ecs性能設置閾值進行預警SEARCH AGGREGATION


回答:從系統架構本身來說,一般系統優化主要從三個方面入手,數據持久層、業務邏輯層和前端展示層。數據持久層限制系統性能主要有兩個方面,一是數據庫自身的性能,二是對數據庫操作的方式,數據庫自身相對簡單,一般通過優化配置、采用高可用方案、搭建集群或者使用性能更好的數據庫來提升性能;數據庫操作主要是數據庫讀寫操作,可以通過SQL優化的方式來提升讀寫速度,或者通過緩存的方式減低并發、提升性能。業務邏輯層代碼層面常...
 senntyou
|
1068人閱讀
senntyou
|
1068人閱讀
回答:ucloud一直在強調云端、大數據的重要性,同樣它也是這么做的。1月9ucloud云推出的ESSD云盤無疑是給上一代的云盤加上了一個強勁的發動機,不論是底層微秒級延遲還是百億級IOPS,都大大增加了整個系統的性能、安全性,同時降低了成本。ucloud目前的企業級高性能產品線,速度較上一代提升50%,這一新型存儲推進云端大數據時代大步向前,而且在此之前國家天文臺就已經跟ucloud云進行合作了,將所...
 harryhappy
|
1047人閱讀
harryhappy
|
1047人閱讀

...的存和讀。之所以沒有采用傳統的數據庫是由于讀寫表的性能,如為了防止多個進程同時寫表造成沖突必須進行鎖表等操作,而且讀寫硬盤的性能相對內存讀寫較低;之所以沒有采用IPC+事件機制實現多進程通信,主要是由于node...
...d是一個守護(daemon)進程,用來定期收集系統和應用程序的性能指標,同時提供了機制,以不同的方式來存儲這些指標值。 可視化 獨立的可視化組件比較少,不過解決方案里一般都帶一個web端,像grafana這么專注的,不太多。 grafa...
...d是一個守護(daemon)進程,用來定期收集系統和應用程序的性能指標,同時提供了機制,以不同的方式來存儲這些指標值。 可視化 獨立的可視化組件比較少,不過解決方案里一般都帶一個web端,像grafana這么專注的,不太多。 grafa...
... 算法優化 由于獲取了完整了dom的json,因此可以通過相關閾值的設定或者算法的優化;來對比結果,進行更加優化的分級預警和分析;作者一般對非核心預警超過15%變化會做出預警,超過更高閾值會進一步的預警等等。貼一個dom...
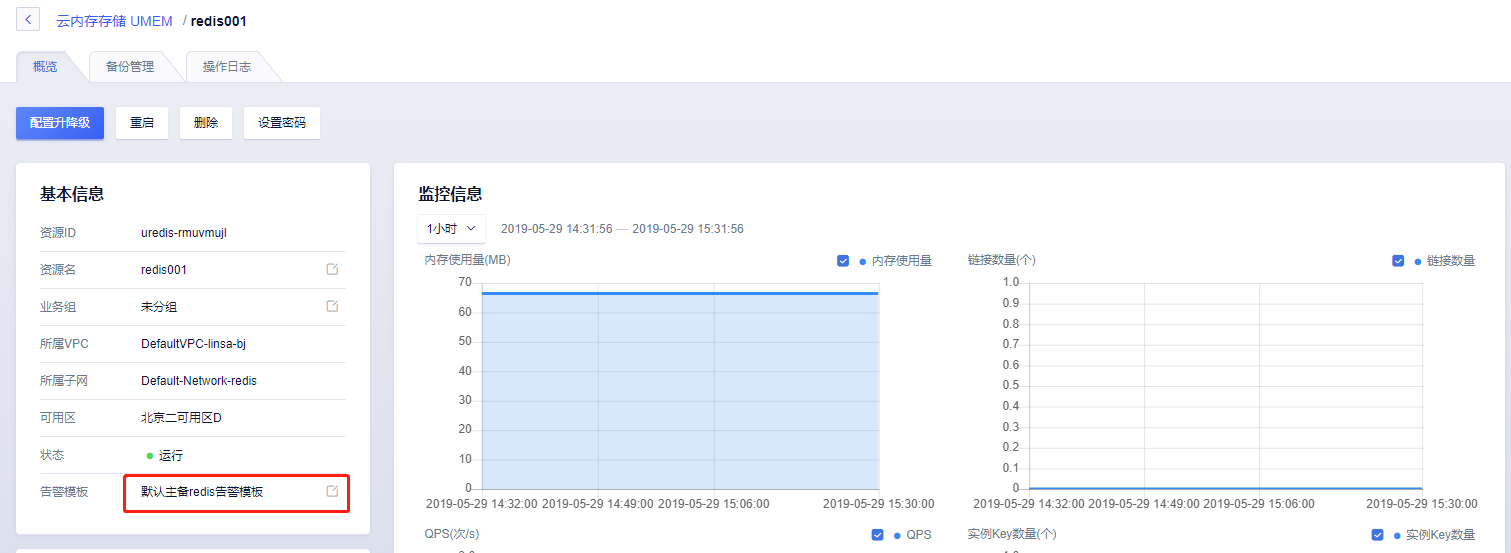
...共用同一告警模板配置閾值管理時,若需要對于Redis實例性能情況預警,可通過添加監控項Redis平均負載(%)或Redis最高負載(%)至告警模板中并設置閾值,Redis最高負載(%)比Redis平均負載(%)更敏感,如出現一次突增...
...純手工打造,需要經過日志埋點、監控配置、報警閾值設置,整個過程費時費力,缺乏自動化、智能化監控的手段,這也是造成各系統監控能力參差不齊的重要原因,一些新業務因為無力投入大量精力配置監控,導致業務監控...
...務器安全等基礎防護、免費提供云監控,并支持多種實時預警保障業務安全。 免費開通云盾,提供網絡安全、服務器安全等基礎防護DDoS 基礎防護: 提供最高 5G 的 DDoS 防護能力,可防御 SYN flood、UDP flood、ICMP flood、ACK flood 常規 ...
...Apache Flink 與 Apache Storm 在完成流數據清洗的分布式任務的性能對比。 Flink 保存點提供了一個狀態化的版本機制,使得能以無丟失狀態和最短停機時間的方式更新應用或者回退歷史數據。 Flink 被設計成能用上千個點在大規模集...
...平臺。UAV.Monitor具備監控功能,包含基礎監控、應用/服務性能監控、日志監控、業務監控等。在應用監控中,UAV可以根據應用實例畫像;其中應用實例組件可以對日志、服務、客戶端等進行畫像;基于客戶端的畫像又分為Http、Du...
...商,那只是個數而已。 但是阿里云最近推出的那個突發性能t5實例,被大家詬病,其實這個t5只是大家用錯了地方。首先這個t5價格便宜,這是毋庸置疑,但是這個t5限制CPU使用率啊,這一點沒搞清楚直接就買了。那么t5實例適合...
ChatGPT和Sora等AI大模型應用,將AI大模型和算力需求的熱度不斷帶上新的臺階。哪里可以獲得...
大模型的訓練用4090是不合適的,但推理(inference/serving)用4090不能說合適,...
圖示為GPU性能排行榜,我們可以看到所有GPU的原始相關性能圖表。同時根據訓練、推理能力由高到低做了...




 陸斌
陸斌 張金寶
張金寶 王晗
王晗 李增田
李增田