資訊專欄INFORMATION COLUMN

摘要:特征工程與圖像處理信息檢索以及表達譜等大不相同。以這種方式使用通常被稱為特征提取。在這一問題的范圍內,它們的直覺應該驅動特征工程處理。此外,細胞核的大小與細胞整體大小相關等等。
“特征工程”這個華麗的術語,它以盡可能容易地使模型達到良好性能的方式,來確保你的預測因子被編碼到模型中。例如,如果你有一個日期字段作為一個預測因子,并且它在周末與平日的響應上有著很大的不同,那么以這種方式編碼日期,它更容易取得好的效果。
但是,這取決于許多方面。
首先,它是依賴模型的。例如,如果類邊界是一個對角線,那么樹可能會在分類數據集上遇到麻煩,因為分類邊界使用的是數據的正交分解(斜樹除外)。
其次,預測編碼過程從問題的特定學科知識中受益較大。在我剛才列舉的例子中,你需要了解數據模式,然后改善預測因子的格式。特征工程與圖像處理、信息檢索以及RNA表達譜等大不相同。你需要了解關于這個問題的一些信息,并且用你的特定數據集來做好特征工作。
下面是一些訓練集的數據,使用兩個預測因子來建立一個二分類系統模型(我會在后面揭曉數據來源):
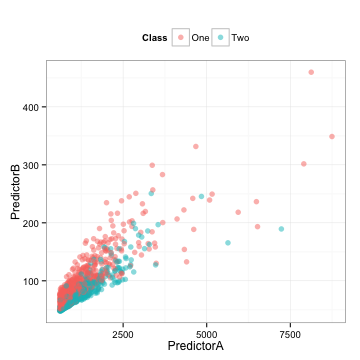
這里還有我們將在下面使用到的相關測試集。
我們可以得到以下結論:
這些數據是高度相關的(相關系數=0.85)。
每個預測因子似乎是向右傾斜的。
它們似乎是多信息的,從某種意義上來說,你或許可以畫出一條對角線來區分類別。
取決于我們選擇使用的模型,兩個預測因子的相關性可能會困擾我們。同樣,我們應該檢查單個預測因子是否重要。為了衡量這一點,我們將直接使用在預測數據上的ROC曲線下方的面積。
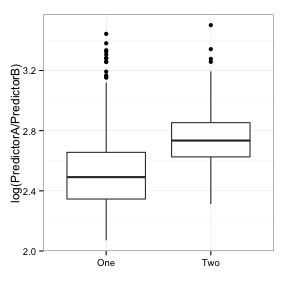
下面是每一個預測因子的單變量盒圖(在對數尺度上):

這兩個類之間有一些細微的差別,但是有很多重疊部分。預測模型A和B的ROC曲線面積分別是0.61和0.59。這個結果并不好。
那我們能做什么?主成分分析(PCA)是一種預處理的方法,它以創建新的綜合預測因子(即主要成分或PC"s)的方式旋轉預測數據。它通過這樣的方式分析:第一個成分占預測數據中大多數(線性)變量或信息的比重。在提取第一個成分之后,第二個成分以同樣的方式來處理剩下的數據,并且依次下去。對于這些數據,有兩種可能的組成部分(因為只有兩個預測因子)。以這種方式使用PCA通常被稱為特征提取。
我們來計算下這些成分:
> library(caret)
> head(example_train)
? ?PredictorA PredictorB Class
2 ? ?3278.726 ?154.89876 ? One
3 ? ?1727.410 ? 84.56460 ? Two
4 ? ?1194.932 ?101.09107 ? One
12 ? 1027.222 ? 68.71062 ? Two
15 ? 1035.608 ? 73.40559 ? One
16 ? 1433.918 ? 79.47569 ? One
> pca_pp <- preProcess(example_train[, 1:2],
+ ? ? ? ? ? ? ? ? ? ? ?method = c("center", "scale", "pca"))
+ pca_pp
Call:
preProcess.default(x = example_train[, 1:2], method = c("center",
?"scale", "pca"))
Created from 1009 samples and 2 variables
Pre-processing: centered, scaled, principal component signal extraction?
PCA needed 2 components to capture 95 percent of the variance
> train_pc <- predict(pca_pp, example_train[, 1:2])
> test_pc <- predict(pca_pp, example_test[, 1:2])
> head(test_pc, 4)
? ? ? ? PC1 ? ? ? ? PC2
1 0.8420447 ?0.07284802
5 0.2189168 ?0.04568417
6 1.2074404 -0.21040558
7 1.1794578 -0.20980371
請注意,我們在訓練集上計算了所有的必要信息,并且將這些計算應用到測試集。那么測試集是什么樣的呢?
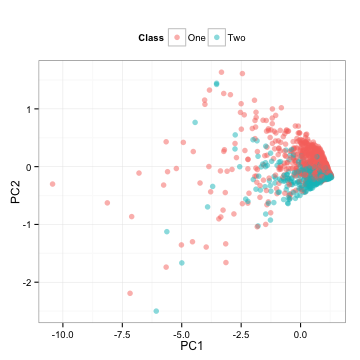
這是測試集預測因子簡單的旋轉。
PCA是非監督式的,這意味著當計算結束時,不需要考慮輸出類。在這里,ROC曲線的下方部分,用第一個成分得到的面積是0.5,第二個成分得到的面積是0.81。這些結果與上面的點混在一起;第一個成分在類中具有隨機混合的特性,而第二個成分似乎可以很好地分離類。兩種成分的盒圖反映了同樣的情況:

在第二個成分中,兩個類的分離度更高。
這很有趣。首先,盡管PCA是非監督式的,它還是成功地找到了一個新的預測因子來劃分類別。其次,這些成分對于這些類別是最終要的,但對于預測器而言則沒那么重要。通常PCA并不會保證任何成分會給出準確預測。但在這里,我們很幸運,它得到一個不錯的預測結果。
但是,試想如果有上百個預測因子。我們可能只需要使用前X個成分來獲取預測因子中絕大部分的信息,然后丟棄其他的成分。在這個例子中,第一個成分占據預測器變量的92.4%,同樣的方法可能會丟棄最有效的預測因子。
特征工程的想法是怎么出現的呢?給定這兩種預測因子,我們可以得到下面所示的散點圖,我首先想到的事情是“有兩個相關聯的,正相關并且斜交的預測因子,一前一后地進行分類”。其次我想到的是“利用比例”。那么數據是什么樣的呢?
ROC曲線下方的相應面積是0.8,它跟第二個成分的結果很相近。一個基于數據視覺化探索的簡單轉換可能會與沒有偏差的經驗算法效果相當。
這些數據來自于Hill等人的細胞分割實驗,預測因子A是“由旋轉得到的等效圓直徑的球體表面”(標記為EqSphereAreaCh1),預測因子B是細胞核的周長(PerimCh1)。一個高內涵篩選的專家,可能會自然而然的采用這兩種細胞特征的比率,因為它會帶來科學意義上良好的效果(我并不是那個人)。在這一問題的范圍內,它們的直覺應該驅動特征工程處理。
然而,在保證諸如PCA算法效能時,機器會因此受益。總的來說,這些數據中有近60個預測因子,它們的特征和EqSphereAreaCh1相近。我的個人愛好是“基于共生矩陣像素空間排列的Haralick 結構測量”。為此研究了一段時間。問題的關鍵是,經常有太多的特征需要設計,而且它們很可能在一開始就很不直觀。
特征提取的另一方面關系到相關性。在特定數據集上的預測因子之間往往有著高度相關性,這是很好理解的。比如,有不同的方法來量化細胞的離心率(比如拉伸程度)。此外,細胞核的大小與細胞整體大小相關等等。PCA可以顯著地緩解相關性的效果。手動采用多預測因子比例的做法似乎可能不太有效,而且會花費更多的時間。
去年,在我支持的一個R&D小組中,專注于偏差分析(即建立我們預先知道的模型)和專注于非偏差分析(即讓機器去尋找最優模型)的科學家之間存在著爭議。我的觀點處于這兩者之間,認為它們之間存在一些交集。一旦挖掘完畢,機器可以將新的、有趣的特征打上“已知事物”的標簽,并把它們作為知識來使用。
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4328.html
摘要:學習筆記七數學形態學關注的是圖像中的形狀,它提供了一些方法用于檢測形狀和改變形狀。學習筆記十一尺度不變特征變換,簡稱是圖像局部特征提取的現代方法基于區域圖像塊的分析。本文的目的是簡明扼要地說明的編碼機制,并給出一些建議。 showImg(https://segmentfault.com/img/bVRJbz?w=900&h=385); 前言 開始之前,我們先來看這樣一個提問: pyth...

閱讀 3514·2023-04-25 20:09
閱讀 3720·2022-06-28 19:00
閱讀 3035·2022-06-28 19:00
閱讀 3058·2022-06-28 19:00
閱讀 3132·2022-06-28 19:00
閱讀 2859·2022-06-28 19:00
閱讀 3014·2022-06-28 19:00
閱讀 2610·2022-06-28 19:00


