資訊專欄INFORMATION COLUMN

摘要:谷歌發(fā)布的一篇論文給出了較早的關(guān)于深度神經(jīng)網(wǎng)絡(luò)訓(xùn)練相關(guān)的理論證明,實驗觀察結(jié)果也為初步解釋梯度下降強(qiáng)于貝葉斯優(yōu)化奠定了基礎(chǔ)。
谷歌 AI 發(fā)布的一篇論文給出了較早的關(guān)于深度神經(jīng)網(wǎng)絡(luò)訓(xùn)練相關(guān)的理論證明,實驗觀察結(jié)果也為初步解釋梯度下降強(qiáng)于貝葉斯優(yōu)化奠定了基礎(chǔ)。神經(jīng)網(wǎng)絡(luò)的理論面紗,正逐步被揭開。
原來,神經(jīng)網(wǎng)絡(luò)實際上跟線性模型并沒那么大不同!
谷歌 AI 的研究人員日前在 arxiv 貼出一篇文章,給出了較早的神經(jīng)網(wǎng)絡(luò)訓(xùn)練相關(guān)的理論證明。
實驗中,他們將一個實際的神經(jīng)網(wǎng)絡(luò)訓(xùn)練過程與線性模型的訓(xùn)練過程相比,發(fā)現(xiàn)兩者高度一致。這里用到的神經(jīng)網(wǎng)絡(luò)是一個 wide ResNet,包括 ReLU 層、卷積層、pooling 層和 batch normalization;線性模型是用 ResNet 關(guān)于其初始 (隨機(jī)) 參數(shù)的泰勒級數(shù)建立的網(wǎng)絡(luò)。
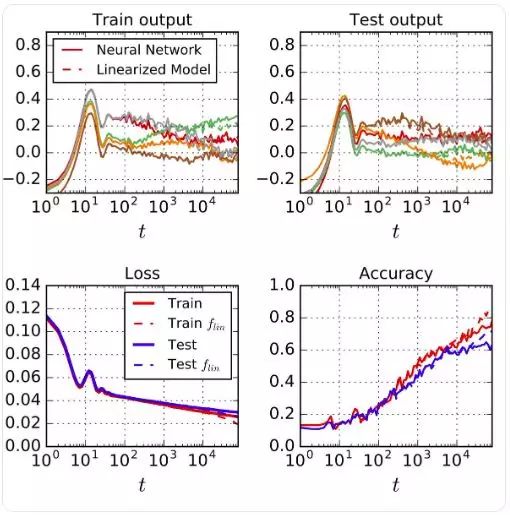
將神經(jīng)網(wǎng)絡(luò)的訓(xùn)練過程與線性模型的相比,兩者高度一致
在多個不同模型上試驗并排除量化誤差后,觀察結(jié)果依舊保持一致。由此,谷歌 AI 研究人員得出結(jié)論,當(dāng)學(xué)習(xí)率比較小且網(wǎng)絡(luò)足夠?qū)?(不必?zé)o限寬) 的時候,神經(jīng)網(wǎng)絡(luò)就是線性模型。
由此得出的一個推論是,使用梯度下降訓(xùn)練的大型網(wǎng)絡(luò)集成能夠用一個高斯過程描述,而且在梯度下降的任意時間都能用完備形式化描述這個高斯過程。
這些觀察結(jié)果也構(gòu)成了一個理論框架基礎(chǔ),可以用來初步解釋長期以來困擾深度學(xué)習(xí)研究界的一個難題:梯度下降究竟在哪些情況下,具體是如何優(yōu)于貝葉斯優(yōu)化?
在訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)被戲謔為 “調(diào)參煉丹” 的當(dāng)下,這一發(fā)現(xiàn)猶如一道希望的強(qiáng)光,射進(jìn)還被排除在 “科學(xué)” 之外的深度學(xué)習(xí)領(lǐng)域,激動人心。

相關(guān)論文:使用梯度下降訓(xùn)練的任意深度的 Wide 神經(jīng)網(wǎng)絡(luò)與線性模型的一致性
終于,調(diào)參不再是煉丹:較早的關(guān)于神經(jīng)網(wǎng)絡(luò)訓(xùn)練的理論證明
基于深度神經(jīng)網(wǎng)絡(luò)的機(jī)器學(xué)習(xí)模型在許多任務(wù)中取得了前所未有的性能。通常,這些模型被認(rèn)為是復(fù)雜系統(tǒng),其中許多類型的理論分析是很棘手的。此外,由于控制優(yōu)化的通常是高維的非凸損失平面 (non-convex loss surfaces),因此要描述這些模型的基于梯度的訓(xùn)練動態(tài)機(jī)制具有挑戰(zhàn)性。
就像在物理科學(xué)中常見的那樣,研究這些系統(tǒng)的極限通常可以解釋這些難題。對于神經(jīng)網(wǎng)絡(luò)來說,其中一個極限就是它的 “無限寬度”(infinite width),指的是完全連接層中的隱藏單元數(shù)量,或卷積層中的通道數(shù)量。
在此限制下,網(wǎng)絡(luò)初始化時的輸出取自高斯過程 (GP);此外,在使用平方損失進(jìn)行較精確貝葉斯訓(xùn)練后,網(wǎng)絡(luò)輸出仍然由 GP 控制。除了理論上的簡單性,nfinite-width 這一限制也具有實際意義,因為許多研究已經(jīng)證明,更寬的網(wǎng)絡(luò)可以更好地進(jìn)行泛化。
在這項工作中,我們探索了梯度下降下寬的神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)動態(tài)機(jī)制 (learning dynamics),并發(fā)現(xiàn)動態(tài)的權(quán)重空間描述變得非常簡單:隨著寬度變大,神經(jīng)網(wǎng)絡(luò)可以有效地被關(guān)于其初始化參數(shù)的一階泰勒展開式 (first-order Taylor expansion) 取代。
對于這種誘導(dǎo)的線性模型,梯度下降的動態(tài)機(jī)制變得易于分析了。雖然線性化只在無限寬度限制下是較精確的,但我們發(fā)現(xiàn),即使是有限寬度的情況下,原始網(wǎng)絡(luò)的預(yù)測與線性化版本的預(yù)測仍然非常一致。這種一致性在不同的架構(gòu)、優(yōu)化方法和損失函數(shù)之間都存在。
對于平方損失 (squared loss),較精確的學(xué)習(xí)動態(tài)機(jī)制允許封閉形式的解決方案,這允許我們用 GP 來描述預(yù)測分布的演化。這一結(jié)果可以看作是 “先采樣再優(yōu)化”(sample-then-optimize) 后驗采樣對深度神經(jīng)網(wǎng)絡(luò)訓(xùn)練的延伸。我們的經(jīng)驗?zāi)M證實,該結(jié)果準(zhǔn)確地模擬了具有不同隨機(jī)初始化的有限寬度模型集合中預(yù)測的變化。
谷歌 AI 的研究人員表示,這篇論文的幾大主要貢獻(xiàn)包括:
首先,我們以 Jacot et al. (2018) 最近的研究成果為基礎(chǔ),該成果描述了在 infinite width 限制下,整個梯度下降訓(xùn)練過程中網(wǎng)絡(luò)輸出的較精確動態(tài)。他們的結(jié)果證明了參數(shù)空間的梯度下降對應(yīng)于函數(shù)空間中關(guān)于新核的核梯度下降 (kernel gradient descent),即 Neural Tangent Kernel (NTK)。
我們工作的一個關(guān)鍵貢獻(xiàn)是證明了參數(shù)空間中的動態(tài)等價于所有網(wǎng)絡(luò)參數(shù)、權(quán)重和偏差集合中的仿射模型的訓(xùn)練動態(tài)。無論損失函數(shù)的選擇如何,這個結(jié)果都成立。在平方損失的情況下, dynamics 允許一個封閉形式的解作為時間函數(shù)。
無限寬 (infinitely wide) 神經(jīng)網(wǎng)絡(luò)初始化時的輸出是高斯的,并且如 Jacot et al.(2018) 中所述,平方損失在整個訓(xùn)練過程中始終是高斯的。我們推導(dǎo)了該 GP 的均值和協(xié)方差函數(shù)的顯式時間依賴表達(dá)式,并為結(jié)果提供了新的解釋。
具體來說,該解釋對梯度下降與參數(shù)的貝葉斯后驗采樣的不同機(jī)制提供了一種定量理解:雖然這兩種方法都取自 GP,但梯度下降不會從任何概率模型的后驗生成樣本。
這一觀察結(jié)果與 (Matthews et al.,2017) 的 “先采樣后優(yōu)化”(sample-then-optimize) 框架形成了對比,在該框架中,只訓(xùn)練頂層權(quán)重,梯度下降從貝葉斯后驗采樣。
這些觀察構(gòu)成了一個框架,用來分析長期存在的問題,如梯度下降是否、如何以及在何種情況下提供了相對于貝葉斯推理的具體好處。
正如 Chizat & Bach (2018b) 中論述的,這些理論結(jié)果可能過于簡單,無法適用于現(xiàn)實的神經(jīng)網(wǎng)絡(luò)。但是,我們通過實證研究證明了該理論在 finite-width 設(shè)置中的適用性,發(fā)現(xiàn)它準(zhǔn)確地描述了各種條件下的學(xué)習(xí)動態(tài)機(jī)制和后驗函數(shù)分布,包括一些實際的網(wǎng)絡(luò)架構(gòu),如 Wide Residual Network (Zagoruyko & Komodakis, 2016)。
理論結(jié)果:無限寬的神經(jīng)網(wǎng)絡(luò)就是線性模型
線性化網(wǎng)絡(luò) (linearized network)
此處,我們將考慮線性化網(wǎng)絡(luò)的訓(xùn)練動態(tài),具體地說,就是用一階泰勒展開代替神經(jīng)網(wǎng)絡(luò)的輸出:

值得注意的是,flint 是兩項之和:第一項是網(wǎng)絡(luò)的初始輸出,在訓(xùn)練過程中保持不變;第二項是在訓(xùn)練過程中捕捉對初始值的變化。
使用這個線性化函數(shù)的梯度流的動態(tài)受到如下約束:
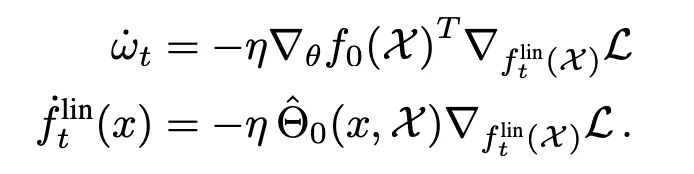
無限寬度限制產(chǎn)生高斯過程
當(dāng)隱藏層的寬度接近無窮大時,中心極限定理 (CLT) 意味著初始化 {f0(x)}x∈X 時的輸出在分布上收斂于多元高斯分布。這一點(diǎn)可以用歸納法非正式的進(jìn)行證明。
因此,隨機(jī)初始化的神經(jīng)網(wǎng)絡(luò)對應(yīng)于一類高斯過程 (以下簡稱 NNGP),將有利于神經(jīng)網(wǎng)絡(luò)的完全貝葉斯處理。
梯度下降訓(xùn)練中的高斯過程
如果我們在初始化之后凍結(jié)變量 θ≤L,并且只優(yōu)化 θ≤L+1,那么原始網(wǎng)絡(luò)及其線性化是相同的。讓寬度趨于無窮,這個特殊的 tangent kernel 的概率將收斂于 K。這是用于評估高斯過程后驗的 “先采樣后優(yōu)化” 方法的實現(xiàn)。
我們對比了 NNGP、NTK-GP 和 NN 集合的預(yù)測分布,如下圖所示:

訓(xùn)練神經(jīng)網(wǎng)絡(luò)輸出的均值和方差的動態(tài)遵循線性化的分析動態(tài)機(jī)制
黑線表示來自 100 個訓(xùn)練神經(jīng)網(wǎng)絡(luò)集合的預(yù)測輸出分布的時間演變; 藍(lán)色區(qū)域表示整個訓(xùn)練中輸出分布的分析預(yù)測;最后,紅色區(qū)域表示僅訓(xùn)練頂層的預(yù)測,對應(yīng)于 NNGP。
受過訓(xùn)練的網(wǎng)絡(luò)有 3 個隱藏層,寬度為 8192。陰影區(qū)域和虛線表示平均值的 2 個標(biāo)準(zhǔn)偏差。
無限寬度網(wǎng)絡(luò)是線性化網(wǎng)絡(luò)
原始網(wǎng)絡(luò)的常微分方程 (ODE) 在一般情況下是不可解的。在積分函數(shù)梯度范數(shù)保持隨機(jī)有界為n1,n2,…,nL→∞的技術(shù)假設(shè)下:
值得注意的是,上面公式中的上界只是理論性的,是根據(jù)經(jīng)驗觀察得到的:
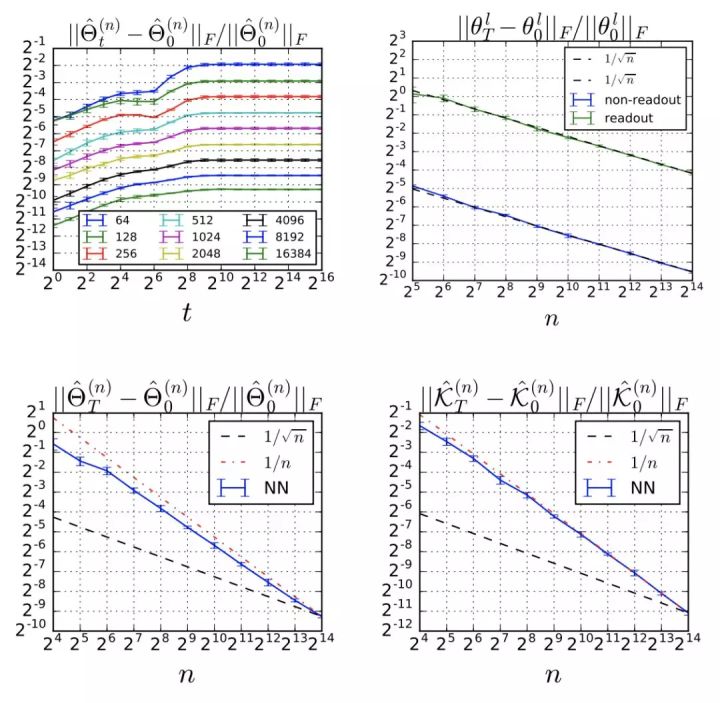
訓(xùn)練過程中 Relative Frobenius 范數(shù)的改變
在 MSE 設(shè)置中,我們可以對原始網(wǎng)絡(luò)的輸出與其線性化輸出之間的差異進(jìn)行上限:

對于非常寬的網(wǎng)絡(luò),我們可以用線性化動態(tài)機(jī)制來近似訓(xùn)練動態(tài)機(jī)制。
而從網(wǎng)絡(luò)線性化中獲得的另一個見解是,動態(tài)機(jī)制等效于隨機(jī)特征法,其中,特征是模型相對于其權(quán)重的梯度。
實驗
我們的實驗證明,寬的神經(jīng)網(wǎng)絡(luò)的訓(xùn)練動態(tài)能很好地被線性模型捕獲。
我們考慮了全連接、卷積和 wide ResNet 架構(gòu),這些架構(gòu)使用足夠小的學(xué)習(xí)率進(jìn)行 full-batch 或 mini-batch 梯度下降訓(xùn)練,從而使連續(xù)時間近似保持良好。
我們考慮了 CIFAR10 上的 two-class 分類任務(wù) (馬匹和飛機(jī)),以及 MNIST 和 CIFAR-10 上的 ten-class 分類。
在 MSE loss 的情況下,輸出分布在整個訓(xùn)練過程中保持高斯分布。圖 3 顯示,神經(jīng)網(wǎng)絡(luò)及其對應(yīng)的 GP 的集合顯示了在兩個訓(xùn)練點(diǎn)之間插值的輸入點(diǎn)的預(yù)測輸出分布。

圖 4:對于網(wǎng)絡(luò)輸出和單個權(quán)重,模型的 full batch 梯度下降在線性化方面的表現(xiàn)與 analytic dynamics 類似
在圖 4 中,我們看到線性模型很好地描述了具有交叉熵?fù)p失的 CIFAR-10 所有類分類任務(wù)的 learning dynamics。

圖 5:卷積網(wǎng)絡(luò)及其線性化在使用動量優(yōu)化器進(jìn)行 full batch 梯度下降訓(xùn)練時表現(xiàn)類似
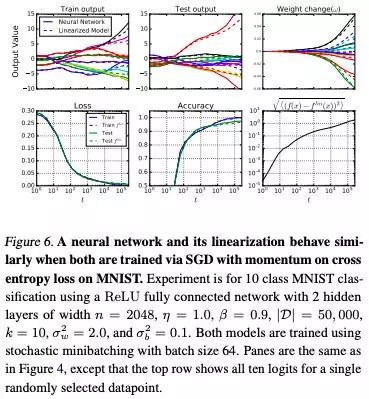
圖 6:在通過 SGD 進(jìn)行訓(xùn)練時,神經(jīng)網(wǎng)絡(luò)及其線性化表現(xiàn)相似,在 MNIST 上的交叉熵?fù)p失上具有動量
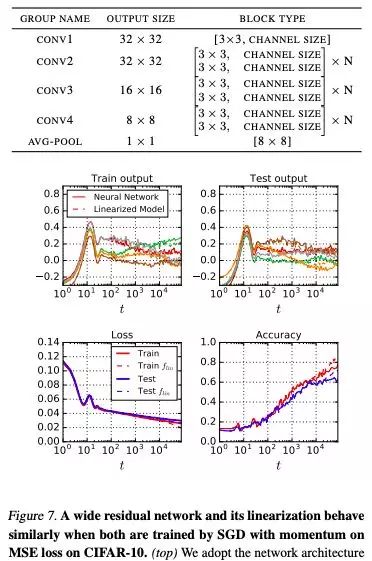
圖 7:兩者都利用 SGD 在 CIFAR-10 上訓(xùn)練時, wide ResNet 及其線性化的表現(xiàn)相似
完整論文:
https://arxiv.org/pdf/1902.06720.pdf
聲明:文章收集于網(wǎng)絡(luò),如有侵權(quán),請聯(lián)系小編及時處理,謝謝!
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價值的辦法,實際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/4851.html
摘要:第一條是關(guān)于深度學(xué)習(xí)的晚宴,討論的是背后的數(shù)學(xué)支撐,以及未來的方向。大數(shù)據(jù)與深度學(xué)習(xí)是一種蠻力盡管當(dāng)場說了很多觀點(diǎn),但是最核心的還是援引了愛因斯坦關(guān)于上帝的隱喻。不過,我自己并不同意深度學(xué)習(xí)必須等同于機(jī)器蠻力。 Vladimir Vapnik 介紹:Vladimir Vapnik 被稱為統(tǒng)計學(xué)習(xí)理論之父,他出生于俄羅斯,1990 年底移居美國,在美國貝爾實驗室一直工作到 2002 年,之后加...
摘要:進(jìn)一步說,如果承認(rèn)深度學(xué)習(xí)系統(tǒng)在解決問題時不可思議的表現(xiàn),那么大數(shù)據(jù)和深度學(xué)習(xí),都有某種蠻力的味道。不過,我自己并不同意深度學(xué)習(xí)必須等同于機(jī)器蠻力。 Facebook去年底挖來了一個機(jī)器學(xué)習(xí)大神Vladimir Vapnik,他是統(tǒng)計學(xué)習(xí)理論和支持向量機(jī)的主要發(fā)明者。Vladimir Vapnik被稱為統(tǒng)計學(xué)習(xí)理論之父,他出生于俄羅斯,1990年底移居美國,在美國貝爾實驗室一直工作到2002...
摘要:大數(shù)據(jù)與深度學(xué)習(xí)是一種蠻力盡管當(dāng)場說了很多觀點(diǎn),但是最核心的還是援引了愛因斯坦關(guān)于上帝的隱喻。大數(shù)據(jù)與深度學(xué)習(xí)是一種蠻力在算法和模型上,我們是否能發(fā)明所有東西認(rèn)為,在機(jī)器學(xué)習(xí)的算法和模型上,我們并不能發(fā)明所有東西。 Facebook去年底挖來了一個機(jī)器學(xué)習(xí)大神Vladimir Vapnik,他是統(tǒng)計學(xué)習(xí)理論和支持向量機(jī)的主要發(fā)明者。Vladimir Vapnik被稱為統(tǒng)計學(xué)習(xí)理論之父,他出生...
摘要:而這種舉一反三的能力在機(jī)器學(xué)習(xí)領(lǐng)域同樣適用,科學(xué)家將其稱之為遷移學(xué)習(xí)。與深度學(xué)習(xí)相比,我們技術(shù)較大優(yōu)點(diǎn)是具有可證明的性能保證。近幾年的人工智能熱潮中,深度學(xué)習(xí)是最主流的技術(shù),以及之后的成功,更是使其幾乎成為的代名詞。 如今,人類將自己的未來放到了技術(shù)手里,無論是讓人工智能更像人類思考的算法,還是讓機(jī)器人大腦運(yùn)轉(zhuǎn)更快的芯片,都在向奇點(diǎn)靠近。谷歌工程總監(jiān)、《奇點(diǎn)臨近》的作者庫茲韋爾認(rèn)為,一旦智能...

閱讀 2451·2021-10-13 09:40
閱讀 3337·2019-08-30 13:46
閱讀 1125·2019-08-29 14:05
閱讀 2961·2019-08-29 12:48
閱讀 3657·2019-08-26 13:28
閱讀 2148·2019-08-26 11:34
閱讀 2284·2019-08-23 18:11
閱讀 1163·2019-08-23 12:26





