資訊專欄INFORMATION COLUMN

摘要:李理卷積神經(jīng)網(wǎng)絡(luò)之簡介是一種防止模型過擬合的技術(shù),這項技術(shù)也很簡單,但是很實用。原文鏈接李理三層卷積網(wǎng)絡(luò)和的實現(xiàn)卷積神經(jīng)網(wǎng)絡(luò)的原理已經(jīng)在推薦李理卷積神經(jīng)網(wǎng)絡(luò)之的原理及實現(xiàn)以及李理卷積神經(jīng)網(wǎng)絡(luò)之二文中詳細講過了,這里我們看怎么實現(xiàn)。
《李理:卷積神經(jīng)網(wǎng)絡(luò)之Dropout》
4. Dropout
4.1 Dropout簡介
dropout是一種防止模型過擬合的技術(shù),這項技術(shù)也很簡單,但是很實用。它的基本思想是在訓練的時候隨機的dropout(丟棄)一些神經(jīng)元的激活,這樣可以讓模型更魯棒,因為它不會太依賴某些局部的特征(因為局部特征有可能被丟棄)。
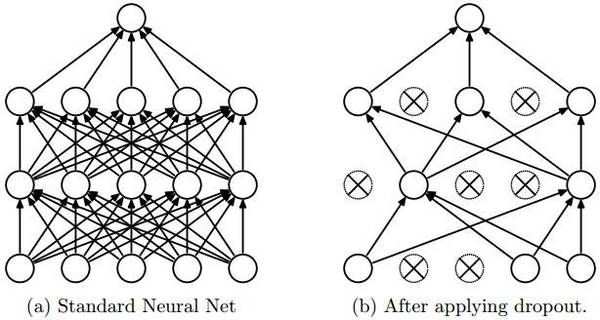
上圖a是標準的一個全連接的神經(jīng)網(wǎng)絡(luò),b是對a應用了dropout的結(jié)果,它會以一定的概率(dropout probability)隨機的丟棄掉一些神經(jīng)元。
4.2 Dropout的實現(xiàn)
實現(xiàn)Dropout最直觀的思路就是按照dropout的定義來計算,比如上面的3層(2個隱藏層)的全連接網(wǎng)絡(luò),我們可以這樣實現(xiàn):
""" 最原始的dropout實現(xiàn),不推薦使用 """p = 0.5 # 保留一個神經(jīng)元的概率,這個值越大,丟棄的概率就越小。def train_step(X):?
? H1 = np.maximum(0, np.dot(W1, X) + b1)
? U1 = np.random.rand(*H1.shape) < p # first dropout mask
? H1 *= U1 # drop!
? H2 = np.maximum(0, np.dot(W2, H1) + b2)
? U2 = np.random.rand(*H2.shape) < p # second dropout mask
? H2 *= U2 # drop!
? out = np.dot(W3, H2) + b3 ?# 反向梯度計算,代碼從略def predict(X):
? H1 = np.maximum(0, np.dot(W1, X) + b1) * p # NOTE: scale the activations
? H2 = np.maximum(0, np.dot(W2, H1) + b2) * p # NOTE: scale the activations
? out = np.dot(W3, H2) + b3
我們看函數(shù) train_step,正常計算第一層的激活H1之后,我們隨機的生成dropout mask數(shù)組U1。它生成一個0-1之間均勻分布的隨機數(shù)組,然后把小于p的變成1,大于p的變成0。極端的情況,p = 0,則所有數(shù)都不小于p,因此U1全是0;p=1,所有數(shù)都小于1,因此U1全是1。因此越大,U1中1越多,也就keep的越多,反之則dropout的越多。?
然后我們用U1乘以H1,這樣U1中等于0的神經(jīng)元的激活就是0,其余的仍然是H1。?
第二層也是一樣的道理。
predict函數(shù)我們需要注意一下。因為我們訓練的時候會隨機的丟棄一些神經(jīng)元,但是預測的時候就沒辦法隨機丟棄了【我個人覺得也不是不能丟棄,但是這會帶來結(jié)果會不穩(wěn)定的問題,也就是給定一個測試數(shù)據(jù),有時候輸出a有時候輸出b,結(jié)果不穩(wěn)定,這是實際系統(tǒng)不能接受的,用戶可能認為你的模型有”bug“】。那么一種”補償“的方案就是每個神經(jīng)元的輸出都乘以一個p,這樣在”總體上“使得測試數(shù)據(jù)和訓練數(shù)據(jù)是大致一樣的。比如一個神經(jīng)元的輸出是x,那么在訓練的時候它有p的概率keep,(1-0)的概率丟棄,那么它輸出的期望是p x+(1-p) 0=px。因此測試的時候把這個神經(jīng)元乘以p可以得到同樣的期望。
原文鏈接:
http://geek.csdn.net/news/detail/161276
《李理:三層卷積網(wǎng)絡(luò)和vgg的實現(xiàn)》
卷積神經(jīng)網(wǎng)絡(luò)的原理已經(jīng)在【推薦】李理:卷積神經(jīng)網(wǎng)絡(luò)之Batch Normalization的原理及實現(xiàn)以及《李理:卷積神經(jīng)網(wǎng)絡(luò)之Dropout》二文中詳細講過了,這里我們看怎么實現(xiàn)。
5.1 cell1-2
打開ConvolutionalNetworks.ipynb,運行cell1和2
5.2 cell3 實現(xiàn)最原始的卷積層的forward部分
打開layers.py,實現(xiàn)conv_forward_naive里的缺失代碼:
N, C, H, W = x.shape
? F, _, HH, WW = w.shape
? stride = conv_param["stride"]
? pad = conv_param["pad"]
? H_out = 1 + (H + 2 * pad - HH) / stride
? W_out = 1 + (W + 2 * pad - WW) / stride ?out = np.zeros((N,F,H_out,W_out))
? # Pad the input
? x_pad = np.zeros((N,C,H+2*pad,W+2*pad))
? for n in range(N):
? ? ? for c in range(C):
? ? ? x_pad[n,c] = np.pad(x[n,c],(pad,pad),"constant", constant_values=(0,0))
? for n in range(N):
? ? ? for i in range(H_out):
? ? ? ? ? for j in range(W_out):
? ? ? ? ? current_x_matrix = x_pad[n, :, i * stride: i * stride + HH, j * stride:j * stride + WW]
? ? ? ? ? ? ?for f in range(F):
? ? ? ? ? ? ? ? ?current_filter = w[f]
? ? ? ? ? ? ? ? ?out[n,f,i,j] = np.sum(current_x_matrix*current_filter)?
? ? ? ? ? ? ?out[n,:,i,j] = out[n,:,i,j]+b
我們來逐行來閱讀上面的代碼
5.2.1 第1行
首先輸入x的shape是(N, C, H, W),N是batchSize,C是輸入的channel數(shù),H和W是輸入的Height和Width
5.2.2 第2行
參數(shù)w的shape是(F, C, HH, WW),F(xiàn)是Filter的個數(shù),HH是Filter的Height,WW是Filter的Width
5.2.3 第3-4行
從conv_param里讀取stride和pad
5.2.4 第5-6行
計算輸出的H_out和W_out
5.2.5 第7行
定義輸出的變量out,它的shape是(N, F, H_out, W_out)
5.2.6 第8-11行
對x進行padding,所謂的padding,就是在一個矩陣的四角補充0。
首先我們來熟悉一下numpy.pad這個函數(shù)。
In [19]: x=np.array([[1,2],[3,4],[5,6]])
In [20]: x
Out[20]:?
array([[1, 2],
? ? ? ?[3, 4],
? ? ? ?[5, 6]])
首先我們定義一個3*2的矩陣
然后給它左上和右下都padding1個0。
In [21]: y=np.pad(x,(1,1),"constant", constant_values=(0,0))
In [22]: y
Out[22]:?
array([[0, 0, 0, 0],
? ? ? ?[0, 1, 2, 0],
? ? ? ?[0, 3, 4, 0],
? ? ? ?[0, 5, 6, 0],
? ? ? ?[0, 0, 0, 0]])
我們看到3*2的矩陣的上下左右都補了一個0。
我們也可以只給左上補0:
In [23]: y=np.pad(x,(1,0),"constant", constant_values=(0,0))
In [24]: y
Out[24]:?
array([[0, 0, 0],
? ? ? ?[0, 1, 2],
? ? ? ?[0, 3, 4],
? ? ? ?[0, 5, 6]])
了解了pad函數(shù)之后,上面的代碼就很容易閱讀了。對于每一個樣本,對于每一個channel,這都是一個二位的數(shù)組,我們根據(jù)參數(shù)pad對它進行padding。
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/4475.html
摘要:顯示了殘差連接可以加速深層網(wǎng)絡(luò)的收斂速度,考察了殘差網(wǎng)絡(luò)中激活函數(shù)的位置順序,顯示了恒等映射在殘差網(wǎng)絡(luò)中的重要性,并且利用新的架構(gòu)可以訓練極深層的網(wǎng)絡(luò)。包含恒等映射的殘差有助于訓練極深層網(wǎng)絡(luò),但同時也是殘差網(wǎng)絡(luò)的一個缺點。 WRN Wide Residual NetworksSergey Zagoruyko, Nikos Komodakis Caffe實現(xiàn):https://github...
摘要:在本文中,快捷連接是為了實現(xiàn)恒等映射,它的輸出與一組堆疊層的輸出相加見圖。實驗表明見圖,學習得到的殘差函數(shù)通常都是很小的響應值,表明將恒等映射作為先決條件是合理的。 ResNet Deep Residual Learning for Image RecognitionKaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun Caffe實現(xiàn):ht...
摘要:年,發(fā)表,至今,深度學習已經(jīng)發(fā)展了十幾年了。年的結(jié)構(gòu)圖圖片來自于論文基于圖像識別的深度卷積神經(jīng)網(wǎng)絡(luò)這篇文章被稱為深度學習的開山之作。還首次提出了使用降層和數(shù)據(jù)增強來解決過度匹配的問題,對于誤差率的降低至關(guān)重要。 1998年,Yann LeCun 發(fā)表Gradient-Based Learning Applied to Document Recognition,至今,深度學習已經(jīng)發(fā)展了十幾年了...

閱讀 2288·2023-04-25 14:22
閱讀 3733·2021-11-15 18:12
閱讀 1293·2019-08-30 15:44
閱讀 3215·2019-08-29 15:37
閱讀 638·2019-08-29 13:49
閱讀 3454·2019-08-26 12:11
閱讀 866·2019-08-23 18:28
閱讀 1581·2019-08-23 14:55




