資訊專欄INFORMATION COLUMN

摘要:數據湖通常更大,其存儲成本也更為廉價。高存儲成本數倉和數據湖都是為了降低數據存儲的成本。數據停滯在數據湖中,數據停滯是一個最為嚴重的問題,如果數據一直無人治理,那將很快變為數據沼澤。
數據湖(Data Lake),湖倉一體(Data Lakehouse)儼然已經成為了大數據領域最為火熱的流行詞,在接受這些流行詞洗禮的時候,身為技術人員我們往往會發出這樣的疑問,這是一種新的技術嗎,還是僅僅只是概念上的翻新(新瓶裝舊酒)呢?它到底解決了什么問題,擁有什么樣新的特性呢?它的現狀是什么,還存在什么問題呢?
帶著這些問題,今天就從筆者的理解,為大家揭開 Data Lakehouse 的神秘面紗,來探一探其技術的本質到底是什么?
Data Lakehouse(湖倉一體)是新出現的一種數據架構,它同時吸收了數據倉庫和數據湖的優勢,數據分析師和數據科學家可以在同一個數據存儲中對數據進行操作,同時它也能為公司進行數據治理帶來更多的便利性。那么何為Data Lakehouse呢,它具備些什么特性呢?
本文參考自 https://www.xplenty.com/glossary/what-is-a-data-lakehouse/ 和 https://databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html。
Data Lakehouse具備什么特性?
一直以來,我們都在使用兩種數據存儲方式來架構數據:
數據倉庫:數倉這樣的一種數據存儲架構,它主要存儲的是以關系型數據庫組織起來的結構化數據。數據通過轉換、整合以及清理,并導入到目標表中。在數倉中,數據存儲的結構與其定義的schema是強匹配的。
數據湖:數據湖這樣的一種數據存儲結構,它可以存儲任何類型的數據,包括像圖片、文檔這樣的非結構化數據。數據湖通常更大,其存儲成本也更為廉價。存儲其中的數據不需要滿足特定的schema,數據湖也不會嘗試去將特定的schema施行其上。相反的是,數據的擁有者通常會在讀取數據的時候解析schema(schema-on-read),當處理相應的數據時,將轉換施加其上。
現在許多的公司往往同時會搭建數倉、數據湖這兩種存儲架構,一個大的數倉和多個小的數據湖。這樣,數據在這兩種存儲中就會有一定的冗余。
Data Lakehouse的出現試圖去融合數倉和數據湖這兩者之間的差異,通過將數倉構建在數據湖上,使得存儲變得更為廉價和彈性,同時lakehouse能夠有效地提升數據質量,減小數據冗余。在lakehouse的構建中,ETL起了非常重要的作用,它能夠將未經規整的數據湖層數據轉換成數倉層結構化的數據。Data Lakehouse概念是由Databricks在此文[1]中提出的,在提出概念的同時,也列出了如下一些特性:
事務支持:Lakehouse可以處理多條不同的數據管道。這意味著它可以在不破壞數據完整性的前提下支持并發的讀寫事務。
Schemas:數倉會在所有存儲其上的數據上施加Schema,而數據湖則不會。Lakehouse的架構可以根據應用的需求為絕大多數的數據施加schema,使其標準化。
報表以及分析應用的支持:報表和分析應用都可以使用這一存儲架構。Lakehouse里面所保存的數據經過了清理和整合的過程,它可以用來加速分析。同時相比于數倉,它能夠保存更多的數據,數據的時效性也會更高,能顯著提升報表的質量。
數據類型擴展:數倉僅可以支持結構化數據,而Lakehouse的結構可以支持更多不同類型的數據,包括文件、視頻、音頻和系統日志。
端到端的流式支持:Lakehouse可以支持流式分析,從而能夠滿足實時報表的需求,實時報表在現在越來越多的企業中重要性在逐漸提高。
計算存儲分離:我們往往使用低成本硬件和集群化架構來實現數據湖,這樣的架構提供了非常廉價的分離式存儲。Lakehouse是構建在數據湖之上的,因此自然也采用了存算分離的架構,數據存儲在一個集群中,而在另一個集群中進行處理。
開放性:Lakehouse在其構建中通常會使Iceberg,Hudi,Delta Lake等構建組件,首先這些組件是開源開放的,其次這些組件采用了Parquet,ORC這樣開放兼容的存儲格式作為下層的數據存儲格式,因此不同的引擎,不同的語言都可以在Lakehouse上進行操作。
Lakehouse的概念最早是由Databricks所提出的,而其他的類似的產品有Azure Synapse Analytics。Lakehouse技術仍然在發展中,因此上面所述的這些特性也會被不斷的修訂和改進。
Data lakehouse解決了什么問題
那說完了Data Lakehouse的特性,它到底解決了什么問題呢?
這些年來,在許多的公司里,數倉和數據湖一直并存且各自發展著,也沒有遇到過太過嚴重的問題。但是仍有一些領域有值得進步的空間,比如:
數據重復性:如果一個組織同時維護了一個數據湖和多個數倉,這無疑會帶來數據冗余。在最好的情況下,這僅僅只會帶來數據處理的不高效,但是在最差的情況下,它會導致數據不一致的情況出現。Data Lakehouse統一了一切,它去除了數據的重復性,真正做到了Single Version of Truth。
高存儲成本:數倉和數據湖都是為了降低數據存儲的成本。數倉往往是通過降低冗余,以及整合異構的數據源來做到降低成本。而數據湖則往往使用大數據文件系統(譬如Hadoop HDFS)和Spark在廉價的硬件上存儲計算數據。而最為廉價的方式是結合這些技術來降低成本,這就是現在Lakehouse架構的目標。
報表和分析應用之間的差異:報表分析師們通常傾向于使用整合后的數據,比如數倉或是數據集市。而數據科學家則更傾向于同數據湖打交道,使用各種分析技術來處理未經加工的數據。在一個組織內,往往這兩個團隊之間沒有太多的交集,但實際上他們之間的工作又有一定的重復和矛盾。而當使用Data Lakehouse后,兩個團隊可以在同一數據架構上進行工作,避免不必要的重復。
數據停滯(Data stagnation):在數據湖中,數據停滯是一個最為嚴重的問題,如果數據一直無人治理,那將很快變為數據沼澤。我們往往輕易的將數據丟入湖中,但缺乏有效的治理,長此以往,數據的時效性變得越來越難追溯。Lakehouse的引入,對于海量數據進行catalog,能夠更有效地幫助提升分析數據的時效性。
潛在不兼容性帶來的風險:數據分析仍是一門興起的技術,新的工具和技術每年仍在不停地出現中。一些技術可能只和數據湖兼容,而另一些則又可能只和數倉兼容。Lakehouse靈活的架構意味著公司可以為未來做兩方面的準備。
Data Lakehouse存在的問題 現有的Lakehouse架構仍存在著一些問題,其中最為顯著的是:
大一統的架構:Lakehouse大一統的架構有許多的優點,但也會引入一些問題。通常,大一統的架構缺乏靈活性,難于維護,同時難以滿足所有用戶的需求,架構師通常更傾向于使用多模的架構,為不同的場景定制不同的范式。
并非現有架構上本質的改進:現在對于Lakehouse是否真的能夠帶來額外的價值仍存在疑問。同時,也有不同的意見 - 將現有的數倉、數據湖結構與合適的工具結合 - 是否會帶來類似的效率呢?
技術尚未成熟:Lakehouse技術當前尚未成熟,在達到上文所提的能力之前仍有較長的路要走。
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/125906.html
摘要:近兩年,為什么都開始談論起這個新名詞了先說我的想法,其實還是用戶需求驅動數據服務,大家開始關注的根本原因是用戶需求發生了質變,過去的數據倉庫模式以及涉及到的相關組件沒有辦法滿足日益進步的用戶需求。近兩年,為什么都開始談論起 Data Lake 這個新名詞了?先說我的想法,其實還是用戶需求驅動數據服務,大家開始關注 Data Lake 的根本原因是用戶需求發生了質變,過去的數據倉庫模式以及涉及...
摘要:題記三國時赤壁鏖戰,孔明說,天有不測風云,欲破曹公,宜用火攻,萬事俱備,只欠東風。現在公共云混戰,我想說,無災備不上云,保護數據,未雨綢繆,帶了雨傘,還需雨衣。題記:三國時赤壁鏖戰,孔明說,天有不測風云,欲破曹公,宜用火攻,萬事俱備,只欠東風。現在公共云混戰,我想說,無災備不上云,保護數據,未雨綢繆,帶了雨傘,還需雨衣。未雨綢繆,到底是帶雨傘還是雨衣呢?時代在變,人的追求也在變。隨著公共云對...
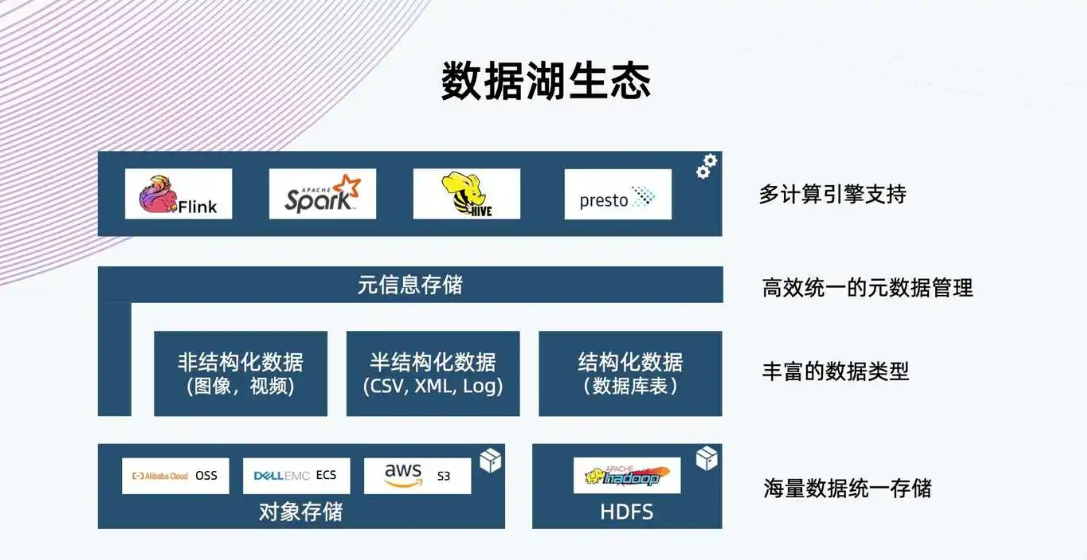
1、數據結構:數據倉庫只能存儲經過處理和提煉的數據,而數據湖存儲尚未出于某種目的處理的原始數據。因此,數據湖需要比數據倉庫大得多的存儲容量,且數據靈活、分析迅速,非常適合機器學習。2、加工:數據倉庫使用寫入時序模式的方法來處理數據以賦予其形狀和結構,而數據湖對原始數據使用讀取模式來處理它。3、成本:存儲在數據倉庫中的成本可能很高,尤其是在有大量數據的情況下,而數據湖是專為低成本數據存儲而設計,成本...
摘要:哪些省份省級行政單位使用了最多的其它省份名作為道路名的呢山東省穩居第一,總共使用了全國全部的省自治區直轄市特別行政區名共個。太平路排名第一。根據周圍的地理事物為道路命名,也是道路命名的一個習慣。帶有海字的路名,集中分布在東部沿海城市中。 showImg(https://segmentfault.com/img/remote/1460000019921753); 作者 | AlfredW...

閱讀 3514·2023-04-25 20:09
閱讀 3720·2022-06-28 19:00
閱讀 3035·2022-06-28 19:00
閱讀 3058·2022-06-28 19:00
閱讀 3132·2022-06-28 19:00
閱讀 2859·2022-06-28 19:00
閱讀 3014·2022-06-28 19:00
閱讀 2610·2022-06-28 19:00




