資訊專欄INFORMATION COLUMN

摘要:在一個數據分析任務和任務混合的環境中,大數據分析任務也會消耗很多網絡帶寬如操作,網絡延遲會更加嚴重。本地更新更新更新目前,我們已經復現中的實驗結果,實現了多機并行的線性加速。
王佐,天數潤科深度學習平臺負責人,曾擔任 Intel亞太研發中心Team Leader,萬達人工智能研究院資深研究員,長期從事分布式計算系統研究,在大規模分布式機器學習系統架構、機器學習算法設計和應用方面有深厚積累。
在上一家公司就開始實踐打磨一個深度優化的深度學習系統,當時從消除網絡瓶頸,非凸優化,以及具體的深度學習算法等方面基于PaddlePaddle做了許多工作。目前公司主要深度學習算法都是跑在TensorFlow上,使用配置了GeForce GTX 1080的單機訓練,一次完整的訓練至少需要一周的時間,所以決定從優化TensorFlow多機并行方面提高算力。
為什么要優化 Tensorflow 多機并行
更多的數據可以提高預測性能[2],這也意味著更沉重的計算負擔,未來計算力將成為AI發展的較大瓶頸。在大數據時代,解決存儲和算力的方法是Scale out,在AI時代,Scale out也一定是發展趨勢,并且大數據分析任務和AI/ML任務會共享處理設備(由于AI/ML迭代收斂和容錯的特征,這兩種任務未來不太可能使用統一平臺),所以需要在分布式環境下優化資源配置[3],消除性能瓶頸。雖然現在TensorFlow能支持多機并行分布式訓練,但是針對復雜網絡,其訓練速度反而不如單臺機器[1]。目前已經有IBM[4]和Petuum[1]分別在其深度學習系統PowerAI 4.0和Poseidon中實現多機并行線性加速,本文介紹我如何通過消除TensorFlow的網絡瓶頸,實現TensorFlow多機并行線性加速。
TensorFlow分布式訓練的網絡瓶頸分析
深度學習訓練需要海量的數據,這就需要超大規模參數的網絡模型擬合。如果訓練數據不足,會造成欠擬合;如果網絡模型參數太少,只會得到低精度的模型。目前常見網絡模型參數已經上億,參數大小達到數GB。[10]中給出了訓練數據和參數大小一些例子。
訓練數據和參數大小(來自[10])

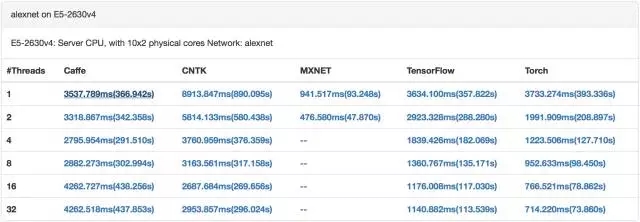
目前GPU已經成為深度學習訓練的標配。GPU具有數量眾多計算單元和超長流水線,并且具備強大并行計算能力與浮點計算能力,可以大幅加速深度學習模型的訓練速度,相比CPU能提供更快的處理速度、更少的服務器投入和更低的功耗。這也意味著,GPU集群上訓練深度學習模型,迭代時間更短,參數同步更頻繁。[9]中對比了主流深度學習系統在CPU和GPU上的訓練性能,可以看出GPU每次迭代的時間比CPU少2個數量級。
CPU 訓練 alexnet(來自[9])
GPU 訓練alexnet(來自[9])
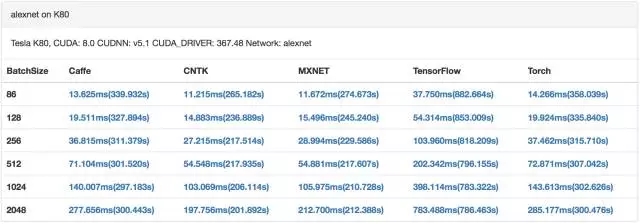
假設每0.5秒一個迭代,每個worker每秒需要通過網絡傳輸的大于4GB,即使使用10GbE,參數同步也會瞬間把網絡占滿。考慮到訓練數據可能通過NFS或者HDFS加載,也會占用很多網絡帶寬。在一個數據分析任務和AI/ML任務混合的環境中,大數據分析任務也會消耗很多網絡帶寬(如shuffle操作),網絡延遲會更加嚴重。所以如果想以Scale out的方式提升算力,網絡將是較大的瓶頸。[1]中通過實驗證明,在8個節點進行TensorFlow分布式訓練,對于VGG19網絡,90%的時間花在等待網絡傳輸上面。
網絡開銷(來自[2])

消除網絡瓶頸的方法(一)
分布式深度學習可以采用BSP和SSP兩種模式。SSP通過允許faster worker使用staled參數,從而達到平衡計算和網絡通信開銷時間的效果[8]。SSP每次迭代收斂變慢,但是每次迭代時間更短,在CPU集群上,SSP總體收斂速度比BSP更快,但是在GPU集群上訓練,BSP總體收斂速度比SSP反而快很多[6]。
BSP模型有個缺點,就是每次迭代結束,Worker需要發送梯度更新到PS,每次迭代開始,Worker需要從PS接收更新后的參數,這會造成瞬間大量的網絡傳輸。參數服務器通過把參數切分成block,并且shard到多臺機器,比較AllReduce,有效利用網絡帶寬,降低網絡延遲。目前主流的深度學習系統(TensorFlow,Mxnet,Petuum)都選擇用參數服務器做參數同步。
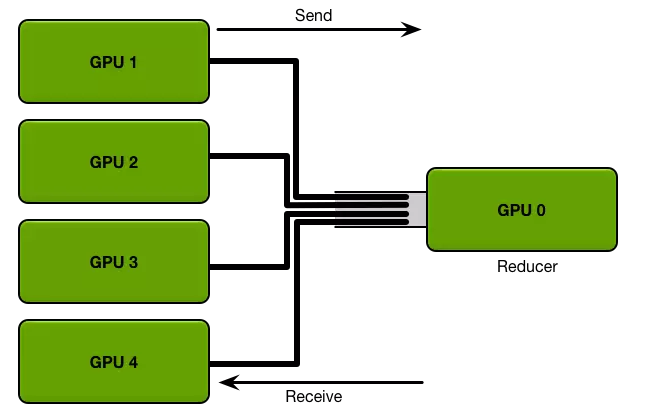
AllReduce(來自[5])
Parameter Server
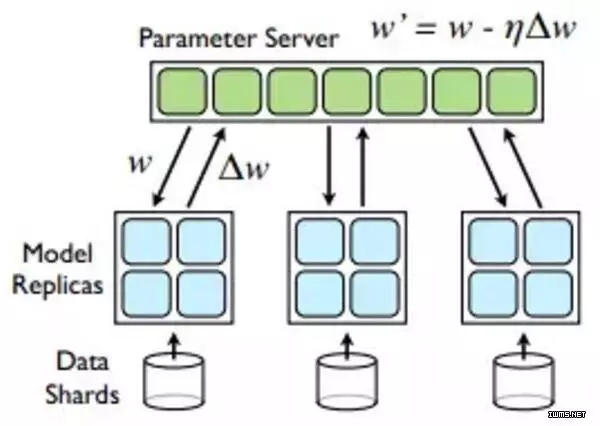
上圖可以很容易看出,AllReduce拓撲中,Reducer節點成為網絡傳輸的瓶頸。PS拓撲中,通常每臺機器啟動相同數量的Worker和Parameter Server,每臺機器的網絡傳輸量基本相同。
ring AllReduce(來自[5])
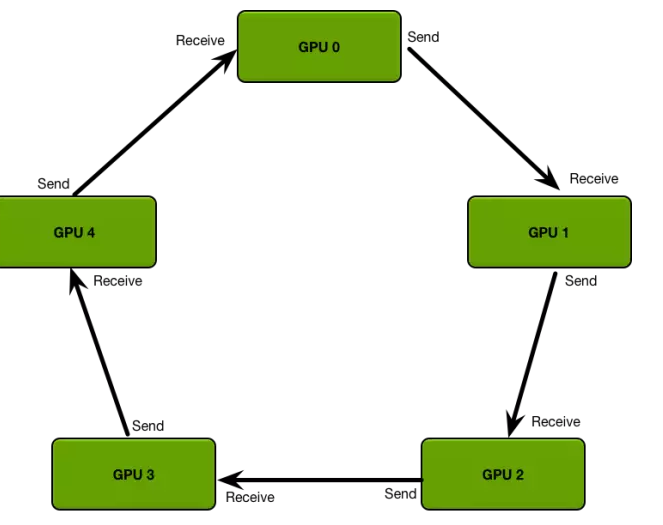
對于多機多卡訓練,可以把參數現在本機聚合,再指定一個worker跟參數服務器交互,可以大量減少網絡傳輸。可以使用PaddlePaddle提出來的ring AllReduce,優化單機多卡的本地聚合。
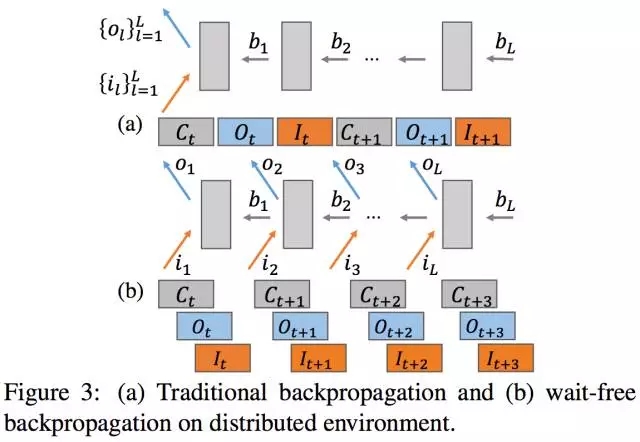
解決瞬間大量的網絡傳輸問題另一個方法是實現GPU計算和網絡通信的Overlap。在反向傳播的backward階段產生梯度時,可異步地進行梯度更新,并立即計算下一層網絡的梯度。梯度更新首先要把新梯度從GPU顯存拷貝到CPU內存,這種GPU-CPU的拷貝也可以和GPU計算做Overlap。因為PS是跑在CPU上,所以GPU計算也跟PS參數更新實現Overlap。
GPU計算和網絡傳輸overlap(來自[1])
消除網絡瓶頸的方法(二)
減少網絡傳輸量也是消除網絡瓶頸的有效途徑。網絡模型中90%參數集中在FC層。很多深度學習系統提出了減少FC層參數大小的方法,比如Adam中的Sufficient Factor,CNTK中的 1-bit quantization,Petuum中的Sufficient Factor Broadcasting[7]。

實現代碼
首先得實現PS和SFB,可以參照petuum,ps-lite,angel。
TensorFlow 相關的修改主要有兩個地方:

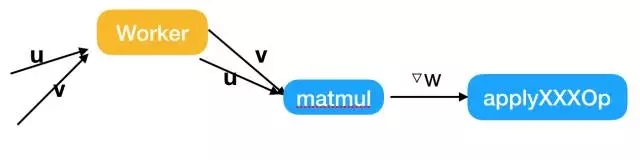
2. tensorflow/core/kernels/http://matmul_op.cc中的MalMulOp::Compute,這里需要判斷是否使用PS或者SFB,從而將本地更新切換為PS更新或SFB更新。
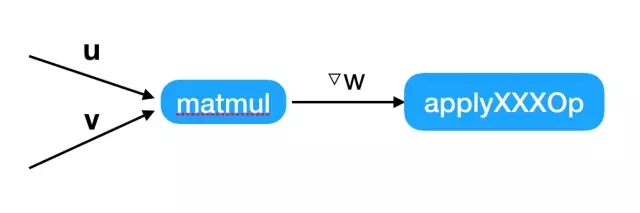
本地更新
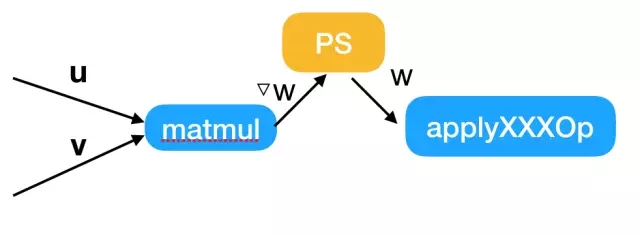
PS更新
SFB更新
目前,我們已經復現[1]中的實驗結果,實現了Tensorflow多機并行的線性加速。我們還在 Tensorflow 其他方面進行優化。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4605.html
摘要:本文內容節選自由主辦的第七屆,北京一流科技有限公司首席科學家袁進輝老師木分享的讓簡單且強大深度學習引擎背后的技術實踐實錄。年創立北京一流科技有限公司,致力于打造分布式深度學習平臺的事實工業標準。 本文內容節選自由msup主辦的第七屆TOP100summit,北京一流科技有限公司首席科學家袁進輝(老師木)分享的《讓AI簡單且強大:深度學習引擎OneFlow背后的技術實踐》實錄。 北京一流...

閱讀 828·2021-09-22 15:18
閱讀 1180·2021-09-09 09:33
閱讀 2757·2019-08-30 10:56
閱讀 1183·2019-08-29 16:30
閱讀 1487·2019-08-29 13:02
閱讀 1458·2019-08-26 13:55
閱讀 1642·2019-08-26 13:41
閱讀 1941·2019-08-26 11:56


