

??????????????????????????????????????? AWS首席數據科學家Matt Wood
亞馬遜云計算AWS首席數據科學家Matt Wood認為,大數據和云計算是天作之合,云計算平臺的海量低成本的數據存儲與處理資源為大數據分享提供了可能。
Matt Wood一天的工作不僅僅是幫亞馬遜員工完成數據淘金工作,他還需要設法取悅亞馬遜的客戶。Wood幫助AWS的用戶利用亞馬遜云計算資源搭建大數據架 構,然后根據客戶需求設計產品,例如數據管道服務(Data Pipeline Service)和Redshift數據倉庫服務。
關于基于云計算的大數據服務的發展趨勢,記者采訪了Matt Wood,會談的亮點摘錄如下:
從資源優先到業務優先
不久前,計算機科學家已經掌握了今日之所謂數據科學的理論和概念,但當時的資源有限,能夠進行的數據分析類型也很有限。
如今,數據存儲和處理資源已經極大豐富和廉價,這使得大數據的概念成為可能。而云計算則進一步降低了數據存儲和處理資源的成本,容量也更大。這意味著數據分析的觀念正在經歷一次重大的范型轉移,從過去資源優先轉向以企業需求為先。
如果他們能夠突破傳統的數據采樣和處理模式,一個人就能專注于要做的事情,因為資源太多了。例如,點評網站Yelp允許開發者無限制使用Elastic MapReduce,這樣開發者就不必為了測試某個瘋狂想法而走繁瑣的資源申請流程。Yelp能夠在一年前發現網站流量的移動化趨勢并及時開展移動業務都得益于此。
數據的問題不都是規模
總的來說,客戶的數據問題并不都是如何更低的成本存儲更多的數據,你不一定需要1PB的數據才能分析出誰是你社交游戲的用戶。
實際上,能夠無限制的存儲和處理數據本身會產生新的問題。公司希望能夠保存所有產生的數據,這會導致復雜性增加。從亞馬遜的S3和DynamoDB服務到企業數據中心的物理服務器,當數據在所有的庫中都堆積如山時,數據轉移和復用的難度也會變得很大。
AWS新推出的數據管道服務(Data Pipeline Service)就是為了解決這個問題。管道非常復雜,從運行一個簡單的數據業務邏輯到在Elastic MapReduce上運行所有的批任務,數據管道服務的目的就是將數據的移動和處理自動化,用戶無需自己建立這些工作流程并手動運行。
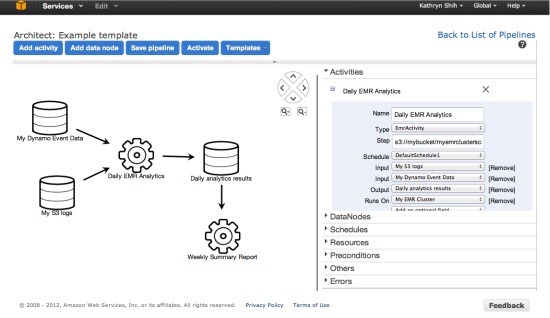
???????????????????????????????????? AWS數據管道服務控制臺
把大數據快遞給云計算
人們有時候會質疑云計算與大數據任務之間的相關度,因為如果將企業內部系統產生的數據都上傳到云端,由于受到網速限制,數據規模越大,上傳的時間就越長。為了解決這個問題,亞馬遜想盡各種辦法,包括與Aspera合作,甚至與那些研究在互聯網上快速轉移大文件(Wood說見過700MB/秒的技術)的開源項目合作。此外,亞馬遜還取消了傳入數據的收費,并開啟了并行上傳功能。此外亞馬遜還與數據中心運營者合作啟動了直連項目(Direct Connect Program),為亞馬遜AWS設施提供專線連接。
最后,如果客戶的數據量實在太大,網速又不夠快,還可以直接將存有數據的硬盤快遞給亞馬遜。
協作是未來趨勢
當數據遷移到云端后,就開啟了一種全興的協作方式,研究人員,乃至整個行業都能訪問和分享這些過去因體量太大而無法移動的數據。一些產生海量數據的行業已經開始在云端分享數據,例如AWS上已經托管的1000個基因組項目。
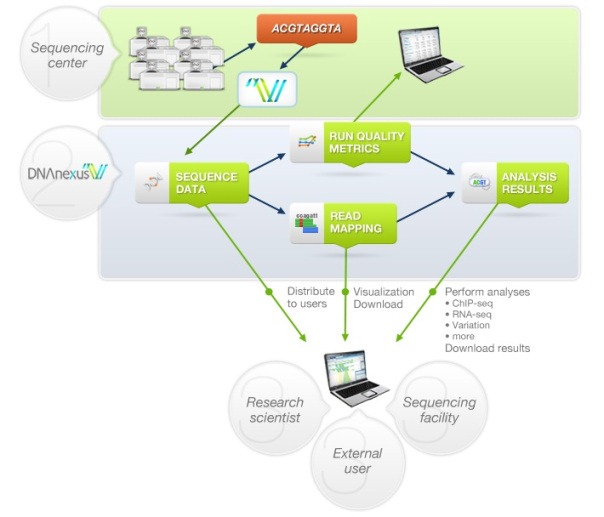
??????????????????????????????????????????DNAnexus的云架構
遺傳學項目從云計算中受益匪淺,雖然AWS上的1000個基因組項目的數據庫只有200TB,但是單個項目很少有足夠的預算存儲這么多數據并與同事分享。即使在資金充裕的醫藥領域,亞馬遜CTO Werner Vogels曾說過,醫藥企業正在使用云計算分享數據,企業們也無需花費時間和金錢"重新發明車輪"。
不再需要超級計算機?
Wood對亞馬遜高性能計算客 戶在AWS平臺上的工作印象深刻——這些工作過去必須依賴超級計算機才能完成。這要感謝AWS的合作伙伴Cycle Computing,維斯康辛大學如今在AWS上能夠一周內完成過去需要116年的計算任務。AWS正在不斷增加實例的配置和性能,從較大的250GB內 存到GPU集群計算實例,AWS都將提供。出于成本的考慮,AWS目前僅在一部分市場提供集群計算實例和Elastic MapReduce。
如今很多運行數據密集型工作負載的企業都開始將目光投向云計算。大數據(尤其是Hadoop)和云計算年紀相仿,相輔相成,可謂天作之合。
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4039.html







