資訊專欄INFORMATION COLUMN

摘要:簡介現在爬取淘寶,天貓商品數據都是需要首先進行登錄的。把關鍵點放在如何爬取天貓商品數據上。是一款優秀的自動化測試工具,所以現在采用進行半自動化爬取數據。以開頭的在中表示類名,以開頭的在中表示名。
簡介
現在爬取淘寶,天貓商品數據都是需要首先進行登錄的。上一節我們已經完成了模擬登錄淘寶的步驟,所以在此不詳細講如何模擬登錄淘寶。把關鍵點放在如何爬取天貓商品數據上。
過去我曾經使用get/post方式進行爬蟲,同時也加入IP代理池進行跳過檢驗,但隨著大型網站的升級,采取該策略比較難實現了。因為你使用get/post方式進行爬取數據,會提示需要登錄,而登錄又是一大難題,需要滑動驗證碼驗證。當你想使用IP代理池進行跳過檢驗時,發現登錄時需要手機短信驗證碼驗證,由此可以知道舊的全自動爬取數據對于大型網站比較困難了(小型網站可以使用get/post,沒檢測或者檢測系數較低)。
selenium是一款優秀的WEB自動化測試工具,所以現在采用selenium進行半自動化爬取數據。
編寫思路由于現在大型網站對selenium工具進行檢測,若檢測到selenium,則判定為機器人,訪問被拒絕。所以第一步是要防止被檢測出為機器人,如何防止被檢測到呢?當使用selenium進行自動化操作時,在chrome瀏覽器中的consloe中輸入windows.navigator.webdriver會發現結果為Ture,而正常使用瀏覽器的時候該值為False。所以我們將windows.navigator.webdriver進行屏蔽。
在代碼中添加:
options = webdriver.ChromeOptions()
# 此步驟很重要,設置為開發者模式,防止被各大網站識別出來使用了Selenium
options.add_experimental_option("excludeSwitches", ["enable-automation"])
self.browser = webdriver.Chrome(executable_path=chromedriver_path, options=options)
同時,為了加快爬取速度,我們將瀏覽器模式設置為不加載圖片,在代碼中添加:
options = webdriver.ChromeOptions()
# 不加載圖片,加快訪問速度
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
同時,為了模擬人工操作,我們在瀏覽網頁的時候,模擬下滑,插入代碼:
# 模擬向下滑動瀏覽
def swipe_down(self,second):
for i in range(int(second/0.1)):
js = "var q=document.documentElement.scrollTop=" + str(300+200*i)
self.browser.execute_script(js)
sleep(0.1)
js = "var q=document.documentElement.scrollTop=100000"
self.browser.execute_script(js)
sleep(0.2)
至此,關鍵的步驟我們已經懂了,剩下的就是編寫代碼的事情了。在給定的例子中,需要你對html、css有一定了解。
比如存在以下代碼:
self.browser.find_element_by_xpath("http://*[@class="btn_tip"]/a/span").click()
taobao_name = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".site-nav-bd > ul.site-nav-bd-l > li#J_SiteNavLogin > div.site-nav-menu-hd > div.site-nav-user > a.site-nav-login-info-nick ")))
print(taobao_name.text)
第1行代碼指的是從根目錄(//)開始尋找任意(*)一個class名為btn_tip的元素,并找到btn_tip的子元素a標簽中的子元素span
第2行代碼指的是等待某個CSS元素出現,否則代碼停留在這里一直檢測。以.開頭的在CSS中表示類名(class),以#開頭的在CSS中表示ID名(id)。A > B,指的是A的子元素B。所以這行代碼可以理解為尋找A的子元素B的子元素C的子元素D的子元素E出現,否則一直在這里檢測。
第3行代碼指的是打印某個元素的文本內容
看完上面的代碼,我們大概了解了selenium中html、css的基本規則。我們來實踐一下,在搜索商品的時候如何檢測一共有多少頁呢?不妨看看以下代碼:
# 等待該頁面全部商品數據加載完畢
good_total = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#J_ItemList > div.product > div.product-iWrap")))
# 等待該頁面input輸入框加載完畢
input = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".ui-page > div.ui-page-wrap > b.ui-page-skip > form > input.ui-page-skipTo")))
# 獲取當前頁
now_page = input.get_attribute("value")
print("當前頁數" + now_page + ",總共頁數" + page_total)
打開chrome中的控制臺,轉向console。點擊console面板中的十字指針,移動到網頁中的“共31頁,到第1頁”,然后點擊。你就可以看到該元素的class名為ui-page-skipTo,由于在css中,class用.表示,所以代碼為.ui-page-skipTo。
同時由于他的類型是input輸入框,變成input.ui-page-skipTo。那么是否可以把代碼直接寫成.ui-page-skipTo呢?答案是不一定,如果這個元素在網頁中是唯一的,沒有其他的input的名字也叫ui-page-skipTo的話,就可以。
所以,為了保證代碼健壯性,我們從他的父元素一直查找,直到我們覺得那個父元素是唯一的,那么這樣查找到的元素就是唯一的了。所以最終查找到的結果為.ui-page > div.ui-page-wrap > b.ui-page-skip > form > input.ui-page-skipTo
最后,我們獲取這個Input的值,代碼為input.get_attribute("value")
在獲取商品數據中,存在以下代碼:
# 獲取本頁面源代碼
html = self.browser.page_source
# pq模塊解析網頁源代碼
doc = pq(html)
# 存儲天貓商品數據
good_items = doc("#J_ItemList .product").items()
# 遍歷該頁的所有商品
for item in good_items:
good_title = item.find(".productTitle").text().replace("
","").replace("
","")
good_status = item.find(".productStatus").text().replace(" ","").replace("筆","").replace("
","").replace("
","")
good_price = item.find(".productPrice").text().replace("¥", "").replace(" ", "").replace("
", "").replace("
", "")
good_url = item.find(".productImg").attr("href")
print(good_title + " " + good_status + " " + good_price + " " + good_url + "
")
首先,我們獲取本頁面的源代碼html = self.browser.page_source,然后用pq模塊對源代碼進行格式化解析doc = pq(html),通過上面的講解,我們已經學會了如何分析css元素了。你會發現有一個DIV元素包含著所有商品元素,他的ID(不是class哦)為J_ItemList,所以代碼為#J_ItemList,由于我們要獲取的是每一個商品,所以代碼為#J_ItemList .product,這樣就可以獲取所有class名為product的元素啦。
接著對每個商品元素進行分析,后面的就不必詳細說了。replace函數是對文本進行一些基本替換。
使用教程點擊這里下載下載chrome瀏覽器
查看chrome瀏覽器的版本號,點擊這里下載對應版本號的chromedriver驅動
pip安裝下列包
[x] pip install selenium
點擊這里登錄微博,并通過微博綁定淘寶賬號密碼
在main中填寫chromedriver的絕對路徑
在main中填寫微博賬號密碼
#改成你的chromedriver的完整路徑地址
chromedriver_path = "/Users/bird/Desktop/chromedriver.exe"
#改成你的微博賬號
weibo_username = "改成你的微博賬號"
#改成你的微博密碼
weibo_password = "改成你的微博密碼"
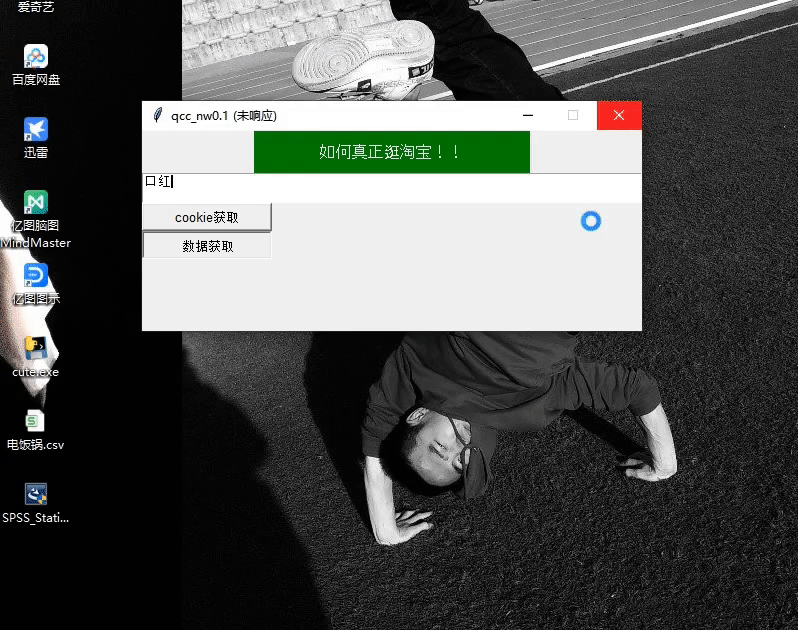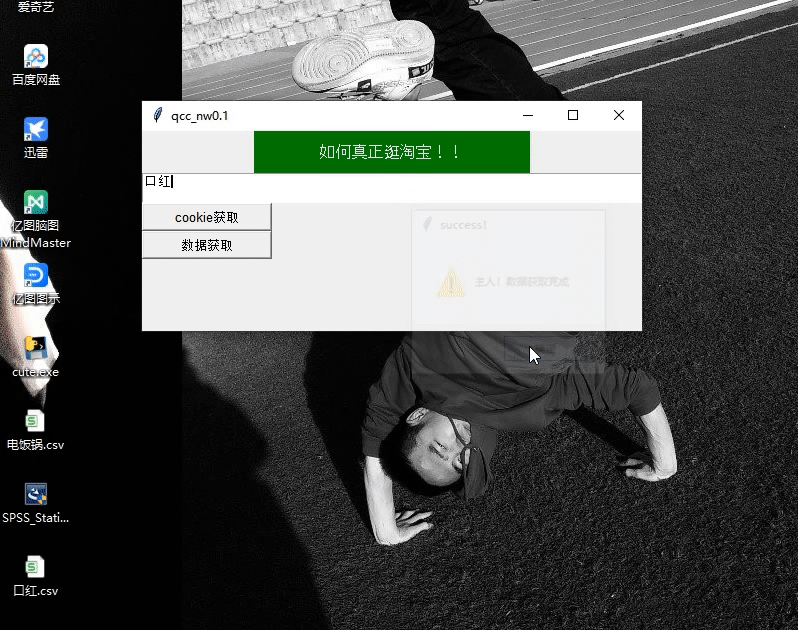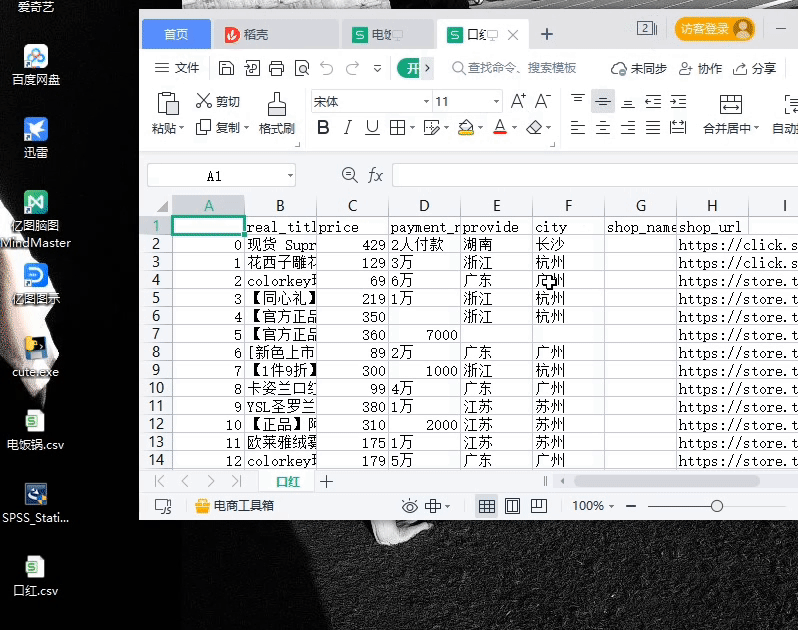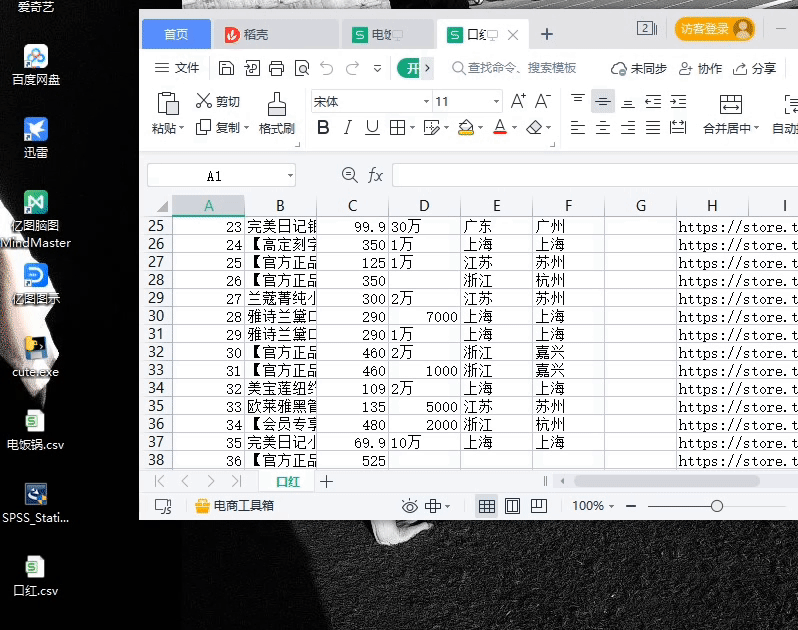
演示圖片
爬蟲過程圖片查看不了點擊這里
爬蟲結果圖片查看不了點擊這里
項目源代碼在GitHub倉庫
項目持續更新,歡迎您star本項目
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/43346.html
摘要:簡介上一個博文已經講述了如何使用跳過檢測并爬取天貓商品數據,所以在此不再詳細講,有需要思路的可以查看另外一篇博文。 簡介 上一個博文已經講述了如何使用selenium跳過webdriver檢測并爬取天貓商品數據,所以在此不再詳細講,有需要思路的可以查看另外一篇博文。 源代碼 # -*- coding: utf-8 -*- from selenium import webdr...
摘要:是一款優秀的自動化測試工具,所以現在采用進行半自動化爬取數據,支持模擬登錄淘寶和自動處理滑動驗證碼。編寫思路由于現在大型網站對工具進行檢測,若檢測到,則判定為機器人,訪問被拒絕。以開頭的在中表示類名,以開頭的在中表示名。 簡介 模擬登錄淘寶已經不是一件新鮮的事情了,過去我曾經使用get/post方式進行爬蟲,同時也加入IP代理池進行跳過檢驗,但隨著大型網站的升級,采取該策略比較難實現了...
摘要:完整代碼火狐瀏覽器驅動下載鏈接提取碼雙十一剛過,想著某寶的信息看起來有些少很難做出購買決定。完整代碼&火狐瀏覽器驅動下載鏈接:https://pan.baidu.com/s/1pc8HnHNY8BvZLvNOdHwHBw 提取碼:4c08雙十一剛過,想著某寶的信息看起來有些少很難做出購買決定。于是就有了下面的設計:?既然有了想法那就趕緊說干就干趁著雙十二還沒到一、準備工作:安裝 :selen...
摘要:且本小白也親身經歷了整個從小白到爬蟲初入門的過程,因此就斗膽在上開一個欄目,以我的圖片爬蟲全實現過程為例,以期用更簡單清晰詳盡的方式來幫助更多小白應對更大多數的爬蟲實際問題。 前言: 一個月前,博主在學過python(一年前)、會一點網絡(能按F12)的情況下,憑著熱血和興趣,開始了pyth...
摘要:,引言最近一直在看爬蟲框架,并嘗試使用框架寫一個可以實現網頁信息采集的簡單的小程序。本文主要介紹如何使用結合采集天貓商品內容,文中自定義了一個,用來采集需要加載的動態網頁內容。 showImg(https://segmentfault.com/img/bVyMnP); 1,引言 最近一直在看Scrapy 爬蟲框架,并嘗試使用Scrapy框架寫一個可以實現網頁信息采集的簡單的小程序。嘗試...

閱讀 2205·2021-10-13 09:39
閱讀 3408·2021-09-30 09:52
閱讀 800·2021-09-26 09:55
閱讀 2775·2019-08-30 13:19
閱讀 1888·2019-08-26 10:42
閱讀 3185·2019-08-26 10:17
閱讀 543·2019-08-23 14:52
閱讀 3631·2019-08-23 14:39






