資訊專欄INFORMATION COLUMN

摘要:今天,發(fā)布了一個新的優(yōu)化工具包一套可以讓開發(fā)者,無論是新手還是高級開發(fā)人員,都可以使用來優(yōu)化機(jī)器學(xué)習(xí)模型以進(jìn)行部署和執(zhí)行的技術(shù)。對于相關(guān)的機(jī)器學(xué)習(xí)模型,這可以實現(xiàn)最多倍的壓縮和倍的執(zhí)行速度提升。
今天,TensorFlow發(fā)布了一個新的優(yōu)化工具包:一套可以讓開發(fā)者,無論是新手還是高級開發(fā)人員,都可以使用來優(yōu)化機(jī)器學(xué)習(xí)模型以進(jìn)行部署和執(zhí)行的技術(shù)。
這些技術(shù)對于優(yōu)化任何用于部署的TensorFlow模型都非常有用。特別是對于在內(nèi)存緊張、功耗限制和存儲有限的設(shè)備上提供模型的TensorFlow Lite開發(fā)人員來說,這些技術(shù)尤其重要。
關(guān)于TensorFlow Lite,這里有更多教程:https://www.tensorflow.org/mobile/tflite/

優(yōu)化模型以減小尺寸,降低延遲和功耗,同時使精度損失可以忽略不計
這次添加支持的第一個技術(shù)是向TensorFlow Lite轉(zhuǎn)換工具添加post-training模型量化(post-training quantization)。對于相關(guān)的機(jī)器學(xué)習(xí)模型,這可以實現(xiàn)最多4倍的壓縮和3倍的執(zhí)行速度提升。
通過量化模型,開發(fā)人員還將獲得降低功耗的額外好處。這對于將模型部署到手機(jī)之外的終端設(shè)備是非常有用的。
啟用 post-training quantization
post-training quantization技術(shù)已集成到TensorFlow Lite轉(zhuǎn)換工具中。入門很簡單:在構(gòu)建了自己的TensorFlow模型之后,開發(fā)人員可以簡單地在TensorFlow Lite轉(zhuǎn)換工具中啟用“post_training_quantize”標(biāo)記。假設(shè)保存的模型存儲在saved_model_dir中,可以生成量化的tflite flatbuffer:
1converter=tf.contrib.lite.TocoConverter.from_saved_model(saved_model_dir)
2converter.post_training_quantize=True
3tflite_quantized_model=converter.convert()
4open(“quantized_model.tflite”, “wb”).write(tflite_quantized_model)
我們提供了教程詳細(xì)介紹如何執(zhí)行此操作。將來,我們的目標(biāo)是將這項技術(shù)整合到通用的TensorFlow工具中,以便可以在TensorFlow Lite當(dāng)前不支持的平臺上進(jìn)行部署。
教程:
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/lite/tutorials/post_training_quant.ipynb
post-training 量化的好處
模型大小縮小4倍
模型主要由卷積層組成,執(zhí)行速度提高10-50%
基于RNN的模型可以提高3倍的速度
由于減少了內(nèi)存和計算需求,預(yù)計大多數(shù)模型的功耗也會降低
有關(guān)模型尺寸縮小和執(zhí)行時間加速,請參見下圖(使用單核心在Android Pixel 2手機(jī)上進(jìn)行測量)。

圖1:模型大小比較:優(yōu)化的模型比原來縮小了4倍
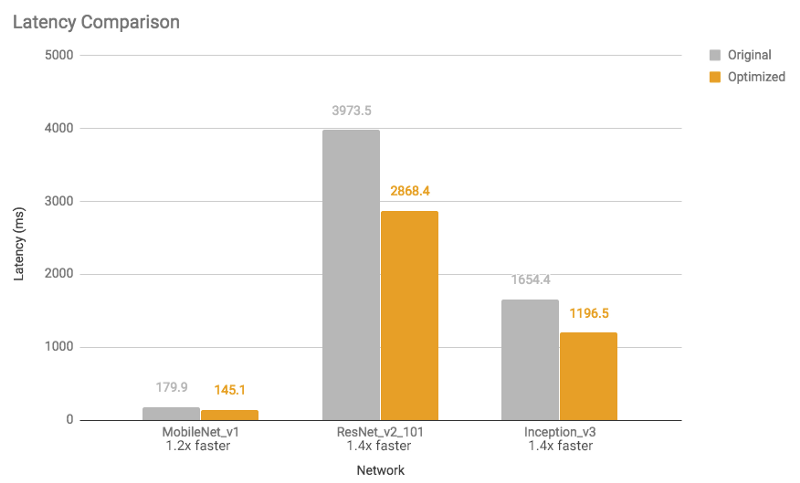
圖2:延遲比較:優(yōu)化后的模型速度提高了1.2到1.4倍
這些加速和模型尺寸的減小對精度影響很小。一般來說,對于手頭的任務(wù)來說已經(jīng)很小的模型(例如,用于圖像分類的mobilenet v1)可能會發(fā)生更多的精度損失。對于這些模型,我們提供預(yù)訓(xùn)練的完全量化模型(fully-quantized models)。

圖3:精度比較:除 mobilenets外,優(yōu)化后的模型的精度下降幾乎可以忽略不計
我們希望在未來繼續(xù)改進(jìn)我們的結(jié)果,請參閱模型優(yōu)化指南以獲得的測量結(jié)果。
模型優(yōu)化指南:
https://www.tensorflow.org/performance/model_optimization
post-training quantization的工作原理
在底層,我們通過將參數(shù)(即神經(jīng)網(wǎng)絡(luò)權(quán)重)的精度從訓(xùn)練時的32位浮點(diǎn)表示降低到更小、更高效的8位整數(shù)表示來運(yùn)行優(yōu)化(也稱為量化)。 有關(guān)詳細(xì)信息,請參閱post-training量化指南。
post-training量化指南:
https://www.tensorflow.org/performance/post_training_quantization
這些優(yōu)化將確保將最終模型中精度降低的操作定義與使用fixed-point和floating-point數(shù)學(xué)混合的內(nèi)核實現(xiàn)配對。這將以較低的精度快速執(zhí)行最繁重的計算,但是以較高的精度執(zhí)行最敏感的計算,因此通常會導(dǎo)致任務(wù)的最終精度損失很小,甚至沒有損失,但相比純浮點(diǎn)執(zhí)行而言速度明顯提高。
對于沒有匹配的“混合”內(nèi)核的操作,或者工具包認(rèn)為必要的操作,它會將參數(shù)重新轉(zhuǎn)換為更高的浮點(diǎn)精度以便執(zhí)行。有關(guān)支持的混合操作的列表,請參閱post-training quantizaton頁面。
未來的工作
我們將繼續(xù)改進(jìn)post-training量化技術(shù)以及其他技術(shù),以便更容易地優(yōu)化模型。這些將集成到相關(guān)的TensorFlow工作流中,使它們易于使用。
post-training量化技術(shù)是我們正在開發(fā)的優(yōu)化工具包的第一個產(chǎn)品。我們期待得到開發(fā)者的反饋。
原文鏈接:
https://medium.com/tensorflow/introducing-the-model-optimization-toolkit-for-tensorflow-254aca1ba0a3?linkId=57036398
聲明:文章收集于網(wǎng)絡(luò),如有侵權(quán),請聯(lián)系小編及時處理,謝謝!
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價值的辦法,實際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/4827.html
摘要:此前,在月底,阿里媽媽就公布了這項開源計劃,引來了業(yè)界的廣泛關(guān)注。突破了現(xiàn)有深度學(xué)習(xí)開源框架大都面向圖像語音等低維稠密數(shù)據(jù)而設(shè)計的現(xiàn)狀,面向高維稀疏數(shù)據(jù)場景進(jìn)行了深度優(yōu)化,并已大規(guī)模應(yīng)用于阿里媽媽的業(yè)務(wù)及生產(chǎn)場景。 showImg(https://segmentfault.com/img/remote/1460000017508808); 剛剛,阿里媽媽正式對外發(fā)布了X-Deep Le...

閱讀 3222·2021-11-23 09:51
閱讀 1029·2021-08-05 09:58
閱讀 663·2019-08-29 16:05
閱讀 970·2019-08-28 18:17
閱讀 3028·2019-08-26 14:06
閱讀 2721·2019-08-26 12:20
閱讀 2154·2019-08-26 12:18
閱讀 3063·2019-08-26 11:56


