資訊專欄INFORMATION COLUMN

摘要:更廣泛地說,這些結果表明神經網絡訓練不需要被認為是一種煉丹術,而是可以被量化和系統化。中間的曲線中存在彎曲,漸變噪聲標度預測彎曲發生的位置。
由于復雜的任務往往具有更嘈雜的梯度,因此越來越大的batch計算包,可能在將來變得有用,從而消除了AI系統進一步增長的一個潛在限制。
更廣泛地說,這些結果表明神經網絡訓練不需要被認為是一種煉丹術,而是可以被量化和系統化。
在過去的幾年里,AI研究人員通過數據并行技術,在加速神經網絡訓練方面取得了越來越大的成功,數據并行性將大batch數據分散到許多機器上。
研究人員成功地使用了成各種的batch進行圖像分類和語言建模,甚至玩Dota 2。
這些大batch數據允許將越來越多的計算量有效地投入到單個模型的訓練中,并且是人工智能訓練計算快速增長的重要推動者。
但是,batch如果太大,則梯度消失。并且不清楚為什么這些限制對于某些任務影響更大而對其他任務影響較小。
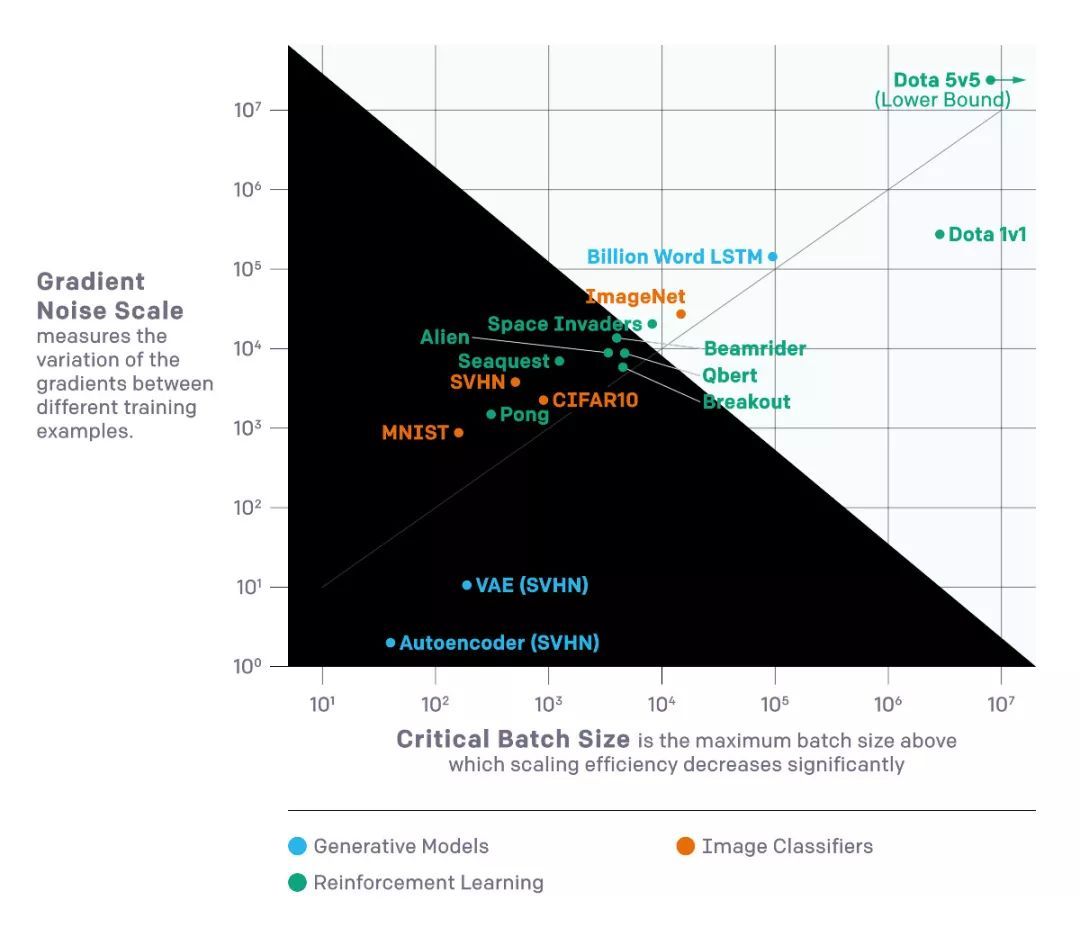
我們已經發現,通過測量梯度噪聲標度,一個簡單的統計量來量化網絡梯度的信噪比,我們可以近似預測較大有效batch大小。
同理,噪聲尺度可以測量模型所見的數據變化(在訓練的給定階段)。當噪聲規模很小時,快速并行查看大量數據變得多余;反之,我們仍然可以從大batch數據中學到很多東西。
這種類型的統計數據被廣泛用于樣本量選擇,并且已被提議用于深度學習,但尚未被系統地測量或應用于現代訓練運行。
我們對上圖所示的各種機器學習任務進行了驗證,包括圖像識別,語言建模,Atari游戲和Dota。
由于大batch通常需要仔細和昂貴的調整或特殊高效的學習率,因此提前知道上限在訓練新模型方面提供了顯著的實際優勢。
我們發現,根據訓練的現實時間和我們用于進行訓練的總體積計算(與美元成本成比例)之間的權衡,可視化這些實驗的結果是有幫助的。
在非常小的batch的情況下,batch加倍可以讓我們在不使用額外計算的情況下減少一半的訓練。在非常大的batch,更多的并行化不會導致更快的訓練。中間的曲線中存在“彎曲”,漸變噪聲標度預測彎曲發生的位置。

我們通過設置性能水平(比如在Beam Rider的Atari游戲中得分為1000)來制作這些曲線,并觀察在不同batch大小下訓練到該性能所需的時間。 結果與績效目標的許多不同值相對較緊密地匹配了我們模型的預測。
梯度噪聲尺度中的模式
我們在梯度噪聲量表中觀察到了幾種模式,這些模式提供了人工智能訓練未來可能存在的線索。
首先,在我們的實驗中,噪聲標度通常在訓練過程中增加一個數量級或更多。
直觀地,這意味著網絡在訓練早期學習任務的“更明顯”的特征,并在以后學習更復雜的特征。
例如,在圖像分類器的情況下,網絡可能首先學習識別大多數圖像中存在的小尺度特征(例如邊緣或紋理),而稍后將這些部分組合成更一般的概念,例如貓和狗。
要查看各種各樣的邊緣或紋理,網絡只需要看到少量圖像,因此噪聲比例較小;一旦網絡更多地了解更大的對象,它就可以一次處理更多的圖像,而不會看到重復的數據。
我們看到一些初步跡象表明,在同一數據集上不同模型具有相同的效果。更強大的模型具有更高的梯度噪聲標度,但這僅僅是因為它們實現了更低的損耗。
因此,有一些證據表明,訓練中增加的噪聲比例不僅僅是收斂的假象,而是因為模型變得更好。如果這是真的,那么我們期望未來的更強大的模型具有更高的噪聲規模,因此可以更加并行化。
在監督學習的背景下,從MNIST到SVHN到ImageNet都有明顯的進展。在強化學習的背景下,從Atari Pong到Dota 1v1到Dota 5v5有明顯的進展,較佳batch大小相差10,000倍以上。
因此,隨著AI進入新的和更困難的任務,我們希望模型能夠容忍更高的batch。
啟示
數據并行度顯著影響AI功能的進展速度。更快的訓練使更強大的模型成為可能,并通過更快的迭代時間加速研究。
在早期研究中,我們觀察到用于訓練較大ML模型的計算,每3.5個月翻一番。我們注意到這種趨勢是由經濟能力和算法并行訓練的能力共同決定的。
后一因素(算法可并行性)更難以預測,其局限性尚不清楚,但我們目前的結果代表了系統化和量化的一步。
特別是,我們有證據表明,在同一任務中,更困難的任務和更強大的模型將允許比我們迄今為止看到的更激進的數據并行性,這為訓練計算的持續快速指數增長提供了關鍵驅動因素。
參考鏈接:
https://blog.openai.com/science-of-ai/
聲明:文章收集于網絡,如有侵權,請聯系小編及時處理,謝謝!歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4834.html
摘要:我仍然用了一些時間才從神經科學轉向機器學習。當我到了該讀博的時候,我很難在的神經科學和的機器學習之間做出選擇。 1.你學習機器學習的歷程是什么?在學習機器學習時你最喜歡的書是什么?你遇到過什么死胡同嗎?我學習機器學習的道路是漫長而曲折的。讀高中時,我興趣廣泛,大部分和數學或科學沒有太多關系。我用語音字母表編造了我自己的語言,我參加了很多創意寫作和文學課程。高中畢業后,我進了大學,盡管我不想去...
摘要:訓練深度神經網絡需要大量的內存,用戶使用這個工具包,可以在計算時間成本僅增加的基礎上,在上運行規模大倍的前饋模型。使用導入此功能,與使用方法相同,使用梯度函數來計算參數的損失梯度。隨后,在反向傳播中重新計算檢查點之間的節點。 OpenAI是電動汽車制造商特斯拉創始人 Elon Musk和著名的科技孵化器公司 Y Combinator總裁 Sam Altman于 2016年聯合創立的 AI公司...

閱讀 2511·2021-09-26 10:18
閱讀 3386·2021-09-22 10:02
閱讀 3183·2019-08-30 15:44
閱讀 3326·2019-08-30 15:44
閱讀 1831·2019-08-29 15:25
閱讀 2572·2019-08-26 14:04
閱讀 2035·2019-08-26 12:15
閱讀 2437·2019-08-26 11:43



