資訊專欄INFORMATION COLUMN

摘要:我們可以讓它相信,下面黑色的圖像是一張紙巾,而熊貓則會被識別為一只禿鷲現在,這個結果對我來說并不吃驚,因為機器學習是我的工作,而且我知道機器學習習慣產生奇怪的結果。
神奇的神經網絡
當我打開Google Photos并從我的照片中搜索“skyline”時,它找到了我在八月拍攝的這張紐約地平線的照片,而我之前并未對它做過任何標記。

當我搜索‘cathedral’,Google的神經網絡會找到我曾看到的大教堂和教堂。這似乎很神奇。
當然,神經網絡并不神奇,一點都不!最近我閱讀了一篇論文,“Explaining and Harnessing Adversarial Examples(對抗樣本的解釋和利用)”,進一步削弱了我對神經網絡的神秘感。
這篇論文介紹了如何欺騙神經網絡,讓其犯下非常驚人的錯誤。通過利用比你想象更簡單(更線性!)的網絡事實來做到這一點。我們會使用一個線性函數來逼近這個網絡!
重點是要理解,這并不能解釋神經網絡犯下的所有(或是大多數)類型的錯誤!有很多可能會犯的錯誤!但它確實在一些特定類型的錯誤上給了我們一些靈感,這非常好。
在閱讀這篇論文之前,我對神經網絡的了解有以下三點:
它在圖片分類中表現得很出色(當我搜索“baby”時,它會找到我朋友可愛的孩子照片)
大家都在網上談論“深度”神經網絡
它們是由多層簡單的函數(通常是sigmoid)構成,其結構如下圖所示:
錯誤
我對神經網絡了解的第四點(也是最后一點)是:它們有時會犯很可笑的錯誤。劇透一下本文后面的結果:這是兩張圖片,文章會展示神經網絡是如何對其進行分類的。我們可以讓它相信,下面黑色的圖像是一張紙巾,而熊貓則會被識別為一只禿鷲!
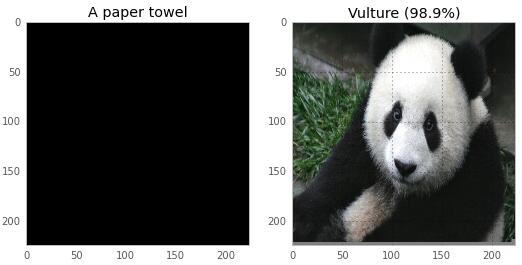
現在,這個結果對我來說并不吃驚,因為機器學習是我的工作,而且我知道機器學習習慣產生奇怪的結果。但如果要解決這個超級奇怪的錯誤,我們就需要理解其背后的原理!我們要學習一些與神經網絡有關的知識,然后我會教你如何讓神經網絡認為熊貓就是一只禿鷲。
做第一個預測
我們首先加載一個神經網絡,然后做一些預測,最后再打破這些預測。這聽起來真棒。但首先我需要在電腦上得到一個神經網絡。
我在電腦上安裝了Caffe,這是一個神經網絡軟件,是Berkeley Vision and Learning Center (BVLC) 社區貢獻者開發的。我選擇它是因為它是我第一個可以找到的軟件,而且我可以下載一個預先訓練好的網絡。你也可以嘗試下Theano或者Tensorflow。Caffe有非常清晰的安裝說明,這意味著在我正式使用它進行工作前,僅僅只需花6個小時來熟悉。
如果你想要安裝Caffe,可以參考我寫的程序,它會讓你節省更多的時間。只需去the neural-networks-are-weird repo這個倉庫,然后按照說明運行即可。警告:它會下載大約1.5G的數據,并且需要編譯一大堆的東西。下面是構建它的命令(僅僅3行!),你也可以在倉庫下的README文件中找到。
git clone https://github.com/jvns/neural-nets-are-weird
cd neural-nets-are-weird
docker build -t neural-nets-fun:caffe .
docker run -i -p 9990:8888 -v $PWD:/neural-nets -t neural-nets-fun:caffe /bin/bash -c "export PYTHONPATH=/opt/caffe/python && cd /neural-nets && ipython notebook --no-browser --ip 0.0.0.0"
這會啟動你電腦中的IPython notebook服務,然后你便可以用Python做神經網絡預測了。它需要在本地9990端口中運行。如果你不想照著做,完全沒關系。我在這篇文章中也包含了實驗圖片。
一旦我們有了IPtyon notebook并運行后,我們就可以開始運行代碼并做預測了!在這里,我會貼一些美觀的圖片和少量的代碼片段,但完整的代碼和詳細細節可以在這里查看。
我們將使用一個名叫GoogLeNet的神經網絡,它在LSVRC 2014 多個競賽中勝出。正確分類是在耗費94%時間的前5大網絡猜測中。這是我讀過的那篇論文的網絡。(如果你想要一個很好的閱讀,你可以閱讀一下人類不能比GoogLeNet做得更好這篇文章。神經網絡真的很神奇。)
首先,讓我們使用網絡對一只可愛的kitten進行分類:

下面是對kitten進行分類的代碼:
image = "/tmp/kitten.png"
# preprocess the kitten and resize it to 224x224 pixels
net.blobs["data"].data[...] = transformer.preprocess("data", caffe.io.load_image(image))
# make a prediction from the kitten pixels
out = net.forward()
# extract the most likely prediction
print("Predicted class is #{}.".format(out["prob"][0].argmax()))
就這些!僅僅只需3行代碼。同樣,我可以對一只可愛的小狗進行分類!
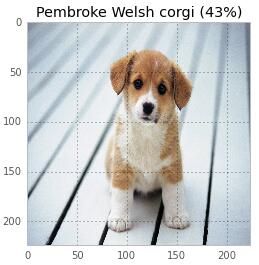
原來這只狗不是柯基犬,只是顏色非常相似。這個網絡對狗的了解果真比我還多。
一個錯誤是什么樣的(以女王為例)
做這項工作時最有趣的事情是,我發現了神經網絡認為英國女王戴在她的頭上。

所以,現在我們看到網絡做了一件正確的事,同時我們也看到它在不經意間犯了一個可愛的錯誤(女王戴的是浴帽)。現在...我們讓它故意去犯錯誤,并進入它的核心。
故意犯錯誤
在真正理解其工作原理之前,我們需要做一些數學變換,首先讓我們看看它對黑色屏幕的一些描述。
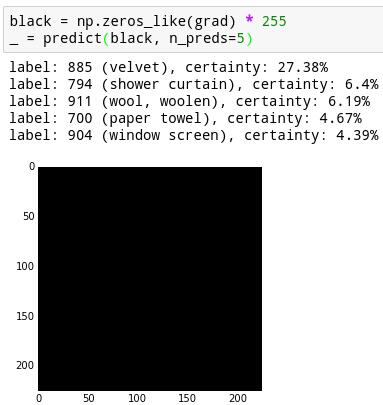
這張純黑色圖像被認為是天鵝絨的概率是27%,被認為是紙巾的概率為4%。還有一些其它類別的概率沒有列出來,這些概率之和為100%。
我想弄清楚如何讓神經網絡更有信心認為這是一個紙巾。
要做到這一點,我們需要計算神經網絡的梯度。也就是神經網絡的導數。你可以將這看作是一個方向,讓圖像在這個方向上看起來更像一張紙巾。
要計算梯度,我們首先需要選擇一個預期的結果來移動方向,并設置輸出概率列表,0表示任何方向,1表示紙巾的方向。反向傳播算法是一種計算梯度的算法。我原以為它很神秘,但事實上它只是一個實現鏈式法則的算法。
下面是我編寫的代碼,實際上非常簡單!反向傳播是一種最基本的神經網絡運算,因此在庫中很容易獲得。
def compute_gradient(image, intended_outcome):
? ? # Put the image into the network and make the prediction
? ? predict(image)
? ? # Get an empty set of probabilities
? ? probs = np.zeros_like(net.blobs["prob"].data)
? ? # Set the probability for our intended outcome to 1
? ? probs[0][intended_outcome] = 1
? ? # Do backpropagation to calculate the gradient for that outcome
? ? # and the image we put in
? ? gradient = net.backward(prob=probs)
? ? return gradient["data"].copy()
這基本上告訴了我們,什么樣的神經網絡會在這一點上尋找。因為我們處理的所有東西都可以表示為一個圖像,下面這個是compute_gradient(black, paper_towel_label)的輸出,縮放到可見比例。
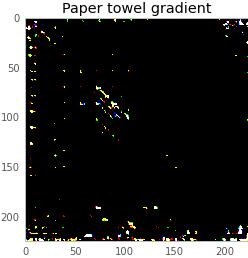
現在,我們可以從我們的黑色屏幕添加或減去一個非常明亮的部分,使神經網絡認為我們的圖像或多或少像一張紙巾。由于我們添加的圖像太亮(像素值小于1 / 256),所以差異完全看不到。下面是這個結果:

現在,神經網絡以16%的概率肯定我們的黑色屏幕是一張紙巾,而不是4%!真靈巧。但是,我們可以做的更好。我們可以采取走十個小步來構成一個有點像紙巾的每一步,而不是在紙巾的方向直接走一步。你可以在下面看到隨時間變化的概率。你會注意到概率值與之前的不同,因為我們的步長大小不同(0.1,而不是0.9)。
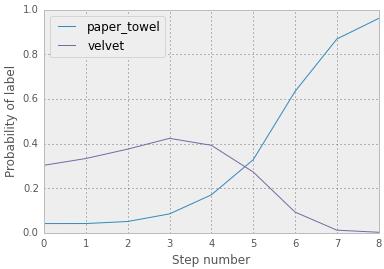
最后的結果:
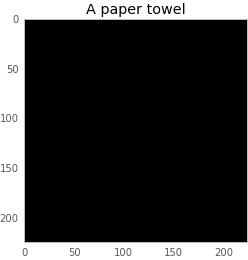
下面是構成這張圖像的像素值!他們都從0開始,而且你可以看到,我們已經轉換了它們,使其認為該圖像就是紙巾。
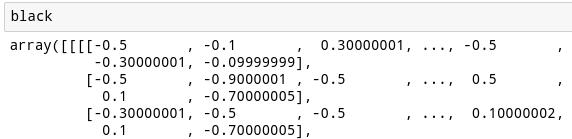
我們還可以用50乘以這個圖像從而獲得一個更好的圖像感知。
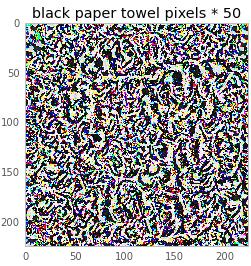
對我來說,這看起來并不像一塊紙巾,但對你可能就像。我猜測圖像的所有漩渦都戲弄了神經網絡使其認為這是一張紙巾。這牽扯到基本的概念證明和一些數學原理。馬上我們就要接觸更多的數學知識了,但首先我們來玩點有趣的。
玩轉神經網絡
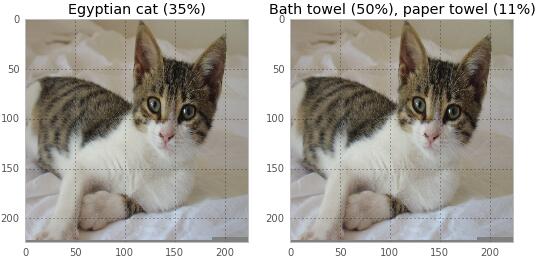
一旦我理解了這個,它就會變得非常有趣。我們可以換一只貓變成浴巾:
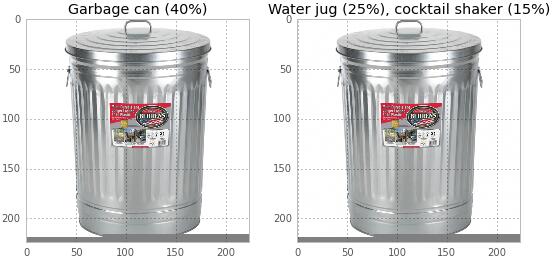
一個垃圾桶可以變成一個水壺/雞尾酒調酒器:
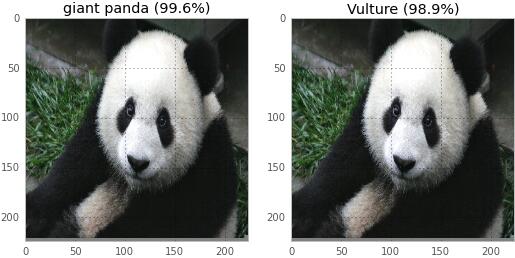
一只熊貓可以變成禿鷲。
這張圖表明,在將熊貓認為是禿鷹的100步內,其概率曲線轉變地很迅速。

你可以查看代碼,讓這些工作在 IPython notebook中運行。真的很有趣。
現在,是時候多一點數學原理了。
如何工作:邏輯回歸
首先,讓我們討論一種最簡單的圖像分類方法——邏輯回歸。什么是邏輯回歸?下面我來試著解釋下。
假設你有一個線性函數,用于分類一張圖像是否是浣熊。那么我們如何使用線性函數呢?現在假設你的圖像只有5個像素(x1,x2,x3,x4,x5),取值均在0和255之間。我們的線性函數都有一個權重,比如取值為(23, - 3,9,2, 5),然后對圖像進行分類,我們會將得到像素和權重的內積:
result=23x1?3x2+9x3+2x4?5x5
假設現在的結果是794。那么794到底意味著它是浣熊或者不是呢?794是概率嗎?794當然不是概率。概率是一個0到1之間的數。我們的結果在?∞到∞之間。人們將一個取值在?∞到∞之間的數轉為一個概率值的一般方法是使用一個叫做logistic的函數:S(t)=1/(1+e^(-t))
此函數的圖形如下所示:

S(794)的結果基本為1,所以如果我們從浣熊的權重得到794,那么我們就肯定它100%是個浣熊。在這個模型中——我們先使用線性函數變換數據,然后應用邏輯函數得到一個概率值,這就是邏輯回歸,而且這是一種非常簡單流行的機器學習技術。
機器學習中的“學習”主要是在給定的訓練集下,如何決定正確的權重(比如(23, - 3,9,2, 5)),這樣我們得到的概率值才能盡可能的好。通常訓練集越大越好。
現在我們理解了什么是邏輯回歸,接下來讓我們討論下如何打破它吧!
打破邏輯回歸
這有一篇華麗的博文,Andrej Karpathy發表的Breaking Linear Classifiers on ImageNet,解釋了如何完美地打破一個簡單線性模型(不是邏輯回歸,而是線性模型)。后面我們將使用同樣的原理來打破神經網絡。
這有一個例子(來自Karpathy的文章),一些區分不同食物,鮮花以及動物的線性分類器,可視化為下圖。

你可以看到“Granny Smith”分類器基本上是問“是綠色么?”(并不是以最壞的方式來找出!),而“menu”分類器發現菜單通常是白色。Karpathy 對其解釋的非常清楚:
例如,蘋果是綠色的,所以線性分類器在所有的空間位置中,綠色通道上呈現正權值,藍色和紅色通道上呈現負權值。因此,它有效地計算了中間是綠色成分的量。
所以,如果我想要讓Granny Smith分類器認為我是一個蘋果,我需要做的是:
找出圖中哪一個像素點最關心綠色
給關心綠色的像素點著色
證明!
所以現在我們知道如何去欺騙一個線性分類器。但是神經網絡并不是線性的,它是高度非線性的!為什么會相關呢?
如何工作:神經網絡
在這我必須誠實一點:我不是神經網絡專家,我對神經網絡的解釋并不會很出色。Michael Nielsen寫了一本叫做《Neural Networks and Deep Learning》的書,寫的很好。另外,Christopher Olah的博客也不錯。
我所知道的神經網絡是:它們是函數。你輸入一張圖像,你會得到一個概率列表,對每個類都有一個概率。這些是你在這篇文章中看到的圖像的數字。(它是一只狗嗎?不。淋浴帽?也不是。一個太陽能電池?YES!!)
因此,一個神經網絡,就像1000個函數(每個概率對應一個)。但1000個函數對于推理來說非常復雜。因此,做神經網絡的人,他們把這1000個概率組合并為一個單一的“得分”,并稱之為“損失函數”。
每個圖像的損失函數取決于圖像實際正確的輸出。假設我有一張鴕鳥的圖片,并且神經網絡有一個輸出概率Pj,其中j=1...1000,但對于每只鴕鳥我想要得到的是概率yj。那么損失函數為:
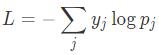
假設與“鴕鳥”對應的標簽值是700,那么y700=1,其它的yj就為0,L=-logp700。
在這里,重點是要理解神經網絡給你的是一個函數,當你輸入一張圖像(熊貓),你會得到損失函數的最終值(一個數,如2)。因為它是一個單值函數,所以我們將該函數的導數(或梯度)賦值給另一張圖像。然后,你就可以使用這個圖像來欺騙神經網絡,也就是用我們在這篇文章前面討論的方法!
打破神經網絡
下面是關于如何打破一個線性函數/邏輯回歸與神經網絡的關系!也就是你一直在等待的數學原理!思考下我們的圖像(可愛的熊貓),損失函數看起來像:
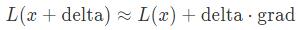
其中,梯度grad等于?L(x)。因為這是微積分。為了讓損失函數的變化的更多,我們要較大化移動的delta和梯度grad兩者的點積。讓我們通過compute_gradient()函數計算梯度,并把它畫成一個圖片:

直覺告訴我們需要做的是創建一個delta,它重點強調神經網絡認為重要的圖像像素。現在,假設grad為(?0.01,?0.01,0.01,0.02,0.03).
我們可以取delta=(?1,?1,1,1,1),那么grad?delta的值為0.08.。讓我們嘗試一下!在代碼中,就是delta = np.sign(grad)。當我們通過這個數量移動時,果然–現在熊貓變成黃鼠狼了。
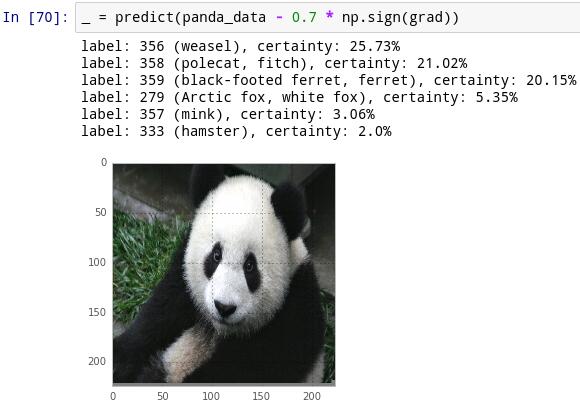
但是,這是為什么呢?讓我們來思考下損失函數。我們開始看到的結果顯示,它是熊貓的概率為99.57%。?log(0.9957)=0.0018。非常小!因此,添加一個delta倍會增加我們的損失函數(使它不像熊貓),而減去一個delta倍會減少我們的損失函數(使它更像熊貓)。但事實正好相反!我對這一點還是很困惑。
你欺騙不了狗
現在我們了解了數學原理,一個簡短的描述。我還嘗試去欺騙網絡,讓它識別先前那只可愛的小狗:

但對于狗,網絡會強烈地抵抗將其歸類為除狗之外的東西!我花了一些時間試圖讓它相信那只狗是一個網球,但是它仍然是一只狗。是其它種類的狗!但仍然還是一只狗。
我在一個會議上遇到了Jeff Dean(他在谷歌做神經網絡工作),并向他請教了這一點。他告訴我,這個網絡在訓練集中有一堆狗,比熊貓多。所以他假設是要訓練更好的網絡來識別狗。似乎有道理!
我認為這非常酷,這讓我覺得訓練更較精確的網絡更有希望。
關于這個話題還有另一件更有趣的事情–當我試圖讓網絡認為熊貓是一只禿鷲時,它在中間花了一點時間去思考它是否是鴕鳥。當我問Jeff Dean關于熊貓和狗這個問題時,他隨口提到了“熊貓鴕鳥空間”,而我并沒有提到讓網絡認為熊貓是禿鷲時曾思考過它是否是鴕鳥。這真的很酷,他用數據和這些網絡花足夠的時間一下子就清楚地知道鴕鳥和熊貓以某種關系緊密地結合在一起。
更少的神秘感
當我開始做這件事的時候,我幾乎不知道什么是神經網絡。現在我可以使它認為熊貓是一只禿鷹,并看到它是如何聰明的分類狗,我一點點的了解他們。我不再認為谷歌正在做的很神奇了,但對于神經網絡我仍然很疑惑。有很多需要學習!使用這種方式去欺騙它們,會消除一些神秘感,并且現在對它們的了解更多了。
相信你也可以的!這個程序的所有代碼都在(neural-networks-are-weird)這個倉庫中。它使用的是Docker,所以你可以輕易地安裝,而且你不需要一個GPU或是新電腦。這些代碼都是在我這臺用了3年的老GPU筆記本上運行的。
想要了解更多,請閱讀原論文:Explaining and Harnessing Adversarial Examples。論文內容簡短,寫得很好,會告訴你更多本文沒提及到的內容,包括如何使用這個技巧建立更好的神經網絡!
最后,感謝Mathieu Guay-Paquet, Kamal Marhubi以及其他在編寫這篇文章幫助過我的人!
譯者簡介:劉帝偉,中南大學軟件學院在讀研究生,關注機器學習、數據挖掘及生物信息領域。
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4321.html
摘要:論文可遷移性對抗樣本空間摘要對抗樣本是在正常的輸入樣本中故意添加細微的干擾,旨在測試時誤導機器學習模型。這種現象使得研究人員能夠利用對抗樣本攻擊部署的機器學習系統。 現在,卷積神經網絡(CNN)識別圖像的能力已經到了出神入化的地步,你可能知道在 ImageNet 競賽中,神經網絡對圖像識別的準確率已經超過了人。但同時,另一種奇怪的情況也在發生。拿一張計算機已經識別得比較準確的圖像,稍作調整,...
摘要:言簡意賅地說,我們的這款即時視覺翻譯,用到了深度神經網絡,技術。您是知道的,深度學習的計算量是不容小覷的。因為如果字符扭曲幅度過大,為了識別它,神經網絡就會在過多不重要的事物上,使用過高的信息密度,這就大大增加深度神經網絡的計算量。 前幾天谷歌更新了它們的翻譯App,該版本有諸多提升的地方,其中較大的是提升了所謂字鏡頭實時視頻翻譯性能和通話實時翻譯性能。怎么提升的呢?字鏡頭技術首創者、Goo...
摘要:解決辦法是多層神經網絡,底層神經元的輸出是高層神經元的輸入。這個例子中特征的形狀稱為異或,這種情況一個神經元搞不定,但是兩層神經元就能正確對其進行分類。年多倫多大學的等人構造了一個超大型卷積神經網絡,有層,共萬個神經元,千萬個參數。 0. 分類神經網絡最重要的用途是分類,為了讓大家對分類有個直觀的認識,咱們先看幾個例子:垃圾郵件識別:現在有一封電子郵件,把出現在里面的所有詞匯提取出來,送進一...

閱讀 1410·2021-11-17 09:33
閱讀 3018·2021-10-13 09:39
閱讀 2686·2021-10-09 10:01
閱讀 2447·2021-09-29 09:35
閱讀 3891·2021-09-26 10:01
閱讀 3518·2019-08-26 18:37
閱讀 3149·2019-08-26 13:46
閱讀 1910·2019-08-26 13:39




