資訊專欄INFORMATION COLUMN

摘要:近十年監控系統開發經驗,具有構建基于大數據平臺的海量高可用分布式監控系統研發經驗。監控多維數據特點監控的核心是對監控對象的指標采集處理檢測和分析。通過單一對象的指標反映的狀態已不能滿足業務監控需求。
吳樹生:騰訊高級工程師,負責SNG大數據監控平臺建設。近十年監控系統開發經驗,具有構建基于大數據平臺的海量高可用分布式監控系統研發經驗。
前言
在2015年構建多維監控平臺時用kmeans做了異常點多維根因分析的嘗試,后因種種原因而擱置了深入研究。雖中止了兩年,但一直未忘當初的夢想。隨著掀起AI浪潮,平臺和技術也已成熟,監控團隊歷經兩個月的重新調研和預研后取得突破,另辟蹊徑地找到異常點的多維根因分析方法,我們稱為MDRCA(Multi-Dimensional Root Cause Analysis)算法。
這篇文章為持續兩年多的夢畫上一個句號,它是監控團隊第一代成果總結:介紹監控多維數據特點、基于kmeans多維根因分析方法、第一代MDRCA算法和AI在監控領域應用經驗。筆者不敢貪功,僅將成果描述出來,如有偏差不全之處還望與讀者多交流修正。
監控多維數據特點
監控的核心是對監控對象的指標采集、處理、檢測和分析。傳統監控的對象是一個單一的實體,例如服務器、路由器、交換機等。這些單一對象通過指標反映運行狀態,例如服務器的狀態指標有CPU使用率、內存使用大小、磁盤IO和網卡流量等。
傳統監控系統通過定時任務采集這些監控對象的指標數據,經過校正后存儲起來用于展示和異常檢測。異常檢測通過判斷指標是否偏離設置的閾值來標識異常事件。
在傳統監控之后,將監控對象擴展為一個虛擬的業務功能或業務模塊,這時的對象仍是單一的,可用一個ID表達。對象的指標也相應的轉變為反映業務功能狀態的指標,例如接口調用次數、http返回200次數、http返回500次數等。
這些指標數據通常需要在應用程序埋點上報。數據處理、存儲和異常檢測與傳統監控一致。
隨著業務擴展,業務模塊間的關系愈加復雜。通過單一對象的指標反映的狀態已不能滿足業務監控需求。業務異常往往體現在多個對象的指標異常,用戶收到告警后需要在大量指標數據中剝絲抽繭般地分析異常原因。
這個狀況伴生了運維痛點:一是告警量大;二是分析耗時長。
解決這一問題的關鍵是建立對象和指標的關聯模型。通過相關性收斂對象和指標,減少告警量。并通過關聯模型中的調用關系模型和層次關系模型快速找到問題根因。對傳統監控中的對象翻譯為多維度屬性后對指標數據進行處理、存儲和異常檢測,形成多維監控。對象的維度屬性將對象分類,構建了對象的關聯模型。
這樣對單一對象的異常檢測可提煉為對某一維度屬性的異常檢測,從而減少檢測對象。在發生異常后根據維度下鉆分析,有規則地提供分析路徑,避免盲目分析,減少分析耗時。
用A、B和C這三個業務模塊來說明上面介紹的多維監控形成過程:
這三個模塊的調用關系為A調用B,B調用C。C根據機房劃分為C1和C2兩個子模塊。A模塊下有2臺機器(10.0.1.1和10.0.1.2),B下有3臺機器(10.0.2.1、10.0.2.2和10.0.2.3),C1下有1臺機器(10.0.3.11),C2下有2臺機器(10.0.3.21和10.0.3.22)。
假設C模塊下的機器負載已飽和,也就是說如果其中有一臺機器異常,則提供有損服務,影響B和A的成功率。如果C2模塊下的10.0.3.21機器異常,則會觸發10.0.3.21機器告警及A和B下的5臺機器告警,總共有6個對象產生告警。
在實際運營中,往往有多個指標反映一個功能狀態,進一步增加告警量。
為解決例子描述的告警量大和分析耗時痛點,將監控對象的機器翻譯成業務模塊,從而形成一個業務模塊和機器的多維度數據。異常檢測也由機器維度更改為業務模塊維度,減少檢測對象的數量。在分析異常時,沿著業務模塊到機器的層級關系可查找出異常點。
還有一種多維數據的場景是面向APP應用。APP的請求自身帶有版本、機型、運營商和地域這些維度信息。發現指標異常后需要判斷是哪個維度特性造成的異常或異常影響的維度范圍。
監控多維數據由三部分組成:
時間維度,監控系統時間粒度通常取1分鐘粒度;
業務特性維度,后端服務的維度通常為業務模塊,APP監控的維度通常為版本、機型、運營商和地域;
指標,如成功率,耗時和延時分段統計等。
下表是一個SNG移動監控的多維數據樣例:
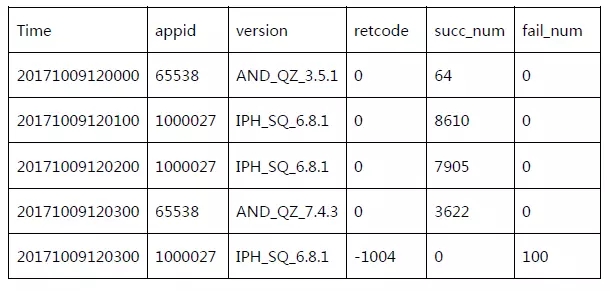
基于Kmeans分類的多維根因分析方法
在建設多維監控平臺初期,為解決人工逐個觀察各維度的異常數據帶來的效率問題,使用kmeans對成功率指標分類。推薦出分類后的異常維度后再做二次分析。
下圖是2014年12月手Q接入層SSO模塊的成功率分鐘曲線。當天中午13:00附近接入層成功率由接近99.9%下降為99.5%。

發生異常后,通過人工分析的步驟為分別查看某一維度的成功率,找出成功率低并且總量大的維度條件。選定最可疑的維度條件再重復剛剛介紹的分析過程。直到遍歷完所有維度,找出成功率下降的維度組合。
例如:模塊維度有A、B和C三個模塊,A模塊下有命令字(a1,a2和a3),B模塊下有命令字(b1,b2),C模塊下有命令字(c1,c2和c3)。在異常點的指標統計如下表:

按模塊觀察,模塊A的成功率為99.75%,總數為300;模塊B的成功率為95.83%,總數為150;模塊C的成功率為99.4%,總數為300。
經過比較,模塊B成功率顯著低于模塊A和模塊C,并且接近95%。模塊B成為可以維度條件。
接著觀察模塊B條件下的命令字,其中命令字b1的成功率顯著低于異常點平均成功率95%。
分析完成后確定模塊B的命令字b1造成成功率下降。
使用kmeans對成功率分類模擬人工分類操作。對各維度的成功率進行分類后可以得到顯著差異的維度條件。
如對上面例子的各模塊成功率做kmeans分類,可以獲得成功率有顯著差異的模塊B和命令字b1。稱具有顯著差異的維度集合為反向分析。反向分析結果在二次分析時需要特別關注。
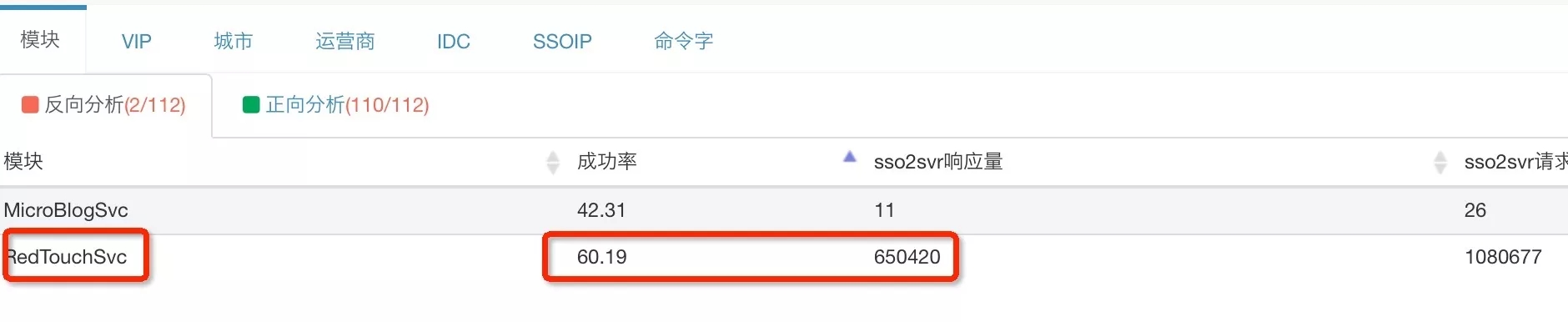
下面兩張圖是對手 Q 接入層異常模塊分析的反向分析結果, 結合接入層的響應量判斷出異常模塊的RedTouchSvc,異常命令字為RedTouchSvc.ClientReport。
MDRCA(Multi-Dimensional Root Cause Analysis)算法
基于Kmeans對成功率分析方法在一定程度上提升了問題分析效率,但存在兩個問題:
只能應用于成功率的指標分析,對于累積量的指標如請求量則失去作用;
未引入成功率總量的權重,分類后推薦出的異常維度條件需要二次人工分析。
中斷近兩年,并在建設完成多維監控平后,監控團隊重新投入人力調研實現多維根因分析方法。在監控領域AI剛剛起步,可參考的論文和經驗較少。我們在走了一段彎路后,借鑒和改進廣告推薦中的異常分析算法,實現MDRCA算法,解決Kmeans成功率分類方法的兩個問題。
對于指標我們分兩類:單一變量指標和復合指標。
單一變量指標:請求量、響應量等不依賴其他變量獨立統計的指標。
復合指標:成功率這類需要通過兩個或多個變量做除法計算的指標。
這里我們用單一變量指標請求量來說明MDRCA算法的原理。
假設一個業務的請求量X(m)的某一維度下有m個值,分解到各維度的請求量為(x1,x2,…,xn,n=m)。X(m)可用公式表示:
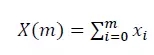
在異常時刻t 觀察到異常的請求量為A(m)。A(m) 由各維度在t 時刻的值組成。A(m) 可用公式表示:
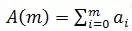
也就是說觀察到的總體請求量異常由各維度的異常分量組成。
根據歷史觀察值獲得時刻 t 的請求量預測值F(m)。F(m)由各維度的預測值組成。F(m) 可用公式表示:
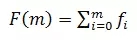
生成預測值算法有多種,一種方法是取前一天對于時刻 t 的值。在本文的 MDRCA 算法中,預測值取離前7天的 [t-20,t] 時刻的平均值最近的一天的 t 時刻作為參考點。
在MDRCA算法中定義一個值 Explanatory Power,簡稱EP來衡量觀察維度 i 下維度值 j 對異常的占比,或稱貢獻度。EP的計算公式為:
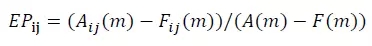
例如,異常時刻t的請求量為1000,根據歷史數據預測時刻t的請求量為1500。維度 i 下的維度值 j 在異常時刻 t 的請求量值為200,根據j的歷史數據預測時刻 t 下 j 的請求量值應為500。根據公式計算可知j的EP值為(200-500)/(1000-1500)=0.6。
當維度下有值的變化方向與異常值變化方向相反時,EP取值為負數。這時其他維度值的EP取值也可能大于1。但是觀察維度下所有維度值的EP和為1。
MDRCA算法中定義另一個值Surprise來衡量觀察維度 i 下維度值 j 的變化差異。為計算JSD,先計算兩個變量 p 和 q 。其中 p 為維度值 j 在預測值中的占比,q 為維度值 j 在異常值中的占比。p 和 q 的計算公式如下:
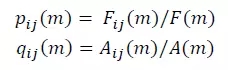
p 和 q 的取值為(0,1)。獲得 p 和 q 后,維度值 j 的變化差異計算公式為:
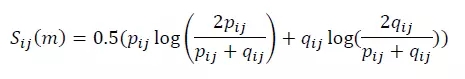
至此,我們獲得衡量維度值 j 的異常貢獻值 EP 和變化差異值 Surprise。對這兩個值用四象限方法解釋如下:
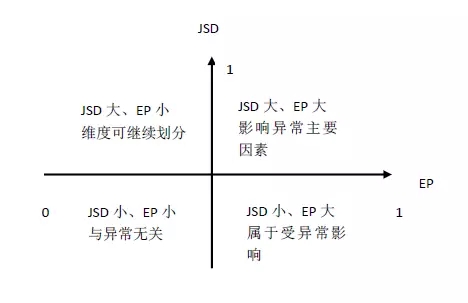
從四象限中可知,維度中 EP 和 Surprise 分類大的維度值可作為候選維度。對 EP 和Surprise 分類可采用前面介紹的 kmeans 分類方法。
選出每個維度下的候選維度集合后,計算各集合的 Surprise 和用于衡量各維度的異常變化差異。差異越大的維度越有可能成為異常的主要影響因素。
在這還用了另一個技巧: 異常的主要影響因素往往是少量維度值的集合。所以取后續集合的 Surprise均值大的維度作為優先選擇的條件。選出維度后,在選擇維度中貢獻大的維度值作為優先條件。
MDRCA算法的多維根因分析方法如下:

以上為對單一變量的MDRCA算法介紹。對成功率這類復合指標EP計算為求分子分母兩個變量的偏導,Surprise的計算方法為求分子和分母變量的Surprise值之和。
AI應用經驗
為借助AI的東風解決監控領域的痛點,同時摸索AI在監控的實踐經驗。我們拿智能多維分析探路。中間經歷曲折踩坑,反思當中的過程有幾點經驗值得在后續開發過程中借鑒。
其一,梳理AI應用開發過程的角色。
新近的互聯網浪潮AI,必然吸引不少新老程序員踏浪,如何才能在浪中不翻船呢?
經過摸索后,我們認為在AI應用開發中需要以下四類角色:
領域專家
深入了解業務的領域專家能把握住該業務的核心痛點,結合AI找出著力點和給AI專家提供業務領域信息;
AI專家
這個角色知識淵博、深入掌握算法和實踐。理解領域專家提供的痛點信息后,預研并提供算法指導和支撐。
算法工程化專家
這個角色拿到AI專家提供的算法后做工程化實現和優化提升算法性能。
應用開發專家
這類角色是將AI成果上線應用,提升易用性和用戶體驗,同時在應用中預設收集用戶操作和反饋信息的渠道。
其二,先調研、讀論文和參考業界做法的研究步驟。
讀論文很重要。領域專家梳理出核心痛點,業界也存在類似痛點,并且有相關研究。不妨先參考業界做法,讀懂和理解相關論文和應用場景后再做改進。
其三,溝通交流。
在監控領域AI應用剛剛起步,大家還在摸著石頭過河,可參考的成功案例較少。所謂三個臭皮匠抵過一個諸葛亮,聚在一起學習交流,有利于糾正錯誤認識,明晰算法應用場景和擴展思路。
參考資料:
[1] Adtributor: Revenue Debugging in Advertising Systems
Ranjita Bhagwan,Rahul Kumar,Ramachandran Ramjee, George Varghese,Surjyakanta Mohapatra, Hemanth Manoharan, and Piyush Shah, Microsoft, 2014
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/3958.html
摘要:近十年監控系統開發經驗,具有構建基于大數據平臺的海量高可用分布式監控系統研發經驗。的哈勃多維監控平臺在完成大數據架構改造后,嘗試引入能力,多維根因分析是其中一試點,用于摸索的應用經驗。 作者丨吳樹生:騰訊高級工程師,負責SNG大數據監控平臺建設。近十年監控系統開發經驗,具有構建基于大數據平臺的海量高可用分布式監控系統研發經驗。 導語:監控數據多維化后,帶來新的應用場景。SNG的哈勃多...
摘要:從那個時候開始,我就開始用一些機器學習人工智能的技術來解決的運維問題了,有不少智能運維的嘗試,并發表了不少先關論文和專利。而處理海量高速多樣的數據并產生高價值,正是機器學習的專長。也就是說,采用機器學習技術是運維的一個必然的走向。 大家上午好,非常榮幸,能有這個機會,跟這么多的運維人一起交流智能運維。最近這兩年運維里面有一個很火的一個詞叫做AIOps(智能運維)。我本人是老運維了,在2000...
摘要:本文將介紹美團點評整個數據庫平臺的演進歷史,以及我們當前的情況和面臨的一些挑戰,最后分享一下我們從自動化到智能化運維過渡時,所進行的思考探索與實踐。 從自動化到智能化運維過渡時,美團DBA團隊進行了哪些思考、探索與實踐?本文根據趙應鋼在第九屆中國數據庫技術大會上的演講內容整理而成,部分內容有更新。 背景 近些年,傳統的數據庫運維方式已經越來越難于滿足業務方對數據庫的穩定性、可用性、靈活...
摘要:本文將介紹美團點評整個數據庫平臺的演進歷史,以及我們當前的情況和面臨的一些挑戰,最后分享一下我們從自動化到智能化運維過渡時,所進行的思考探索與實踐。 從自動化到智能化運維過渡時,美團DBA團隊進行了哪些思考、探索與實踐?本文根據趙應鋼在第九屆中國數據庫技術大會上的演講內容整理而成,部分內容有更新。 背景 近些年,傳統的數據庫運維方式已經越來越難于滿足業務方對數據庫的穩定性、可用性、靈活...

閱讀 2488·2021-08-11 11:16
閱讀 2926·2019-08-30 15:55
閱讀 3332·2019-08-30 12:53
閱讀 1568·2019-08-29 13:28
閱讀 3264·2019-08-28 18:17
閱讀 935·2019-08-26 12:19
閱讀 2466·2019-08-23 18:27
閱讀 695·2019-08-23 18:17





