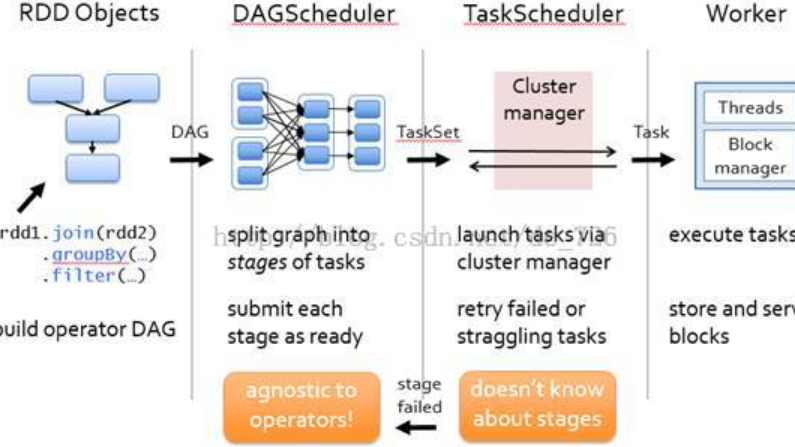
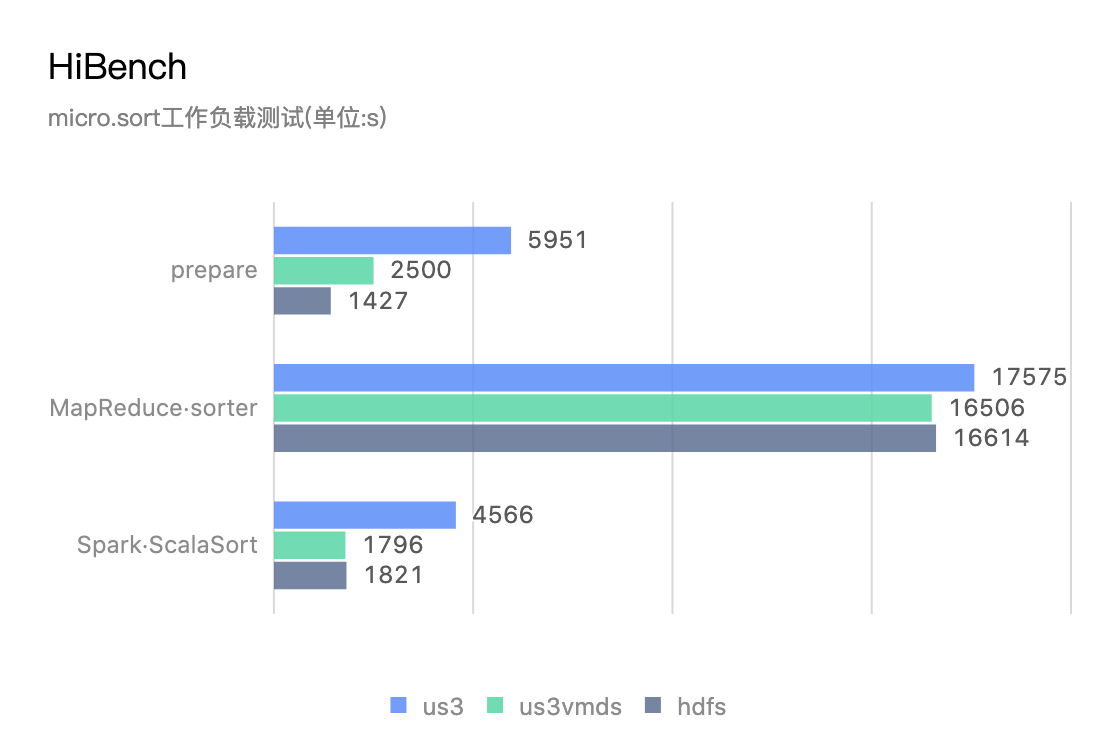
Spark2SEARCH AGGREGATION

回答:可以自行在某些節(jié)點(diǎn)上嘗試安裝 Spark 2.x,手動(dòng)修改相應(yīng) Spark 配置文件,進(jìn)行使用測(cè)試,不安裝 USDP 自帶的 Spark 3.0.1
...處理的快速靈活的數(shù)據(jù)處理引擎。 CDH Spark2 是 Apache Spark 的一個(gè)版本,包含在 Cloudera Distribution for Apache Hadoop (CDH) 中。它是一個(gè)強(qiáng)大而靈活的數(shù)據(jù)處理引擎,非常適合廣泛的數(shù)據(jù)處理任務(wù),包括批處理、流處理...

...ta0:8032 oozie.use.system.libpath=true oozie.libpath=${nameNode}/share/lib/spark2/jars/,${nameNode}/share/lib/spark2/python/lib/,${nameNode}/share/lib/spark2/hive-site.xml oozie.wf.application.path...

...PHOENIX4.14.3HBaseSQL化查詢分析工具PRESTO0.234分布式計(jì)算服務(wù)SPARK2.4.6分布式計(jì)算引擎SQOOP1.4.7數(shù)據(jù)采集與轉(zhuǎn)儲(chǔ)服務(wù)TEZ0.9.2優(yōu)化MapReduce任務(wù)的DAGYARN2.8.5分布式資源調(diào)度服務(wù)ELASTICSEARCH7.8.0分布式全文檢索數(shù)據(jù)庫HBASE1.4.10分布式非關(guān)系型數(shù)據(jù)...
...t pyspark-shell-main --name PySparkShell $@ 在較新一些的版本如Spark2.2中,已經(jīng)不支持用pyspark運(yùn)行py腳本文件,一切spark作業(yè)都應(yīng)該使用spark-submit提交。 pyspark module Spark是用scala編寫的框架,不過考慮到主要是機(jī)器學(xué)習(xí)的應(yīng)用場(chǎng)景,Spark...
...le) .config(spark.some.config.option, some-value) .getOrCreate(); Spark2.0引入SparkSession的目的是內(nèi)建支持Hive的一些特性,包括使用HiveQL查詢,訪問Hive UDFs,從Hive表中讀取數(shù)據(jù)等,使用這些你不需要已存在的Hive配置。而在此之前,你需要引...
...本號(hào)限制約束Hadoop2.8.5標(biāo)準(zhǔn)社區(qū)版本Hive2.3.7標(biāo)準(zhǔn)社區(qū)版本Spark2.4.3標(biāo)準(zhǔn)社區(qū)版本Zookeeper3.5.6標(biāo)準(zhǔn)社區(qū)版本關(guān)鍵參數(shù)
...Connected to: Apache Hive (version 2.3.5) Driver: Hive JDBC (version 1.2.1.spark2) Transaction isolation: TRANSACTION_REPEATABLE_READ Beeline version 1.2.1.spark2 by Apache Hive 0: jdbc:hive2://Mas...
ChatGPT和Sora等AI大模型應(yīng)用,將AI大模型和算力需求的熱度不斷帶上新的臺(tái)階。哪里可以獲得...
大模型的訓(xùn)練用4090是不合適的,但推理(inference/serving)用4090不能說合適,...
圖示為GPU性能排行榜,我們可以看到所有GPU的原始相關(guān)性能圖表。同時(shí)根據(jù)訓(xùn)練、推理能力由高到低做了...













