xué)習(xí)用深層模型替換聲學(xué)模型中的混合高斯模型(GMM),獲得了相對30%左右的錯誤率降低;
在圖像識別領(lǐng)域,通過構(gòu)造深度卷積神經(jīng)網(wǎng)絡(luò)(CNN),將Top5錯誤率由26%大幅降低至15%,又通過加大加深網(wǎng)絡(luò)結(jié)構(gòu),進一步降低到11%;
在自然語言處理領(lǐng)域,深度學(xué)習(xí)基本獲得了與其他方法水平相當?shù)慕Y(jié)果,但可以免去繁瑣的特征提取步驟。
李成華表示,隨著深度學(xué)習(xí)的發(fā)展和成熟,80%的機器學(xué)習(xí)算法將會被取代。
京東研究深度學(xué)習(xí)的初衷
客服對電商發(fā)展的重要性毋庸置疑。京東雖然有近5000人的人工客服團隊,但應(yīng)付618或者雙十一大促仍然顯得捉襟見肘。2012年12月,京東開始籌劃成立JIMI智能客服團隊,通過一些機器算法模擬人的思維,達到客服跟用戶交流的效果。隨后深度學(xué)習(xí)技術(shù)的風靡,加深了京東完善JIMI的想法。2014年9月9日,京東成立了京東深度神經(jīng)網(wǎng)絡(luò)實驗室(DNN Lab),旨在通過神經(jīng)網(wǎng)絡(luò)、知識層次、異構(gòu)計算等新興領(lǐng)域的研究和應(yīng)用來確保京東技術(shù)的領(lǐng)先性,提高JIMI的智能性及其應(yīng)用的廣泛性是實驗室的較早的直接目標。
該實驗室直接隸屬于京東副總裁馬松——馬松本人是電商及人工智能領(lǐng)域的資深專家,在美國日本做過多年的研究,并曾在eBay擔任要職。擔任首席科學(xué)家的李成華是加拿大約克大學(xué)的博士后、美國麻省理工大學(xué)的訪問科學(xué)家,在神經(jīng)網(wǎng)絡(luò)領(lǐng)域有超過十年的研究基礎(chǔ)和行業(yè)經(jīng)驗。其他8名成員也是來自全球知名高校、企業(yè)和研究機構(gòu)的技術(shù)精英,具有多年的實踐經(jīng)驗和技術(shù)積累。
深度學(xué)習(xí)技術(shù)固然有很大的應(yīng)用價值,但隨著IBM Watson、百度大腦等平臺的開放,這種能力的獲得并不困難,產(chǎn)品化的好壞才是直接影響客戶服務(wù)能力的因素。京東沒有采用戰(zhàn)略合作的方式,而是選擇在這個領(lǐng)域投入豪華的陣容自主研發(fā),這說明,深度學(xué)習(xí)和數(shù)據(jù)挖掘技術(shù)已經(jīng)被電商企業(yè)視為核心競爭力,立志做技術(shù)驅(qū)動型企業(yè)的京東,必須自己掌握核心這些技術(shù),讓數(shù)據(jù)更好地服務(wù)于自己。
京東DNN Lab的研發(fā)方向
與Google、百度、騰訊在圖像和語音識別領(lǐng)域投入重金不同,京東DNN Lab目前更注重自然語言的處理。李成華強調(diào),京東深度學(xué)習(xí)算法目前用于破解傳統(tǒng)機器學(xué)習(xí)算法的瓶頸,提升JIMI在各個環(huán)節(jié)的性能、智能程度,從而提升用戶滿意度。基于這樣的目標,DNN Lab主要進行如下4個方面的研發(fā):
意圖識別:針對用戶輸入的文本,通過意圖識別之后對應(yīng)到訂單、售后、商品、閑聊等不同的類別。意圖識別對JIMI非常重要,用戶的每一句問話,JIMI首先要判斷他的意圖,到底說的是訂單問題、商品咨詢還是售后問題,抑或單純的閑聊,才會給出更好的反饋。
命名實體識別:先對用戶輸入的文本進行識別,在對識別后的命名實體進行抽取,對應(yīng)到人名、地名、商品名、機構(gòu)名等不同類別,更好地理解用戶的語言。所以,命名實體識別其實也是用戶意圖識別的必須步驟。
自動問答:在明確用戶的意圖之后,通過自動問答系統(tǒng)匹配答案,抽取和排序候選答案,給用戶反饋較佳答案和建議。通過深度學(xué)習(xí)的算法,可以提高自動問答的準確率。與此同時,京東還開發(fā)了一個知識庫,讓JIMI能夠通過深度學(xué)習(xí)算法識別用戶使用不同的詞語背后的各種情緒,從而提供有針對性的回答。
用戶畫像:通過用戶各個維度的數(shù)據(jù),比如性別、能力、身高,歷史瀏覽記錄,購物記錄,是不是有小孩,最近購物傾向是什么,關(guān)注什么商品,對用戶做很細的刻度,分成很多維度的畫像,標注土豪還是屌絲,用戶價值維度是高是低還是中等,用戶是什么類別、性質(zhì)的,是理性保守型還是購物沖動型的,根據(jù)這種細粒度的畫像提供個性化的服務(wù)。

由于人工智能和深度學(xué)習(xí)技術(shù)與大數(shù)據(jù)相結(jié)合的研究和應(yīng)用都是在探索之中,DNN Lab還沒有詳細的長期規(guī)劃。李成華表示,未來的6個月之內(nèi),DNN Lab的主要精力還是放在JIMI智能機器人的完善上——JIMI背后的用戶畫像、自然語言處理、各種自然問答、命名實體抽取等,每一個技術(shù)點其實都是一個很大的課題。因此,他同時表示出對深度學(xué)習(xí)人才的渴求。
不過,李成華也透露,京東對深度學(xué)習(xí)算法的主要預(yù)期,將在產(chǎn)品銷量預(yù)測、互聯(lián)網(wǎng)金融、智能硬件、商品搜索/推薦/廣告等方面。
DNN在京東的應(yīng)用
京東基于其人工客服和用戶交互產(chǎn)生的上億條數(shù)據(jù)對JIMI進行訓(xùn)練,模擬每一個用戶場景。JIMI的應(yīng)用如前文所述,主要分為三類場景。它在2014年雙十一期間接待了近百萬用戶,有效緩解了人工客服的壓力。
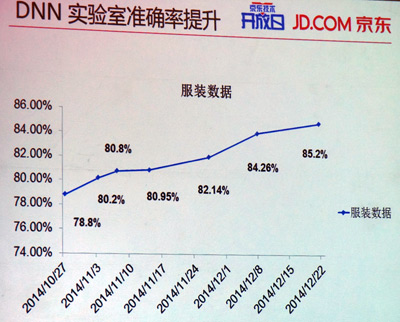
從實際效果來說, JIMI在一定程度上能夠讓不解內(nèi)情的用戶單從對話無法區(qū)分對方是智能機器人還是人工客服。不過,京東以用戶滿意度提升、用戶體驗的提升、用戶愿意使用、服務(wù)占比提高等指標是來衡量其技術(shù)的好壞或者應(yīng)用的效果,在每個課題上,都有識別的準確性、評判分類的準確性的不同標準。在這些標準下,京東內(nèi)部對JIMI現(xiàn)階段的服務(wù)效果較為滿意。
從神經(jīng)網(wǎng)絡(luò)層級來說,李成華介紹,目前工業(yè)界用得最多的已經(jīng)到了十幾層甚至幾十層,京東目前能夠做到八九層,明年可以達到十幾層。
在對京東其他大數(shù)據(jù)應(yīng)用場景的支持,DNN Lab目前主要是根據(jù)項目合作的形式來做,兄弟部門的算法工程師加入項目,提供數(shù)據(jù)和業(yè)務(wù)需求,看看哪些點上能用到深度學(xué)習(xí),共同改進業(yè)務(wù)。
李成華希望能夠做到深度學(xué)習(xí)的平民化,即研究一種深度學(xué)習(xí)算法的架構(gòu),把很多參數(shù)固定起來,通過預(yù)處理,封裝成跟數(shù)據(jù)相關(guān)性很小的標準化的API或者云服務(wù),提供給京東內(nèi)部,讓他們很容易地應(yīng)用于各種數(shù)據(jù),最終還將會向京東產(chǎn)業(yè)鏈輸出。
DNN Lab階段性成果的經(jīng)驗
京東DNN Lab正式成立至今不過短短的幾個月,JIMI智能機器人就已經(jīng)取得如此的成績,確實有驕傲的資本。總結(jié)一下,京東的成功主要有以下的幾個原因:
業(yè)務(wù)導(dǎo)向。相對于財大氣粗的Google、百度,京東的體量要小一些,這也讓京東以更加務(wù)實的姿態(tài)進入這個領(lǐng)域,以為業(yè)務(wù)帶來價值為宗旨,譬如第一個目標直指JIMI智能機器人的打造。所以,具體操作上,京東DNN Lab以項目組的方式運行,由一位副總裁直接領(lǐng)導(dǎo),同時網(wǎng)羅全球優(yōu)秀的、有經(jīng)驗的技術(shù)人才,形成了一個高效的團隊。
數(shù)據(jù)量與數(shù)據(jù)質(zhì)量。得益于開放生態(tài)系統(tǒng)的構(gòu)建,京東擁有龐大的業(yè)務(wù)量并積累了較為完善的數(shù)據(jù),因而深度學(xué)習(xí)才能達成較好的結(jié)果。李成華介紹說:“我們數(shù)據(jù)比較突出,從大數(shù)據(jù)來說京東的數(shù)據(jù)可能是所有電商中數(shù)據(jù)鏈最長的,包括經(jīng)銷商的數(shù)據(jù)、用戶一開始瀏覽我們的數(shù)據(jù),可能別的電商有,最后我們做到客服有沒有返修,返修的時候跟我們?nèi)私换サ臅r候他的情緒是什么樣的,這是別的平臺他們沒有的,因為他們服務(wù)不是自己做的,我們推送服務(wù)全是自己做的,所以我們對用戶數(shù)據(jù)掌握非常全,所以我們的描述也是最準的。”
模型優(yōu)化。這又包括三個層面:針對輸入向量非常長的文本(京東的詞有將近十萬的維度),首先做特征的降維,而且能夠找到并應(yīng)用非常重要的有區(qū)別度的,有利于業(yè)務(wù)提升的特征。第二是說調(diào)節(jié)各種參數(shù),使得算法能夠更快地收斂。第三是通過底層的分布式集群加速算法運算。李成華表示,京東借助于GPU加速運算構(gòu)建分布式集群,實現(xiàn)性能的提升與大數(shù)據(jù)量的支持,其單臺服務(wù)器能比純CPU運算性能提升8~10倍。
當然,這僅僅是京東在深度學(xué)習(xí)領(lǐng)域的初步應(yīng)用。當被問及DNN縱深研發(fā)的挑戰(zhàn),李成華表示,其中的一個方面是訓(xùn)練的時間會比較長,因為它的迭代、交叉、神經(jīng)元的連接時間比較長。甚至如果參數(shù)調(diào)節(jié)不當,訓(xùn)練就沒有任何效果——隨著深度增加,參數(shù)調(diào)節(jié)需要很多的經(jīng)驗,然而這是一個新興領(lǐng)域。換句話說,人才的缺乏也是一大難題。未來,我們期待有破解這兩個挑戰(zhàn)的分享。
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/4297.html
摘要:近年來機器學(xué)習(xí)領(lǐng)域隨著深度神經(jīng)網(wǎng)絡(luò)的崛起而迎來新一波的春天,尤其最近兩年無論學(xué)界還是業(yè)界,或是各大媒體,甚至文盲老百姓都言必稱智能。 近年來機器學(xué)習(xí)、AI領(lǐng)域隨著深度神經(jīng)網(wǎng)絡(luò)(DNN)的崛起而迎來新一波的春天,尤其最近兩年無論學(xué)界還是業(yè)界,或是各大媒體,甚至文盲老百姓都言必稱智能。關(guān)于這方面,可討論的東西實在太多太多,我不想寫成一本厚厚的書,所以在此僅以機器學(xué)習(xí)在計算機視覺和圖像領(lǐng)域的人臉識...
摘要:深度學(xué)習(xí)方法是否已經(jīng)強大到可以使科學(xué)分析任務(wù)產(chǎn)生最前沿的表現(xiàn)在這篇文章中我們介紹了從不同科學(xué)領(lǐng)域中選擇的一系列案例,來展示深度學(xué)習(xí)方法有能力促進科學(xué)發(fā)現(xiàn)。 深度學(xué)習(xí)在很多商業(yè)應(yīng)用中取得了前所未有的成功。大約十年以前,很少有從業(yè)者可以預(yù)測到深度學(xué)習(xí)驅(qū)動的系統(tǒng)可以在計算機視覺和語音識別領(lǐng)域超過人類水平。在勞倫斯伯克利國家實驗室(LBNL)里,我們面臨著科學(xué)領(lǐng)域中最具挑戰(zhàn)性的數(shù)據(jù)分析問題。雖然商業(yè)...

閱讀 3916·2021-11-16 11:44
閱讀 3116·2021-11-12 10:36
閱讀 3373·2021-10-08 10:04
閱讀 1257·2021-09-03 10:29
閱讀 391·2019-08-30 13:50
閱讀 2605·2019-08-29 17:14
閱讀 1735·2019-08-29 15:32
閱讀 1081·2019-08-29 11:27



