資訊專欄INFORMATION COLUMN

摘要:系統(tǒng)動(dòng)力學(xué)之父之父再發(fā)新作這一次,他借鑒了人類認(rèn)知世界的模式,為機(jī)器建造了一個(gè)世界觀模型。同時(shí),文摘菌也會(huì)手把手教你訓(xùn)練出一個(gè)有簡單世界觀的賽車手。遞歸神經(jīng)網(wǎng)絡(luò)沒有遞歸神經(jīng)網(wǎng)絡(luò)的賽車手可能會(huì)把車開成這樣。。。
“人類對(duì)周遭世界的認(rèn)知,只是我們腦海中的一個(gè)模型。”——系統(tǒng)動(dòng)力學(xué)之父J.W.Forrester
LSTM之父Ju?rgen Schmidhuber再發(fā)新作!
這一次,他借鑒了人類認(rèn)知世界的模式,為機(jī)器建造了一個(gè)世界觀模型。
諸多證據(jù)表明,人腦為了處理日常生活中的海量信息,學(xué)會(huì)了對(duì)這些時(shí)空信息作出抽象化的處理。借此,我們能夠在面對(duì)周遭復(fù)雜的信息時(shí),進(jìn)行迅速而準(zhǔn)確的分析。而我們?cè)诋?dāng)前所“看”到的這個(gè)世界,也受到了大腦對(duì)未來世界預(yù)測(cè)的影響。
比方說,棒球選手可以毫不費(fèi)力地?fù)糁写驎r(shí)速100英里的棒球,正是得益于大腦對(duì)棒球運(yùn)動(dòng)軌跡的較精確判斷。
那么,我們能不能讓機(jī)器也學(xué)會(huì)這樣的世界觀呢?機(jī)器有了世界觀后又將具備怎么樣的能力呢?
今天,文摘菌就帶你一起來讀LSTM之父的一篇力作。同時(shí),文摘菌也會(huì)手把手教你訓(xùn)練出一個(gè)有簡單世界觀的AI賽車手。到底有多厲害,試了就知道!
在大數(shù)據(jù)文摘后臺(tái)回復(fù)“世界觀”可下載這篇論文~
提出問題
讓我們通過一個(gè)具體案例來探究這個(gè)問題:如何讓機(jī)器擁有世界觀?
假設(shè)我們要訓(xùn)練出一個(gè)AI賽車手,讓它擅長在2D賽道上駕駛汽車。示例如下圖。

在每個(gè)時(shí)間節(jié)點(diǎn),這個(gè)AI賽車手都會(huì)觀察它的周圍環(huán)境(64×64像素彩色圖像),然后決定并執(zhí)行操作——設(shè)定方向(-1到1)、加速(0到1)或制動(dòng)(0到1)。在它執(zhí)行操作后,它所處的環(huán)境會(huì)返回下一個(gè)觀測(cè)結(jié)果。以此類推,這個(gè)過程講不斷重復(fù)。
它的目標(biāo)是,在盡可能短的時(shí)間內(nèi)走完賽道。
解決方案
我們給出一個(gè)由三部分組成的解決方案。
變分自編碼器(VAE)
當(dāng)你在開車的時(shí)候做決定時(shí),你并不會(huì)主動(dòng)分析你視圖中的每一個(gè)“像素”——相反,你的大腦會(huì)將視覺信息凝聚成較少數(shù)量的“隱藏”實(shí)體,比如道路的筆直程度、即將到來的彎道以及你在道路中的相對(duì)位置,從而判斷出你需要操作的下一個(gè)動(dòng)作。
這正是VAE的要義所在——將64x64x3(RGB)輸入圖像壓縮成一個(gè)長度為32的特征向量(z)。
借此,我們的AI賽車手可以用更少的信息去表示周圍的環(huán)境,從而提高學(xué)習(xí)效率。
遞歸神經(jīng)網(wǎng)絡(luò)(RNN)
沒有遞歸神經(jīng)網(wǎng)絡(luò)的AI賽車手可能會(huì)把車開成這樣。。。

回想一下。當(dāng)你開車的時(shí)候,其實(shí)是會(huì)對(duì)下一秒可能出現(xiàn)的情況進(jìn)行持續(xù)預(yù)估的。
而RNN就能夠模擬這種前瞻性思維。
與VAE類似,RNN試圖捕捉到汽車在其所處環(huán)境中當(dāng)前狀態(tài)的隱藏特性,但這次的目的是要基于先前的“z”和先前的動(dòng)作來預(yù)測(cè)下一個(gè)“z”的樣子。
控制器(Controller)
目前為止,我們還沒有提到任何有關(guān)選擇動(dòng)作的事情。因?yàn)椋@些選擇都是控制器要做的。
控制器是一個(gè)密集連接的神經(jīng)網(wǎng)絡(luò),輸入是z(VAE的當(dāng)前隱藏狀態(tài)——長度為32)和h(RNN的隱藏狀態(tài)——長度為256)的串聯(lián),3個(gè)輸出神經(jīng)元對(duì)應(yīng)于三個(gè)動(dòng)作,并被縮放到適當(dāng)?shù)姆秶鷥?nèi)。
為了理解這三個(gè)組成部分所擔(dān)任的不同角色,以及他們是如何一起工作的,我們可以想象他們之間的一段對(duì)話:
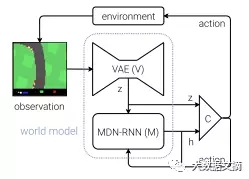
世界模型體系結(jié)構(gòu)圖
VAE:(關(guān)注的64 * 64 * 3的觀測(cè)結(jié)果)這看起來像一條直路,前方稍微向左彎曲,汽車朝向道路方向(z)。
RNN:基于該描述(z)和控制器在上一個(gè)時(shí)間節(jié)點(diǎn)(動(dòng)作)選擇加速的情況,我將更新我的隱藏狀態(tài)(h),以便預(yù)測(cè)下一個(gè)觀測(cè)結(jié)果仍然是筆直的道路,但要略微左轉(zhuǎn)一點(diǎn)。
Controller:基于VAE(z)的描述和RNN(h)反饋的當(dāng)前隱藏狀態(tài),我的神經(jīng)網(wǎng)絡(luò)下一個(gè)輸出的動(dòng)作為[0.34,0.8,0]。
然后,這個(gè)操作會(huì)被傳遞給環(huán)境,該環(huán)境會(huì)返回更新后的觀測(cè)結(jié)果,并重新開始循環(huán)。
現(xiàn)在,讓我們來實(shí)際演練一下吧!
實(shí)現(xiàn)代碼來了
如果你使用的是高規(guī)格筆記本電腦,則可以在本地運(yùn)行此解決方案,但我建議你在谷歌云計(jì)算平臺(tái)(Google Cloud Compute)上用功能更強(qiáng)大的計(jì)算機(jī)來運(yùn)行,從而在短時(shí)間內(nèi)完成。
以下步驟已經(jīng)在Linux(Ubuntu 16.04)上進(jìn)行了測(cè)試——在Mac或Windows上只需要更改軟件包安裝的相關(guān)命令即可。
第一步:下載代碼
在命令行中輸入以下內(nèi)容:
git clone https://github.com/AppliedDataSciencePartners/WorldModels.git
第二步:創(chuàng)建虛擬環(huán)境
創(chuàng)建一個(gè)Python3虛擬環(huán)境(這里使用的是virutalenv和virtualenvwrapper):
sudo apt-get install python-pip
sudo pip install virtualenv
sudo pip install virtualenvwrapper
export WORKON_HOME=~/.virtualenvs
source /usr/local/bin/virtualenvwrapper.sh
mkvirtualenv --python=/usr/bin/python3 worldmodels
第三步:安裝程序包
sudo apt-get install cmake swig python3-dev zlib1g-dev python-opengl
mpich xvfb xserver-xephyr vnc4server
cd WorldModels
pip install -r requirements.txt
第四步:生成隨機(jī)訓(xùn)練數(shù)據(jù)
對(duì)于這個(gè)塞車問題,VAE和RNN都可以使用隨機(jī)生成的訓(xùn)練數(shù)據(jù)——也就是在每個(gè)時(shí)間節(jié)點(diǎn)隨機(jī)采取動(dòng)作所生成的觀測(cè)數(shù)據(jù)。實(shí)際上,我們可以使用偽隨機(jī)動(dòng)作,使車在初始狀態(tài)就能加速離開起跑線。
由于VAE和RNN獨(dú)立于決策控制器,我們需要確保遇到各種各樣的觀測(cè)結(jié)果,并且選擇不同行動(dòng)來應(yīng)對(duì),并將結(jié)果保存為訓(xùn)練數(shù)據(jù)。
要生成隨機(jī)策略,請(qǐng)從命令行運(yùn)行以下命令:
python 01_generate_data.py car_racing --total_episodes 2000 –
start_batch 0 --time_steps 300
如果你的服務(wù)器沒有顯示結(jié)果,你可以運(yùn)行以下命令:
xvfb-run -a -s "-screen 0 1400x900x24" python 01_generate_data.py
car_racing --total_episodes 2000 --start_batch 0 --time_steps 300
以上命令將會(huì)產(chǎn)生2000個(gè)策略,保存在200個(gè)批次中,每個(gè)批次10個(gè))。
在./data文件夾中,你會(huì)看到以下文件(*為批次號(hào)):
obs_data_*.npy (此文件將64 * 64 * 3圖像存儲(chǔ)為numpy數(shù)組)
action_data_*.npy (此文件存儲(chǔ)三維動(dòng)作)
第五步:訓(xùn)練VAE
這里我們只需要用obs_data_*.npy就可以訓(xùn)練VAE。確保你已經(jīng)完成了第四步,否則這個(gè)文件不在./data文件夾下。
在命令行中運(yùn)行下列語句:
python 02_train_vae.py --start_batch 0 --max_batch 9 --new_model
在每一批從0到9的數(shù)據(jù)中都會(huì)訓(xùn)練出一個(gè)新的變分自編碼器VAE。模型的權(quán)重保存在./vae/weights.h5中。“--new_model”參數(shù)表明從頭開始訓(xùn)練模型。
如果文件夾中已經(jīng)存在weights.h5,也沒有聲明“--new_model”參數(shù),腳本將直接導(dǎo)入這個(gè)文件中的權(quán)重,繼續(xù)訓(xùn)練現(xiàn)有的模型。這樣的話,你就可以實(shí)現(xiàn)模型的迭代訓(xùn)練,而不需要對(duì)每批數(shù)據(jù)都重新運(yùn)行。
VAE架構(gòu)的相關(guān)參數(shù)都在 ./vae/arch.py文件里聲明。
第六步:生成循環(huán)神經(jīng)網(wǎng)絡(luò)RNN數(shù)據(jù)
現(xiàn)在我們就可以利用這個(gè)訓(xùn)練好的VAE模型生成RNN模型的訓(xùn)練集。
RNN模型要求把經(jīng)由VAE編碼后的圖像數(shù)據(jù)(z)和動(dòng)作(a)作為輸入,把一個(gè)時(shí)間步長前的由VAE模型編碼后的圖像數(shù)據(jù)作為輸出。
運(yùn)行這行命令可以生成這些數(shù)據(jù):
python 03_generate_rnn_data.py --start_batch 0 --max_batch 9
這一步需要把第0至9批的obs_data_*.npy 和 action_data_*.npy文件轉(zhuǎn)成在RNN中訓(xùn)練所需要的格式。
這兩組文件保存在./data(*是批量編號(hào))
rnn_input_*.npy(存儲(chǔ)了[z a]串聯(lián)向量)
rnn_output_*.npy(存儲(chǔ)了前一個(gè)時(shí)間步長的z向量)
第七步:訓(xùn)練RNN模型
訓(xùn)練RNN只需要用到rnn_input_*.npy和rnn_output_*.npy文件。確認(rèn)你已經(jīng)完成了第六步,否則這個(gè)文件不在./data文件夾下。
在命令行運(yùn)行:
python 04_train_rnn.py --start_batch 0 --max_batch 9 --new_model
在每一批從0到9的數(shù)據(jù)中都會(huì)訓(xùn)練出一個(gè)新的VAE。模型的權(quán)重保存在./rnn/weights.h5。“--new_model”表明從頭開始訓(xùn)練模型。
和VAE訓(xùn)練很相似的是,如果文件夾中已經(jīng)存在weights.h5,也沒有聲明“--new_model”標(biāo)志,腳本將直接導(dǎo)入文件中的權(quán)重,繼續(xù)訓(xùn)練現(xiàn)有的模型。這樣的話,你就可以實(shí)現(xiàn)RNN模型的迭代訓(xùn)練,而不需要對(duì)每批數(shù)據(jù)都重新運(yùn)行。
RNN循環(huán)神經(jīng)網(wǎng)絡(luò)模型的具體參數(shù)都在./rnn/arch.py文件里聲明。
第八步:訓(xùn)練控制器
到了最有趣的部分了!
到目前為止,我們已經(jīng)使用深度學(xué)習(xí)搭建了VAE模型和RNN模型。VAE能把高維的圖片降至低維的隱藏?cái)?shù)據(jù),RNN用來預(yù)測(cè)隱藏空間中數(shù)據(jù)的時(shí)序變化。正因?yàn)槲覀兛梢詫?duì)每個(gè)模型都采用隨機(jī)抽取的數(shù)據(jù)來創(chuàng)建訓(xùn)練集,模型才有可能達(dá)到預(yù)期效果。
為了訓(xùn)練控制器,我們將采用強(qiáng)化學(xué)習(xí)的方法,它使用了名叫CMA-ES(自適應(yīng)協(xié)方差矩陣進(jìn)化算法)的進(jìn)化算法。
輸入是一個(gè)288(32+256)維向量,輸出是一個(gè)3維向量,因此我們要訓(xùn)練的參數(shù)有288 * 3 + 1 (bias) = 867個(gè)。

CMA-ES算法,首先隨機(jī)生成867個(gè)參數(shù)(即一個(gè)群體)的副本,然后對(duì)環(huán)境中每個(gè)群體成員變量做測(cè)試,并記錄其平均得分。正如自然選擇中的法則一樣,產(chǎn)生較高得分的權(quán)重變量允許其繼續(xù)“繁殖”,并生出下一代。
運(yùn)行下列代碼將在你的機(jī)器上啟動(dòng)這個(gè)過程,并為變量選擇合適的值。
python 05_train_controller.py car_racing --num_worker 16 –
num_worker_trial 4 --num_episode 16 --max_length 1000 --eval_steps 25
或者在服務(wù)器上運(yùn)行,但不顯示結(jié)果:
xvfb-run -s "-screen 0 1400x900x24" python 05_train_controller.py?
car_racing --num_worker 16 --num_worker_trial 2 --num_episode 4 –
max_length 1000 --eval_steps 25
--num_worker 16:worker的個(gè)數(shù)不要超過可用內(nèi)核的數(shù)量
--num_work_trial 2 :每個(gè)worker測(cè)試的群體成員的數(shù)量(num_worker * num_work_trial表示每一代群體的總規(guī)模)
--num_episode 4:為群體的每個(gè)成員進(jìn)行打分的次數(shù)(分?jǐn)?shù)將是該次打分的平均得分)
--max_length 1000:一次打分中較大時(shí)間步長
--eval_steps 25:每隔25步對(duì)權(quán)重進(jìn)行評(píng)估
默認(rèn)情況下,控制器每次運(yùn)行都會(huì)從零開始,將進(jìn)程的當(dāng)前狀態(tài)保存到controller目錄的pickle文件中。這樣你就可以通過指定相關(guān)文件,從上一次保存的地方繼續(xù)訓(xùn)練。
每生成一代后,算法的當(dāng)前狀態(tài)和較佳權(quán)重的集合將會(huì)輸出到./controller文件夾。
第九步:可視化結(jié)果
經(jīng)過200代的訓(xùn)練,我已經(jīng)訓(xùn)練出一個(gè)平均得分約為833.13的角色。我在谷歌云上使用配置為Ubuntu 16.04, 18 vCPU, 67.5GB RAM的機(jī)器,采用的是本文給出的步驟和參數(shù)。
在論文中,作者試圖在2000代訓(xùn)練后達(dá)到約906的平均得分,這是迄今為止該環(huán)境下的較高分。他利用了稍高的規(guī)格設(shè)置(例如10,000集訓(xùn)練數(shù)據(jù),群體大小設(shè)為64,64臺(tái)核心機(jī)器,每次試驗(yàn)16次)。
如果你想可視化控制器的當(dāng)前狀態(tài),那你只需要運(yùn)行下列代碼:
python model.py car_racing –filename
?./controller/car_racing.cma.4.32.best.json --render_mode –
record_video
--filename:想要添加到控制器的權(quán)重json的路徑
--render_mode :在屏幕上顯示環(huán)境
--record_video:輸出mp4文件到./video文件夾,展現(xiàn)出每個(gè)片段
--final_mode:運(yùn)行100次控制器測(cè)試,輸出平均得分
就是這樣啦!

第十步:幻覺學(xué)習(xí)
到這一步已經(jīng)很了不起了——但下一步則更令人興奮哦,同時(shí)對(duì)人工智能未來的發(fā)展也很有啟發(fā)意義。
增加難度,我們可以讓賽車在行進(jìn)過程中避免火球的襲擊。
作者展示了角色將怎樣實(shí)際地學(xué)會(huì)如何在自己的VAE / RNN模型啟發(fā)的幻覺夢(mèng)境中玩游戲,而不是在實(shí)際的游戲環(huán)境中。
我們需要做出的改變是,訓(xùn)練RNN使其也可以預(yù)測(cè)出在下一個(gè)時(shí)間步長中賽車被火球擊中的概率。這樣,VAE / RNN組合模型可以作為一個(gè)獨(dú)立的環(huán)境被封裝起來,并用于訓(xùn)練控制器。這就是“世界模式”的概念。
我們將幻覺學(xué)習(xí)的概念總結(jié)如下:
角色的初始訓(xùn)練數(shù)據(jù)不過是與真實(shí)環(huán)境的隨機(jī)互動(dòng)。通過這一互動(dòng),它對(duì)世界“如何運(yùn)作”形成了一種潛在的理解——世界運(yùn)作的物理規(guī)律,以及自己的行為會(huì)如何影響世界的狀態(tài)。
然后,它可以利用這種理解為一個(gè)給定的任務(wù)建立一個(gè)較佳策略,甚至無需在現(xiàn)實(shí)環(huán)境中進(jìn)行測(cè)試,因?yàn)樗梢允褂米约旱囊惶篆h(huán)境模型作為各種測(cè)試的“試驗(yàn)場(chǎng)”。
就像嬰兒學(xué)走路一樣。小嬰兒通過自己的探索建立一個(gè)初步的世界觀,明白自己的動(dòng)作會(huì)帶來的后果,然后一步步調(diào)整自己的策略。在這一過程中,嬰兒甚至能夠在腦海中進(jìn)行自我模擬。
最后,獻(xiàn)上這篇論文的動(dòng)態(tài)演示鏈接:
https://worldmodels.github.io/
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價(jià)值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報(bào)表系統(tǒng)等全方位知識(shí)
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請(qǐng)勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請(qǐng)注明本文地址:http://specialneedsforspecialkids.com/yun/4778.html
摘要:嚴(yán)肅的開場(chǎng)白故事要從深度學(xué)習(xí)說起。本文從視頻分類的角度,對(duì)深度學(xué)習(xí)在該方向上的算法進(jìn)行總結(jié)。數(shù)據(jù)集熟悉深度學(xué)習(xí)的朋友們應(yīng)該清楚,深度學(xué)習(xí)是一門數(shù)據(jù)驅(qū)動(dòng)的技術(shù),因此數(shù)據(jù)集對(duì)于算法的研究起著非常重要的作用。是一個(gè)比較成功的傳統(tǒng)方法與深度學(xué)習(xí)算 showImg(https://segmentfault.com/img/bV7hQP?w=900&h=330); 不嚴(yán)肅的開場(chǎng)白 視頻社交已經(jīng)成為...
摘要:下圖總結(jié)了絕大多數(shù)上的開源深度學(xué)習(xí)框架項(xiàng)目,根據(jù)項(xiàng)目在的數(shù)量來評(píng)級(jí),數(shù)據(jù)采集于年月初。然而,近期宣布將轉(zhuǎn)向作為其推薦深度學(xué)習(xí)框架因?yàn)樗С忠苿?dòng)設(shè)備開發(fā)。該框架可以出色完成圖像識(shí)別,欺詐檢測(cè)和自然語言處理任務(wù)。 很多神經(jīng)網(wǎng)絡(luò)框架已開源多年,支持機(jī)器學(xué)習(xí)和人工智能的專有解決方案也有很多。多年以來,開發(fā)人員在Github上發(fā)布了一系列的可以支持圖像、手寫字、視頻、語音識(shí)別、自然語言處理、物體檢測(cè)的...
摘要:在讓無處不在,讓無所不及的主題論壇上,華為云服務(wù)產(chǎn)品部總經(jīng)理賈永利發(fā)表了讓無所不及的主題演講,分享了華為全棧全場(chǎng)景在使能企業(yè)智能化轉(zhuǎn)型過程的創(chuàng)新解決方案及相關(guān)行業(yè)實(shí)踐。 日前,華為第十六屆全球分析師大會(huì)在中國深圳召開。在讓Cloud無處不在,讓AI無所不及的主題論壇上,華為云EI服務(wù)產(chǎn)品部總經(jīng)理賈永利發(fā)表了《讓AI無所不及》的主題演講,分享了華為全棧全場(chǎng)景AI在使能企業(yè)智能化轉(zhuǎn)型過程的...

閱讀 1828·2021-09-22 15:55
閱讀 3521·2021-09-07 10:26
閱讀 627·2019-08-30 15:54
閱讀 683·2019-08-29 16:34
閱讀 838·2019-08-26 14:04
閱讀 3258·2019-08-26 11:47
閱讀 2133·2019-08-26 11:33
閱讀 2293·2019-08-23 15:17




