資訊專欄INFORMATION COLUMN

摘要:就在最近,這項技術在流行地無監督學習數據集上實現了非常好的結果。雖然這項工作并不針對無監督學習,但是它可以用作無監督學習。利用替代類別的無監督學習視覺表征使用圖像不行來創建非常大的替代類。
如今深度學習模型都需要在大規模的監督數據集上訓練。這意味著對于每一個數據,都會有一個與之對應的標簽。在很流行的 ImageNet 數據集中,其共有一百萬張帶人工標注的圖片,即 1000 類中的每一類都有 1000 張。創建這么一個數據集是需要一番功夫的,可能需要很多人花數月的功夫完成。假定現在要創建一個有一百萬類的數據集,那么就必須給總共 1 億幀視頻數據集中的每一幀做標注,這基本是無法實現的。
現在,回想一下在你很小的時候,自己是如何得到教導的。沒錯,我們的確受到了一些監督,但是當你的父母告訴你這是一只「貓」之后,他們不會在日后的生活中每一次觀察到貓時都告訴你這是「貓」!而如今的監督式學習是這樣的:我一次又一次地告訴你「貓」是什么樣的,也許會重復一百萬次。然后你的深度學習模型就領會了關于貓的知識。
理想情況下,我們希望有一個更像我們的大腦一樣去運行得模型。它僅僅需要很少的一些標簽就能夠理解現實世界中的很多類事物。在現實世界中,我指的類是物體類別、動作類別、環境類別、物體的部分的類別,諸如此類還有很多很多。
正如你會在這篇評論中看到的一樣,最成功的模型就是那些能夠預測視頻中即將出現的畫面的模型。很多這類技術面臨并正嘗試解決的一個問題,即為了達到良好的全局表現,訓練要在視頻上進行,而不是靜態的圖片上。這是將學習到的表征應用在實際任務中的途徑。
基本概念
無監督學習研究的主要目標就是要預訓練出能夠用于其他任務的模型(即鑒別器或者編碼器)。編碼器的特點應該盡可能的通用,以便可以用在分類任務中(如在 ImageNet 上進行訓練),并且提供盡可能像監督模型一樣好的結果。
的監督模型總是表現得比無監督預訓練模型更好。那是因為,監督會允許模型能夠更好的編碼數據集上的特征。但是當模型應用在其他的數據集上時,監督會衰減。在這方面,無監督訓練有希望提供更加通用的特性來執行任何任務。
如果以實際生活中的應用為目標,例如無人駕駛、動作識別、目標檢測和實時提取中的識別,那么算法需要在視頻上訓練。
自編碼器
UC Davis 的 Bruno Olshausen 和康奈爾大學的 David Field 于 1996 年的發表的論文《Sparse Coding with an Overcomplete Basis Set: A Strategy by V1?》(論文鏈接:http://redwood.psych.cornell.edu/papers/olshausen_field_1997.pdf) 表明,編碼理論可以被用在視覺皮層的接收域中。他們證明了我們大腦中的基本視覺旋渦 (V1) 使用稀疏性原理來創建一個能夠被用于重建輸入圖像的基本功能的最小集合。
下面的鏈接是 2014 年倫敦微軟 Bing 團隊的 Piotr Mirowski 關于自動編碼器的一個很好的綜述。
鏈接:https://piotrmirowski.files.wordpress.com/2014/03/piotrmirowski_2014_reviewautoencoders.pdf
Yann LeCun 的團隊也從事這個領域的研究。在鏈接網頁中的 demo 中,你可以看到像 V1 一樣的濾波器是如何學習的。(鏈接:http://www.cs.nyu.edu/~yann/research/deep/)
通過重復貪婪逐層訓練的過程,堆棧式自編碼器(Stacked-auto encoder)也被使用了。
自動編碼器方法也被稱為直接映射方法。
自動編碼器/稀疏編碼/堆疊式自動編碼的優點和缺點
優點:
簡單的技術:重建輸入
多層可堆疊
直觀和基于神經科學的研究
缺點
每一層都被貪婪地(greedily)訓練
沒有全局優化
比不上監督學習地性能
多層失效
對通用目標地表征而言,重建輸入可能不是理想的指標
聚類學習
它是用 k-means 聚類在多層中學習濾波器的一種技術。
我們組把這項技術命名為:聚類學習(見論文:Clustering Learning for Robotic Vision)、聚類連接 (見論文:An Analysis of the Connections Between Layers of Deep Neural Networks),以及卷積聚類 (見論文:Convolutional Clustering for Unsupervised Learning)。就在最近,這項技術在流行地無監督學習數據集 STL-10 上實現了非常好的結果。
我們在這個領域的研究和 Adam Coates 與 Andrew Ng 在基于 k-means 學習特征表示 ( Learning Feature Representations with K-means ) 中發表的研究成果是獨立的。
眾所周知,由于在求解配分函數時的數值問題,受限波爾茲曼機(RBM),深波爾茲曼機(DBM),深度信念網絡(DBN/參見 Geoffrey E. Hinton 等人的研究:A fast learning algorithm for deep belief net)等模型已經很難去訓練了。因此,它們沒有廣泛應用于解決問題中。
聚類學習的優缺點:
優點:
簡單的技術:得到相似群集的輸出
多層可堆疊
直觀和基于神經科學的研究
缺點:
每一層都被貪婪地訓練
沒有全局優化
在某些情況下可以和監督學習的性能媲美
多層遞增式失效==性能回報遞減
生成對抗網絡模型
生成對抗網絡嘗試通過鑒別器和生成器的對抗而得來一個優良的生成模型,該網絡希望能夠生成足以騙過鑒別器的逼真圖像。生成模型這一領域近年來十分優秀的生成對抗網絡正是由 Ian Goodfellow 和 Yoshua Bengio 等人在論文《Generative Adversarial Nets》中提出。這里還有 OpenAI 的研究員 Ian 在 2016 年底做的關于生成對抗網絡 (GANS) 的總結,視頻鏈接:https://channel9.msdn.com/Events/Neural-Information-Processing-Systems-Conference/Neural-Information-Processing-Systems-Conference-NIPS-2016/Generative-Adversarial-Networks。
由 Alec Radford、 Luke Metz 以及 Soumith Chintala 等人實例化的一個被稱作 DCGAN 的生成對抗模型取得了非常好的結果。他們的研究發表在論文:Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks。
Vincent Dumoulin 和 Ishmael Belghazi 等人對這個模型做了一個比較好的解釋(鏈接:https://ishmaelbelghazi.github.io/ALI/)。
DCGAN 鑒別器被設計來判斷一副輸入圖片是真實的(來源于某個數據集的真實圖片)或虛假的(來源于某個生成器)。生成器將隨機地噪聲向量(例如 1024 個數值)作為輸入,并生成一副圖片。
在 DCGAN 中,生成器網絡如下:
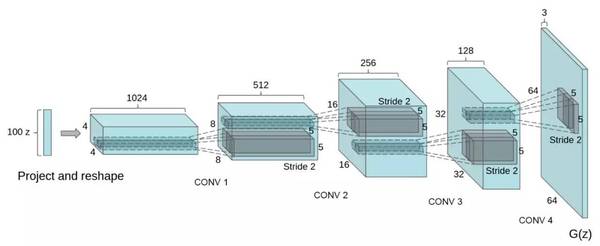
盡管這個鑒別器是一個標準的神經網絡。具體的細節可以參考下文提及的代碼。
關鍵是要并行地去訓練這兩個網絡,同時不要完全過擬合,因此才會復制數據集。學習到的特征需要泛化在未知的樣本上,所以學習數據集將不會有用。
在 Torch7 上訓練 DCGAN 的代碼(https://github.com/soumith/dcgan.torch)也被提供了。這需要大量的實驗,相關內容 Yann LeCun 在 Facebook 中也分享過:https://www.facebook.com/yann.lecun/posts/10153269667222143
當生成器和鑒別器都被訓練之后,你可以同時使用兩者。主要的目標就是訓練出一個能夠被用于其他任務的鑒別器網絡,例如在其他數據集上可以分類。生成器可以用來從隨機向量中生成圖片。這些圖片有著非常有趣的屬性。首先,它們從輸入空間中提供了平滑的變換。如下所示的例子展示了在 9 個隨機輸入向量中移動而生成的圖片:

輸入向量空間也提供了數學屬性,證明學習到的特征是按照相似性來組織的,如下圖所示:
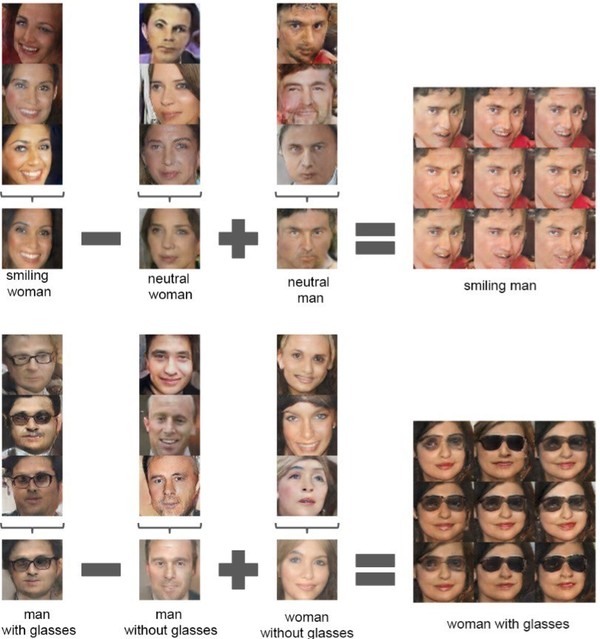
生成器學習到的平滑空間啟示鑒別器也要有類似的屬性,這使得鑒別器在編碼圖像時成了一個很棒的通用特征提取器。這有助于解決 CNN 在訓練不連續圖像的時候由于對抗噪聲而造成的失敗(詳見 Christian Szegedy 等人的文章《Intriguing properties of neural networks》,https://arxiv.org/abs/1312.6199)。
GAN 的進展,在僅有 1000 個標簽樣本的 CIFAR-10 數據集上實現了 21% 的錯誤率,參見 OpenAI 的 Tim Salimans 等人的論文《Improved Techniques for Training GANs》,論文鏈接:https://arxiv.org/pdf/1606.03498v1.pdf。
最近關于 infoGAN 的論文《InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets》(鏈接:https://arxiv.org/abs/1606.03657)中,能夠產生特征非常清晰的圖像,并且這些圖像具有更加有趣的意義。然而,他們并沒有公布學習到的特征在某項任務或某個數據集中的性能對比。
在如下所示的博客和網站中也有關于生成對抗模型的總結,參見 OpenAI 的技術博客 https://blog.openai.com/generative-models/ 和網頁 https://code.facebook.com/posts/1587249151575490/a-path-to-unsupervised-learning-through-adversarial-networks/。
另一個非常有趣的例子如下,在例子中,作者用生成對抗訓練去學習從文本描述中生成圖像。參見論文《Generative Adversarial Text to Image Synthesis》,鏈接:https://arxiv.org/abs/1605.05396。

我最欣賞這項工作的地方在于它所使用的網絡用文本描述作為生成器的輸入,而不是隨機向量,這樣就可以較精確地控制生成器的輸出。網絡模型結構如下圖所示:
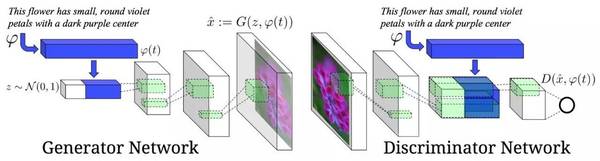
生成對抗模型的缺點和優點
優點:
對整個網絡的全局訓練
易于編程和實現
缺點:
難以訓練和轉換問題
在某些情況下可以比得上監督學習的性能
需要提升可用性(這是所有無監督學習算法面臨的問題)
可以從數據中學習的模型
通過設計不需要標簽的無監督學習任務和旨在解決這些任務的學習算法,這些模型直接從無標簽的數據中學習。
在視覺表征中通過解決拼圖問題來進行無監督學習確實是一個聰明的技巧。作者將圖像分割成了拼圖,并且訓練深度網絡來解決拼圖問題。最終得到的網絡的表現足以比肩較好的預訓練網絡。詳見論文《Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles》,鏈接:https://arxiv.org/abs/1603.09246
在視覺表征中通過圖像補丁和布局來進行無監督學習也是一個聰明的技巧。他們讓同一幅圖像上的兩個補丁緊密分布。這些補丁在統計上來講是同一個物體。第三個補丁選擇隨機的圖像,并且布局在隨機的位置,從統計上來講與前兩個補丁并不是同一類物體。然后訓練一個深度網絡來區分兩個屬于同一類的補丁和另一個不同類別的補丁。最終得到的網絡具有和較高性能精調網絡之一相同的性能。詳情參見論文《Learning visual groups from co-occurrences in space and time》,鏈接:https://arxiv.org/abs/1511.06811。
從立體圖像重建中進行的無監督學習模型采用立體圖像作為輸入,例如圖像一幀的左半部分,然后重建出圖像的右半部分。雖然這項工作并不針對無監督學習,但是它可以用作無監督學習。這種方法也可以用來從靜態圖片生成 3D 電影。參見論文《Deep3D: Fully Automatic 2D-to-3D Video Conversion with Deep Convolutional Neural Networks》,鏈接:https://arxiv.org/abs/1604.03650,github 上的 Python 源碼:https://github.com/piiswrong/deep3d。
利用替代類別的無監督學習視覺表征使用圖像不行來創建非常大的替代類。這些圖像補丁然后被增強,然后被用來訓練基于增強替代類的監督網絡。這在無監督特征學習中給出了較好的結果。詳情參見論文《Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks》,鏈接:https://arxiv.org/abs/1406.6909。
使用視頻的無監督學習視覺表征采用了基于 LSTM 的編碼器-解碼器對。編碼 LSTM 運行在視頻幀的序列上以生成一個內部表征。隨后這些表征通過另一個 LSTM 被解碼以生成一個目標序列。為了使這個變成無監督的,一種方法是預測與輸入相同的序列。另一種方式是預測未來的幀。詳情參見論文《Unsupervised Learning of Visual Representations using Videos》,鏈接:https://arxiv.org/abs/1505.00687。
另一篇使用視頻的文章出自 MIT 的 Vondrick 和 Torralba 等人(http://arxiv.org/abs/1504.08023),有著非常惹人注目的結果。這項工作背后的思想是從視頻輸入中預測未來幀的表示。這是一種優雅的方法。使用的模型如下:
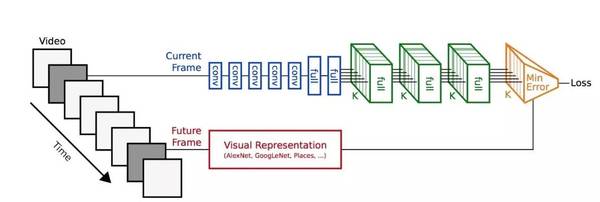
這項技術的一個問題就是:一個訓練在靜態圖像幀上的神經網絡被用來解釋視頻輸入。這種網絡不會學習到視頻的時間動態變化以及在空間運動的物體的平滑變換。所以我們認為這個網絡并不適合用來預測未來視頻中的畫面。
為了克服這個問題,我們團隊創建了一個大型的視頻數據集 eVDS(https://engineering.purdue.edu/elab/eVDS/),可用來直接從視頻數據上訓練新的(遞歸和反饋)網絡模型。
PredNet
PredNet 是被設計來預測視頻中未來幀的網絡。在這個博客中可以看到一些例子,博客鏈接:https://coxlab.github.io/prednet/。
PredNet 是一個非常聰明的神經網絡型,在我們看來,它將在將來的神經網絡中起著重要的作用。PredNet 學習到了超越監督式 CNN 中的單幀圖片的神經表征。
PredNet 結合了生物啟發的雙向 [人腦模型](詳見論文《Unsupervised Pixel-prediction》,https://papers.nips.cc/paper/1083-unsupervised-pixel-prediction.pdf)。它使用了 [預測編碼和神經模型中的反饋連接](詳見論文《Neural Encoding and Decoding with Deep Learning for Dynamic Natural Vision》,http://arxiv.org/abs/1608.03425)。下面是 PredNet 模型以及一個具有兩個堆疊層的例子:
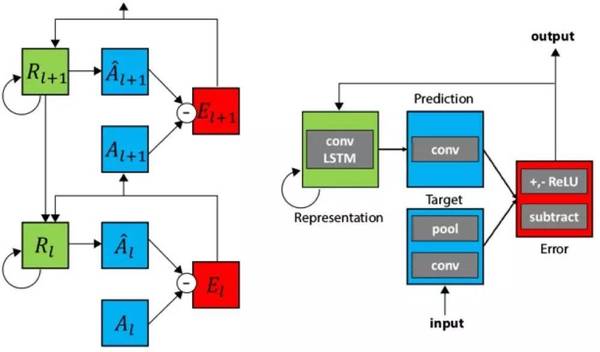
PredNet 結合了生物啟發的雙向人腦模型
這個模型有以下這幾個優點:
可使用無標簽的數據來訓練
在每一層嵌入了損失函數來計算誤差
具有執行在線學習的能力,通過監控錯誤信號,當模型不能預測輸出的時候,它會知道需要學習誤差信號
PredNet 存在的一個問題是,對第一層的一些簡單的基于運動的濾波器而言,預測未來輸入的幀是相對容易的。在我們所做的 PredNet 的實驗中,PredNet 在重建輸入幀的時候學會了在重建輸入幀時達到很好的效果,但是更高層不會學到較好的表征。事實上,在實驗中更高層連簡單的分類任務都解決不了。
事實上,預測未來的幀是不必要的。我們愿意做的就是去預測下一幀的表征,就像 Carl Vondrick 做的一樣。詳見論文《Anticipating Visual Representations from Unlabeled Video》,鏈接:https://arxiv.org/abs/1504.08023。
通過觀察物體的運動來學習特征
最近的這篇論文通過觀察視頻中物體的運動來訓練無監督模型(《Learning Features by Watching Objects Move》,https://people.eecs.berkeley.edu/~pathak/unsupervised_video/)。運動以光流的形式被提取出來,并被用作運動物體的分割模板。盡管光流信號并沒有提供任何一個接近良好的分割模板,但是在大規模數據集上的平均效果使得最終的網絡會表現良好。例子如下所示:
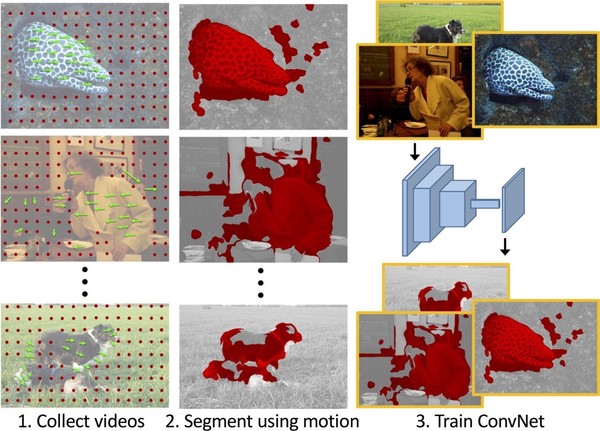
這項工作是非常激動人心的,因為它遵循關于人類視覺皮層如何學習分割運動物體的神經學理論。參見論文《Development of human visual function》,鏈接:http://www.sciencedirect.com/science/article/pii/S004269891100068X。
未來
未來需要你們來創造。
無監督訓練仍然還是一個有待發展的主題,你可以通過以下方式做出較大的貢獻:
創建一個新的無監督任務去訓練網絡,例如:解決拼圖問題、對比圖像補丁、生成圖像等......
想出能夠創造很棒的無監督功能的任務,例如:像我們人類視覺系統的工作方式一樣,理解立體圖像和視頻中什么是物體、什么是背景。
原文鏈接:https://medium.com/intuitionmachine/navigating-the-unsupervised-learning-landscape-951bd5842df9
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4537.html
摘要:的兩位研究者近日融合了兩種非對抗方法的優勢,并提出了一種名為的新方法。的缺陷讓研究者開始探索用非對抗式方案來訓練生成模型,和就是兩種這類方法。不幸的是,目前仍然在圖像生成方面顯著優于這些替代方法。 生成對抗網絡(GAN)在圖像生成方面已經得到了廣泛的應用,目前基本上是 GAN 一家獨大,其它如 VAE 和流模型等在應用上都有一些差距。盡管 wasserstein 距離極大地提升了 GAN 的...
摘要:引用格式王坤峰,茍超,段艷杰,林懿倫,鄭心湖,王飛躍生成對抗網絡的研究與展望自動化學報,論文作者王坤峰,茍超,段艷杰,林懿倫,鄭心湖,王飛躍摘要生成式對抗網絡目前已經成為人工智能學界一個熱門的研究方向。本文概括了的研究進展并進行展望。 3月27日的新智元 2017 年技術峰會上,王飛躍教授作為特邀嘉賓將參加本次峰會的 Panel 環節,就如何看待中國 AI學術界論文數量多,但大師級人物少的現...

閱讀 1999·2023-04-25 16:53
閱讀 1441·2021-10-13 09:39
閱讀 605·2021-09-08 09:35
閱讀 1639·2019-08-30 13:03
閱讀 2120·2019-08-30 11:06
閱讀 1830·2019-08-30 10:59
閱讀 3188·2019-08-29 17:00
閱讀 2287·2019-08-23 17:55



