資訊專欄INFORMATION COLUMN

摘要:近段時間以來,張量與新的機器學習工具如是非常熱門的話題,在那些尋求應用和學習機器學習的人看來更是如此。計算機之所以可憑極快速度求出用線性代數編寫的程序值,部分原因是線性代數具有規律性。但是,我們沒有必要把自己限制在線性代數上。
近段時間以來,張量與新的機器學習工具(如 TensorFlow)是非常熱門的話題,在那些尋求應用和學習機器學習的人看來更是如此。但是,當你回溯歷史,你會發現一些基礎但強大的、有用且可行的方法,它們也利用了張量的能力,而且不是在深度學習的場景中。下面會給出具體解釋。
如果說計算是有傳統的,那么使用線性代數的數值計算就是其中最重要的一支。像 LINPACK 和 LAPACK 這樣的包已經是非常老的了,但是在今天它們任然非常強大。其核心,線性代數由非常簡單且常規的運算構成,它們涉及到在一維或二維數組(這里我們稱其為向量或矩陣)上進行重復的乘法和加法運算。同時線性代數適用范圍異常廣泛,從計算機游戲中的圖像渲染到核武器設計等許多不同的問題都可以被它解決或近似計算,
關鍵的線性代數運算:在計算機上使用的最基礎的線性代數運算是兩個向量的點積(dot product)。這種點積僅僅是兩個向量中相關元素的乘積和。一個矩陣和一個向量的積可以被視為該矩陣和向量行(row)的點積,兩個矩陣的乘積可以被視為一個矩陣和另一個矩陣的每一列(column)進行的矩陣-向量乘積的和。此外,再配上用一個值對所有元素進行逐一的加法和乘法,我們可以構造出所需要的線性代數運算機器。
計算機之所以可憑極快速度求出用線性代數編寫的程序值,部分原因是線性代數具有規律性。此外,另一個原因是它們可以大量地被并行處理。完全就潛在性能而言,從早期的 Cray-1(譯者注:Cary-1 是世界上最早的一臺超級計算機,于 1975 年建造,運算速度每秒 1 億次)到今天的 GPU 計算機,我們可以發現性能增長了超過 30000 倍。此外,當你要考慮用大量 GPU 處理集群數據時,其潛在的性能,在極小成本下,比曾經世上最快速的計算機大約高出一百萬倍。
然而,歷史的模式總是一致的,即要想充分利用新的處理器,我們就要讓運算越來越抽象。Cray-1 和它向量化的后繼者們需要其運行程序能夠使用向量運算(如點積)才能發揮出硬件的全部性能。后來的機器要求要就矩陣-向量運算或矩陣-矩陣運算來將算法形式化,從而方可盡可能地發揮硬件的價值。
我們現在正站在這樣一個結點上。不同的是我們沒有任何超越矩陣-矩陣運算的辦法,即:我們對線性代數的使用已達極限。
但是,我們沒有必要把自己限制在線性代數上。事實證明,我們可以沿著數學這棵大樹的枝葉往上再爬一段。長期以來,人們都知道在數學抽象的海洋中存在著比矩陣還要大的魚,這其中一個候選就是張量(tensor)。張量是廣義相對論重要的數學基礎,此外它對于物理學的其它分支來說也具有基礎性的地位。那么如同數學的矩陣和向量概念可被簡化成我們在計算機中使用的數組一樣,我們是否可以將張量也簡化和表征成多維數組和一些相關的運算呢?很不幸,事情沒有那么簡單,這其中的主要原因是不存在一個顯而易見且簡單的(如在矩陣和向量上類似的)可在張量上進行的一系列運算。
然而,也有好消息。雖然我們不能對張量使用僅幾個運算。但是我們可以在張量上寫下一套運算的模式(pattern)。不過,這還不不夠,因為根據這些模式編寫的程序不能像它們寫的那樣被充分高效地執行。但我們還有另外的好消息:那些效率低下但是編寫簡單的程序可以被(基本上)自動轉換成可非常高效執行的程序。
更贊的是,這種轉換可以無需構建一門新編程語言就能實現。只需要一個簡單的技巧就可以了,當我們在 TensorFlow 中寫下如下代碼時:
v1 = tf.constant(3.0)
v2 = tf.constant(4.0)
v3 = tf.add(node1, node2)
實際情況是,系統將建立一個像圖 1 中顯示的數據結構:
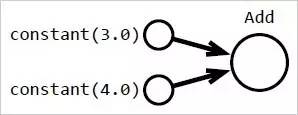
圖 1:上方的代碼被轉譯成一個可被重建的數據結構,而且它會被轉成機器可執行的形式。將代碼轉譯成用戶可見的數據結構可讓我們所編寫的程序能被重寫從而更高效地執行,或者它也可以計算出一個導數,從而使高級優化器可被使用。
該數據結構不會在上面我們展示的程序中實際執行。因此,TensorFlow 才有機會在我們實際運行它之前,將數據結構重寫成更有效的代碼。這也許會牽涉到我們想讓計算機處理的小型或大型結構。它也可生成對我們使用的計算機 CPU、使用的集群、或任何手邊可用的 GPU 設備實際可執行的代碼。對它來說很贊的一點是,我們可以編寫非常簡單但可實現令人意想不到結果的程序。
然而,這只是開始。
做一些有用但不一樣的事
TensorFlow 和像它一樣的系統采用的完全是描述機器學習架構(如深度神經網絡)的程序,然后調整那個架構的參數以最小化一些誤差值。它們通過創建一個表征我們程序的數據結構,和一個表征相對于我們模型所有參數誤差值梯度的數據結構來實現這一點。這個梯度函數的存在使得優化變得更加容易。
但是,雖然你可以使用 TensorFlow 或 Caffe 或任何其它基本上同樣工作模式的架構來寫程序,不過你寫的程序不一定要去優化機器學習函數。如果你寫的程序使用了由你選擇的包(package)提供的張量標注,那它就可以優化所有類型的程序。自動微分和較先進的優化器以及對高效 GPU 代碼的編譯對你仍然有利。
舉個簡例,圖二給出了一個家庭能耗的簡單模型。
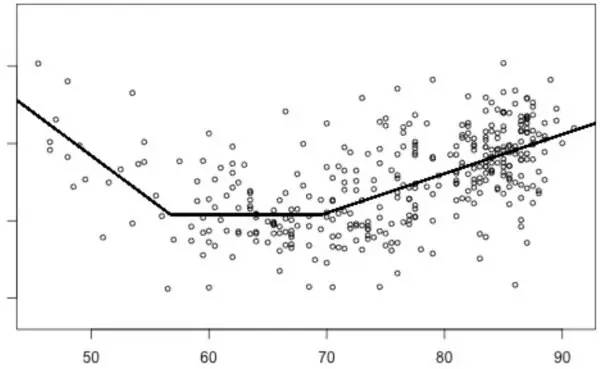
圖 2:該圖顯示了一間房子的日常能耗情況(圓圈),橫軸代表了溫度(華氏度)。能耗的一個分段線性模型疊加在了能耗具體數據上。模型的參數按理來說會形成一個矩陣,但是當我們要處理上百萬個模型時,我們便可以用到張量。
該圖顯示了一間房子的能耗使用情況,并對此進行了建模。得到一個模型不是什么難事,但是為了找出這個模型,筆者需要自己寫代碼來分別對數百萬間房子的能耗情況進行建模才行。如果使用 TensorFlow,我們可以立即為所有這些房子建立模型,并且我們可以使用比之前得到這個模型更有效的優化器。于是,筆者就可以立即對數百萬個房間的模型進行優化,而且其效率比之前我們原始的程序要高得多。理論上我們可以手動優化代碼,并且可以有人工推導的導數函數。不過完成這項工作所需要的時間,以及更重要的,調試花費的時間會讓筆者無法在有限時間里建立這個模型。
這個例子為我們展示了一個基于張量的計算系統如 TensorFlow(或 Caffe 或 Theano 或 MXNet 等等)是可以被用于和深度學習非常不同的優化問題的。
所以,情況可能是這樣的,對你而言較好用的機器學習軟件除了完成機器學習功能以外還可以做很多其它事情。
原文鏈接:http://www.kdnuggets.com/2017/06/deep-learning-demystifying-tensors.html
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4563.html
摘要:是一個專為移動端異構計算平臺優化的神經網絡計算框架。地址文檔鏈接打開在線文檔網頁,引入眼簾的是這里簡單介紹一下中的內容移動計算引擎是一種針對移動異構計算平臺優化的深度學習推理框架。 Mobile AI Compute Engine (MACE) 是一個專為移動端異構計算平臺優化的神經網絡計算框架。主要從以下的角度做了專門的優化:性能代碼經過NEON指令,OpenCL以及Hexagon HVX...

閱讀 2265·2023-04-25 23:15
閱讀 1917·2021-11-22 09:34
閱讀 1546·2021-11-15 11:39
閱讀 955·2021-11-15 11:37
閱讀 2152·2021-10-14 09:43
閱讀 3493·2021-09-27 13:59
閱讀 1506·2019-08-30 15:43
閱讀 3454·2019-08-30 15:43



