資訊專欄INFORMATION COLUMN

摘要:專門設計了一套針對時間序列預測問題的,目前提供三種預測模型。使用模型預測時間序列自回歸模型,可以簡稱為模型是統計學上處理時間序列模型的基本方法之一。使用模型訓練驗證并進行時間序列預測的示例程序為。
前言
如何用TensorFlow結合LSTM來做時間序列預測其實是一個很老的話題,然而卻一直沒有得到比較好的解決。如果在Github上搜索“tensorflow time series”,會發現star數較高的tgjeon/TensorFlow-Tutorials-for-Time-Series已經和TF 1.0版本不兼容了,并且其他的項目使用的方法也各有不同,比較混亂。
在此前發布的TensorFlow 1.3版本中,引入了一個TensorFlow Time Series模塊(源碼地址為:tensorflow/tensorflow - https://github.com/tgjeon/TensorFlow-Tutorials-for-Time-Series,以下簡稱為TFTS)。
TFTS專門設計了一套針對時間序列預測問題的API,目前提供AR、Anomaly Mixture AR、LSTM三種預測模型。
由于是剛剛發布的庫,文檔還是比較缺乏的,我通過研究源碼,大體搞清楚了這個庫的設計邏輯和使用方法,這篇文章是一篇教程帖,會詳細的介紹TFTS庫的以下幾個功能:
讀入時間序列數據(分為從numpy數組和csv文件兩種方式)
用AR模型對時間序列進行預測
用LSTM模型對時間序列進行預測(包含單變量和多變量)
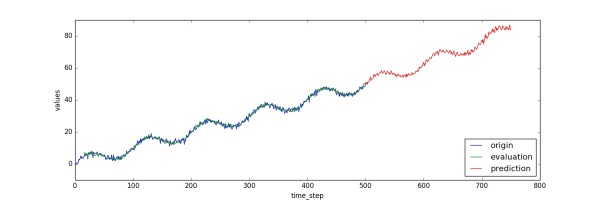
先上效果圖,使用AR模型預測的效果如下圖所示,藍色線是訓練數據,綠色為模型擬合數據,紅色線為預測值:
使用LSTM進行單變量時間序列預測:
使用LSTM進行多變量時間序列預測(每一條線代表一個變量):
文中涉及的所有代碼已經保存在Github上了,地址是:hzy46/TensorFlow-Time-Series-Examples(https://github.com/hzy46/TensorFlow-Time-Series-Examples),以下提到的所有代碼和文件都是相對于這個項目的根目錄來說的。
時間序列問題的一般形式
一般地,時間序列數據可以看做由兩部分組成:觀察的時間點和觀察到的值。以商品價格為例,某年一月的價格為120元,二月的價格為130元,三月的價格為135元,四月的價格為132元。那么觀察的時間點可以看做是1,2,3,4,而在各時間點上觀察到的數據的值為120,130,135,132。
從Numpy數組中讀入時間序列數據
如何將這樣的時間序列數據讀入進來?TFTS庫中提供了兩個方便的讀取器NumpyReader和CSVReader。前者用于從Numpy數組中讀入數據,后者則可以從CSV文件中讀取數據。
我們利用np.sin,生成一個實驗用的時間序列數據,這個時間序列數據實際上就是在正弦曲線上加上了上升的趨勢和一些隨機的噪聲:
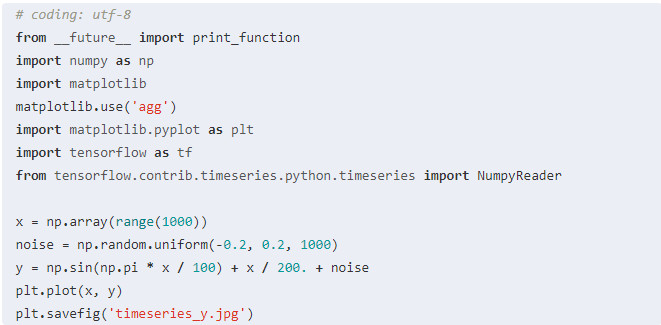
如圖:
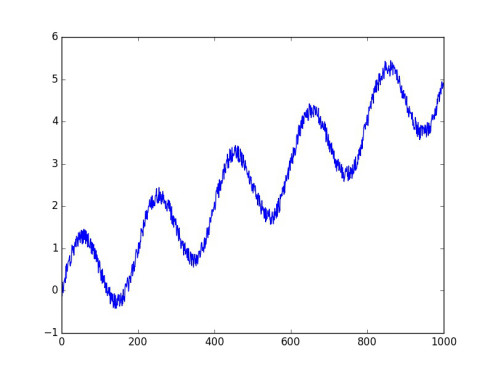
橫坐標對應變量“x”,縱坐標對應變量“y”,它們就是我們之前提到過的“觀察的時間點”以及“觀察到的值”。TFTS讀入x和y的方式非常簡單,請看下面的代碼:
data = {
? ?tf.contrib.timeseries.TrainEvalFeatures.TIMES: x,
? ?tf.contrib.timeseries.TrainEvalFeatures.VALUES: y,
}
reader = NumpyReader(data)
我們首先把x和y變成python中的詞典(變量data)。
變量data中的鍵值tf.contrib.timeseries.TrainEvalFeatures.TIMES實際就是一個字符串“times”,而tf.contrib.timeseries.TrainEvalFeatures.VALUES就是字符串”values”。所以上面的定義直接寫成“data = {‘times’:x, ‘values’:y}”也是可以的。寫成比較復雜的形式是為了和源碼中的寫法保持一致。
得到的reader有一個read_full()方法,它的返回值就是時間序列對應的Tensor,我們可以用下面的代碼試驗一下:
with tf.Session() as sess:
? ? full_data = reader.read_full()
? ? # 調用read_full方法會生成讀取隊列
? ? # 要用tf.train.start_queue_runners啟動隊列才能正常進行讀取
? ? coord = tf.train.Coordinator()
? ? threads = tf.train.start_queue_runners(sess=sess, coord=coord)
? ? print(sess.run(full_data))
? ? coord.request_stop()
不能直接使用sess.run(reader.read_full())來從reader中取出所有數據。原因在于read_full()方法會產生讀取隊列,而隊列的線程此時還沒啟動,我們需要使用tf.train.start_queue_runners啟動隊列,才能使用sess.run()來獲取值。
我們在訓練時,通常不會使用整個數據集進行訓練,而是采用batch的形式。從reader出發,建立batch數據的方法也很簡單:
train_input_fn = tf.contrib.timeseries.RandomWindowInputFn(
? ?reader, batch_size=2, window_size=10)
tf.contrib.timeseries.RandomWindowInputFn會在reader的所有數據中,隨機選取窗口長度為window_size的序列,并包裝成batch_size大小的batch數據。換句話說,一個batch內共有batch_size個序列,每個序列的長度為window_size。
以batch_size=2, window_size=10為例,我們可以打出一個batch內的數據:
with tf.Session() as sess:
? ?batch_data = train_input_fn.create_batch()
? ?coord = tf.train.Coordinator()
? ?threads = tf.train.start_queue_runners(sess=sess, coord=coord)
? ?one_batch = sess.run(batch_data[0])
? ?coord.request_stop()
print("one_batch_data:", one_batch)
這部分讀入代碼的地址在
https://github.com/hzy46/TensorFlow-Time-Series-Examples/blob/master/test_input_array.py。
從CSV文件中讀入時間序列數據
有的時候,時間序列數據是存在CSV文件中的。我們當然可以將其先讀入為Numpy數組,再使用之前的方法處理。更方便的做法是使用tf.contrib.timeseries.CSVReader讀入。項目中提供了一個test_input_csv.py代碼,示例如何將文件./data/period_trend.csv中的時間序列讀入進來。
假設CSV文件的時間序列數據形式為:
1,-0.6656603714
2,-0.1164380359
3,0.7398626488
4,0.7368633029
5,0.2289480898
6,2.257073255
7,3.023457405
8,2.481161007
9,3.773638612
10,5.059257738
11,3.553186083
CSV文件的第一列為時間點,第二列為該時間點上觀察到的值。將其讀入的方法為:
# coding: utf-8
from __future__ import print_function
import tensorflow as tf
csv_file_name = "./data/period_trend.csv"
reader = tf.contrib.timeseries.CSVReader(csv_file_name)
從reader建立batch數據形成train_input_fn的方法和之前完全一樣。下面我們就利用這個train_input_fn來訓練模型。
使用AR模型預測時間序列
自回歸模型(Autoregressive model,可以簡稱為AR模型)是統計學上處理時間序列模型的基本方法之一。在TFTS中,已經實現了一個自回歸模型。使用AR模型訓練、驗證并進行時間序列預測的示例程序為train_array.py。
先建立一個train_input_fn:
x = np.array(range(1000))
noise = np.random.uniform(-0.2, 0.2, 1000)
y = np.sin(np.pi * x / 100) + x / 200. + noise
plt.plot(x, y)
plt.savefig("timeseries_y.jpg")
data = {
? ?tf.contrib.timeseries.TrainEvalFeatures.TIMES: x,
? ?tf.contrib.timeseries.TrainEvalFeatures.VALUES: y,
}
reader = NumpyReader(data)
train_input_fn = tf.contrib.timeseries.RandomWindowInputFn(
? ?reader, batch_size=16, window_size=40)
針對這個序列,對應的AR模型的定義就是:
ar = tf.contrib.timeseries.ARRegressor(
? ?periodicities=200, input_window_size=30, output_window_size=10,
? ?num_features=1,
? ?loss=tf.contrib.timeseries.ARModel.NORMAL_LIKELIHOOD_LOSS)
這里的幾個參數比較重要,分別給出解釋。第一個參數periodicities表示序列的規律性周期。我們在定義數據時使用的語句是:“y = np.sin(np.pi * x / 100) + x / 200. + noise”,因此周期為200。input_window_size表示模型每次輸入的值,output_window_size表示模型每次輸出的值。input_window_size和output_window_size加起來必須等于train_input_fn中總的window_size。在這里,我們總的window_size為40,input_window_size為30,output_window_size為10,也就是說,一個batch內每個序列的長度為40,其中前30個數被當作模型的輸入值,后面10個數為這些輸入對應的目標輸出值。最后一個參數loss指定采取哪一種損失,一共有兩種損失可以選擇,分別是NORMAL_LIKELIHOOD_LOSS和SQUARED_LOSS。
num_features參數表示在一個時間點上觀察到的數的維度。我們這里每一步都是一個多帶帶的值,所以num_features=1。
除了程序中出現的幾個參數外,還有一個比較重要的參數是model_dir。它表示模型訓練好后保存的地址,如果不指定的話,就會隨機分配一個臨時地址。
使用變量ar的train方法可以直接進行訓練:
ar.train(input_fn=train_input_fn, steps=6000)
TFTS中驗證(evaluation)的含義是:使用訓練好的模型在原先的訓練集上進行計算,由此我們可以觀察到模型的擬合效果,對應的程序段是:
evaluation_input_fn = tf.contrib.timeseries.WholeDatasetInputFn(reader)
evaluation = ar.evaluate(input_fn=evaluation_input_fn, steps=1)
如果要理解這里的邏輯,首先要理解之前定義的AR模型:它每次都接收一個長度為30的輸入觀測序列,并輸出長度為10的預測序列。整個訓練集是一個長度為1000的序列,前30個數首先被當作“初始觀測序列”輸入到模型中,由此就可以計算出下面10步的預測值。接著又會取30個數進行預測,這30個數中有10個數就是前一步的預測值,新得到的預測值又會變成下一步的輸入,以此類推。
最終我們得到970個預測值(970=1000-30,因為前30個數是沒辦法進行預測的)。這970個預測值就被記錄在evaluation[‘mean’]中。evaluation還有其他幾個鍵值,如evaluation[‘loss’]表示總的損失,evaluation[‘times’]表示evaluation[‘mean’]對應的時間點等等。
evaluation[‘start_tuple’]會被用于之后的預測中,它相當于最后30步的輸出值和對應的時間點。以此為起點,我們可以對1000步以后的值進行預測,對應的代碼為:
(predictions,) = tuple(ar.predict(
? ?input_fn=tf.contrib.timeseries.predict_continuation_input_fn(
? ? ? ?evaluation, steps=250)))
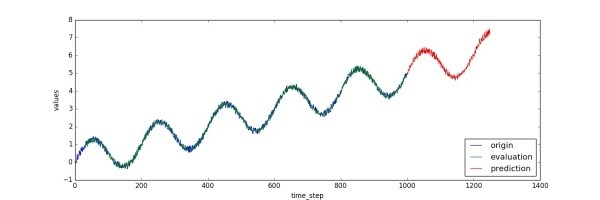
這里的代碼在1000步之后又像后預測了250個時間點。對應的值就保存在predictions[‘mean’]中。我們可以把觀測到的值、模型擬合的值、預測值用下面的代碼畫出來:
向下滑動查看完整代碼???
plt.figure(figsize=(15, 5))
plt.plot(data["times"].reshape(-1), data["values"].reshape(-1), label="origin")
plt.plot(evaluation["times"].reshape(-1), evaluation["mean"].reshape(-1), label="evaluation")
plt.plot(predictions["times"].reshape(-1), predictions["mean"].reshape(-1), label="prediction")
plt.xlabel("time_step")
plt.ylabel("values")
plt.legend(loc=4)
plt.savefig("predict_result.jpg")
畫好的圖片會被保存為“predict_result.jpg”
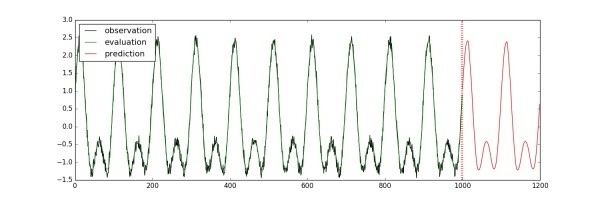
使用LSTM預測單變量時間序列
注意:
以下LSTM模型的例子必須使用TensorFlow的開發版的源碼。具體來說,要保證“from tensorflow.contrib.timeseries.python.timeseries.estimators import TimeSeriesRegressor”可以成功執行。
給出兩個用LSTM預測時間序列模型的例子,分別是train_lstm.py
https://github.com/hzy46/TensorFlow-Time-Series-Examples/blob/master/train_lstm.py
和train_lstm_multivariate.py
https://github.com/hzy46/TensorFlow-Time-Series-Examples/blob/master/train_lstm_multivariate.py
前者是在LSTM中進行單變量的時間序列預測,后者是使用LSTM進行多變量時間序列預測。為了使用LSTM模型,我們需要先使用TFTS庫對其進行定義,定義模型的代碼來源于TFTS的示例源碼
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/timeseries/examples/lstm.py
在train_lstm.py和train_lstm_multivariate.py中分別拷貝了一份。
我們同樣用函數加噪聲的方法生成一個模擬的時間序列數據:
向下滑動查看完整代碼???
x = np.array(range(1000))
noise = np.random.uniform(-0.2, 0.2, 1000)
y = np.sin(np.pi * x / 50 ) + np.cos(np.pi * x / 50) + np.sin(np.pi * x / 25) + noise
data = {
? ?tf.contrib.timeseries.TrainEvalFeatures.TIMES: x,
? ?tf.contrib.timeseries.TrainEvalFeatures.VALUES: y,
}
reader = NumpyReader(data)
train_input_fn = tf.contrib.timeseries.RandomWindowInputFn(
? ?reader, batch_size=4, window_size=100)
此處y對x的函數關系比之前復雜,因此更適合用LSTM這樣的模型找出其中的規律。得到y和x后,使用NumpyReader讀入為Tensor形式,接著用tf.contrib.timeseries.RandomWindowInputFn將其變為batch訓練數據。一個batch中有4個隨機選取的序列,每個序列的長度為100。
接下來我們定義一個LSTM模型:
estimator = ts_estimators.TimeSeriesRegressor(
? ?model=_LSTMModel(num_features=1, num_units=128),
? ?optimizer=tf.train.AdamOptimizer(0.001))
num_features = 1表示單變量時間序列,即每個時間點上觀察到的量只是一個多帶帶的數值。num_units=128表示使用隱層為128大小的LSTM模型。
訓練、驗證和預測的方法都和之前類似。在訓練時,我們在已有的1000步的觀察量的基礎上向后預測200步:
estimator.train(input_fn=train_input_fn, steps=2000)
evaluation_input_fn = tf.contrib.timeseries.WholeDatasetInputFn(reader)
evaluation = estimator.evaluate(input_fn=evaluation_input_fn, steps=1)
# Predict starting after the evaluation
(predictions,) = tuple(estimator.predict(
? ? ?input_fn=tf.contrib.timeseries.predict_continuation_input_fn(
? ? ? ? ? ? ?evaluation, steps=200)))
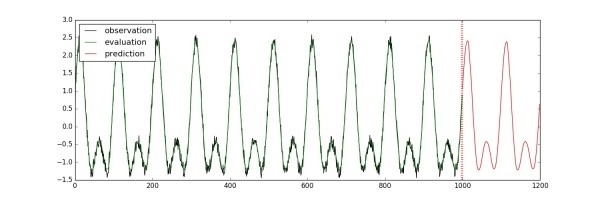
將驗證、預測的結果取出并畫成示意圖,畫出的圖像會保存成“predict_result.jpg”文件:
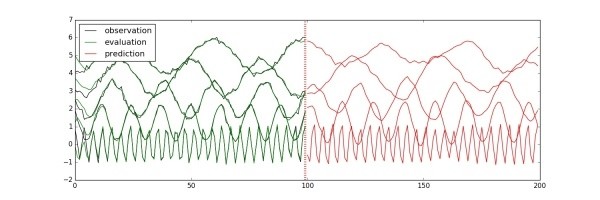
使用LSTM預測多變量時間序列
所謂多變量時間序列,就是指在每個時間點上的觀測量有多個值。在data/multivariate_periods.csv文件中,保存了一個多變量時間序列的數據:
0,0.926906299771,1.99107237682,2.56546245685,3.07914768197,4.04839057867
1,0.108010001864,1.41645361423,2.1686839775,2.94963962176,4.1263503303
2,-0.800567600028,1.0172132907,1.96434754116,2.99885333086,4.04300485864
3,0.0607042871898,0.719540073421,1.9765012584,2.89265588817,4.0951014426
4,0.933712200629,0.28052120776,1.41018552514,2.69232603996,4.06481164223
5,-0.171730652974,0.260054421028,1.48770816369,2.62199129293,4.44572807842
6,-1.00180162933,0.333045158863,1.50006392277,2.88888309683,4.24755865606
7,0.0580061875336,0.688929398826,1.56543458772,2.99840358953,4.52726873347
這個CSV文件的第一列是觀察時間點,除此之外,每一行還有5個數,表示在這個時間點上的觀察到的數據。換句話說,時間序列上每一步都是一個5維的向量。
使用TFTS讀入該CSV文件的方法為:
csv_file_name = path.join("./data/multivariate_periods.csv")
reader = tf.contrib.timeseries.CSVReader(
? ?csv_file_name,
? ?column_names=((tf.contrib.timeseries.TrainEvalFeatures.TIMES,)
? ? ? ? ? ? ? ? ?+ (tf.contrib.timeseries.TrainEvalFeatures.VALUES,) * 5))
train_input_fn = tf.contrib.timeseries.RandomWindowInputFn(
? ?reader, batch_size=4, window_size=32)
與之前的讀入相比,的區別就是column_names參數。它告訴TFTS在CSV文件中,哪些列表示時間,哪些列表示觀測量。
接下來定義LSTM模型:
estimator = ts_estimators.TimeSeriesRegressor(
? ?model=_LSTMModel(num_features=5, num_units=128),
? ?optimizer=tf.train.AdamOptimizer(0.001))
區別在于使用num_features=5而不是1,原因在于我們在每個時間點上的觀測量是一個5維向量。
訓練、驗證、預測以及畫圖的代碼與之前比較類似,可以參考代碼train_lstm_multivariate.py(https://github.com/hzy46/TensorFlow-Time-Series-Examples/blob/master/train_lstm_multivariate.py),此處直接給出最后的運行結果:
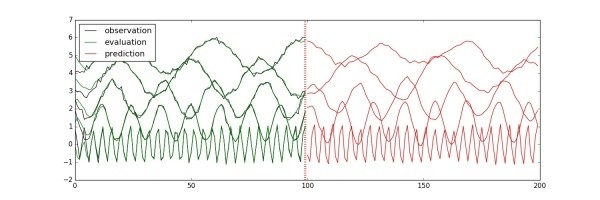
圖中前100步是訓練數據,一條線就代表觀測量在一個維度上的取值。100步之后為預測值。
總結
這篇文章詳細介紹了TensorFlow Time Series(TFTS)庫的使用方法。主要包含三個部分:數據讀入、AR模型的訓練、LSTM模型的訓練。文章里使用的所有代碼都保存在Github上了,地址是:hzy46/TensorFlow-Time-Series-Examples
(https://github.com/hzy46/TensorFlow-Time-Series-Examples)。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4620.html
摘要:據介紹,在谷歌近期的強化學習和基于進化的的基礎上構建,快速靈活同時能夠提供學習保證。剛剛,谷歌發布博客,開源了基于的輕量級框架,該框架可以使用少量專家干預來自動學習高質量模型。 TensorFlow 是相對高階的機器學習庫,用戶可以方便地用它設計神經網絡結構,而不必為了追求高效率的實現親自寫 C++或 CUDA 代碼。它和 Theano 一樣都支持自動求導,用戶不需要再通過反向傳播求解...
摘要:然而,對于廣大工程人員而言,應用新技術仍存在挑戰,谷歌最近開源的庫解決了這個問題。為使開發者更輕松地使用進行實驗,谷歌最近開源了,一個實現輕松訓練和評估的輕量級庫。 生成對抗網絡(GAN)自被 Ian Goodfellow 等人提出以來,以其優異的性能獲得人們的廣泛關注,并應用于一系列任務中。然而,對于廣大工程人員而言,應用新技術仍存在挑戰,谷歌最近開源的 TFGAN 庫解決了這個問題。項目...
摘要:概述這是使用機器學習預測平均氣溫系列文章的最后一篇文章了,作為最后一篇文章,我將使用的開源機器學習框架來構建一個神經網絡回歸器。請注意,我把這個聲明推廣到整個機器學習的連續體,而不僅僅是神經網絡。 概述 ??這是使用機器學習預測平均氣溫系列文章的最后一篇文章了,作為最后一篇文章,我將使用google的開源機器學習框架tensorflow來構建一個神經網絡回歸器。關于tensorflow...

閱讀 3076·2023-04-26 00:53
閱讀 3521·2021-11-19 09:58
閱讀 1693·2021-09-29 09:35
閱讀 3278·2021-09-28 09:46
閱讀 3850·2021-09-22 15:38
閱讀 2691·2019-08-30 15:55
閱讀 3005·2019-08-23 14:10
閱讀 3821·2019-08-22 18:17




