資訊專欄INFORMATION COLUMN

摘要:老顧受邀在一些大學和科研機構做了題為深度學習的幾何觀點的報告,匯報了這方面的進展情況。特別是深度學習網絡的學習能力取決于網絡的超參數,如何設計超參數,目前主要依賴于經驗。
(最近,哈佛大學丘成桐先生領導的團隊,大連理工大學羅鐘鉉教授、雷娜教授領導的團隊應用幾何方法研究深度學習。老顧受邀在一些大學和科研機構做了題為“深度學習的幾何觀點”的報告,匯報了這方面的進展情況。這里是報告的簡要記錄,具體內容見【1】。)
上一次博文(深度學習的幾何理解(1) - 流形分布定律)引發很大反響,許多新朋老友和老顧聯系,深入探討學術細節,并給出寶貴意見和建議,在此一并深表謝意。特別是中國科學技術大學的陳發來教授提出了和傳統流形學習相比較的建議;和熊楚渝先生提出通用學習機的X-形式理論等等。

圖1. 巴塞羅那的馬賽克(barcelona mosaic)兔子,揭示深度學習的本質。
(感謝李慧斌教授,贈送給我們藝術品,啟發我們領悟深度學習。)
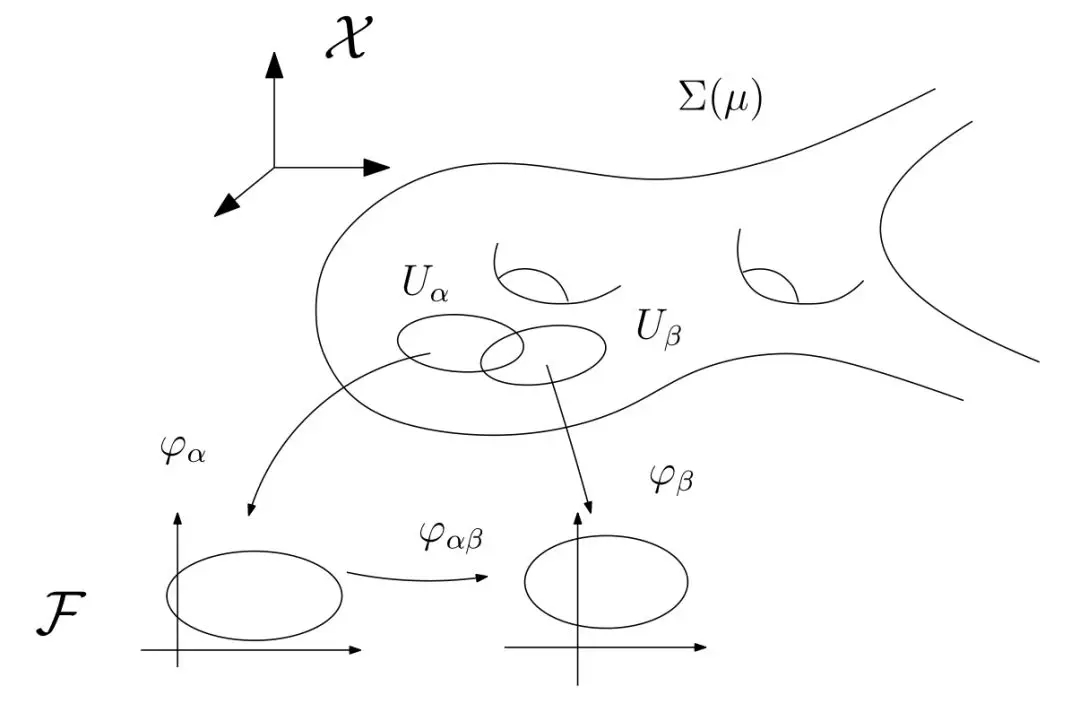
圖2. 流形結構。
萬有逼近定理


但是,我們更為關心的是給定一個流形,給定一個深度神經網絡,這個網絡能否學習這個流形,即能否實現參數化映射,構造參數表示?
網絡學習過程的觀察

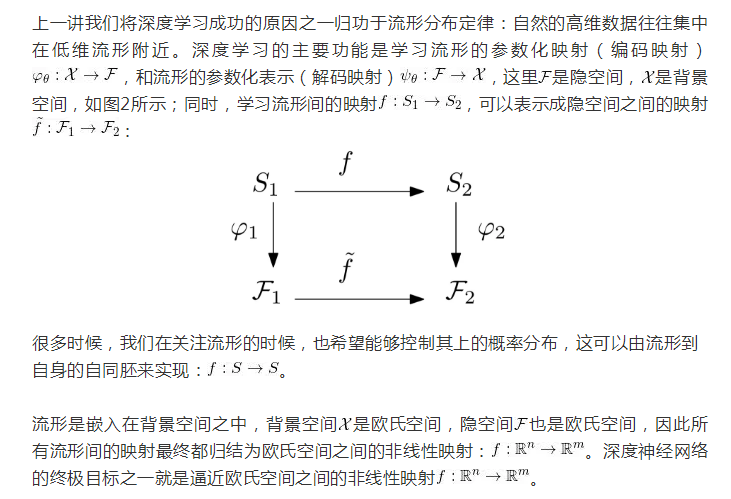
圖3. 自動編碼器學習一條螺旋線。
我們考察一個更為簡單的例子,如圖3所示,一條螺旋線嵌入在二維平面上(上行左幀),autoencoder計算了編碼映射,將其映射到一維直線上(上行中幀),同時計算了解碼映射,將直線映回平面,得到重建的曲線(上行右幀)。編碼映射誘導了平面的胞腔分解(下行左幀),編碼映射和解碼映射的復合誘導了更為細致的胞腔分解(下行中幀),編碼映射的水平集顯示在下行右幀。
由此可見,ReLU深度神經網絡的每個神經元代表一個超平面,將輸入空間一分為二;眾多超平面將輸入空間剖分,然后將每個胞腔線性映射到輸出空間,由此得到編碼、解碼映射的分片線性逼近。進一步,我們可以得到如下關鍵的觀察:流形(螺旋線)被輸入空間上的胞腔分解分割成很多片,每片流形所在的胞腔被線性映射到參數域上(一段直線),這個線性映射限制在流形上是拓撲同胚。
我們將這一計算框架和有限元方法進行類比。線性有限元也是將空間剖分,然后用分片線性函數來逼近目標函數。但是,在有限元方法中,空間剖分和線性逼近是分離的兩個過程。在深度學習中,這兩個過程混合在一起,密不可分。有限元的剖分更加局部靈活,深度學習的剖分全局刻板。同時,兩者都是基于變分法則,即在函數空間中優化某種損失函數。我們可以將每個神經元的參數歸一化,那么深度網絡的所有參數構成一個緊集,損失函數是網絡參數的連續函數,必然存在較大最小值。在傳統有限元計算中,人們往往尋求凸能量,這樣可以保證解的性。在深度學習中,損失函數的凸性比較難以分析。
從歷史經驗我們知道,有限元分析中更為困難的步驟在于設計胞腔分解,這直接關系到解的存在性和計算的精度和穩定性。深度神經網絡所誘導的輸入空間剖分對于優化過程實際上也是至關重要的,我們可以定量地分析網絡的空間剖分能力。
網絡學習的能力


圖4. 米勒佛的參數化(編碼)映射。
我們參看彌勒佛曲面的編碼映射,如圖4所示,編碼映射(參數化映射)可以被ReLU神經網絡表示成分片線性映射,右列顯示了輸入空間和參數空間的胞腔分解。

為網絡的分片線性復雜度(Rectified Linear Complexity)。



這一粗略估計給出了神經網絡所表達的所有分片線性函數的片數的上限,亦即網絡分片線性復雜度的上限。這一不等式也表明:相對于增加網絡寬度,增加網絡的深度能夠更為有效地加強網絡的復雜度,即加強網絡的學習能力。
流形被學習的難度

圖6. 克萊因瓶。
如果的維數小于隱空間的維數,情形更加復雜。比如背景空間為4維歐氏空間,流形為克萊因瓶(Klein bottle),隱空間為3維歐氏空間。那么根據矢量叢理論,克萊因瓶無法嵌入到三維歐氏空間,編碼映射不存在。由此,流形的拓撲為其可學習性帶來本質困難。目前,人們對于深度學習理論的理解尚未達到需要應用拓撲障礙理論的高度,我們相信未來隨著深度學習方法的發展和完備,拓撲理論會被逐步引入。

圖7. 可被線性編碼和不可被線性編碼的曲線。

如圖1所示,巴塞羅那的馬賽克兔子,整體不可被線性編碼。我們可以將流形分成很多片,每一片都是線性可編碼,然后映分片線性映射來構造編碼解碼映射,如此分解所需要的最少片數被定義成流形的分片線性復雜度(Rectified Linear Complexity)。

圖8. Peano曲線。
我們可以構造分片線性復雜度任意高的流形。圖8顯示了經典的皮亞諾曲線。我們首先構造一個單元,如左幀左上角紅色框內所示,然后將此單元拷貝,旋轉平移,重新連接,得到左幀的曲線;如果我們將單元縮小一倍,重新構造,得到右幀所示曲線。重復這一過程,我們可以構造越來越復雜的皮亞諾曲線,直至極限,極限曲線通過平面上的每一個點。在迭代過程中,每一條皮亞諾曲線所包含的單元個數呈指數增長。每個單元都是線性不可編碼的,因此亞諾曲線的分片線性復雜度大于單元個數。在迭代過程中,皮亞諾曲線的分片線性復雜度呈指數增長。經過修改,Peano曲線可以經過任意維歐氏空間中的任意一點。我們將Peano曲線直積上高維球面,就可以構造(k+1)為流形,這種流形具有任意高的復雜度。
如果一個ReLU神經網絡能夠對一個嵌入流形進行編碼,那么網絡的分片線性復雜度必定不低于流形的分片線性復雜度。通過以上討論,我們看到對于固定組合結構的神經網絡,其分片線性復雜度可以被組合結構所界定,我們可以構造一個流形其復雜度超過網絡復雜度的上界。由此我們得到結論:給定一個具有固定組合結構的神經網絡,存在一個流形,此網絡無法學習(編碼)這個流形。雖然大家都在直覺上相信這一結論,但是嚴格的數學證明并不普遍。這里我們將人所共知的一個基本信念加以數學證明。
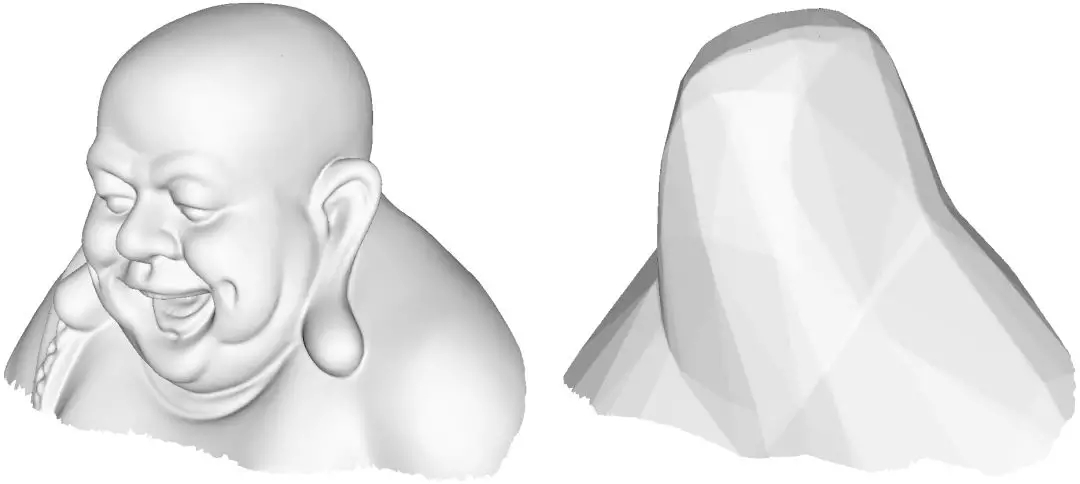
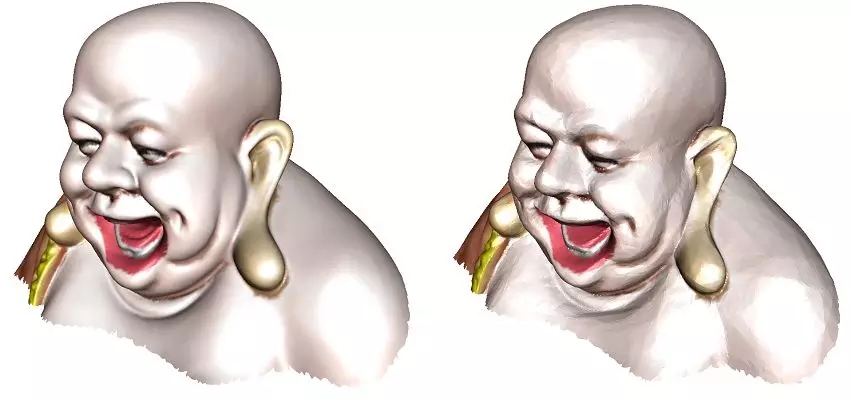
圖9. 不同的學習效果:左幀,輸入流形;右幀,Autoencoder重建的流形。
在實際應用中,深度學習具有很大的工程難度,需要很多經驗性的技巧。特別是深度學習網絡的學習能力取決于網絡的超參數,如何設計超參數,目前主要依賴于經驗。如圖9所示,我們用autoencoder編碼解碼彌勒佛頭像曲面,上面一行顯示了輸入輸出曲面,重建后的曲面大體上模仿了米勒佛的總體形狀,但是失去具體的局部細節。在下面一行,我們加寬了網絡,修改了超參數,重建曲面的逼近精度提高很多。
小結
ReLU深度神經網絡用分片線性函數來逼近一般的非線性函數:每個神經元定義一個超平面,所有的超平面將輸入空間進行胞腔分解,每個胞腔是一個凸多面體。映射在每個胞腔上都是線性映射,整體上是連續的分片線性映射。編碼映射限制在輸入流形上是拓撲同胚。
深度神經網絡將輸入空間分解的最多胞腔個數定義為網絡的分片線性復雜度,代表了網絡學習能力的上限;流形需要被分解,每一片可以被背景空間的線性映射所參數化,這種分解所需的最少片數定義為流形的分片線性復雜度。一個網絡能夠學習一個流形的必要條件是:流形的復雜度低于網絡的復雜度。對于任意一個網絡,我們都可以構造一個流形,使得此網絡無法學習。
目前所做的估計非常粗糙,需要進一步精化;對于優化過程的動力學,目前沒有精細的理論結果,未來需要建立。
在深度學習的應用中,人們不單單只關心流形,也非常關心流形上的概率分布。如何通過改變編解碼映射,使得重建概率分布很好地逼近數據概率分布,使得隱空間的概率分布符合人們預定的標準分布?這些是變分編碼器(VAE)和對抗生成網絡(GAN)的核心問題。下一講,我們討論控制概率分布方法的理論基礎【2,3】。
References? ? ? ? ? ? ? ? ? ??
Na Lei, Zhongxuan Luo, Shing-Tung Yau and David Xianfeng Gu. ?"Geometric Understanding of Deep Learning". arXiv:1805.10451?.?
https://arxiv.org/abs/1805.10451
Xianfeng Gu, Feng Luo, Jian Sun, and Shing-Tung Yau. "Variational principles for minkowski type problems, discrete optimal transport", and discrete monge-ampere equations. Asian Journal of Mathematics (AJM), 20(2):383-398, 2016.
Na Lei,Kehua Su,Li Cui,Shing-Tung Yau,David Xianfeng Gu, "A Geometric View of Optimal Transportation and Generative Model", arXiv:1710.05488. https://arxiv.org/abs/1710.05488
聲明:文章收集于網絡,如有侵權,請聯系小編及時處理,謝謝!
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4792.html
摘要:老顧受邀在一些大學和科研機構做了題為深度學習的幾何觀點的報告,匯報了這方面的進展情況。深度學習的主要目的和功能之一就是從數據中學習隱藏的流形結構和流形上的概率分布。 (最近,哈佛大學丘成桐先生領導的團隊,大連理工大學羅鐘鉉教授、雷娜教授領導的團隊應用幾何方法研究深度學習。老顧受邀在一些大學和科研機構做了題為深度學習的幾何觀點的報告,匯報了這方面的進展情況。這里是報告的簡要記錄,具體內容見【1...
摘要:老顧受邀在一些大學和科研機構做了題為深度學習的幾何觀點的報告,匯報了這方面的進展情況。昨天年月日,嚴東輝教授邀請老顧在泛華統計協會舉辦的應用統計會議上做了深度學習的幾何觀點的報告。小結最優傳輸理論可以用于解釋深度學習中的概率分布變換。 (最近,哈佛大學丘成桐先生領導的團隊,大連理工大學羅鐘鉉教授、雷娜教授領導的團隊應用幾何方法研究深度學習。老顧受邀在一些大學和科研機構做了題為深度學習的幾何觀...
摘要:本文著重以人臉識別為例介紹深度學習技術在其中的應用,以及優圖團隊經過近五年的積累對人臉識別技術乃至整個人工智能領域的一些認識和分享。從年左右,受深度學習在整個機器視覺領域迅猛發展的影響,人臉識別的深時代正式拉開序幕。 騰訊優圖隸屬于騰訊社交網絡事業群(SNG),團隊整體立足于騰訊社交網絡大平臺,專注于圖像處理、模式識別、機器學習、數據挖掘、深度學習、音頻語音分析等領域開展技術研發和業務落地。...

閱讀 875·2021-11-15 11:37
閱讀 3611·2021-11-11 16:55
閱讀 3275·2021-11-11 11:01
閱讀 1005·2019-08-30 15:43
閱讀 2750·2019-08-30 14:12
閱讀 686·2019-08-30 12:58
閱讀 3394·2019-08-29 15:19
閱讀 2032·2019-08-29 13:59




