處理數據SEARCH AGGREGATION


回答:使用SQL處理數據時,數據會在數據庫內直接進行處理,而且sql處理本身可以對sql語句做優化,按照最優的策略自動執行。使用Java處理時,需要把數據從數據庫讀入到Java程序內存,其中有網絡處理和數據封裝的操作,數據量比較大時,有一定的延遲,所以相對來說數據處理就慢一些。當然,這個只是大體示意圖,實際根據業務不同會更復雜。兩者側重的點不同,有各自適合的業務領域,需要根據實際情況選用合適的方式。
 stefanieliang
|
2077人閱讀
stefanieliang
|
2077人閱讀
回答:我是做JAVA后臺開發的,目前為止最多處理過每天600萬左右的數據!數據不算特別多,但是也算是經歷過焦頭爛額,下面淺談下自己和團隊怎么做的?后臺架構:前置部門:負責接收別的公司推過來的數據,因為每天的數據量較大,且分布不均,使用十分鐘推送一次報文的方式,使用batch框架進行數據落地,把落地成功的數據某個字段返回給調用端,讓調用端驗證是否已經全部落地成功的,保證數據的一致性!核心處理:使用了spr...
 李增田
|
1483人閱讀
李增田
|
1483人閱讀
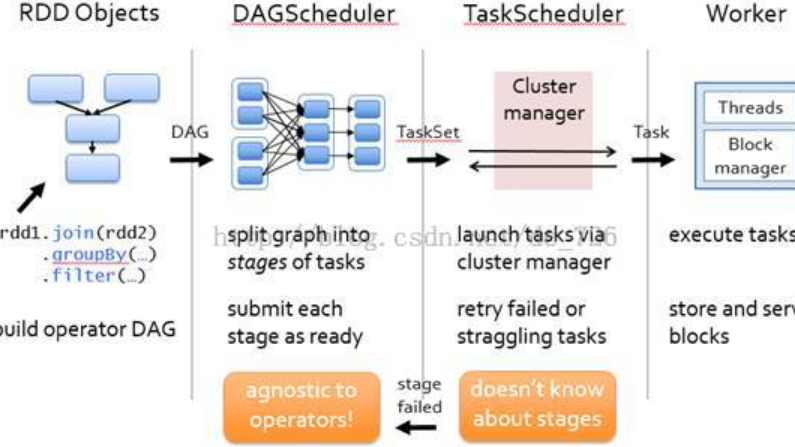
回答:首先明確下定義:計算時間是指計算機實際執行的時間,不是人等待的時間,因為等待時間依賴于有多少資源可以調度。首先我們不考慮資源問題,討論時間的預估。執行時間依賴于執行引擎是 Spark 還是 MapReduce。Spark 任務Spark 任務的總執行時間可以看 Spark UI,以下圖為例Spark 任務是分多個 Physical Stage 執行的,每個stage下有很多個task,task 的...
 silenceboy
|
1059人閱讀
silenceboy
|
1059人閱讀

...之間的數據交互模型。本篇文章詳細地介紹 DM 數據同步處理單元(DM-worker 內部用來同步數據的邏輯單元),包括數據同步處理單元實現了什么功能,數據同步流程、運行邏輯,以及數據同步處理單元的 interface 設計。 數據同步...
...智能媒體管理(Intelligent Media Management)服務, 通過離線處理能力關聯授權的云存儲,提供便捷的海量多媒體數據一鍵分析,并通過該分析過程構建價值元數據,更好支撐內容檢索。 導語近日,阿里云發布了智能媒體管理(Intell...
...工具和技術,例如 Apache Spark,它是一種用于大規模數據處理的快速靈活的數據處理引擎。 CDH Spark2 是 Apache Spark 的一個版本,包含在 Cloudera Distribution for Apache Hadoop (CDH) 中。它是一個強大而靈活的數據處理引...
...并且高速生成的數據的一個術語.這類數據對用于存儲和處理數據傳統RDBMS(即關系數據庫管理系統)提出了挑戰.大數據為處理和存儲數據的新途徑鋪平了道路.在本章節中,我們將探討大數據基礎、來源以及挑戰,將介紹大數據的三個...
... Redis 的線程模型 Redis是基于reactor模式開發的網絡事件處理器,這個處理器叫做文件事件處理器,file event handler。這個文件事件處理器是單線程的,所以Redis叫做單線程模型,采用IO多路復用機制同時監聽多個socket,根據socket上...
ChatGPT和Sora等AI大模型應用,將AI大模型和算力需求的熱度不斷帶上新的臺階。哪里可以獲得...
大模型的訓練用4090是不合適的,但推理(inference/serving)用4090不能說合適,...
圖示為GPU性能排行榜,我們可以看到所有GPU的原始相關性能圖表。同時根據訓練、推理能力由高到低做了...




 崔曉明
崔曉明 bbbbbb
bbbbbb 付倫
付倫










