資訊專欄INFORMATION COLUMN

摘要:在上個月發(fā)表博客文章深度學習機器學習模式識別之后,博士博士后及聯合創(chuàng)始人這一次帶領我們回顧年來人工智能領域三大范式邏輯學概率方法和深度學習的演變歷程。最令人興奮的,后來的頻率論與貝葉斯之爭,是一些被稱為概率圖模型的東西。
在上個月發(fā)表博客文章《深度學習vs機器學習vs模式識別》之后,CMU博士、MIT博士后及vision.ai聯合創(chuàng)始人Tomasz?
Malisiewicz這一次帶領我們回顧50年來人工智能領域三大范式(邏輯學、概率方法和深度學習)的演變歷程。通過本文我們能夠更深入地理解人工智能和深度學習的現狀與未來。
以下為正文:
今天,我們一起來回顧過去50年人工智能(AI)領域形成的三大范式:邏輯學、概率方法和深度學習。如今,無論依靠經驗和“數據驅動”的方式,還是大數據、深度學習的概念,都已經深入人心,可是早期并非如此。很多早期的人工智能方法是基于邏輯,并且從基于邏輯到數據驅動方法的轉變過程受到了概率論思想的深度影響,接下來我們就談談這個過程。
本文按時間順序展開,先回顧邏輯學和概率圖方法,然后就人工智能和機器學習的未來走向做出一些預測。

圖片來源:Coursera的概率圖模型課
1.邏輯和算法(常識性的“思考”機)
許多早期的人工智能工作都是關注邏輯、自動定理證明和操縱各種符號。John McCarthy于1959年寫的那篇開創(chuàng)性論文取名為《常識編程》也是順勢而為。
如果翻開當下最流行的AI教材之一——《人工智能:一種現代方法》(AIMA),我們會直接注意到書本開篇就是介紹搜索、約束滿足問題、一階邏輯和規(guī)劃。第三版封面(見下圖)像一張大棋盤(因為棋藝精湛是人類智慧的標志),還印有阿蘭·圖靈(計算機理論之父)和亞里士多德(最偉大的古典哲學家之一,象征著智慧)的照片。

AIMA的封面,它是CS專業(yè)本科AI課程的規(guī)范教材
然而,基于邏輯的AI遮掩了感知問題,而我很早之前就主張了解感知的原理是解開智能之謎的金鑰匙。感知是屬于那類對于人很容易而機器很難掌握的東西。(延伸閱讀:《計算機視覺當屬人工智能》,作者2011年的博文)邏輯是純粹的,傳統(tǒng)的象棋機器人也是純粹算法化的,但現實世界卻是丑陋的,骯臟的,充滿了不確定性。
我想大多數當代人工智能研究者都認為基于邏輯的AI已經死了。萬物都能完美觀察、不存在測量誤差的世界不是機器人和大數據所在的真實世界。我們生活在機器學習的時代,數字技術擊敗了一階邏輯。站在2015年,我真是替那些死守肯定前件拋棄梯度下降的傻子們感到惋惜。
邏輯很適合在課堂上講解,我懷疑一旦有足夠的認知問題成為“本質上解決”,我們將看到邏輯學的復蘇。未來存在著很多開放的認知問題,那么也就存在很多場景,在這些場景下社區(qū)不用再擔心認知問題,并開始重新審視這些經典的想法。也許在2020年。
2.概率,統(tǒng)計和圖模型(“測量”機)
概率方法在人工智能是用來解決問題的不確定性。《人工智能:一種現代方法》一書的中間章節(jié)介紹“不確定知識與推理”,生動地介紹了這些方法。如果你第一次拿起AIMA,我建議你從本節(jié)開始閱讀。如果你是一個剛剛接觸AI的學生,不要吝嗇在數學下功夫。
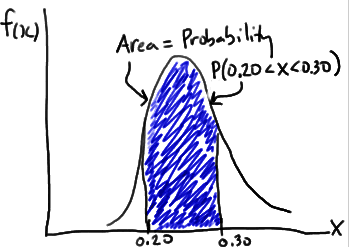
來自賓夕法尼亞州立大學的概率論與數理統(tǒng)計課程的PDF文件
大多數人在提到的概率方法時,都以為只是計數。外行人很容易想當然地認為概率方法就是花式計數方法。那么我們簡要地回顧過去統(tǒng)計思維里這兩種不相上下的方法。
頻率論方法很依賴經驗——這些方法是數據驅動且純粹依靠數據做推論。貝葉斯方法更為復雜,并且它結合數據驅動似然和先驗。這些先驗往往來自第一原則或“直覺”,貝葉斯方法則善于把數據和啟發(fā)式思維結合做出更聰明的算法——理性主義和經驗主義世界觀的完美組合。
最令人興奮的,后來的頻率論與貝葉斯之爭,是一些被稱為概率圖模型的東西。該類技術來自計算機科學領域,盡管機器學習現在是CS和統(tǒng)計度的重要組成部分,統(tǒng)計和運算結合的時候它強大的能力才真正釋放出來。
概率圖模型是圖論與概率方法的結合產物,2000年代中期它們都曾在機器學習研究人員中風靡一時。當年我在研究生院的時候(2005-2011),變分法、Gibbs抽樣和置信傳播算法被深深植入在每位CMU研究生的大腦中,并為我們提供了思考機器學習問題的一個極好的心理框架。我所知道大部分關于圖模型的知識都是來自于Carlos Guestrin和Jonathan Huang。Carlos Guestrin現在是GraphLab公司(現改名為Dato)的CEO,這家公司生產大規(guī)模的產品用于圖像的機器學習。Jonathan Huang現在是Google的高級研究員。
下面的視頻盡管是GraphLab的概述,但它也完美地闡述了“圖形化思維”,以及現代數據科學家如何得心應手地使用它。Carlos是一個優(yōu)秀的講師,他的演講不局限于公司的產品,更多的是提供下一代機器學習系統(tǒng)的思路。
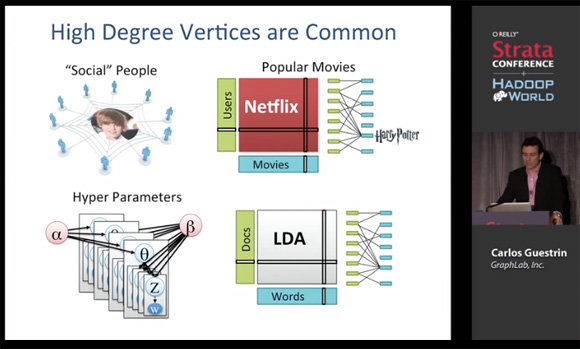
概率圖模型的計算方法介紹(視頻和PPT下載)
Dato CEO,Carlos Guestrin教授
如果你覺得深度學習能夠解決所有機器學習問題,真得好好看看上面的視頻。如果你正在構建一套推薦系統(tǒng),一個健康數據分析平臺,設計一個新的交易算法,或者開發(fā)下一代搜索引擎,圖模型都是完美的起點。
3.深度學習和機器學習(數據驅動機)
機器學習是從樣本學習的過程,所以當前較先進的識別技術需要大量訓練數據,還要用到深度神經網絡和足夠耐心。深度學習強調了如今那些成功的機器學習算法中的網絡架構。這些方法都是基于包含很多隱藏層的“深”多層神經網絡。注:我想強調的是深層結構如今(2015年)不再是什么新鮮事。只需看看下面這篇1998年的“深層”結構文章。
LeNet-5,Yann LeCun開創(chuàng)性的論文《基于梯度學習的文檔識別方法》
你在閱讀LeNet模型導讀時,能看到以下條款聲明:
要在GPU上運行這個示例,首先得有個性能良好的GPU。GPU內存至少要1GB。如果顯示器連著GPU,可能需要更多內存。
當GPU和顯示器相連時,每次GPU函數調用都有幾秒鐘的時限。這么做是必不可少的,因為目前的GPU在進行運算時無法繼續(xù)為顯示器服務。如果沒有這個限制,顯示器將會凍結太久,計算機看上去像是死機了。若用中等質量的GPU處理這個示例,就會遇到超過時限的問題。GPU不連接顯示器時就不存在這個時間限制。你可以降低批處理大小來解決超時問題。
我真的十分好奇Yann究竟是如何早在1998年就把他的深度模型折騰出一些東西。毫不奇怪,我們大伙兒還得再花十年來消化這些內容。
更新:Yann說(通過Facebook的評論)ConvNet工作可以追溯到1989年。“它有大約400K連接,并且在一臺SUN4機器上花了大約3個星期訓練USPS數據集(8000個訓練樣本)。”——LeCun
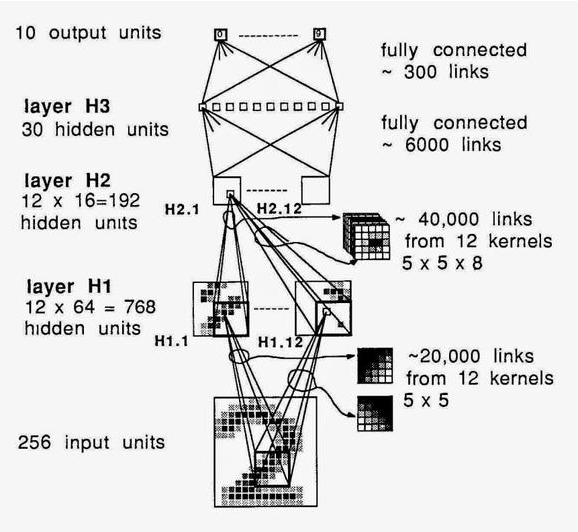
深度網絡,Yann1989年在貝爾實驗室的成果
注:大概同一時期(1998年左右)加州有兩個瘋狂的家伙在車庫里試圖把整個互聯網緩存到他們的電腦(他們創(chuàng)辦了一家G打頭的公司)。我不知道他們是如何做到的,但我想有時候需要超前做些并不大規(guī)模的事情才能取得大成就。世界最終將迎頭趕上的。
結論
我沒有看到傳統(tǒng)的一階邏輯很快卷土重來。雖然在深度學習背后有很多炒作,分布式系統(tǒng)和“圖形思維”對數據科學的影響更可能比重度優(yōu)化的CNN來的更深遠。深度學習沒有理由不和GraphLab-style架構結合,未來幾十年機器學習領域的重大突破也很有可能來自這兩部分的結合。
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規(guī)行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4318.html
摘要:雅虎開源了一個進行色情圖像檢測的深度學習解決方案。卷積神經網絡架構和權衡近年來,卷積神經網絡已經在圖像分類問題中取得了巨大成功。自年以來,新的卷積神經網絡架構一直在不斷改進標準分類挑戰(zhàn)的精度。 雅虎開源了一個進行色情圖像檢測的深度學習解決方案。據文章介紹,這可能是較早的識別 NSFW 圖像的開源模型。開源地址:https://github.com/yahoo/open_nsfw自動識別一張對...
摘要:這種無明確任務目標的聊天機器人也可以稱作為開放領域的聊天機器人。此外,聊天機器人應該給人個性表達一致的感覺。使用深度學習技術來開發(fā)聊天機器人相對傳統(tǒng)方法來說,整體思路非常簡單并可擴展。 作者:張俊林,中科院軟件所博士,技術書籍《這就是搜索引擎:核心技術詳解》、《大數據日知錄:架構與算法》作者。曾擔任阿里巴巴、百度、新浪微博資深技術專家,目前是用友暢捷通工智能相關業(yè)務負責人,關注深度學習在自然...
摘要:深度學習理論在機器翻譯和字幕生成上取得了巨大的成功。在語音識別和視頻,特別是如果我們使用深度學習理論來捕捉多樣的時標時,會很有用。深度學習理論可用于解決長期的依存問題,讓一些狀態(tài)持續(xù)任意長時間。 Yoshua Bengio,電腦科學家,畢業(yè)于麥吉爾大學,在MIT和AT&T貝爾實驗室做過博士后研究員,自1993年之后就在蒙特利爾大學任教,與 Yann LeCun、 Geoffrey Hinto...

閱讀 562·2023-04-25 14:26
閱讀 1310·2021-11-25 09:43
閱讀 3507·2021-09-22 15:25
閱讀 1471·2019-08-30 15:54
閱讀 547·2019-08-30 12:57
閱讀 793·2019-08-29 17:24
閱讀 3189·2019-08-28 18:13
閱讀 2716·2019-08-28 17:52




