資訊專欄INFORMATION COLUMN

摘要:深度學習近年來在中廣泛使用,在機器閱讀理解領域也是如此,深度學習技術的引入使得機器閱讀理解能力在最近一年內有了大幅提高,本文對深度學習在機器閱讀理解領域的技術應用及其進展進行了歸納梳理。目前的各種閱讀理解任務中完形填空式任務是最常見的類型。
關于閱讀理解,相信大家都不陌生,我們接受的傳統語文教育中閱讀理解是非常常規的考試內容,一般形式就是給你一篇文章,然后針對這些文章提出一些問題,學生回答這些問題來證明自己確實理解了文章所要傳達的主旨內容,理解地越透徹,學生越能考出好的成績。
如果有一天機器能夠做類似于我們人類做閱讀理解任務,那會發生什么呢?很明顯教會機器學會閱讀理解是自然語言處理(NLP)中的核心任務之一。如果哪一天機器真能具備相當高水準的閱讀理解能力,那么很多應用便會體現出真正的智能。比如搜索引擎會在真正理解文章內容基礎上去回答用戶的問題,而不是目前這種以關鍵詞匹配的方式去響應用戶,這對于搜索引擎來說應該是個技術革命,其技術革新對產品帶來的巨大變化,遠非在關鍵詞匹配之上加上鏈接分析這種技術進化所能比擬的。而眾所周知,谷歌其實就是依賴鏈接分析技術起家的,所以如果機器閱讀理解技術能夠實用化,對搜索引擎領域帶來的巨變很可能是顛覆性的。對話機器人如果換個角度看的話,其實也可以看做是一種特殊的閱讀理解問題,其他很多領域也是如此,所以機器閱讀理解是個非常值得關注的技術方向。
深度學習近年來在NLP中廣泛使用,在機器閱讀理解領域也是如此,深度學習技術的引入使得機器閱讀理解能力在最近一年內有了大幅提高,本文對深度學習在機器閱讀理解領域的技術應用及其進展進行了歸納梳理。
什么是機器閱讀理解
機器閱讀理解其實和人閱讀理解面臨的問題是類似的,不過為了降低任務難度,很多目前研究的機器閱讀理解都將世界知識排除在外,采用人工構造的比較簡單的數據集,以及回答一些相對簡單的問題。給定需要機器理解的文章以及對應的問題,比較常見的任務形式包括人工合成問答、Cloze-style queries和選擇題等方式。
人工合成問答是由人工構造的由若干簡單事實形成的文章以及給出對應問題,要求機器閱讀理解文章內容并作出一定的推理,從而得出正確答案,正確答案往往是文章中的某個關鍵詞或者實體。比如圖1展示了人工合成閱讀理解任務的示例。圖1示例中前四句陳述句是人工合成的文章內容,Q是問題,而A是標準答案。

?圖1. 人工合成閱讀理解任務示例
Cloze-style queries是類似于“完形填空”的任務,就是讓計算機閱讀并理解一篇文章內容后,對機器發出問題,問題往往是抽掉某個單詞或者實體詞的一個句子,而機器回答問題的過程就是將問題句子中被抽掉的單詞或者實體詞預測補全出來,一般要求這個被抽掉的單詞或者實體詞是在文章中出現過的。圖2展示了完形填空式閱讀理解任務的示例。圖中表明了文章內容、問題及其對應的答案。這個例子是將真實的新聞數據中的實體詞比如人名、地名等隱去,用實體標記符號替換掉實體詞具體名稱,問題中一般包含個占位符placeholder,這個占位符代表文章中的某個實體標記,機器閱讀理解就是在文章中找出能夠回答問題的某個真實答案的實體標記。目前的各種閱讀理解任務中“完形填空式”任務是最常見的類型。

圖2.完形填空式閱讀理解
還有一種任務類型是選擇題,就是閱讀完一篇文章后,給出問題,正確答案是從幾個選項中選擇出來的,典型的任務比如托福的聽力測試,目前也有研究使用機器來回答托福的聽力測試,這本質上也是一種閱讀理解任務。

圖3.托福聽力測試題示例
如果形式化地對閱讀理解任務和數據集進行描述的話,可以將該任務看作是四元組:

其中,代表一篇文章,代表針對文章內容提出的一個問題,是問題的正確答案候選集合而代表正確答案。對于選擇題類型來說,就是明確提供的答案候選集合而是其中的正確選項。對于人工合成任務以及完形填空任務來說,一般要求:
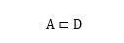
也就是說,要求候選答案是在文章中出現過的詞匯或者實體詞。
深度學習技術進展
本節內容對目前機器閱讀理解領域中出現的技術方案進行歸納梳理,正像本文標題所述,我們只對深度學習相關的技術方案進行分析,傳統技術方案不在討論之列。
1.文章和問題的表示方法
用神經網絡處理機器閱讀理解問題,首先面臨的問題就是如何表示文章和問題這兩個最重要的研究對象。我們可以從現有機器閱讀理解相關文獻中歸納總結出常用的表示方法,當然這些表示方法不僅僅局限于閱讀理解問題,也經常見于NLP其他子領域中。
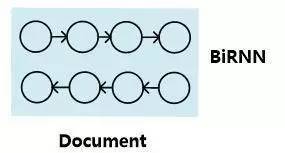
圖4.文檔表示方法:模型一
首先,對于機器閱讀理解中的文章來說,有兩種常見的文章內容表達方式。最常見的一種即是將一篇文章看成有序的單詞流序列(參考圖4的模型一,圖中每個圓即代表某個單詞的神經網絡語義表達,圖中的BiRNN代表雙向RNN模型),在這個有序序列上使用RNN來對文章進行建模表達,每個單詞對應RNN序列中的一個時間步t的輸入,RNN的隱層狀態代表融合了本身詞義以及其上下文語義的語言編碼。這種表示方法并不對文章整體語義進行編碼,而是對每個單詞及其上下文語義進行編碼,在實際使用的時候是使用每個單詞的RNN隱層狀態來進行相關計算。至于具體的RNN模型,常見的有標準RNN、LSTM、GRU及其對應的雙向版本等。對于機器閱讀理解來說雙向RNN是最常用的表示方法,一般每個單詞的語義表示由正向RNN隱層狀態和反向RNN隱層狀態拼接來表示,即:
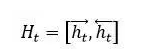
模型一往往在機器閱讀理解系統的原始輸入部分對文章進行表征,因為對于很多閱讀理解任務來說,本質上是從文章中推導出某個概率較大的單詞作為問題的答案,所以對文章以單詞的形式來表征非常自然。
另外一種常見的文章內容表達方式則是從每個單詞的語義表達推導出文章整體的Document Embedding表達,這種形式往往是在對問題和文章進行推理的內部過程中使用的表達方式。典型的表達過程如圖5所示的模型二所示。
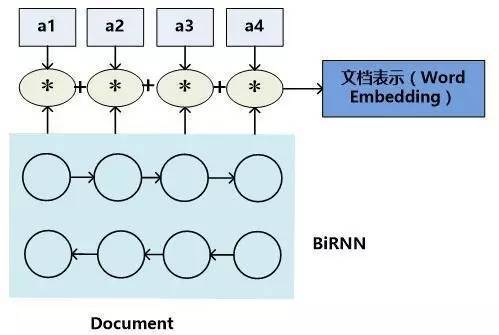
圖5. 文檔表示方法:模型二
模型二的含義是:首先類似于模型一,用雙向RNN來對每個單詞及其上下文進行語義表征,形成隱層狀態表示,然后對于向量的每一維數值,乘以某個系數,這個系數代表了單詞對于整個文章最終語義表達的重要程度,將每個單詞的系數調整后的隱層狀態累加即可得到文章的Word Embedding語義表達。而每個單詞的權重系數通常用Attention計算機制來計算獲得,也有不使用權重系數直接累加的方式,這等價于每個單詞的權重系數都是1的情形,所以可以看作加權平均方法的特殊版本。以公式表達的話,文章的語義表達公式如下:
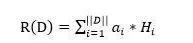
對于機器閱讀理解中的問題來說,有三種常見的語義表達方式。如果將查詢看作一種特殊的文章的話,很明顯文章的語義表達方式同樣可以用來表征問題的語義,也就是類似于文檔表示方法的模型一和模型二。問題的表示方法模型一如圖6所示,模型二如圖7所示,其代表的含義與文章表征方式相似,所以此處不贅述。
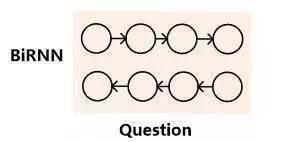
圖6.問題表示方式:模型一
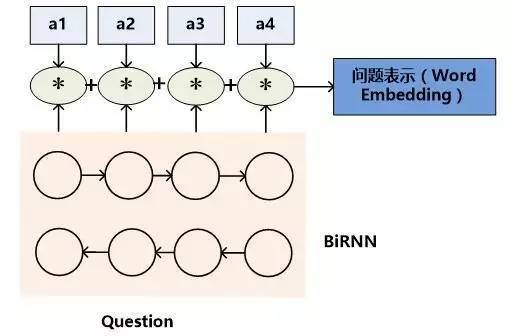
圖7.問題表示方法:模型二
問題表示方法的另外一種表示如圖8所示,我們可以稱之為模型三。

圖8.問題表示方法:模型三
模型三也是在模型一的基礎之上的改進模型,也是NLP任務中表達句子語義的最常見的表達方式。首先類似于模型一,使用雙向RNN來表征每個單詞及其上下文的語義信息。對于正向RNN來說,其尾部單詞(句尾詞)RNN隱層節點代表了融合了整個句子語義的信息;而反向RNN的尾部單詞(句首詞)則逆向融合了整個句子的語義信息,將這兩個時刻RNN節點的隱層狀態拼接起來則可以表征問題的整體語義:
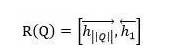
理論上模型三也可以用來表征文章的語義信息,但是一般不會這么用,主要原因是文章往往都比較長,RNN對于太長的內容表征能力不足,所以類似模型三的方法會存在大量的信息丟失,而“問題”一般來說都是比較短的一句話,所以用模型三表征是比較合適的。
以上介紹的幾個模型是在機器閱讀理解領域里常用的表征文章和問題的表示方法。下面我們從機器閱讀理解神經網絡結構的角度來進行常用模型的介紹。
2、機器閱讀理解的深度學習模型
目前機器閱讀理解研究領域出現了非常多的具體模型,如果對這些模型進行技術思路梳理的話,會發現本質上大多數模型都是論文“Teaching Machines to Read and Comprehend”提出的兩個基礎模型”Attentive Reader”和“Impatient Reader”的變體(參考文獻1),當然很多后續模型在結構上看上去有了很大的變化,但是如果仔細推敲的話會發現根源和基礎思路并未發生顛覆性的改變。
我們將主流模型技術思路進行歸納梳理以及某些技術點進行剝離組合,將其歸類為“一維匹配模型”、“二維匹配模型”、“推理模型”等三類模型,其中“一維匹配模型”和“二維匹配模型”是基礎模型,“推理模型”則是在基礎模型上重點研究如何對文本內容進行推理的機制。當然,還有個別模型在結構上有其特殊性,所以最后會對這些模型做些簡介。
2.1 ?一維匹配模型
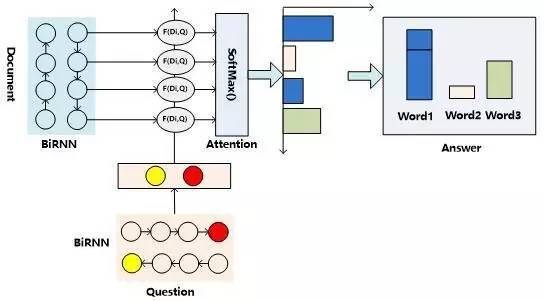
圖9. 機器閱讀理解的一維匹配結構
目前機器閱讀理解任務的解決方案中,有相當多的模型可以被歸類到“一維匹配模型”這種技術范型中,這類模型本質上是“Attentive Reader”的變體。我們首先介紹這種技術思路的總體流程結構,然后說明下主流方法在這個框架下的一些區別。
圖9所示是“一維匹配模型”的技術流程示意圖:首先,對文章內容使用“文章表示方法:模型一”的方式對文章語義內容進行編碼,對于問題來說,則一般會使用“問題表示方法:模型三”的方式對問題進行語義編碼,即使用雙向RNN的頭尾部節點RNN隱層狀態拼接作為問題的語義表示。然后,通過某種匹配函數來計算文章中每個單詞Di(編碼中包括單詞語義及其上下文單詞的語義)語義和問題Q整體語義的匹配程度,從含義上可以理解為F是計算某個單詞Di是問題Q的答案的可能性映射函數。接下來,對每個單詞的匹配函數值通過SoftMax函數進行歸一化,整個過程可以理解為Attention操作,意即凸顯出哪些單詞是問題答案的可能性。最后,因為一篇文章中,某個單詞可能在多處出現,而在不同位置出現的同一個單詞都會有相應的Attention計算結果,這代表了單詞在其具體上下文中是問題答案的概率,將相同單詞的Attention計算出的概率值進行累加,即可作為該單詞是問題Q答案的可能性,選擇可能性較大的那個單詞作為問題的答案輸出。在最后相同單詞概率值累加這一步,一般容易質疑其方式:如果這樣,那么意味著這個方法隱含一個假設,即出現次數越多的單詞越可能成為問題的答案,這樣是否合理呢?實驗數據表明,這個假設基本是成立的,所以這種累加的方式目前是非常主流的技術方案,后文所述的AS Reader和GA Reader采取了這種累加模式,而Stanford AR和Attentive Reader則采取非累加的模式。之所以將這個結構稱為“一維匹配模型”,主要是其在計算問題Q和文章中單詞序列的匹配過程形成了一維線性結構。
上述內容是“一維匹配模型”的基本思路,很多主流的模型基本都符合上述架構,模型之間的較大區別主要是匹配函數的定義不同。具體而言,“Attention Sum Reader”,(后文簡稱AS Reader,參考文獻2)、“Stanford Attentive Reader”(后文簡稱 Stanford AR,參考文獻3)、“Gated-Attention Reader”(后文簡稱GA Reader,參考文獻4)、“Attentive Reader”(參考文獻1)、AMRNN(參考文獻5)等模型都基本遵循這個網絡結構。
AS Reader可以看作是一維匹配結構的典型示例,其匹配函數定義為Di和Q向量的點積:
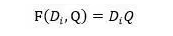
Attentive Reader是最早提出的模型之一,所以在整體結構上和一維匹配結構有些差異,模型性能相對差些,不過這些結構上的差異點并非性能差異的關鍵,而匹配函數能夠解釋其和效果好的模型性能差異的主要原因,其采用了前向神經網絡的形式:

Stanford AR的匹配函數則采用了雙線性(Bilinear)函數:

這里需要說明的是,Stanford AR的效果已經是目前所有機器閱讀理解模型中性能較好的之一,同時其一維匹配模型相對簡單,且沒有采用深層的推理機制,所以這個模型是值得關注的。而其相對Attentive Reader來說,對提升性能最主要的區別就在于采用了雙線性函數,而這個改變對性能提升帶來了極大的幫助;相對AS Reader來說,其性能也有明顯提升,很明顯雙線性函數在其中起了主要作用。由此可見,目前的實驗結果支持雙線性函數效果明顯優于很多其它匹配模型的結論。
AMRNN是用來讓機器做TOFEL聽力題的閱讀理解系統采用的技術方案,類似于GA Reader的整體結構,其是由一維匹配模型加深層網絡組合而成的方案,同樣的,深層網絡是為了進行推理,如果摘除深層網絡結構,其結構與AS Reader也是基本同構的。其采用的匹配函數則使用Di和Q的Cosine相似性,類似于AS Reader向量點積的思路。AMRNN解決的是選擇題而非完形填空任務,所以在輸出階段不是預測文中哪個單詞或實體是問題的答案,而是對幾個候選答案選項進行評估,從中選擇正確答案。
由上述模型對比可以看出,一維匹配模型是個結構簡潔效果整體而言也不錯的模型范式,目前相當多的具體模型可以映射到這個范式中,而其中的關鍵點在于匹配函數如何設計,這一點是導致具體模型性能差異的相當重要的影響因素。可以預見,后續的研究中必然會把重心放在如何改進設計出更好地匹配函數中來。
2.2 ?二維匹配模型
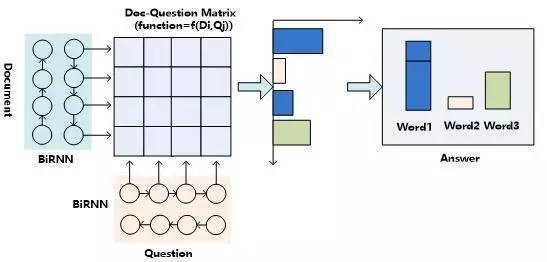
圖10. 機器閱讀理解的二維匹配結構
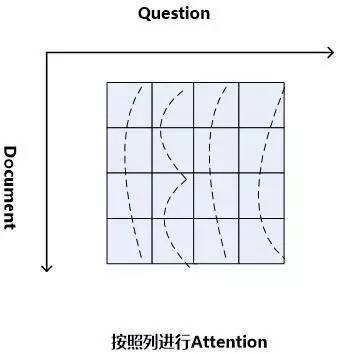
顧名思義,“二維匹配模型”是相對“一維匹配模型”而言的,其最初的思想其實體現在”Impatient Reader”的思路中。圖10是機器閱讀理解中二維匹配模型的整體流程示意圖,從中可以看出,其整體結構與一維匹配模型是類似的,最主要的區別體現在如何計算文章和問題的匹配這個層面上。與一維匹配模型不同的是:二維匹配模型的問題表征方式采用“問題表示方法:模型一”,就是說不是將問題的語義表達為一個整體,而是問題中的每個單詞都多帶帶用Word Embedding向量來表示。這樣,假設文檔長度為||D||,問題長度為||Q||,那么在計算問題和文章匹配的步驟中,就形成了||D||*||Q||的二維矩陣,就是說文章中任意單詞Di和問題中的任意單詞Qj都應用匹配函數來形成矩陣的位置的值。
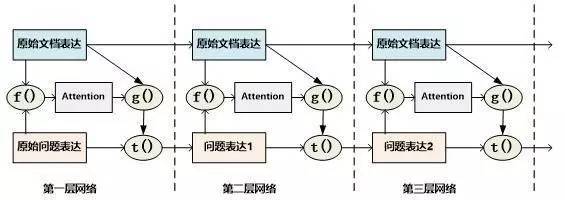
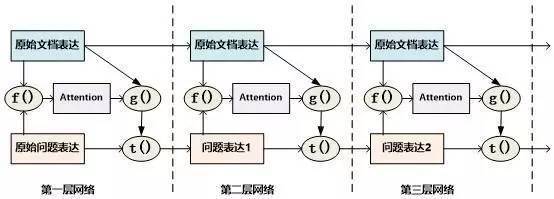
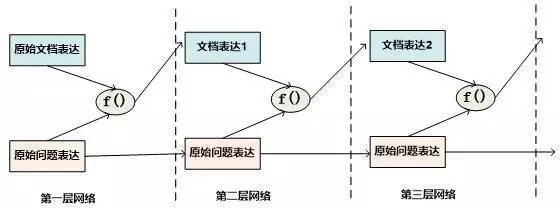
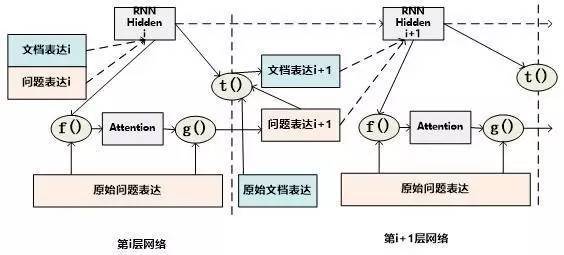
當二維矩陣的值根據匹配函數填充完畢后,就可以考慮進行Attention計算。因為是二維矩陣,所以可以有很多種不同的Attention計算機制。比如可以如圖11這樣按照二維矩陣的行來進行Attention計算,因為矩陣的一行代表文檔中某個單詞Di相對問題中每個單詞Qj(1 圖11.二維結構按行進行Attention 圖12. 二維結構按列進行Attention Consensus Attention 模型(后文簡稱CA Reader,參考文獻6)、Attention-over-Attention模型(后文簡稱AOA Reader,參考文獻7)和Match-LSTM模型(參考文獻8)基本都符合二維匹配結構的范式,其主要區別在于Attention計算機制的差異上。CA Reader按照列的方式進行Attention計算,然后對每一行文檔單詞對應的針對問題中每個單詞的Attention向量,采取一些啟發規則的方式比如取行向量中較大值或者平均值等方式獲得文檔每個單詞對應的概率值。AOA Reader則對CA Reader進行了改進,同時結合了按照列和按照行的方式進行Attention計算,核心思想是把啟發規則改為由按行計算的Attention值轉換成的系數,然后用對按列計算出的Attention加權平均的計算方式獲得文檔每個單詞對應的概率值。Match-LSTM模型則是按行進行Attention計算,同樣地把這些Attention值轉換成列的系數,不過與AOA不同的是,這些系數用來和問題中每個單詞的Word Embedding相乘并對Word Embedding向量加權求和,擬合出整個問題的綜合語義Word Embedding(類似于“問題表示方法:模型二”思路),并和文章中每個單詞的Word Embedding進行合并,構造出另外一個LSTM結構,在這個LSTM結構基礎上去預測哪個或者那些單詞應該是正確答案。 由于二維匹配模型將問題由整體表達語義的一維結構轉換成為按照問題中每個單詞及其上下文的語義的二維結構,明確引入了更多細節信息,所以整體而言模型效果要稍優于一維匹配模型。 從上面的具體模型介紹可以看出,目前二維匹配模型相關工作還不多,而且都集中在二維結構的Attention計算機制上,由于模型的復雜性比較高,還有很多很明顯的值得改進的思路可以引入。最直觀的改進就是探索新的匹配函數,比如可以摸索雙線性函數在二維結構下的效果等;再比如可以引入多層網絡結構,這樣將推理模型加入到閱讀理解解決方案中等。可以預見,類似的思路很快會被探索。 2.3 ?機器閱讀理解中的推理過程 人在理解閱讀文章內容的時候,推理過程幾乎是無處不在的,沒有推理幾乎可以斷定人是無法完全理解內容的,對于機器也是如此。比如對于圖1中所展示的人工合成任務的例子,所提的問題是問蘋果在什么地方,而文章表達內容中,剛開始蘋果在廚房,Sam將其拿到了臥室,所以不做推理的話,很可能會得出“蘋果在廚房”的錯誤結論。 乍一看“推理過程”是個很玄妙而且說不太清楚的過程,因為自然語言文本不像一階邏輯那樣,已經明確地定義出符號以及表達出符號之間的邏輯關系,可以在明確的符號及其關系上進行推理,自然語言表達有相當大的模糊性,所以其推理過程一直是很難處理好的問題。 現有的工作中,記憶網絡(Memory Networks,參考文獻9)、GA Reader、Iterative Alternating神經網絡(后文簡稱IA Reader,參考文獻10)以及AMRNN都直接在網絡結構中體現了這種推理策略。一般而言,機器閱讀理解過程網絡結構中的深層網絡都是為了進行文本推理而設計的,就是說,通過加深網絡層數來模擬不斷增加的推理步驟。 圖13. 記憶網絡的推理過程 記憶網絡是最早提出推理過程的模型,對后續其它模型有重要的影響。對于記憶網絡模型來說,其第一層網絡的推理過程(Layer-Wise RNN模式)如下(參考圖13):首先根據原始問題的Word Embedding表達方式以及文檔的原始表達,通過f函數計算文檔單詞的Attention概率,然后g函數利用文章原始表達和Attention信息,計算文檔新的表達方式,這里一般g函數是加權求和函數。而t函數則根據文檔新的表達方式以及原始問題表達方式,推理出問題和文檔最終的新表達方式,這里t函數實際上就是通過兩者Word Embedding的逐位相加實現的。t函數的輸出更新下一層網絡問題的表達方式。這樣就通過隱式地內部更新文檔和顯示地更新問題的表達方式實現了一次推理過程,后續每層網絡推理過程就是反復重復這個過程,通過多層網絡,就實現了不斷通過推理更改文檔和問題的表達方式。 圖14. AMRNN的推理過程 AMRNN模型的推理過程明顯受到了記憶網絡的影響,圖14通過摒除論文中與記憶網絡不同的表面表述方式,抽象出了其推理過程,可以看出,其基本結構與記憶網絡的Layer-Wise RNN模式是完全相同的,的區別是:記憶網絡在擬合文檔或者問題表示的時候是通過單詞的Word Embedding簡單疊加的方式,而AMRNN則是采用了RNN結構來推導文章和問題的表示。所以AMRNN模型可以近似理解為AS Reader的基礎網絡結構加上記憶網絡的推理過程。 圖15.GA Reader的推理過程 GA Reader的推理過程相對簡潔,其示意圖如圖15所示。它的第一層網絡推理過程如下:其每層推理網絡的問題表達都是原始問題表達方式,在推理過程中不變。而f函數結合原始問題表達和文檔表達來更新文檔表達到新的形式,具體而言,f函數就是上文所述的被稱為Gated-Attention模型的匹配函數,其計算過程為Di和Q兩個向量對應維度數值逐位相乘,這樣形成新的文檔表達。其它層的推理過程與此相同。 圖16. IA Reader的推理過程 IA Reader的推理結構相對復雜,其不同網絡層是由RNN串接起來的,圖16中展示了從第i層神經網絡到第i+1層神經網絡的推理過程,其中虛線部分是RNN的組織結構,每一層RNN結構是由新的文檔表達和問題表達作為RNN的輸入數據。其推理過程如下:對于第i層網絡來說,首先根據RNN輸入信息,就是第i層的文檔表達和問題表達,更新隱層狀態信息;然后f函數根據更新后的隱層狀態信息以及原始的問題表達,計算問題中詞匯的新的attention信息;g函數根據新的attention信息更新原始問題的表達形式,形成第i+1層網絡的新的問題表達,g函數一般采取加權求和的計算方式;在獲得了第i+1層新的問題表達后,t函數根據第i層RNN隱層神經元信息以及第i+1層網絡新的問題表達形式,更新原始文檔表達形成第i+1層文檔的新表達形式。這樣,第i+1層的問題表達和文檔表達都獲得了更新,完成了一次推理過程。后面的推理過程都遵循如此步驟來完成多步推理。 從上述推理機制可以看出,盡管不同模型都有差異,但是其中也有很多共性的部分。一種常見的推理策略往往是通過多輪迭代,不斷更新注意力模型的注意焦點來更新問題和文檔的Document Embedding表達方式,即通過注意力的不斷轉換來實現所謂的“推理過程”。 推理過程對于有一定難度的問題來說具有很明顯的幫助作用,對于簡單問題則作用不明顯。當然,這與數據集難度有一定關系,比如研究證明(參考文獻10),CNN數據集整體偏容易,所以正確回答問題不需要復雜的推理步驟也能做得很好。而在CBT數據集上,加上推理過程和不加推理過程進行效果對比,在評價指標上會增加2.5%到5%個百分點的提升。 2.4 ?其它模型 上文對目前主流的技術思路進行了歸納及抽象并進行了技術歸類,除了上述的三種技術思路外,還有一些比較重要的工作在模型思路上不能歸于上述分類中,本節對這些模型進行簡述,具體模型主要包括EpiReader(參考文獻11)和動態實體表示模型(Dynamic Entity Representation,后文簡稱DER模型,參考文獻12)。 EpiReader是目前機器閱讀理解模型中效果較好的模型之一,其思路相當于使用AS Reader的模型先提供若干候選答案,然后再對候選答案用假設檢驗的驗證方式再次確認來獲得正確答案。假設檢驗采用了將候選答案替換掉問題中的PlaceHolder占位符,即假設某個候選答案就是正確答案,形成完整的問題句子,然后通過判斷問題句和文章中每個句子多大程度上是語義蘊含(Entailment)的關系來做綜合判斷,找出經過檢驗最合理的候選答案作為正確答案。這從技術思路上其實是采用了多模型融合的思路,本質上和多Reader進行模型Ensemble起到了異曲同工的作用,可以將其歸為多模型Ensemble的集成方案,但是其假設檢驗過程模型相對復雜,而效果相比模型集成來說也不占優勢,實際使用中其實不如直接采取某個模型Ensemble的方案更實用。 DER模型在閱讀理解時,首先將文章中同一實體在文章中不同的出現位置標記出來,每個位置提取這一實體及其一定窗口大小對應的上下文內容,用雙向RNN對這段信息進行編碼,每個位置的包含這個實體的片段都編碼完成后,根據這些編碼信息與問題的相似性計算這個實體不同語言片段的Attention信息,并根據Attention信息綜合出整篇文章中這個實體不同上下文的總的表示,然后根據這個表示和問題的語義相近程度選出最可能是答案的那個實體。DER模型盡管看上去和一維匹配模型差異很大,其實兩者并沒有本質區別,一維匹配模型在最后步驟相同單詞的Attention概率合并過程其實和DER的做法是類似的。 3、問題與展望 用深度學習解決機器閱讀理解問題探索歷史時間并不長,經過最近一年的探索,應該說很多模型相對最初的技術方案來說,在性能提升方面進展明顯,在很多數據集上性能都有大幅度的提高,甚至在一些數據集(bAbi,CNN,Daily Mail等)性能已經達到性能上限。但是總體而言,這距離讓機器像人一樣能夠理解文本并回答問題還有非常遙遠的距離。最后我們對這個研究領域目前面臨的問題進行簡述并對一些發展趨勢進行展望。 1. 需要構建更具備難度的大規模閱讀理解數據集 手工構建大規模的閱讀理解訓練數據需要花費極大成本,因此目前的不少數據集都存在一定問題。某些數據集比如MCTest經過人的精心構建,但是規模過小,很難用來有效訓練復雜模型。另外一類是采用一定的啟發規則自動構建的數據集,這類數據集數據規模可以做得足夠大,但是很多數據集失之于太過簡單。不少實驗以及對應的數據分析結果證明常用的大規模數據集比如CNN和Daily Mail 相對簡單,正確回答問題所需要的上下文很短(5個單詞窗口大小范圍)(參考文獻3),只要采取相對簡單的模型就可以達到較好的性能,復雜技術發揮不出優勢,這從某種角度說明數據集難度偏小,這也極大限制了新技術的探索。 為了能夠促進領域技術的進一步快速發展,需要一些大規模的人工構建的閱讀理解數據集合,這樣既能滿足規模要求,又能具備相當難度。類似SQuAD數據集(參考文獻13)這種采用眾包的方式制作數據集合是個比較有前途的方向,也期待更多高質量的數據集尤其是更多中文數據集的出現(哈工大在16年7月份公布了第一份中文閱讀理解數據集)。 2. 神經網絡模型偏單一 從上述相關工作介紹可以看出,目前在機器閱讀理解任務中,解決方案的神經網絡結構還比較單一,后續需要探索更多種多樣的新型網絡結構及新式模型,以促進這個研究領域的快速發展。 3. 二維匹配模型需要做更深入的探索 二維匹配模型由于引入了更多的細節信息,所以在模型性能上具備一定優勢。但是目前相關的工作還不多,而且大多集中在Attention機制的改造上。這個模型需要做更多的探索,比如匹配函數的創新、多層推理機制的引入等,我相信短期內在這塊會有很多新技術會被提出。 4. 世界知識(World Knowledge)的引入 對于人來說,如果需要真正理解一篇新的文章,除了文章本身提供的上下文外,往往需要結合世界知識,也就是一些常識或者文章相關的背景知識,才能真正理解內容。目前機器閱讀理解任務為了降低任務難度,往往將世界知識排除在任務之外,使得閱讀理解任務更單純,這在該領域研究初期毫無疑問是正確的思路,但是隨著技術發展越來越完善,會逐漸引入世界知識來增強閱讀理解任務的難度,也和人類的閱讀理解過程越來越相似。 5. 發展更為完善的推理機制 在閱讀一篇文章后,為了能夠回答復雜的問題,設計合理的推理機制是閱讀理解能力進行突破的關鍵技術,如上文所述,目前的推理機制大多數還是采用注意力焦點轉移的機制來實現,隨著復雜數據集的逐漸出現,推理機制會在閱讀理解中起到越來越重要的作用,而今后需要提出更加豐富的推理機制。 參考文獻 [1] Karl Moritz Hermann, Tomas Kocisky, Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Suleyman,and Phil Blunsom. 2015. Teaching machines to read and comprehend. In Proc. of NIPS, pages 1684–1692. ? [2] Rudolf Kadlec, Martin Schmid, Ondrej Bajgar, andJan Kleindienst. 2016. Text understanding with the attention sum reader network. tarXiv:1603.01547. ? [3] Danqi Chen, Jason Bolton, and Christopher D. Manning.2016. A thorough examination of the cnn / daily mail reading comprehension task. In Proc. of ACL. ? [4] Bhuwan Dhingra, Hanxiao Liu, William W Cohen, and Ruslan Salakhutdinov. 2016. Gated-attention readers for text comprehension. arXiv preprint arXiv:1606.01549 ? [5] Bo-Hsiang Tseng, Sheng-Syun Shen, Hung-Yi Lee and Lin-Shan Lee,2016. Towards Machine Comprehension of Spoken Content:Initial TOEFL Listening Comprehension Test by Machine. arXiv preprint arXiv: 1608.06378 ? [6] Yiming Cui, Ting Liu, Zhipeng Chen, Shijin Wang, and Guoping Hu. 2016. Consensus attention-based neural networks for chinese reading comprehension. arXiv preprint arXiv:1607.02250. ? [7] Yiming Cui, Zhipeng Chen, Si Wei, Shijin Wang, Ting Liu and Guoping Hu.2016. Attention-over-Attention Neural Networks for Reading Comprehension. arXiv preprint arXiv: 1607.04423v3. ? [8] Shuohang Wang and Jing Jiang.2016. Machine Comprehension Using Match-LSTM and Answer Pointer. arXiv preprint arXiv: 1608.07905 ? [9] Sainbayar Sukhbaatar, Jason Weston, Rob Fergus, et al.2015. End-to-end memory networks. In Proc. of NIPS,pages 2431–2439. ? [10] Alessandro Sordoni, Phillip Bachman, and Yoshua Bengio. 2016. Iterative alternating neural attention for machine reading. arXiv preprint arXiv:1606.02245. ? [11] Adam Trischler, Zheng Ye, Xingdi Yuan, and Kaheer Suleman. 2016. Natural language comprehension with theepireader. arXiv preprint arXiv:1606.02270 ? [12] Sosuke Kobayashi, Ran Tian,Naoaki Okazaki, and Kentaro Inui. 2016. Dynamic entity representations with max-pooling improves machine reading. In NAACL-HLT. ? [13] Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. SQuAD: 100,000+ questionsfor machine comprehension of text. In Proceedings of the Conference on Empirical Methods inNatural Language Processing, 2016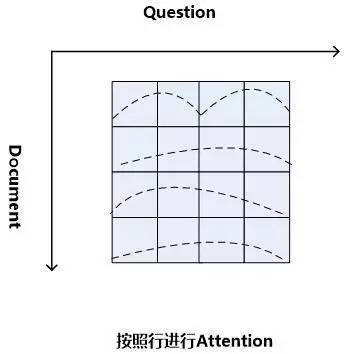
商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/4419.html
摘要:本文著重以人臉識別為例介紹深度學習技術在其中的應用,以及優圖團隊經過近五年的積累對人臉識別技術乃至整個人工智能領域的一些認識和分享。從年左右,受深度學習在整個機器視覺領域迅猛發展的影響,人臉識別的深時代正式拉開序幕。 騰訊優圖隸屬于騰訊社交網絡事業群(SNG),團隊整體立足于騰訊社交網絡大平臺,專注于圖像處理、模式識別、機器學習、數據挖掘、深度學習、音頻語音分析等領域開展技術研發和業務落地。...
摘要:深度學習自動找到對分類重要的特征,而在機器學習,我們必須手工地給出這些特征。數據依賴深度學習和傳統機器學習最重要的區別在于數據量增長下的表現差異。這是深度學習一個特別的部分,也是傳統機器學習主要的步驟。 前言 機器學習和深度學習現在很火!突然間每個人都在討論它們-不管大家明不明白它們的不同! 不管你是否積極緊貼數據分析,你都應該聽說過它們。 正好展示給你要關注它們的點,這里...

閱讀 651·2021-11-23 09:51
閱讀 3598·2021-11-15 11:38
閱讀 926·2021-10-14 09:42
閱讀 3160·2021-09-29 09:35
閱讀 2104·2021-09-03 10:33
閱讀 769·2021-07-30 16:33
閱讀 1557·2019-08-30 15:55
閱讀 1840·2019-08-30 14:04



