資訊專欄INFORMATION COLUMN

摘要:近兩年,為什么都開始談論起這個新名詞了先說我的想法,其實還是用戶需求驅動數據服務,大家開始關注的根本原因是用戶需求發生了質變,過去的數據倉庫模式以及涉及到的相關組件沒有辦法滿足日益進步的用戶需求。
近兩年,為什么都開始談論起 Data Lake 這個”新名詞”了?
先說我的想法,其實還是用戶需求驅動數據服務,大家開始關注 Data Lake 的根本原因是用戶需求發生了質變,過去的數據倉庫模式以及涉及到的相關組件沒有辦法滿足日益進步的用戶需求。
趨勢
這里聊一個很重要的趨勢:
數據實時化
當然這里有很多其他的趨勢,比如低成本化、設計云原生化等,但總體上我還是認為數據實時化是近一兩年來最熱門、最明顯且最容易讓人看到收益的一個趨勢。
數據倉庫過去的模式大家可能都很了解,將整個數據倉庫劃分為 ODS、DWD、DWS,使用 Hive 作為數據存儲的介質,使用 Spark 或者 MR 來做數據清洗的計算。這樣的數據倉庫設計很清晰,數據也比較容易管理,所以大家開開心心地使用這套理論和做法將近 10 年左右。
在這 10 年的時間里,主流的互聯網公司在數據技術上的玩法并沒有多大的改變,比如推薦需要用到的用戶畫像、電商里商品的標簽、好友傳播時用的圖、金融風控數據體系,站在更高的一個角度看,我們會發現,十年前做的事情,比如用戶畫像表,如果你現在去做推薦服務,還是需要這個表。這樣會產生一個什么現象?十年的互聯網行業的人才積累、知識積累、經驗積累,讓我們可以更加容易地去做一些事情,比如十年前很難招聘到的懂推薦數據的人才,水平在如今也就是一個行業的平均值罷了。
既然這些事情變得更好做了,人才更多了,我們就期望在事情上做的更精致。因為從業務上講,我去推薦短視頻,讓用戶購買東西,這個需求是沒有止境的,是可以永遠做下去的。所以以前我可能是 T+1 才能知道用戶喜歡什么,現在這個需求很容易就達到之后,我希望用戶進來 10s 之后的行為就告訴我這個用戶的喜好;以前可能做一些粗粒度的運營,比如全人群投放等,現在可能要轉化思路,做更加精細化的運營,給每個用戶提供個性化定制的結果。
技術演進1
數據實時化沒問題,但是對應到技術上是什么情況呢?是不是我們要在實時領域也搭一套類似離線數據倉庫的數據體系和模式?
是的,很多公司確實是將實時數據流劃分為了不同層級,整體層級的劃分思路和離線倉庫類似,但是實時數據的載體就不是 Hive 或者 Hdfs 了,而是要選擇更加實時的消息隊列,比如 Kafka,這樣就帶來了很多問題,比如:
消息隊列的存儲時間有限
消息隊列沒有查詢分析的功能
回溯效率比文件系統更差
除了實時數據載體的問題,還有引入實時數倉后,和離線數倉的統一的問題,
比如實時數倉的數據治理、權限管理,是不是要多帶帶做一套?
如何統一實時數據和離線數據的計算口徑?
兩套數據系統的資源浪費嚴重,成本提高?
舉一個比較現實的例子,假設我們構造了一個實時計算指標,在發現計算錯誤后我們需要修正昨天的實時數據,這種情況下一般是另外寫一個離線任務,從離線數倉中獲取數據,再重新計算一遍,寫入到存儲里。這樣的做法意味著我們在每寫一個實時需求的同時,都要再寫一個離線任務,這樣的成本對于一個工程師是巨大的。
技術演進2
實時系統的成本太大了,這也是讓很多公司對實時需求望而生畏的原因之一。所以這樣去建設實時數倉的思路肯定不行啊,等于我要招兩倍的人才(可能還不止),花兩倍的時間,才能做一個讓我的業務可能只提升 10% 的功能。從技術的角度來看,是這兩套系統的技術棧不一樣造成了工程無法統一。那么,Data Lake 就是用來解決這樣一個問題,比如我一個離線任務,能不能既產生實時指標,也產生離線指標,類似下圖這樣:
除了計算層面上,在數據管理上,比如中間表的 schema 管理,數據權限管理,能否做到統一?在架構上實現統一后,我們在應對實時需求時,可以將實時離線的冗余程度降到最低,甚至能夠做到幾乎沒有多余成本。
這塊我們也在積極探索,國內互聯網公司的主流做法還是停留在 【技術演進1】 的階段,相信隨著大家的努力,很快就會出現優秀且成功的實踐。
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/125909.html
摘要:數據湖通常更大,其存儲成本也更為廉價。高存儲成本數倉和數據湖都是為了降低數據存儲的成本。數據停滯在數據湖中,數據停滯是一個最為嚴重的問題,如果數據一直無人治理,那將很快變為數據沼澤。數據湖(Data Lake),湖倉一體(Data Lakehouse)儼然已經成為了大數據領域最為火熱的流行詞,在接受這些流行詞洗禮的時候,身為技術人員我們往往會發出這樣的疑問,這是一種新的技術嗎,還是僅僅只是概...
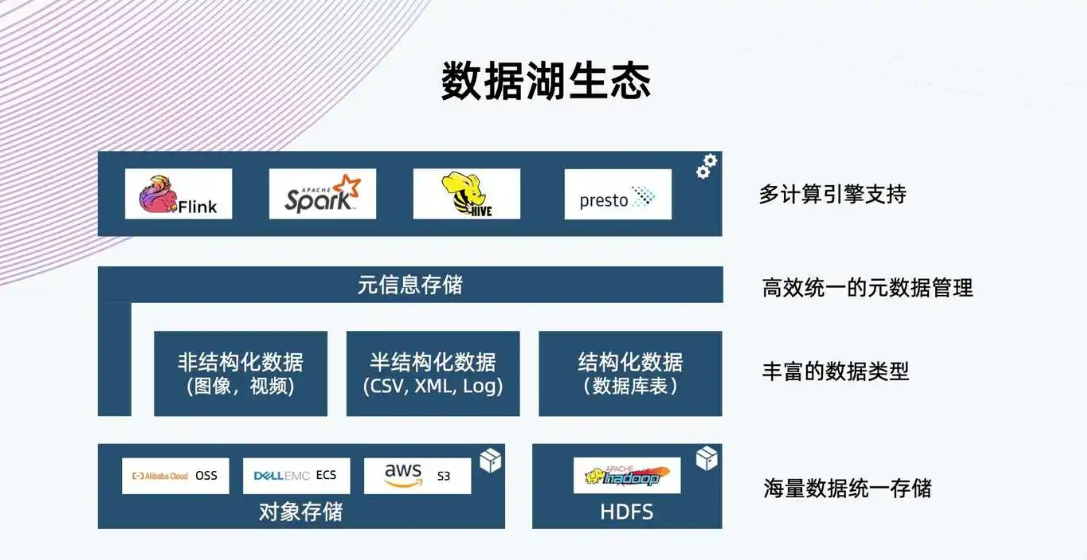
1、數據結構:數據倉庫只能存儲經過處理和提煉的數據,而數據湖存儲尚未出于某種目的處理的原始數據。因此,數據湖需要比數據倉庫大得多的存儲容量,且數據靈活、分析迅速,非常適合機器學習。2、加工:數據倉庫使用寫入時序模式的方法來處理數據以賦予其形狀和結構,而數據湖對原始數據使用讀取模式來處理它。3、成本:存儲在數據倉庫中的成本可能很高,尤其是在有大量數據的情況下,而數據湖是專為低成本數據存儲而設計,成本...
摘要:今天就我和大家來談談大數據領域的一些新變化新趨勢。結語以上四個方面是數據科學在實踐發展中提出的新需求,誰能在這些方面得到好的成績,誰便會在這個大數據時代取得領先的位置。 從2012年開始,幾乎人人(至少是互聯網界)言必稱大數據,似乎不和大數據沾點邊都不好意思和別人聊天。從2016年開始,大數據系統逐步開始在企業中進入部署階段,大數據的炒作逐漸散去,隨之而來的是應用的蓬勃發展期,一些代表...
摘要:今天就我和大家來談談大數據領域的一些新變化新趨勢。結語以上四個方面是數據科學在實踐發展中提出的新需求,誰能在這些方面得到好的成績,誰便會在這個大數據時代取得領先的位置。 從2012年開始,幾乎人人(至少是互聯網界)言必稱大數據,似乎不和大數據沾點邊都不好意思和別人聊天。從2016年開始,大數據系統逐步開始在企業中進入部署階段,大數據的炒作逐漸散去,隨之而來的是應用的蓬勃發展期,一些代表...

閱讀 3528·2023-04-25 20:09
閱讀 3733·2022-06-28 19:00
閱讀 3053·2022-06-28 19:00
閱讀 3071·2022-06-28 19:00
閱讀 3160·2022-06-28 19:00
閱讀 2870·2022-06-28 19:00
閱讀 3031·2022-06-28 19:00
閱讀 2628·2022-06-28 19:00




