資訊專欄INFORMATION COLUMN

摘要:陳云霽陳天石課題組在國際上提出了較早的深度學(xué)習(xí)處理器架構(gòu)寒武紀。而則是寒武紀的指令集。模擬實驗表明,采用指令集的深度學(xué)習(xí)處理器相對于指令集的有兩個數(shù)量級的性能提升。
背景:
中科院計算所提出國際上較早的深度學(xué)習(xí)指令集DianNaoYu
2016年3月,中國科學(xué)院計算技術(shù)研究所陳云霽、陳天石課題組提出的深度學(xué)習(xí)處理器指令集DianNaoYu被計算機體系結(jié)構(gòu)領(lǐng)域較高級國際會議ISCA2016(International Symposium on Computer Architecture)所接收,其評分排名所有近300篇投稿的第一名。論文第一作者為劉少禮博士。
深度學(xué)習(xí)是一類借鑒生物的多層神經(jīng)網(wǎng)絡(luò)處理模式所發(fā)展起來的智能處理技術(shù)。這類技術(shù)已被微軟、谷歌、臉書、阿里、訊飛、百度等公司廣泛應(yīng)用于計算機視覺、語音識別、自然語言處理、音頻識別與生物信息學(xué)等領(lǐng)域并取得了極好的效果。基于深度學(xué)習(xí)的圍棋程序AlphaGo甚至已經(jīng)達到了職業(yè)棋手的水平。因此,深度學(xué)習(xí)被公認為目前最重要的智能處理技術(shù)。
但是深度學(xué)習(xí)的基本操作是神經(jīng)元和突觸的處理,而傳統(tǒng)的處理器指令集(包括x86和ARM等)是為了進行通用計算發(fā)展起來的,其基本操作為算術(shù)操作(加減乘除)和邏輯操作(與或非),往往需要數(shù)百甚至上千條指令才能完成一個神經(jīng)元的處理,深度學(xué)習(xí)的處理效率不高。因此谷歌甚至需要使用上萬個x86 CPU核運行7天來訓(xùn)練一個識別貓臉的深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)。
陳云霽、陳天石課題組在國際上提出了較早的深度學(xué)習(xí)處理器架構(gòu)寒武紀。而DianNaoYu則是寒武紀的指令集。DianNaoYu指令直接面對大規(guī)模神經(jīng)元和突觸的處理,一條指令即可完成一組神經(jīng)元的處理,并對神經(jīng)元和突觸數(shù)據(jù)在芯片上的傳輸提供了一系列專門的支持。模擬實驗表明,采用DianNaoYu指令集的深度學(xué)習(xí)處理器相對于x86指令集的CPU有兩個數(shù)量級的性能提升。
指令集是計算機軟硬件生態(tài)體系的核心。Intel和ARM正是通過其指令集控制了PC和嵌入式生態(tài)體系。寒武紀在深度學(xué)習(xí)處理器指令集上的開創(chuàng)性進展,為我國占據(jù)智能產(chǎn)業(yè)生態(tài)的領(lǐng)導(dǎo)性地位提供了技術(shù)支撐。
兩篇論文
楊軍 從事大規(guī)模機器學(xué)習(xí)系統(tǒng)研發(fā)及應(yīng)用相關(guān)工作
(更新歷史:10.5號更新,加入了DianNao部分的內(nèi)容;10.4號更新,加入了DaDianNao部分的內(nèi)容;10.2號更新,加入了ShiDianNao部分的內(nèi)容;)
最近正好在比較系統(tǒng)地關(guān)注AI硬件加速的東東。
前幾天比較細致的讀了一下ISCA16上關(guān)于寒武紀指令集的文章,在這里(寒武紀神經(jīng)網(wǎng)絡(luò)處理器效能如何 ? - 楊軍的回答)有一個當時寫的paper reading notes。
這兩天花了一些時間,又把發(fā)在ASPLOS 15、ISCA 15、Micro 14以及ASPLOS 14上的PuDianNao/ShiDianNao/DaDianNao/DianNao這四篇文章也讀了一下,整理了一份reading notes,分享出來供參考。在我看來,系統(tǒng)性地把DianNao項目的相關(guān)重點論文一起梳理一遍,對于透過陳氏兄弟的工作來把握AI硬件加速器這個技術(shù)trend會更有助益。
1. PuDianNao
[1]是陳氏兄弟發(fā)起的Diannao項目[2]中的最后一篇論文,文章對七種常見的機器學(xué)習(xí)算法的計算操作類型和訪存模式進行了總結(jié)。包括:?
kNN/k-Means/DNN/Linear Regression/Support Vector Machine/Naive Bayes/Classification Tree。?
基于對這七種算法的分析,提出了一種能夠同時支持七種算法的硬件加速器的設(shè)計方案。?
發(fā)在ASPLOS這種國際頂會上的文章,寫作風(fēng)格通常也非常干凈清晰,結(jié)構(gòu)明了,這篇文章也秉持了這個傳統(tǒng),即使是非體系結(jié)構(gòu)出身的人,讀起來也會感覺很清爽。?
文章先是對七種機器學(xué)習(xí)算法的計算及訪存范式進行了分析,這也是后續(xù)的硬件加速器的基礎(chǔ),套用工業(yè)界的說法,這屬于我們的“業(yè)務(wù)問題”,只有先對業(yè)務(wù)問題認識清楚了,才能給出好的解決方案。?
以kNN算法[3]為例,這個算法的核心思想比較直觀,并不需要顯式的訓(xùn)練環(huán)節(jié),而是直接根據(jù)已經(jīng)獲取到的有標簽的reference sample,對于待預(yù)測樣本,通過給定的distance function,找到距離待預(yù)測樣本最近的k個reference sample,然后再根據(jù)這k個reference sample的標簽決議出待預(yù)測樣本的標簽,核心的代碼邏輯如下:?

主要的計算開銷花在了distance function的計算上(具體distance function根據(jù)業(yè)務(wù)、數(shù)據(jù)的特點來進行design,常用的比如cosine similarity[4]/Euclidean distance[5]/Hamming distance[6])。?
如果我們把計算開銷拆解得再細致一些,會發(fā)現(xiàn),計算開銷由純計算時間+訪存時間構(gòu)成。純計算時間的優(yōu)化,可以通過定制硬件資源來獲取到,而訪存時間的優(yōu)化則需要結(jié)合具體的訪存模式來展開。?
在計算機體系結(jié)構(gòu)領(lǐng)域,常用的提升訪存性能的方案是緩存機制的引入,這在Pattern 04年的talk[7]里,也將其列為解決計算機系統(tǒng)里bandwidth與latency的gap的1st solution。?
我個人比較直觀的印象是,在讀master的時候,自己做過一段時間硬件模擬器的開發(fā)工作,當時的工作現(xiàn)在看起來并不復(fù)雜,參考VMIPS[8]實現(xiàn)了一個基于龍芯1號的SoC模擬器,當時的實際觀測里,運行非常簡單的benchmark(因為是裸芯片,所以為了簡單,這個benchmark就是一個類似于簡易BIOS的bootloader + 硬件測試邏輯的組合),能夠觀察到cache生效與否對性能帶來幾十倍以上的影響。?
回到我們討論的這篇文章,訪存性能的提升,往往對于最終系統(tǒng)的性能會帶來顯著的影響。在文章里也基于一個cache仿真器,對七類機器學(xué)習(xí)算法的訪存行為進行了仿真評估,并發(fā)現(xiàn)kNN算法的原始實現(xiàn)會引入大量的訪存行為,這個訪存行為的頻繁度會隨著reference sample集合的增加而增加(原因很簡單,cache無法裝下所有 的reference sample,所以,即便這些reference sample會不斷地被重復(fù)訪問,也無法充分挖掘data locality所帶來的cache收益)。針對這種應(yīng)用類型,實際上存在成熟的優(yōu)化范式——Loop tiling[9]。?
Loop tiling的基本思想是,對于循環(huán)邏輯,通過將大塊的循環(huán)迭代拆解成若干個較小的循環(huán)迭代塊,減少一個內(nèi)存元素的re-use distance,換句話說,也就是確保當這個內(nèi)存元素被加載到cache以后,盡可能保留在cache中,直到被再次訪問,這樣就達到了減少了昂貴的片外訪存的開銷的目的。對體系結(jié)構(gòu)不太熟悉的同學(xué),可能未必能一下子感知到這樣做的意義,參考[10][11][12][16][17]里的一些number,能夠更為量化地感知到數(shù)據(jù)訪問落在不同的存儲部件上(CPU寄存器/Cache/內(nèi)存/磁盤外存/網(wǎng)絡(luò))的差異,也許就可以更為深刻地理解到loop tiling這個看起來不起眼的優(yōu)化技巧對性能帶來的潛在提升。?

針對kNN算法,使用loop tiling優(yōu)化后的代碼邏輯會長成這樣:?

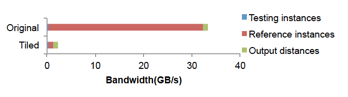
優(yōu)化后相較于優(yōu)化之前的實現(xiàn),片外訪存帶寬減少了 90%:
針對kNN算法的分析套路,也可以套用在剩下的6種算法上,每種算法的most time-consuming的主要計算邏輯類型不同(kNN/k-Means對應(yīng)的是distance function的計算,DNN/Linear Regression對應(yīng)的則是向量點積和矩陣乘法計算, Naive Bayes對應(yīng)的是計數(shù)),為了充分挖掘data locality的優(yōu)化技巧細節(jié)也有所差異,但基本上都是loop tiling的應(yīng)用。?
比如k-Means里,聚類中心點會被反復(fù)訪問,其data locality就是需要著力優(yōu)化的地方;DNN里,兩層layer之間的線性變換操作中,weight和上層layer不具備data locality,不需要進行優(yōu)化,而下層layer的神經(jīng)元會被訪問多次,就需要充分挖掘其data locality,這里就不再詳述,可以直接參考原始論文。?
在這7個算法中,基于loop tiling優(yōu)化技巧,kNN/k-Means/Linear Regression/DNN/SVM具有較好的data locality挖掘空間,而Naive Bayes/Classification Tree的data locality挖掘空間則較小。這從下圖可以表現(xiàn)得更為形象:?
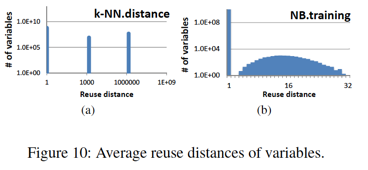
對跑在加速器上的這7類算法任務(wù)的認識,對于加速器的結(jié)構(gòu)設(shè)計有著重要的影響。?
比如,在kNN為代表的5算法都表現(xiàn)出相似的data locality,帶來的一個直觀啟示就是對于reuse distance > 1的兩大類變量,分別提供兩種不同尺寸的cache,來配合loop tiling充分挖掘data locality。?
另外,對于不同算法里耗時最多的計算任務(wù)的理解,對于具體的硬件執(zhí)行流水線的設(shè)計也有著重要的啟示。?
下面我們可以來看一下PuDianNao的結(jié)構(gòu)設(shè)計圖:?
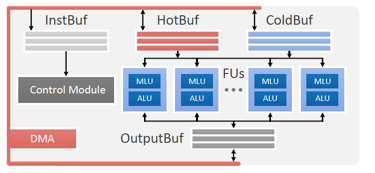
PuDiannao的結(jié)構(gòu)主要由若干個Function Unit(每個FU的功能是相同的),三個數(shù)據(jù)緩存(Hot Buffer, Cold Buffer, Output Buffer),一個指令緩存(Inst Buffer),一個控制模塊(Control Module),以及DMA控制器組成。?
Function Unit是PuDiannao的基本執(zhí)行單元,每個FU又由兩個部件構(gòu)成,分別是用于機器學(xué)習(xí)算法硬件定制支持的Machine Learning Unit,以及用于常規(guī)計算控制任務(wù)的Arithmetic Logic Unit。?
作為提供機器學(xué)習(xí)硬件加速支持的MLU,其內(nèi)部由Counter、Adder、Multiplier、Adder Tree、Acc、Misc 6級流水線組成。MLU的流水線微結(jié)構(gòu)圖如下:?
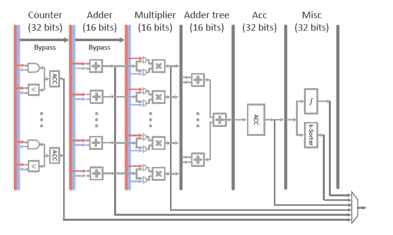
關(guān)于流水線的設(shè)計,值得一提的是Multiplier + Adder Tree提供了dot product的支持,這也是LR/SVM/DNN里的高頻操作。當樣本維度高于流水線運算部件的計算寬度時,可以通過Acc stage對Multiplier + Adder Tree輸出的partial sum結(jié)果進行累積,來給以支持。Misc stage提供了對非線性函數(shù)(比如sigmoid/tanh函數(shù))的線性插值近似和top-k/tail-k功能(在kNN和k-Means里會用到)的硬件支持。?
為了減少芯片面積及功耗,在Adder/Multipler/Adder tree這三個stage里支持的是16位的浮點計算,而對于Counter/Acc/Misc這三個stage則仍然使用32位浮點數(shù),這種設(shè)計也是考慮到Counter/Acc/Misc離最終計算結(jié)果比較近,overflow的風(fēng)險較高,而Adder/Multiplier/Adder tree對應(yīng)于中間計算結(jié)果,overflow風(fēng)險較低,所以會做出這種設(shè)計trade-off。?
在文章里,也對于這種16-bit的trade-off所可能帶來的算法精度下降進行了量化評估:?
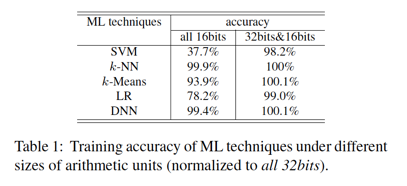
基準線是所有pipeline stage都采用32-bit浮點數(shù)的精度,能夠看到,32bi&16bit的混合設(shè)計,對于模型精度影響并不大。?
相較于MLU,ALU的設(shè)計則比較簡單,主要實現(xiàn)了MLU里未支持,也即是在機器學(xué)習(xí)算法中非高頻操作的邏輯。比如除法、條件賦值等。這樣設(shè)計的考慮是希望PuDiannao能夠盡可能自治地支持起機器學(xué)習(xí)算法運行所需的基礎(chǔ)部件支持,因為PuDiannao本質(zhì)上還是一個加速器,所以會作為協(xié)處理器[15]嵌入到宿主系統(tǒng)里,協(xié)同支持完整計算任務(wù)的執(zhí)行。如果對于機器學(xué)習(xí)算法中非典型高頻操作不提供支持,那么這些操作就需要回落到宿主cpu上,這會增加宿主系統(tǒng)與PuDiannao的協(xié)同開銷,對加速效果也會帶來影響。?
關(guān)于存儲部件的設(shè)計,在上面已經(jīng)提了引入多種data buffer的設(shè)計動機(支持計算任務(wù)里不同的reuse distance),需要再補充一下的是,為了減少芯片面積和功耗,hot buffer/code buffer使用的是單端口的SRAM,而output buffer則因為其支持的操作類型(同時讀寫),使用了雙端口的SRAM。?
在[13]里,可以了解到,相較于單端口RAM,雙端口RAM無論是在基本存儲單元cell的面積上,還是控制邏輯上,都引入了額外的代價,這也是這里做這個設(shè)計trade-off的考量。另外,為了提升主存到PuDiannao的數(shù)據(jù)交換性能,對于inst buffer和data buffer都采取了DMA與宿主系統(tǒng)進行交互。?
PuDiannao的Control Module扮演的是指令譯碼器和dispatcher的功能。PuDiannao里,計算任務(wù)的描述,通過control instruction來描述,而control module就是對control instruction進行譯碼,然后把需要執(zhí)行的操作指令發(fā)送給所有 的FU上。PuDiannao的指令抽象度比較低,所以使用control instruction編程需要對PuDiannao的架構(gòu)實現(xiàn)細節(jié)非常了解,看一下control instruction的格式會有助于建立這個認識:?

以及基于control instruction所編寫的k-Means的code snippet:?
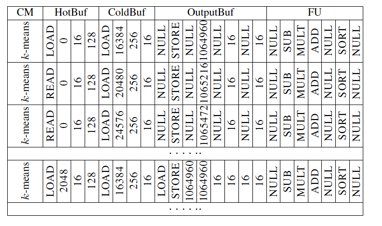
最后基于PuDianNao的評估集中在性能加速比以及功耗這兩個方面。分別基于verilog和C仿真器完成了評估環(huán)境的搭建。verilog評估環(huán)境(65nm工藝)的精度更高,但速度慢,C仿真器的速度快,但評估精度會有一定的損失。?
評估使用的數(shù)據(jù)集描述如下:?
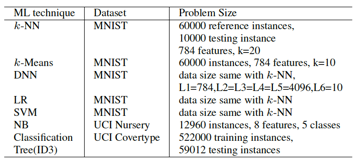
評估的baseline是GPU(NVIDIA K20M, 3.2TFlops peak,5GB顯存,208GB/s顯存帶寬,28nm工藝, CUDA SDK5.5)。?
性能評估的策略是將7個算法的不同phase拆分開來與baseline進行評估對比:?
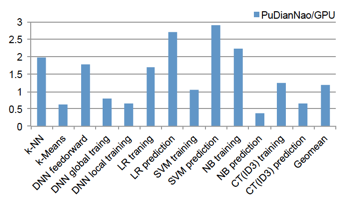
在上面的評估結(jié)果中,能夠看到,有某些phase里,GPU baseline的表現(xiàn)要比PuDianNao要好,比如Naive Bayes的prediction phase,這跟Naive Bayes的prediction的計算類型涉及到大量的乘法計算有關(guān),PuDianNao并沒有配置大規(guī)模的寄存器堆,所以需要在on-chip的data buffer和FU之間頻繁地進行數(shù)據(jù)交互,而K20M則有64K個寄存器可供給計算,所以不會存在這個問題,于是造成了這種performance差異(說到這里,我有些好奇的是在[14]里,對于這個問題是怎樣解決的。因為在[14]里,我并沒有看到在regisger上面的額外設(shè)計資源投入,仍是通過data buffer來完成計算任務(wù)所需的數(shù)據(jù)存儲,看起來似乎應(yīng)該存在跟PuDianNao相同的問題。但是在[14]里,工藝與PuDianNao相同,都是65nm,相較于相同的GPU baseline,averagely卻獲得了3X的性能提升,這是一個讓我暫時未解的疑問)。性能提升最明顯的SVM prediction則主要是FU里提供了kernel函數(shù)的插值邏輯硬件實現(xiàn)帶來的。?
如果說PuDianNao帶來的性能提升相較于GPU并不顯著的話(in average 1.2X),那么在計算能耗比上的提升,就相當顯著了:?
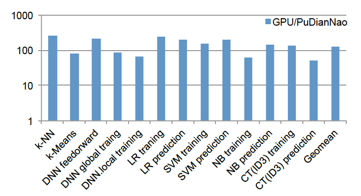
最后可以看一下PuDianNao的layout信息:?

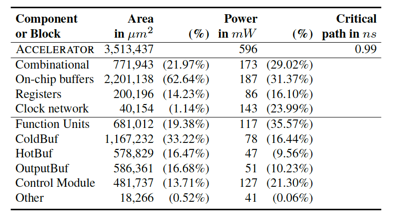
能夠看到,F(xiàn)U(Functional Unit)和CB(Cold Buffer)是面積大戶,CM(Control Module)的面積不大,但是功耗并不小。?
正好前不久剛剛精讀了Cambricon指令集的論文[14],把兩篇論文聯(lián)系在一起來看,還是隱約能夠感知到一些脈絡(luò)。PuDianNao里給出的流水線設(shè)計,更像是一個特殊的定制硬件邏輯,ad-hoc的味道更濃,而[14]里給出的流水線設(shè)計則比較接近于一個中規(guī)中矩的處理器的設(shè)計了。[14]里也能夠看到更明顯的抽象的味道,把Add/Multplication這些操作都集中在了Vector/Matrix Func Unit里,不像PuDianNao這樣,會在不同的流水線stage里,分別提供了看起來有些相近的實現(xiàn)(Add邏輯在多個pipeline stage里出現(xiàn))。在片上存儲體系的設(shè)計里,[14]也更為general,通過更為精巧的crossbar scratchpad memory來統(tǒng)一提供片上訪存支持。最重要的是,PuDianNao只提供了針對7種算法的操作碼,而[14]則在指令集的層次為更豐富的應(yīng)用類型提供了支持。?
接下來計劃再去讀一下DianNao系列的其他幾篇文章,以作相互映照。?
在閱讀PuDianNao的時候,還是發(fā)現(xiàn)對于[14]的理解,有些地方并不如之前所以為的那樣深入,因為在PuDianNao里看到的一些問題(比如Naive Bayes prediction的問題),似乎并沒有理解清楚在[14]里是如何針對性解決的,也許隨著對整個系列論文的深入閱讀 ,能夠形成一個更為完整系統(tǒng)化的認識吧。?
References:?
[1]. Daofu Liu. PuDianNao: A Polyvalent Machine Learning Accelerator. ASPLOS, 2015.?
[2]. A Brief Introduction to The Dianao Project. http://novel.ict.ac.cn/diannao/
[3]. k-nearest neighbors algorithm. k-nearest neighbors algorithm
[4]. cosine similarity. Cosine similarity
[5]. Euclidean distance. Euclidean distance
[6]. Hamming distance. Hamming distance
[7]. David Patterson. Why Latency Lags Bandwidth and What It Means to Computing. https://www.ll.mit.edu/HPEC/agendas/proc04/invited/patterson_keynote.pdf
[8]. VMIPS. The vmips Project
[9]. Loop tiling. Loop tiling
[10]. Approximate cost to access various caches and main memory. latency - Approximate cost to access various caches and main memory?
[11]. CPU Cache Flushing Fallacy. http://mechanical-sympathy.blogspot.com/2013/02/cpu-cache-flushing-fallacy.html
[12]. Answers from Peter Norvig. Teach Yourself Programming in Ten Years
[13]. What is dual-port RAM. Dual port memory, dual ported memory, Ports, sdram, sram, sdram, memories
[14]. Shaoli Liu. Cambricon: An Instruction Set Architecture for Neural Networks", in Proceedings of the 43rd ACM/IEEE International Symposium on Computer Architecture. ISCA, 2016.?
[15]. Coprocessor. Coprocessor
[16]. Visualization of Latency Numbers Every Programmer Should Know. Numbers Every Programmer Should Know By Year
[17]. Latency Numbers Every Programmer Should Know. https://gist.github.com/jboner/2841832
2. ShiDianNao
這[1]是陳氏兄弟DianNao項目[2]的第三篇論文,發(fā)在了ISCA 2015上。?
之前閱讀了這個系列里的Cambricon[4]和PuDianNao[3]這兩篇論文,感覺ShiDianNao這篇論文在立意的創(chuàng)新性上比起[3][4]略遜了一籌,更像是一個針對具體應(yīng)用場景的一個偏工程層面的體系結(jié)構(gòu)設(shè)計&優(yōu)化工作,但是在加速器的設(shè)計細節(jié)上卻是touch得更為詳細的,無論是訪存體系的設(shè)計,還是計算單元的設(shè)計,介紹得都非常的細致,看完這個設(shè)計,說對一個比較naive的GPGPU這樣的硬件加速器建立起一定的sense并不為過。?
文章的核心思想是利用CNN網(wǎng)絡(luò)weight sharing的特性,將CNN模型整體加載入SRAM構(gòu)成的高速存儲里,減少了訪問DRAM帶來的內(nèi)存開銷。同時,將加速器直接與視頻圖像傳感器相連接,傳感器采集到的圖像數(shù)據(jù)直接作為加速器的輸入進行處理,減少了額外的訪存操作(傳統(tǒng)模式下,會先將傳感器采集到的數(shù)據(jù)放入DRAM,再知會加速器進行處理,于是會有至少兩次的額外DRAM訪問操作)。?
Overall的思想聽起來很直觀,但真正操作起來,有著大量的設(shè)計細節(jié)需要去考量,列舉幾個文章中提到的挑戰(zhàn)以及我在文章閱讀過程中想到的挑戰(zhàn):?
1.與傳感器直連的加速器芯片中的SRAM尺寸取多大比較合適?太大了,功耗、面積就上去了。太小了,對性能會帶來明顯的影響(想象一下如果模型不能全部hold到加速器的SRAM里,對計算過程帶來的影響)。所以這很考究架構(gòu)師對目標問題以及技術(shù)實現(xiàn)方案細節(jié)的把控和理解。?
2.對于會跑在這款加速器上的CNN模型,采取什么樣的方式來映射到硬件計算資源?比較natural且高效的方式是,每個神經(jīng)元都要對應(yīng)于一個硬件計算單位,但這樣很容易因為模型尺寸超出硬件物理計算單元個數(shù)而限制加速器所能支持的應(yīng)用類型。而如果不強求一個神經(jīng)元對應(yīng)一個硬件計算單位,采用時分復(fù)用的方法,也還有小的設(shè)計權(quán)衡要考慮,以卷積層為例,在計算一個特定的feature map的output neuron的時候,在同一個時刻是只為一個output neuron進行計算,還是同時為多個output neuron進行計算,這在硬件復(fù)雜性/面積/靈活性上都會有不同的影響。?
3.跑在加速器芯片上的應(yīng)用任務(wù),存在一定的data locality,對這種data locality是否需要進行挖掘,以榨取更多的性能加速的空間?比如,在計算卷積層feature map的時候,卷積輸入層的input neuron實際上是會被多個output neuron使用到的,這些input neuron是每次為某個output neuron計算的時候,都去從SRAM中訪問獲取,還是在計算單元中,引入一些local storage,進行計算單元之間的內(nèi)部通信。雖然說SRAM已經(jīng)比DRAM的性能要好了一個數(shù)量級[7],但是計算單元之間的直連通信能夠帶來更多的性能收益。當然,這樣做的代價是硬件設(shè)計的復(fù)雜性。?
硬件開發(fā)工作不像軟件開發(fā),一次性成本非常高,所以在設(shè)計環(huán)節(jié)往往需要食不厭精,反復(fù)雕琢。也只有這樣做,當芯片大規(guī)模量產(chǎn)以后,ROI優(yōu)勢才能突顯出來。?
ShiDianNao的工作,最出彩的,就是針對上面提到的具體問題場景,給出了比較精巧的硬件設(shè)計方案。?
首先來看一下ShiDianNao的頂層結(jié)構(gòu):?
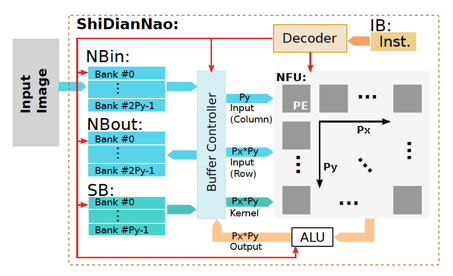
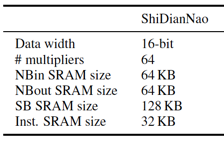
在這個設(shè)計方案里,左側(cè)是SRAM堆起來的數(shù)據(jù)存儲(共計288KB,見下圖片上SRAM的具體功用分配),?
根據(jù)CNN計算任務(wù)的特點(一組input neurons通過一層數(shù)學(xué)計算,生成一組output neurons),設(shè)計了三類SRAM存儲:?
NBin:存取input neurons。?
NBout:存放輸出output neurons。?
SB:存放完整的模型參數(shù)。?
在這三類存儲中,SB要求能夠hold住模型的全部參數(shù),而NBin/NBout要求能夠hold住神經(jīng)網(wǎng)絡(luò)一個layer的完整input/output neurons。原因是因為,模型參數(shù)會被反復(fù)使用,所以需要放在SRAM里以減少從DRAM里加載模型參數(shù)的時間開銷,而作為CNN模型輸入數(shù)據(jù)的一張?zhí)囟ǖ膱D片/視頻幀的raw data被模型處理完畢后不會被反復(fù)使用,所以只需要確保每個神經(jīng)層計算過程中所需的input/output neurons都hold在SRAM里,就足以滿足性能要求。?
右側(cè)則是一個NFU(Neural Functional Unit),這是一個由若干個PE組成的計算陣列。每個PE內(nèi)部由一個乘法器、一個加法器、若干個寄存器、兩組用于在PE陣列水平/垂直方向進行數(shù)據(jù)交互的FIFO以及一些輔助的控制邏輯組成:?
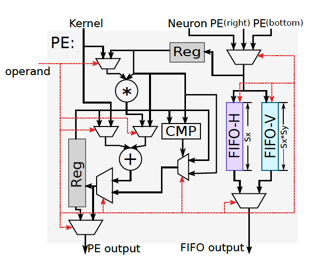
NFU的計算結(jié)果會輸出到一個ALU,通過ALU最終寫入到NBOut里。ALU里實現(xiàn)了一些并行度要求不那么高的運算支持,比如average pooling會用到的除法操作,以及非線性激活函數(shù)的硬件實現(xiàn)等。其中非線性激活函數(shù)的實現(xiàn),使用了分段函數(shù)進行插值近似[8],以求在精度損失較小的情況下,獲取功耗和性能的收益。?
在ShiDianNao里,所有的數(shù)值計算均使用的是16位定點計算[6],而沒有使用32位的浮點計算。這種策略在其他硬件加速器的設(shè)計[5]里也有過成功的應(yīng)用。?
NFU的PE陣列設(shè)計里,值得一提的是對Inter-PE data propagation的支持。引入這層支持的考慮是減少NFU與SRAM的數(shù)據(jù)通訊量。我們回顧一下卷積層Feature Map的計算細節(jié),會注意到同一個feature map里不同的output neuron,在stride沒有超過kernel size的前提下,其輸入數(shù)據(jù)存在一定的overlap,這實際上就是Inter-PE data propagation的引入動機,通過將不同的output neuron之間overlap的那部分input neuron直接在PE之間進行傳播,從而減少訪問SRAM的頻次,可以在性能和功耗上都獲得一定的收益。這個收益,會隨著卷積核尺寸的增加而變得更加明顯。?
以32x32 input feature map + 5x5 卷積核為例,通過下圖,可以看到,隨著PE個數(shù)的增加,對SRAM帶寬需求的增加,以及Inter-PE data propagation優(yōu)化的效果:?

ShiDianNao另一個重要的部件是Buffer Controller,這是用于在片上存儲NBin/NBout/SB與計算部件NFU之間協(xié)調(diào)數(shù)據(jù)交互的co-ordinator。Buffer Controller負責完成兩個功能:以流式的方式,layer-wise的為NFU提供計算所需數(shù)據(jù)的供給,以及緩沖NFU計算的partial輸出結(jié)果,匯總完一個完整layer/feature map上所有的output neuron之后才寫回到NBout。這里比較關(guān)鍵的細節(jié)是,為了能夠高效地支持CNN模型中的不同操作對應(yīng)的訪存特點,在Buffer Controller里提供了對多種read mode的支持:?
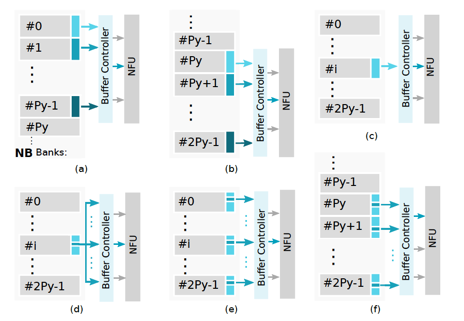
稍微選幾個典型的讀取模式進行介紹。在上面這個圖里,(a)/(b)/(e)模式主要用于為卷積層提供數(shù)據(jù)讀取,讀取的每個input neuron會對應(yīng)于一個output neuron(注意:在ShiDianNao里,這些已經(jīng)通過Buffer Controller讀取到PE中作為輸入的input neuron接下來會通過Inter-PE data propagation的機制進行傳遞,從而節(jié)省了SRAM的訪問帶寬),其中(e)對應(yīng)于卷積核step size > 1的情形。(d)對應(yīng)于全連接層,讀取一個input neuron,會用作多個output neuron的輸入。?
至此,ShiDianNao的設(shè)計思想的核心基本介紹完了,一些更為detail的細節(jié),在論文里描述得很細致,比如,NFU里支持CNN/Pooling/Normalization/DNN layer的細節(jié)、為了節(jié)省指令cache對控制指令進行了一層抽象。我認為已經(jīng)不再影響把握論文的核心設(shè)計思想,所以這里就不再詳述了。?
最后還是評估環(huán)節(jié),評估環(huán)境的搭建使用的是Synopsys提供的EDA工具,65nm(跟[1][3]相同)。Baseline則選取了CPU(Intel Xeon E7-8830/2.13GHZ/1TB Memory/gcc 4.4.7/MMX/SSE/SSE2/SSE4/SSE4.2)、GPU(NVIDIA K20M/5GB顯存/3.52TFlops/28nm/Caffe)以及DianNiao項目的第一個工作成果[9]。?
評估的Benchmark使用了下表中所列出的10類較小規(guī)模的CNN模型(受限于片上SRAM的尺寸,在ShiDianNao里不能支持太大的CNN model,比如AlexNet。在這10個Benchmark model里,layer wise的神經(jīng)元最多消耗45KB SRAM存儲,而模型的權(quán)重最多只消耗118KB SRAM,足以被ShiDianNao目前配備的288KB SRAM所支持):?
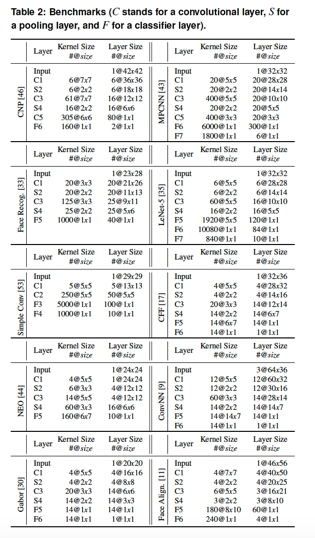
評估所用的ShiDianNao,其NFU由8*8共計64個PE組成,也即在一個cycle里。同時支持64組乘/加組合運算,存儲上,由64KB NBin、64KB NBout、128KB SB和32KB的指令buffer組成。?
評估指標還是集中在計算性能以及功耗兩個方面:?
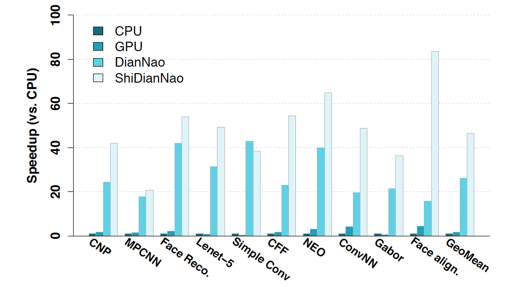
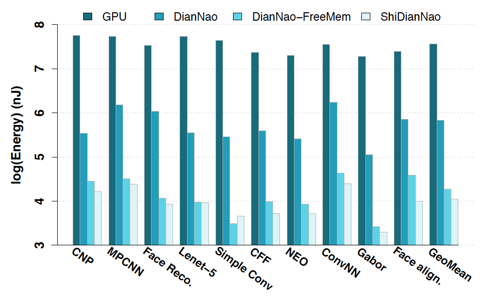
能夠看到,ShiDianNao在性能上相較于CPU/GPU的baseline都有顯著的speed up(46.38X than CPU,28.94X than GPU),相較于[9]里提出的加速器,也有1.87X的加速,這主要是因為ShiDianNao將模型全部hold在片上的SRAM里以及為了進一步減少SRAM訪存開銷設(shè)計的Inter-PE data propagation機制。?
在功耗上,ShiDianNao的優(yōu)勢則更為明顯,具體數(shù)字可以直接閱讀原始論文,值得一提的是ShiDianNao的功耗在不同硬件部件上的分配:?
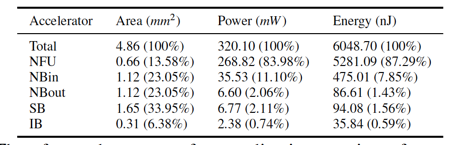
我們能夠看到,在ShiDianNao里,主要的功耗都集中在計算部件(NFU)上了,訪存部件帶來的功耗開銷并不大(小于15%),這與[9里的DianNao加速器]形成了巨大的差異:?
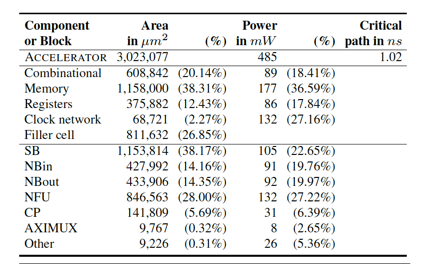
不過,這個關(guān)于功耗的評估對比結(jié)果里有些tricky的地方是,在ShiDianNao里,一部分數(shù)據(jù)傳輸操作實際上從SRAM訪問操作里轉(zhuǎn)移到PE之間的Inter-PE data propagation之上了,這部分功耗被計算入了NFU里,但實際上還是屬于數(shù)據(jù)訪問相關(guān)的功耗開銷。這是我們在觀察這些實驗結(jié)果時要注意的地方。?
最后說說我對這篇論文的一些思考。?
這篇論文propose的加速器,適用面其實還是比較窄的,尺寸超過片上SRAM存儲極限的模型都無法支持。比如包含幾千萬權(quán)重參數(shù)的AlexNet這樣的model,肯定無法在ShiDianNao里被支持。當然這兩年來,有不少研究團隊提出了一些模型壓縮的技術(shù),比如DeepScale提出的SqueezeNet[10]和ICLR16上提出的Deep Compression[11],能夠緩解ShiDianNao這樣的加速器的片上模型存儲的壓力,但ShiDianNao要求模型能夠全部hold在片上SRAM的約束,對于其通用性還是帶來了一些挑戰(zhàn)(相比而言,要求神經(jīng)層的輸入/輸出神經(jīng)元全部能夠hold在NBin/NBout倒并不是一個苛刻的約束),這個約束在[3][4]里并沒有看到。也許未來的一種可能是將ShiDianNao這樣專門針對特定場景的加速芯片與[3][4]這種更具通用性的加速器設(shè)計融合在一起,可以獲取到更好的性能/通用性的trade-off,當然其代價是芯片設(shè)計的復(fù)雜性。?
最后想說的,真的是no free lunch。記得以前Knuth說過,系統(tǒng)的復(fù)雜性是恒定的,無非是在硬件和軟件之間的分配。當硬件遇到了階段性極限的時候,軟件設(shè)計人員就要去填充更多的復(fù)雜性。當軟件也遇到極限的時候,就需要硬件與軟件進行協(xié)同設(shè)計來改善系統(tǒng)復(fù)雜性。在DianNao系列工作中,能夠明顯看到這個trend。在[12]里也通過對體系結(jié)構(gòu)頂會的技術(shù)主題的變遷進行了回顧分析,能夠看到軟硬件協(xié)同設(shè)計、應(yīng)用驅(qū)動設(shè)計的趨勢。我個人相信,隨著計算資源越來越可以便利地獲取,網(wǎng)絡(luò)帶寬的使用成本日益降低,通過計算設(shè)備滿足人類形形色色需求的應(yīng)用驅(qū)動年代會更快/已經(jīng)到來,在這個時代,應(yīng)用/軟件/硬件相結(jié)合來提供更具ROI的解決方案會是相當長一段時間內(nèi)的趨勢性現(xiàn)象。?
References:?
[1]. Zidong Du. ShiDianNao: Shifting Vision Processing Closer to the Sensor. ISCA, 2015.?
[2]. A Brief Introduction to The Dianao Project. http://novel.ict.ac.cn/diannao/
[3]. Daofu Liu. PuDianNao: A Polyvalent Machine Learning Accelerator. ASPLOS, 2015.?
[4]. Shaoli Liu. Cambricon: An Instruction Set Architecture for Neural Networks", in Proceedings of the 43rd ACM/IEEE International Symposium on Computer Architecture. ISCA, 2016.?
[5]. Olivier Temam. A Defect-Tolerant Accelerator for Emerging High-Performance Applications. ISCA, 2012.?
[6]. Fixed-point arithmetic. Fixed-point arithmetic
[7]. Latency Numbers Every Programmer Should Know. https://gist.github.com/jboner/2841832
[8]. D. Larkin, A. Kinane, V. Muresan, and N. E. O’Connor. An Efficient Hardware Architecture for a Neural Network Activation Function Generator. Advances in Neural Networks, ser. Lecture Notes in Computer Science, vol. 3973. Springer, 2006, pp. 1319–1327.?
[9] T. Chen, Z. Du, N. Sun, J. Wang, and C. Wu. DianNao: a small-footprint high-throughput accelerator for ubiquitous machine learning. Proceedings of the 19th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Salt Lake City, UT, USA, 2014, pp. 269–284.?
[10]. Song Han. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. ICLR16.?
[11]. Forrest N. Iandola. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size. Arxiv, 2016.?
[12]. 楊軍. ISCA 2016有哪些看點. ISCA 2016 有哪些看點? - 楊軍的回答
作者:楊軍鏈接:https://www.zhihu.com/question/41216802/answer/124409366
來源:知乎
著作權(quán)歸作者所有,轉(zhuǎn)載請聯(lián)系作者獲得授權(quán)。
3. DaDianNao
DaDianNao[1]這篇文章是Diana項目[5]的第二篇代表性論文,發(fā)表在Micro 2014[6],并且獲得了當屆的best paper。這篇論文里針對主流神經(jīng)網(wǎng)絡(luò)模型尺寸較大的應(yīng)用場景(想像一下AlexNet這樣的模型已經(jīng)包含約6千萬個權(quán)重參數(shù)),提出了一種具備伸縮性,并通過這種伸縮性可以承載較大尺寸模型的加速器設(shè)計架構(gòu)。”Da”也取得是中文“大”的諧音,用來意指伸縮性。這款加速器與針對嵌入式設(shè)備應(yīng)用場景提出的ShiDianNao[13]不同,針對的應(yīng)用場景是服務(wù)器端的高性能計算,所以在計算能耗比上雖然相比于baseline(GPU/CPU)會有提升,但其設(shè)計核心還是專注于高性能地支持大尺寸模型,所以在硬件資源的使用上也遠比[13]要更為大方一些。?
在我的理解中,這款加速器的核心設(shè)計思想包括幾個:?
I. 使用eDRAM[3]代替SRAM/DRAM,在存儲密度/訪存延遲/功耗之間獲得了大模型所需的更適宜的trade-off(參見下表)。?

II. 在體系結(jié)構(gòu)設(shè)計中以模型參數(shù)為中心。模型參數(shù)(對應(yīng)于神經(jīng)網(wǎng)絡(luò)中的突觸連接)存放在固定的eDRAM存儲區(qū)域中,需要通過訪存操作完成加載的是網(wǎng)絡(luò)神經(jīng)元(即對應(yīng)于神經(jīng)層layer的input/outout neurons)。這樣設(shè)計考慮的原因是,無論是神經(jīng)網(wǎng)絡(luò)的training還是inference環(huán)節(jié),對于于DaDianNao的問題場景,模型的尺寸要遠遠大于數(shù)據(jù)尺寸以及網(wǎng)絡(luò)神經(jīng)層的神經(jīng)元數(shù)據(jù)尺寸,所以將尺寸更大的神經(jīng)網(wǎng)絡(luò)模型參數(shù)固定,而將尺寸較小的神經(jīng)元通過訪存操作進行加載、通信,可以減少消耗在訪存上的開銷。此外,模型參數(shù)會布署在距離計算部件很近的布局區(qū)域里,以減少計算部件工作過程中的訪存延時(這也是Computational RAM思想[10]的典型應(yīng)用)。另一個原因在文章里沒有提到,而是我個人結(jié)合DianNao系列論文的解讀,模型參數(shù)在整體計算過程中會不斷地被復(fù)用,而神經(jīng)元被復(fù)用的頻率則并不高,所以將模型參數(shù)存放在固定的存儲區(qū)域里,可以充分挖掘模型參數(shù)的data locality,減少片外訪存帶寬,同時提升整體加速器的性能。
III. 神經(jīng)網(wǎng)絡(luò)模型具備良好的模型可分特性。以常用的CNN/DNN這兩類神經(jīng)層為例。 當單層CNN/DNN layer對應(yīng)的模型參數(shù)較大,超過了DaDianNao單片存儲極限時(參見下圖的一下大尺寸的CNN/DNN layer,具體到這些layer所對應(yīng)的應(yīng)用場景,可以參見DaDianNao的原始論文中的參考文獻),可以利用這種模型可分性,將這個layer劃分到多個芯片上,從而通過多片連接來支持大尺寸模型。想更具體的把握這個問題,不妨這樣思考,對于CNN layer來說,每個feature map的計算(以及計算這個feature map所需的模型參數(shù))實際上都是可以分配在不同的芯片上的,而DNN layer來說,每個output neuron的計算(以及計算這個output neuron所需的模型參數(shù))也都是可以分配在不同的芯片上的。
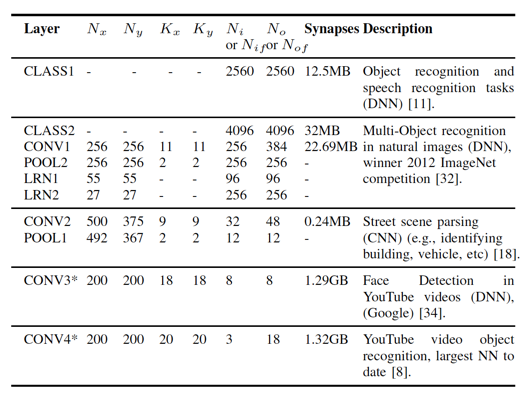
正是基于上面的三個設(shè)計原則,在這篇論文中給出了DaDianNao的設(shè)計方案。在我的理解中,DaDianNao的邏輯結(jié)構(gòu)與DianNao[11](見下圖)是非常相似的:?
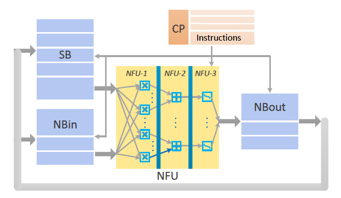
DaDianNao的主要區(qū)別還是在于針對存儲神經(jīng)層輸入輸出數(shù)據(jù)的NBin/NBout,存儲神經(jīng)連接參數(shù)的SB的組織方式,以及其與核心計算單元NFU的數(shù)據(jù)交互方式進行了針對大模型的專門考量。?
把握DaDianNao的核心要素,也在于理解其訪存體系的設(shè)計思想及細節(jié)。?
單個DaDianNao芯片內(nèi)的訪存體系設(shè)計的高層次圖如下:?
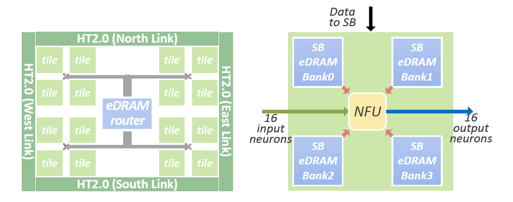
左圖是單個芯片的高層次圖,可以看到,單個芯片由16個Tile組成。右圖則是單個Tile的頂層結(jié)構(gòu)圖。?
每個tile內(nèi)部會由一個NFU配上4個用于存儲SB的eDRAM rank組成。而NBin/NBout則對應(yīng)于左圖eDRAM router所連接的兩條棕色的eDRAM rank。?
看到上面的高層次圖,會感受到在DaDianNao里,SB其實是采用了distributed的方式完成設(shè)計的,并不存在一個centralized的storage用于存儲模型的參數(shù)。這個設(shè)計細節(jié)的選取考量我是這樣理解的:?
I.eDRAM與DRAM相比,雖然因為其集成在了芯片內(nèi)部,latency顯著變小,但是因為仍然有DRAM所存在的漏電效應(yīng),所以還是需要周期性的刷新,并且這個刷新周期與DRAM相比會變得更高[4],而周期性的刷新會對訪存性能帶來一定的負面影響。所以通過將SB存儲拆分成多個Bank,可以將周期性刷新的影響在一定程度上減小。?
II.將SB拆分開,放置在每個NFU的周圍,可以讓每個計算部分在計算過程中,訪問其所需的模型參數(shù)時,訪存延遲更小,從而獲得計算性能上的收益。?
NFU的內(nèi)部結(jié)構(gòu)圖如下所示:?
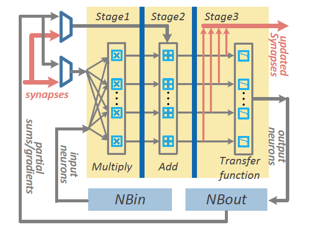
從上圖,能夠看到NFU的每個Pipeline Stage與NBin/NBout/SB的交互連接通路。 而針對不同的神經(jīng)層,NFU的流水線工作模式可以見下圖:?
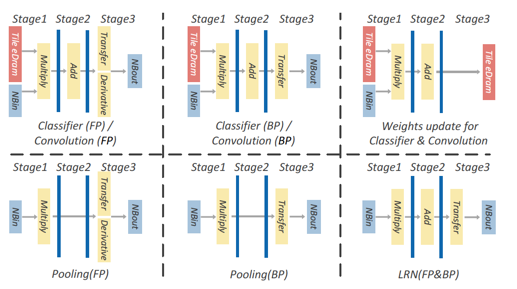
注意,上圖里紅色的“The eDram”代表的就是SB存儲。?
以上是單個DaDianNao芯片的設(shè)計,而單個DaDianNao的片上用于存儲模型參數(shù)的SB存儲仍然有限(見下圖,單個芯片里,用于NBin/NBout的central eDRAM尺寸是4MB,而每個Tile里用于SB的eDRAM尺寸則是2MB,每個芯片由16個Tile組成,所以單個芯片的eDRAM總量是2 * 16 + 4 = 36MB),所以為了支持大模型,就需要由多個DaDianNao芯片構(gòu)成的多片系統(tǒng)。?

DaDianNao里的多片互聯(lián)部分并沒有進行定制開發(fā),而是直接使用了HyperTransport 2.0[12]通信IP,在每個DaDianNao芯片的四周(每個芯片會跟上下左右四個鄰近的DaDianNao芯片連接)提供了共四組HT 2.0的通信通道,每個通道的通信帶寬是在in/out方向分別達到6.6GB/s,支持全雙工通信,inter-chip的通訊延遲是80ns。?
有了inter-chip的連接支持,DaDianNao就可以支持大尺寸的模型了。不同模型,在inter-chip的工作模式下,通信的數(shù)據(jù)量也有較大的差異:?
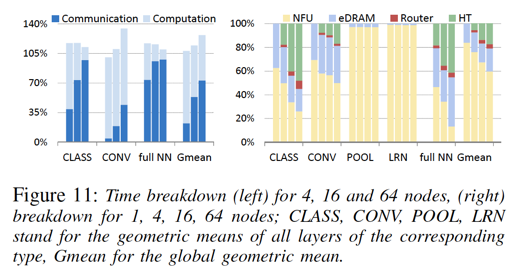
能夠看到,相較于卷積層(CONV),全連接層(full NN)在多片模式下,通信耗時明顯更多。 同樣,卷積層的多片加速比也遠大于全連接層(對于一些全連接層,甚至在Inference環(huán)節(jié),出現(xiàn)多片性能低于單片的情形,這也算make sense,畢竟,inference環(huán)節(jié)的計算通信比要小于training環(huán)節(jié)):?
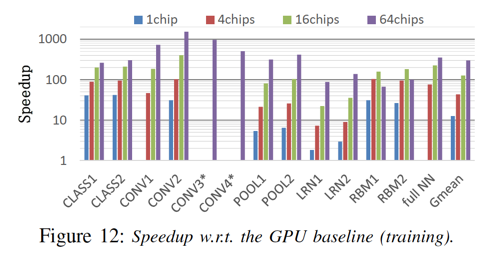
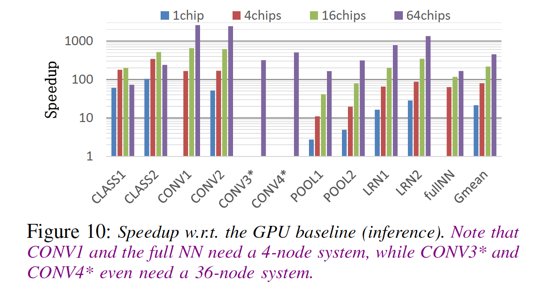
具體的細節(jié)評估指標,在這里就不再引入,感興趣的同學(xué)可以直接參考原始論文。?
References:?
[1]. Yunji Chen. DaDianNao: A Machine-Learning Supercomputer. Micro, 2014.?
[2]. S.-N. Hong and G. Caire. Compute-and-forward strategies for cooperative distributed antenna systems. In IEEE Transactions on Information Theory, 2013.?
[3] eDRAM. eDRAM
[4]. Mittal. A Survey Of Architectural Approaches for Managing Embedded DRAM and Non-volatile On-chip Caches. IEEE TPDS, 2014.?
[5]. A Brief Introduction to The Dianao Project. http://novel.ict.ac.cn/diannao/
[6]. Micro 2014. MICRO-47 Home Page
[7]. N. Maeda, S. Komatsu, M. Morimoto, and Y. Shimazaki. A 0.41a standby leakage 32kb embedded sram with lowvoltage resume-standby utilizing all digital current comparator in 28nm hkmg cmos. In International Symposium on VLSI Circuits (VLSIC), 2012.?
[8]. G. Wang, D. Anand, N. Butt, A. Cestero, M. Chudzik, J. Ervin, S. Fang, G. Freeman, H. Ho, B. Khan, B. Kim, W. Kong, R. Krishnan, S. Krishnan, O. Kwon, J. Liu, K. McStay, E. Nelson, K. Nummy, P. Parries, J. Sim, R. Takalkar, A. Tessier, R. Todi, R. Malik, S. Stiffler, and S. Iyer. Scaling deep trench based edram on soi to 32nm and beyond. In IEEE International Electron Devices Meeting (IEDM), 2009.?
[9]. DDR3 SDRAM Part Catalog. Micron Technology, Inc.
[10]. Computational RAM. Computational RAM
[11] T. Chen, Z. Du, N. Sun, J. Wang, and C. Wu. DianNao: a small-footprint high-throughput accelerator for ubiquitous machine learning. Proceedings of the 19th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Salt Lake City, UT, USA, 2014, pp. 269–284.?
[12]. HyperTransport. HyperTransport
[13]. Zidong Du. ShiDianNao: Shifting Vision Processing Closer to the Sensor. ISCA, 2015.
4.DianNao
[1]是DianNao項目[2]的第一篇,也是篇開創(chuàng)性論文,發(fā)在了ASPLOS 14上,并且獲得了當年的best paper。?
如果用一句話來提煉這篇論文的核心思想,我想可以這樣總結(jié):?
結(jié)合神經(jīng)網(wǎng)絡(luò)模型的數(shù)據(jù)局部性特點以及計算特性,進行存儲體系以及專用硬件設(shè)計,從而獲取更好的性能加速比以及計算功耗比。?
因為我閱讀DianNao項目系列論文是按時間序反序延展的,先后讀的是PuDianNao[5]->ShiDianNao[4]->DaDianNao[3],最后讀的是DianNao這篇論文。所以從設(shè)計復(fù)雜性來說,ASPLOS 14的這篇論文應(yīng)該說是最簡單的。當然,這樣說并不是說這篇論文的價值含量比其他論文低。恰恰相反,我個人以為這篇論文的價值其實是較高的,因為這是一篇具備開創(chuàng)性意義的論文,在科研領(lǐng)域,我認為starter要比follower更有意義的多,這種意義并不會因為follower在執(zhí)行操作層面的出色表現(xiàn)就可以減色starter的突破性貢獻。 因為starter是讓大家看到了一種之前沒有人看到的可能性,而follower則是在看到了這種可能性之后,在執(zhí)行操作層面的精雕細琢。幾個經(jīng)典的例子就是第一個超導(dǎo)材料的發(fā)現(xiàn)帶動了后續(xù)多種超導(dǎo)材料的發(fā)現(xiàn),以及劉易斯百米短跑突破10秒之后帶動了多位運動員跑入10秒之內(nèi)的成績。
在[1]這篇論文里,先是回顧了之前常見的神經(jīng)網(wǎng)絡(luò)的全硬件實現(xiàn)方案(full-hardware implementation)——將每個神經(jīng)元都映射到具體的硬件計算單元上,模型權(quán)重參數(shù)則作為latch或是RAM塊實現(xiàn),具體的示意結(jié)構(gòu)圖如下:?
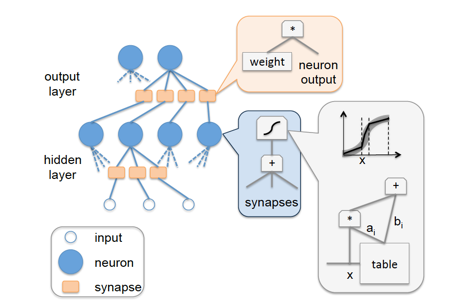
這種方案的優(yōu)點很明顯,實現(xiàn)方案簡潔,計算性能高,功耗低。缺點也不難想象,擴展性太差,無論是模型topology的變化,還是模型尺寸的增加都會使得這種方案無法應(yīng)對。下面針對不同 input neurons/網(wǎng)絡(luò)權(quán)重數(shù) 的network layer給出了full-hardware implementation在硬件關(guān)鍵路徑延時/芯片面積/功耗上的變化趨勢,能夠直觀地反映出full-hardware這種實現(xiàn)方案的伸縮性問題:?
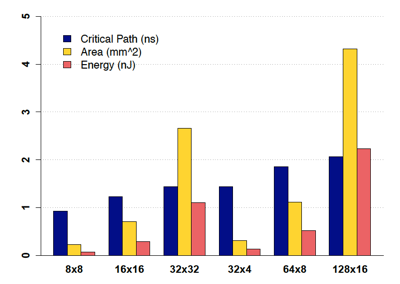
針對full-hardware方案的不足,在[1]里提出了基于時分復(fù)用原則的加速器設(shè)計結(jié)構(gòu):?
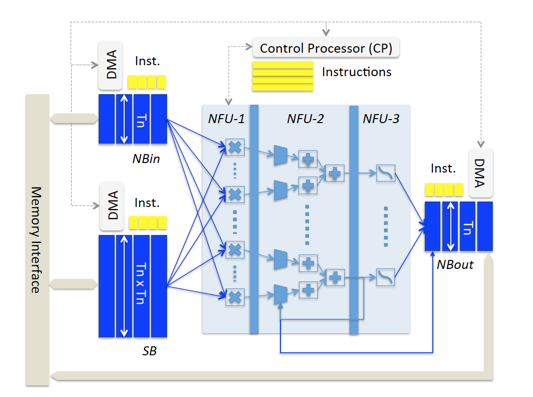
在這個設(shè)計結(jié)構(gòu)里,加速器芯片里包含三塊片上存儲,分別是用于存儲input neurons的NBin、存儲output neurons的NBout以及用于存儲神經(jīng)網(wǎng)絡(luò)模型權(quán)重參數(shù)的SB。這三塊存儲均基于SRAM實現(xiàn),以獲取低延時和低功耗的收益。片上存儲與片外存儲的數(shù)據(jù)交互方式通過DMA來完成,以盡可能節(jié)省通訊延時。?
除了片上存儲以外,另一個核心部件則是由三級流水線組成的NFU(Neural Functional Unit),完成神經(jīng)網(wǎng)絡(luò)的核心計算邏輯。?
時分復(fù)用的思想,正是體現(xiàn)在NFU和片上存儲的時分復(fù)用特性。針對一個大網(wǎng)絡(luò),其模型參數(shù)會依次被加載到SB里,每層神經(jīng)layer的輸入數(shù)據(jù)也會被依次加載到NBin,layer計算結(jié)果寫入到NBout。NFU里提供的是基礎(chǔ)計算building block(乘法、加法操作以及非線性函數(shù)變換),不會與具體的神經(jīng)元或權(quán)重參數(shù)綁定,通過這種設(shè)計,DianNao芯片在支持模型靈活性和模型尺寸上相較于full-hardware implementation有了明顯的改進。?
DianNao加速器的設(shè)計中一些比較重要的細節(jié)包括:?
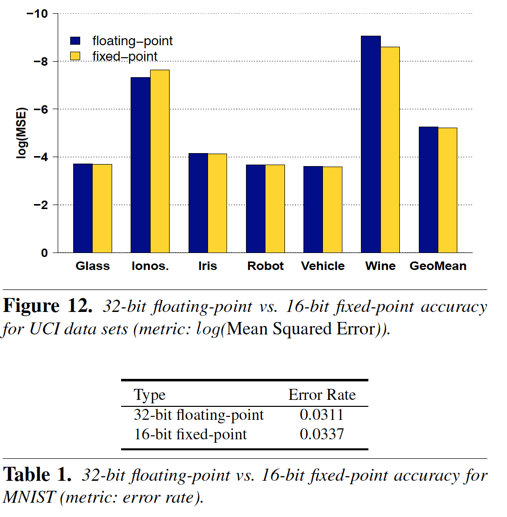
I. 使用16位定點操作代替32位浮點,這在模型的精度方面,損失并不大:?
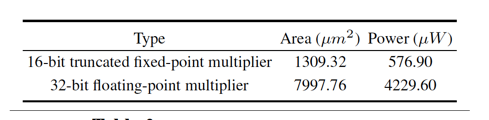
但是在芯片面積和功耗上都獲得了明顯的收益:?
II. 之所以將片上SRAM存儲劃分為NBin/NBout/SB這三個分離的模塊,是考慮到SRAM的不同訪存寬度(NBin/NBout與SB的訪存寬度存在明顯差異,形象來說,NBin/NBout的訪存寬度是向量,而SB則會是矩陣)在功耗上存在比較明顯的差異:
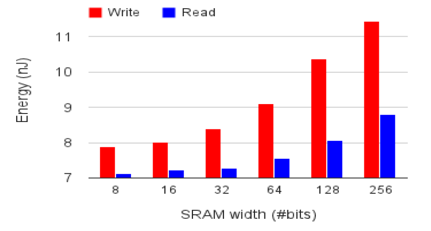
拆分成不同的模塊,可以在功耗/性能上找到更佳的設(shè)計平衡點。而將訪存寬度相同的NBin/NBout也拆分開來的原因則是為了減少data conflict,因為NBin/NBout扮演的還是類似于cache的角色,而這兩類數(shù)據(jù)的訪存pattern并不盡相同,如果統(tǒng)一放在一塊SRAM里,cache conflict的概率會增大,所以通過將訪存pattern相近的數(shù)據(jù)對應(yīng)于不同的SRAM塊,“專款專用”,可以進一步減少cache conflict,而cache conflict的減少,無論是對于性能的提升,還是功耗的減少都會有著正面的意義。?
III. 對input neurons數(shù)據(jù)以及SB數(shù)據(jù)局部性的挖掘。用通俗一些的說法,其實就是把輸入數(shù)據(jù)的加載與計算過程給overlap起來。在針對當前一組input neurons進行計算的同時,可以通過DMA啟動下一組input neurons/SB參數(shù)的加載。當然,這要求精細的co-ordination邏輯保證。另外,這也會要求NBin/SB的SRAM存儲需要支持雙端口訪問,這對功耗和面積會帶來一定的影響[6]。
IV. 對output neurons數(shù)據(jù)局部性的挖掘。在設(shè)計上,為NFU引入了專用寄存器,用于存儲output neurons對應(yīng)的partial計算結(jié)果(想象一下對應(yīng)于全連接層的一個output neuron,input neurons太多,NBin放不下,需要進行多次加載計算才能完成一個output neuron的完整結(jié)果的輸出)。并且會在設(shè)計上將NBout用作專用寄存器的擴展,存放partial計算結(jié)果,以減少將partial計算結(jié)果寫入片外存儲的性能開銷。?
整體上的設(shè)計思想大體上如上所述。?
在實驗評估上,可能是因為作為第一個milestone的工作結(jié)果,還有很多細節(jié)有待雕琢,所以在baseline的選取上與后續(xù)的幾篇論文相比,顯得有些保守,在這篇論文里只選取了CPU作為baseline,并未將GPU作為baseline。具體的評估細節(jié)及指標可以直接參看原始論文,我這里不再重復(fù)。
References:?
[1]. Tianshi Chen. DianNao: A Small-Footprint High-Throughput Accelerator for Ubiquitous Machine-Learning. ASPLOS, 2014.?
[2]. A Brief Introduction to The Dianao Project. http://novel.ict.ac.cn/diannao/
[3]. Yunji Chen. DaDianNao: A Machine-Learning Supercomputer. Micro, 2014.?
[4]. Zidong Du. ShiDianNao: Shifting Vision Processing Closer to the Sensor. ISCA, 2015.?
[5]. Daofu Liu. PuDianNao: A Polyvalent Machine Learning Accelerator. ASPLOS, 2015.?
[6]. What is dual-port RAM. Dual port memory, dual ported memory, Ports, sdram, sram, sdram, memories
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/4434.html
摘要:年,中科院計算所半導(dǎo)體所有關(guān)研制大規(guī)模集成電路的單位和廠合并,成立中科院微電子中心。目前是國資比例最高通過中國長城控股的國產(chǎn)企業(yè),是聚焦國家戰(zhàn)略需求和重大項目的國家隊。年,海光信息同達成合作,共同合資成立兩家子公司,引入架構(gòu)授權(quán)。本文將重點圍繞國產(chǎn)CPU的發(fā)展歷程與當前產(chǎn)業(yè)鏈各領(lǐng)軍企業(yè)的布局情況作詳盡解讀(并包含特大號獨家整理的最新進展),具體如下:1、國產(chǎn)CPU發(fā)展歷程回溯2、飛騰:PK生...
摘要:受到其他同行在上討論更好經(jīng)驗的激勵,我決定買一個專用的深度學(xué)習(xí)盒子放在家里。下面是我的選擇從選擇配件到基準測試。即便是深度學(xué)習(xí)的較佳選擇,同樣也很重要。安裝大多數(shù)深度學(xué)習(xí)框架是首先基于系統(tǒng)開發(fā),然后逐漸擴展到支持其他操作系統(tǒng)。 在用了十年的 MacBook Airs 和云服務(wù)以后,我現(xiàn)在要搭建一個(筆記本)桌面了幾年時間里我都在用越來越薄的 MacBooks 來搭載一個瘦客戶端(thin c...
摘要:月日,各項競賽的排名將決定最終的成績排名。選手通過訓(xùn)練模型,對虛擬股票走勢進行預(yù)測。冠軍將獲得萬元人民幣的獎勵。 showImg(https://segmentfault.com/img/bVUzA7?w=477&h=317); 2017年9月4日,AI challenger全球AI挑戰(zhàn)賽正式開賽,來自世界各地的AI高手,將展開為期三個多月的比拼,獲勝團隊將分享總額超過200萬人民幣的...

閱讀 2591·2023-04-25 22:09
閱讀 2837·2021-10-14 09:47
閱讀 1889·2021-10-11 11:10
閱讀 2676·2021-10-09 09:44
閱讀 3372·2021-09-22 14:57
閱讀 2492·2019-08-30 15:56
閱讀 1614·2019-08-30 15:55
閱讀 775·2019-08-30 14:13




