Flink,Spark,Storm,Hadoop大數據框架比較
點擊上方“IT那活兒”,關注后了解更多精彩內容!!!
大數據分析作為一種用于分析大量按需數據的工具,越來越受到人們的歡迎。四個最常見的大數據處理框架包括Apache Hadoop,Apache Spark,Apache Storm和Apache Flink。雖然這四個都支持大數據處理,但是這些框架的用法和支持該用法的基礎體系結構不同。許多研究已經投入了時間和精力來通過評估已定義的關鍵績效指標(KPI)來比較這些大數據框架。本文通過確定一組通用的關鍵性能指標來總結這些早期工作,這些關鍵性能指標包括處理時間,CPU消耗,延遲,吞吐量,執行時間,可持續的輸入速率,任務性能,可伸縮性和容錯能力,并比較這四個大數據通過文獻綜述了解這些KPI的框架。與Apache Hadoop和Apache Storm框架相比,在非實時數據中Spark為多個KPI(包括處理時間,CPU消耗,延遲,執行時間,任務性能和可伸縮性)的贏家。在流處理中Flink與Apache Spark和Apache Storm框架相比,Flink在處理時間,CPU消耗,延遲,吞吐量,執行時間,任務性能,可伸縮性和容錯能力方面最適合流處理。本文分為以下幾部分:下一部分將解釋大數據的主要特征,稱為大數據的維度。接下來是對一些大數據框架的討論。Hadoop,Spark,Storm和Flink。它們的類別將作為框架和所得結果之間的比較研究而呈現。之后,我們給出一些結論。
當我們在上一階段定義了大數據的含義時,現在說明其特征非常重要。它由通用的大數據需求(volume(容量), variety (多樣性) , and velocity (速度))組成,這些需求統稱為3維。最近,大數據的特性從3維演變為6維度,增加了value (價值), veracity (準確性), 和variability (可變性) 的特征。圖1 中顯示了6維的大數據。
圖1
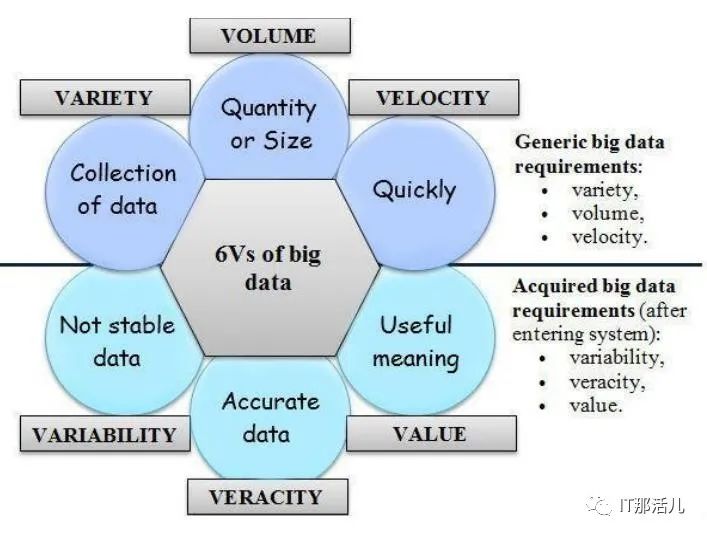 譯者注:Volume(指數據量大)、Velocity(指數據量增加速度快)、Variety(指數據種類多樣)、Value(指數據價值密度)、Veracity(指數據真實性)、 variability(指數據源穩定性)。
譯者注:Volume(指數據量大)、Velocity(指數據量增加速度快)、Variety(指數據種類多樣)、Value(指數據價值密度)、Veracity(指數據真實性)、 variability(指數據源穩定性)。A. Volume(容量)
Volume 是指數據的數量或大小。大數據的大小約為TB,PB(PB),Zettabyte(ZB)和Exabyte(EB)。Facebook,YouTube,Google和NASA等組織擁有大量數據,這給存儲,檢索,分析和處理這些數據帶來了新的挑戰。大數據而非傳統存儲的使用改變了我們傳輸數據和使用數據的方式。B. Variety (多樣性)
多樣性是指正在生成的不同類型的數據。可以使用不同的維度來衡量類型(例如結構,使我們能夠區別結構化,半結構化和非結構化數據,或批處理與流處理的處理量)C. Variability (可變性)
可變性是指不穩定,難以處理且難以管理的數據。解釋可變數據對研究人員來說是一個重大問題。D. Velocity (速度)
是指大數據以多快的速度生成,以便進行操縱,交換,存儲和分析。由于涉及的高成本,速度對數據科學家提出了新的研究挑戰。當用戶需要檢索或處理數據并且處理速度不夠快時,數據就被遺忘了。E. Veracity (準確性)
準確性是指正在處理的數據的質量。數據源的準確性還取決于分析數據準確性。F. Value (價值)
價值是指數據帶來的目的或業務成果,以促進決策過程。
本文比較的四個框架在它們支持的功能和底層體系結構方面彼此不同,同時將支持大數據處理的主要目的保留在其核心。本節概述了這四個大數據處理框架的體系結構。
A. Hadoop
在2008年,Doug Cutting和Mike Cafarella將Apache Hadoop定義為一個開源框架,該框架通過一組稱為群集或節點的主機(硬件層)收集和處理分布式數據。它提供的是分發服務機器,而不是一項服務。因此,它們可以通過使用群集或節點并行工作。 圖2 說明了Hadoop框架的三個主要層。第一個是用于收集數據的數據存儲層,其中包含Hadoop分布式文件系統(HDFS)。第二層是YARN基礎結構,它提供用于作業調度的算術資源,例如CPU和內存。第三個是MapReduce,它用于與其他進程一起處理數據(軟件層)。圖2
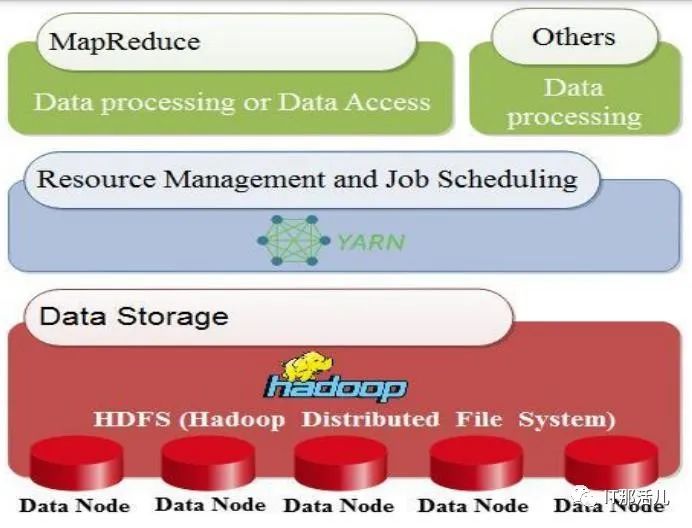 Fig. 2. Hadoop Architecture Adapted 許多公司,企業和組織使用Apache Hadoop的主要原因有兩個。首先,進行學術或科學研究。其次,進行分析以滿足客戶的需求并幫助組織做出正確的決定。例如,當組織需要知道客戶需要哪種產品時。然后,它可以產生大量所需的產品,這是Apache Hadoop的幾種應用程序之一。
Fig. 2. Hadoop Architecture Adapted 許多公司,企業和組織使用Apache Hadoop的主要原因有兩個。首先,進行學術或科學研究。其次,進行分析以滿足客戶的需求并幫助組織做出正確的決定。例如,當組織需要知道客戶需要哪種產品時。然后,它可以產生大量所需的產品,這是Apache Hadoop的幾種應用程序之一。B. Spark
Apache Spark是在加州大學伯克利分校建立的開源框架。它在2013年成為Apache項目,通過大規模數據處理提供更快的服務。Spark框架對Hadoop而言就像MapReduce對數據處理和HDFS一樣。此外,Spark具有數據共享功能,稱為彈性分布式數據集(RDD)和有向無環圖(DAG)。圖3表示Spark架構,它非常容易且快速地選擇大量數據處理。Spark主要由五層組成。第一層包括數據存儲系統,例如HDFS和HBASE。第二層是資源管理;例如YARN和Mesos。第三個是Spark核心引擎。第四個是一個庫,由SQL,流處理,用于機器學習的MLlib,Spark R和用于圖形處理的GraphX組成。最后一層是應用程序接口,例如Java或Scala。通常,Spark提供了一種大型數據處理框架,供銀行,電信公司,游戲公司,政府以及Apple,Yahoo和Facebook等公司使用。圖3
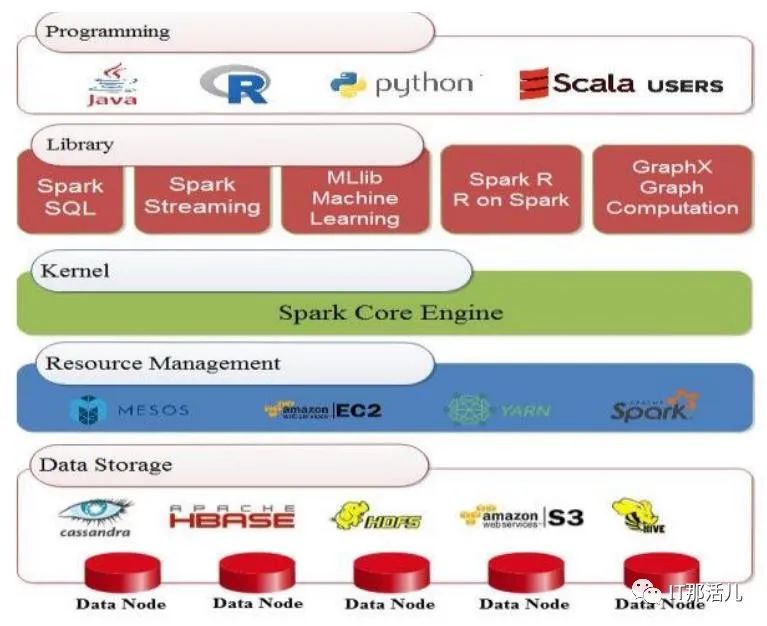 Fig. 3. Spark Architecture Adapted
Fig. 3. Spark Architecture Adapted C. Storm
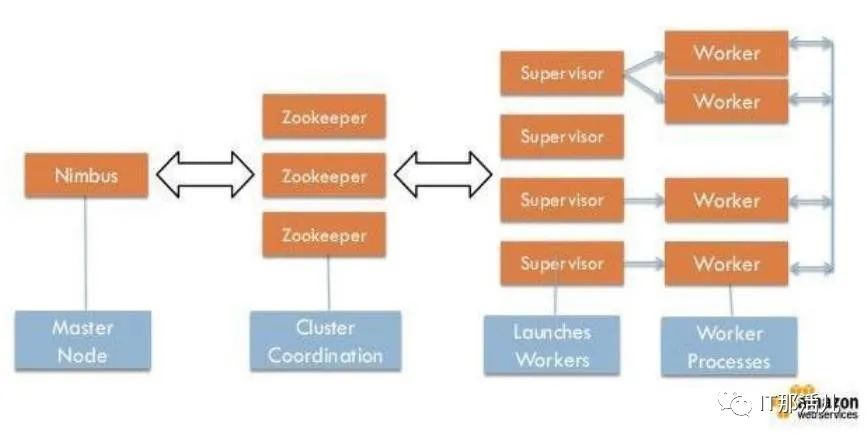
Storm引擎是一個開放源代碼框架,旨在實時處理流數據。它是用Clojure語言編寫的。圖4顯示Storm可以在任何程序語言和任何應用程序開發平臺上使用。因此,它保證了數據不會丟失。圖5說明了兩種類型的節點:第一種是主節點,第二種是工作節點。主節點用于監視故障,承擔分布式節點的責任并為每臺計算機指定每個任務。所有這些任務統稱為Nimbus,類似于Hadoop的Job-Tracker。工作節點稱為主管。當Nimbus為它分配特定的進程時,它將起作用。因此,拓撲的每個子過程都可與許多分布式計算機一起使用。Zookeeper扮演Nimbus與主管之間的協調員。更重要的是,如果任何集群出現故障,它將把任務重新分配給另一個任務。因此,從節點控制自己任務的執行。圖4
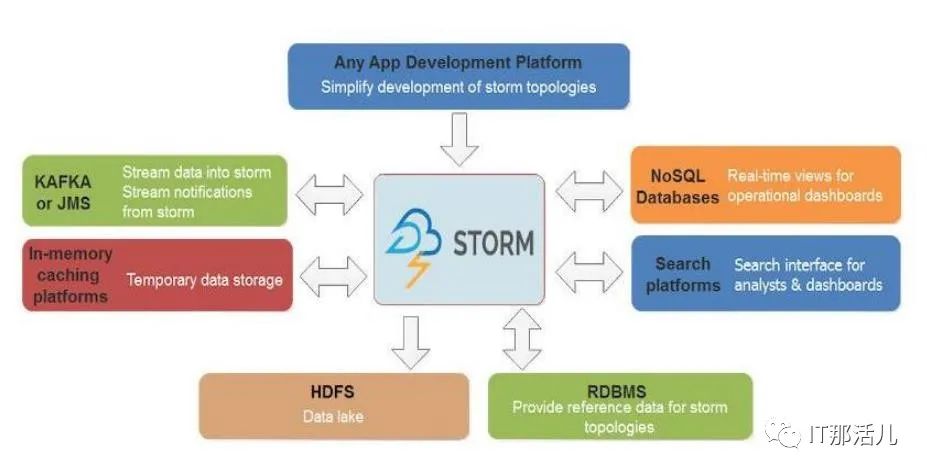 Fig. 4. Storm Architecture圖5
Fig. 4. Storm Architecture圖5
D. Flink
Apache Flink 是由三所德國大學于2010年創建的開源框架,已被有效地用于實時和批處理模式下的數據處理。它使用內存中處理技術,并提供了許多用于查詢的API,例如流處理API(數據流),批處理API(數據集)和表API。它還具有機器學習(ML)和圖形處理(Gelly)庫。圖6展示了Flink的體系結構。在基礎層中,存儲層可以從多個目標(例如HDFS,本地文件等)讀取和寫入數據。然后,部署和資源管理層包含用于管理計劃任務,監視作業和管理資源的群集管理器。該層還包含執行程序的環境,即集群或云環境。同時,它還支持單個Java虛擬機的本地部署。此外,它還具有用于實時處理的分布式流數據流引擎的內核層。此外,應用程序還具有用于兩個過程的接口層:批處理和流傳輸。上層是一個使用Java或Scala編程語言編寫程序的庫。然后在Flink優化器的幫助下將其提交給編譯器進行轉換,以提高其性能。圖6
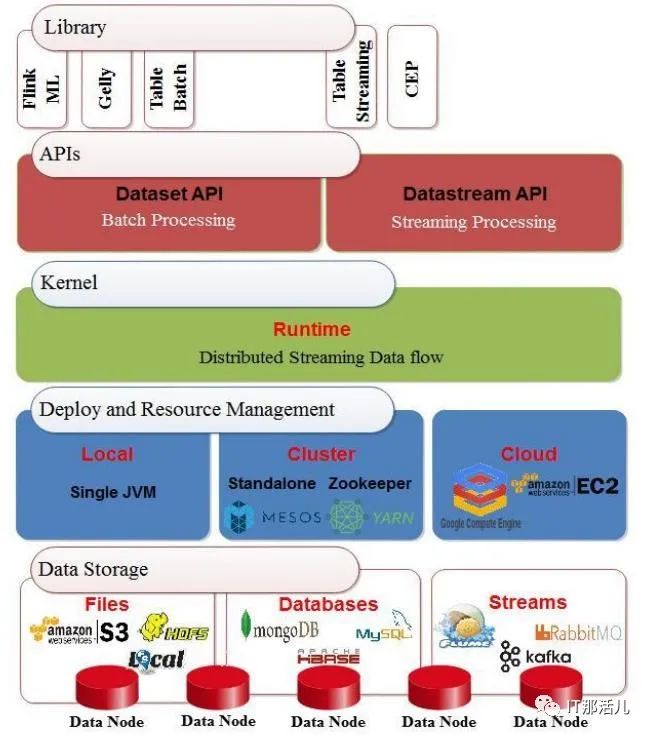 Fig. 6. Flink Architecture Adapted
Fig. 6. Flink Architecture Adapted
我們研究中的每個大數據框架都支持一組功能,這些功能也可以用作關鍵績效指標。在本節中,我們將介紹通過文獻綜述確定的一組通用功能,并比較這些功能中的四個框架。
A. Scalability(可伸縮性)
可伸縮性是系統響應不斷增加的負載量的能力。它有兩種類型:(縱向)擴展和(橫向)擴展。向上擴展用于升級硬件配置,而向外擴展用于添加額外的硬件。我們研究中的所有四個框架都是水平可擴展的。這意味著我們可以根據需要在集群中添加許多節點。B. Message Delivery Guarantees(消息傳遞保證)
失敗時將使用消息傳遞保證。根據上面提到的四個框架,它可以分為兩種類型:exactly once(恰好一次)和atleast-once(至少一次)。exactly once(恰好一次)傳遞意味著該消息將不會重復,也不會丟失,并且將精確地傳遞給收件人一次。另一方面,atleast-once(至少一次)傳遞意味著有很多傳遞消息的嘗試,并且這些嘗試中的至少一個成功。此外,該消息可以重復而不會丟失。C. Computation Mode(計算模式)
計算模式可以是內存中計算,也可以是更傳統的模式,在該模式下,計算結果將寫回到磁盤上。內存中計算速度更快,但存在潛在的缺點,即在關閉計算機的情況下丟失內容。D. Auto-Scaling(自動擴展)
E. Iterative Computation(迭代計算)
迭代計算是指迭代方法的實現,該迭代方法在沒有實際解的情況下或在實際解的成本過高的情況下估計近似解。表I對大數據框架某些特征進行了匯總:表I: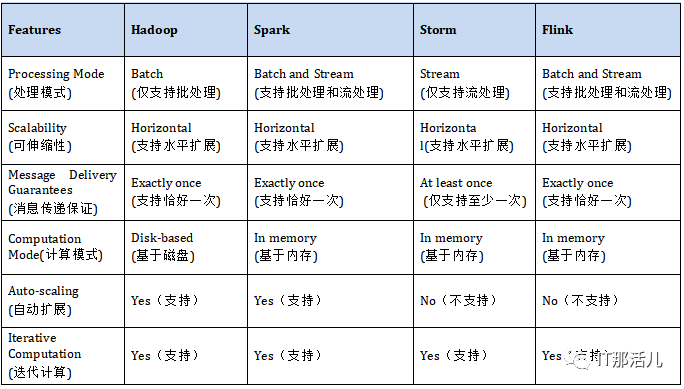
本節介紹現有文獻,比較上述四個大數據處理框架。通過文獻,我們確定了九種不同的關鍵性能指標,即處理時間,CPU消耗,延遲,吞吐量,執行時間,可持續的輸入速率,任務性能,可伸縮性和容錯能力。
A. Processing Time (處理時間)
許多現有研究已通過處理時間評估了大數據框架的性能。進行了一項采用該措施作為關鍵績效指標的工作。這項研究使用了個性化的監視工具來監視資源使用情況,并使用Python腳本來檢測計算機的狀態。在批處理模式實驗中,研究人員包含了100億條推文的數據集,而在流模式實驗中,他們收集了10億條推文。在批處理模式下,他們評估了數據大小和使用的群集對處理時間的影響。關于數據大小,研究發現Spark的速度比Hadoop和Flink的速度快,而Flink的速度最慢。他們還注意到,僅當數據集較小(小于5 GB)時,Flink才比Hadoop更快。實際上,與避免輸入/輸出操作的Spark相比,Hadoop通過訪問HDFS來傳輸數據。因此,在這種情況下,處理時間受到輸入/輸出操作量的影響,因此,當處理大量數據時,處理時間增加。另一方面,關于所用集群的大小,該研究表明,Hadoop和Flink比Spark需要更長的時間,因為Spark中作業的執行受處理器數量和對Linux的讀寫操作量的影響RAM,而不是磁盤使用,例如Hadoop。在流模式實驗中,研究人員通過評估窗口時間對已處理事件數的影響來研究處理速率。他們證明,在每條消息發送100 KB的推文的情況下,Flink和Storm具有最好的處理速度,優于Spark。這是因為這些框架為窗口時間使用了不同的值。Flink和Storm使用毫秒,而Spark使用秒。另一方面,在每條消息發送五個500KB的tweet時,Flink的工作效率比Storm和Spark高。此外,在進行的一項研究中,作者根據亞馬遜網站上的電子商務數據評估了Flink和Spark的性能。他們使用的數據集為JSON格式。每條記錄具有固定數量的字段,一條記錄的平均大小為3000字節。他們發現使用Flink處理數據的平均時間為240.3秒,而Spark則為60.4秒。因此,Spark的性能比Flink更好,約為179.5%。B. CPU Consumption(CPU消耗)
許多人已經使用CPU消耗來評估大數據框架的性能。在進行的一項研究中,發現在批處理模式下,Flink使用的資源少于Hadoop和Spark。這是因為與Spark和Hadoop相比,Flink會部分利用磁盤和內存資源。此外,基于流模式,研究發現Flink在CPU消耗方面低于Spark和Storm,因為與Storm相比,Flink主要用于處理大型消息。Spark每秒收集一次事件,然后執行任務。因此,將處理多個消息,結果導致CPU使用率高。研究中,使用Yahoo流基準測試(YSB)和三個數據流框架-Spark,Storm和Flink-進行實驗。實驗發現,與其他框架相比,Storm具有最高的CPU資源使用率。此外,進行的一項研究發現,Apache Spark達到大約100%的CPU利用率,而Apache Flink使用更少的CPU資源執行相同的負載。C. Latency(延遲)
延遲是評估大數據框架性能的另一重要性能指標。例如,使用來自監視攝像機的數據集,其中包括1595個不同人的3425個視頻,使用RAM3S框架比較了Spark,Storm和Flink的性能。研究人員在本地環境以及Google Cloud平臺上實施了他們的實驗。當本地集群和云的節點數量變化時,Apache Storm達到了最低的延遲,并且與Flink延遲非常相似。但是,由于其微批處理設計,Spark獲得了最高的延遲。此外,進行的一項研究發現,只有在可以接受高延遲的情況下,Spark才能勝過Flink。另外,使用RAM3S框架比較Storm,Spark和Flink中大量多媒體流的實時分析。他們使用了YouTube面孔數據集(YTFD),其中包括來自1595個不同人群的3425個視頻和不同的視頻分辨率,其中480360最常見,總共621、126幀,平均連接的人臉最少每個視頻181.3幀。他們證明,Storm和Flink的效果比Spark稍好。另一項研究基于兩組數據集(即3000個良性和500個異常)比較了Spark和Storm。第一個數據集來自VMware中的Spark集群(D1),第二個數據集來自Yahoo Cloud Serving Benchmark(YCSB),可預測異常(D2)。作者完成了在不同VM和單個VM中測試數據的工作。他們發現,在所有情況下,Spark的平均延遲都小于Storm。D. Throughput(吞吐量)
吞吐量是已用于評估大數據框架性能的另一種度量。例如,發現Spark的吞吐量要比Storm和Flink低,然而,研究人員證明,當Spark的批處理間隔較長時,吞吐量會更高。此外,在使用云環境的情況下,Storm和Flink的效果略好于Spark,而沒有考慮構建D-stream所需的時間。E. Execution Time (執行時間)
使用執行時間來評估和比較Hadoop,Spark和Flink框架的性能。他們使用大數據評估工具(BDEv)在DAS-4上進行了實驗,以自動化框架的配置。實驗指出,將Spark和Flink替換為Hadoop,當使用49個節點時,平均執行時間分別減少77%和70%。工作中,研究人員使用開源數據集評估了SparkCount和Hadoop在WordCount和Logistic回歸程序方面的性能,該數據集包括各種公司的破產預測。他們的結果表明,Spark中WordCount程序的執行時間少于Hadoop。此外,在Spark中執行邏輯回歸程序的時間少于Hadoop。例如,如果迭代次數為100,則Spark中的執行時間為3.452秒;對于Hadoop,為9.383秒。因此,Spark在WordCount和Logistic回歸方面均勝過Hadoop。原因之一是,在Spark的內存存儲中使用緩存使過程更快。此外基于WordCount程序使用Spark和MapReduce框架對性能進行了測量,該框架運行在安裝在Ubuntu機器上的單節點Hadoop(HDFS)上。他們使用了大文本文件形式的數據集,其中包含客戶對多種產品的評論和反饋,并將該文件分配為不同的大小。與MapReduce編程框架相比,Spark的執行速度大約是三到四倍。比較使用Karamel(Web應用程序)的Spark和Flink框架,以便評估系統級別和應用程序級別的性能。使用了TeraSort應用程序生成并使用HDFS存儲的數據,以及各種輸入級別(200GB,400GB和600GB)。研究人員發現Flink減少了執行時間,比Terasort應用程序的Spark快1.5倍。F. Sustainable Input Rate(可持續的輸入速率)
使用可持續輸入率作為比較大數據框架的績效指標。當本地集群和云的計算節點數量發生變化時,將使用此度量。Storm在兩種情況下(本地和云)都優于Flink和Spark。此結果是由于Storm使用的最簡單的一次語義(atleast-once 至少一次),而在Flink中,是exactly once(恰好一次)。另外,Storm的拓撲是由程序員定義的,而在Flink中,它是由優化器定義的。這導致Flink的效率降低。另一方面,Spark并非主要設計為流引擎。因此,這也是輸入速率較低的原因之一。G. Task Performance (任務性能)
研究比較大數據框架在許多給定任務上的性能,這些任務包括WordCount,k-means,PageRank,Grep,TeraSort和connected components。研究發現,與Flink和Hadoop相比,Spark在WordCount和k-means方面表現最佳,而Flink對于PageRank則取得了更好的結果。另一方面,Flink和Spark在Grep,TeraSort和connected components上均取得了相同的結果,并且在這些方面均勝過Hadoop。導致WordCount結果的一種解釋是,求每個單詞出現的次數和,Spark使用reduceByKey()函數與flink中優化程度較低的groupBy()。sum()函數的Flink相比,所以WordCount性能測試中Spark超越Flink。在Grep中,Spark和Flink的性能要優于Hadoop,因為Hadoop使用一個MapReduce搜索模式,然后使用另一個對結果進行排序。這導致大量的內存復制和寫入HDFS。在PageRank中,Flink獲得了最佳性能,因為它使用的增量迭代僅處理尚未達到最終值的元素。H. Scalability(可伸縮性)
在衡量可擴展性方面,將運營商的執行計劃(端到端執行時間)與資源使用和參數配置聯系在一起,以衡量Spark和Flink的性能。結果表明,Spark比Flink快大約1.7倍,特別是在大型圖數據處理中。相比之下,在具有大型數據集和固定節點的情況下,Flink更好,其性能比Spark高出10%。I. Fault Tolerance(容錯)
關于容錯度量, 進行的研究指出,Flink具有比Storm和Spark框架更高的容錯能力。總體而言,這里回顧的所有研究都表明,與Hadoop和Flink相比,Spark在processing time(處理時間)方面是最快的。同樣在延遲方面,Spark也是最低的。此外,與Hadoop和Flink相比,Spark在Throughput(吞吐量)和execution time(執行時間)方面是最好的。同樣在WordCount和k-means方面,它比Flink和Hadoop更好。此外,在Grep,TeraSort和Connected Components方面,它比Hadoop也更好。此外,就可伸縮性而言,與Flink相比,Spark在大型圖計算的情況下更好。與Storm和Spark相比,Flink在processing time(處理時間)方面效率更高。另外,在使用云環境的情況下,它在Throughput(吞吐量)方面更有效,而無需考慮構建d-stream的時間。除此之外,僅在使用Karamel和TeraSort應用程序的情況下,與Spark相比,execution time(執行時間)更短。此外,就PageRank而言,與Spark和Hadoop相比,它是最好的。此外,就Grep,TeraSort和Connected Components而言,它比Hadoop更好。就可伸縮性而言,只有在數據集很大且節點數量固定的情況下,與Spark相比才是最好的。同樣,在容錯方面,它比Storm和Spark好。Storm在CPU利用率方面與Spark,Flink和Hadoop框架相比性能最佳。此外,與Spark和Flink相比,它具有最低的延遲。另外,僅在使用云環境的情況下,它才具有最佳吞吐量,而無需考慮構建d-stream所需的時間。而且,與Flink和Spark相比,它具有更好的可持續輸入速率。表II四個大數據框架比較的文獻綜述。表II: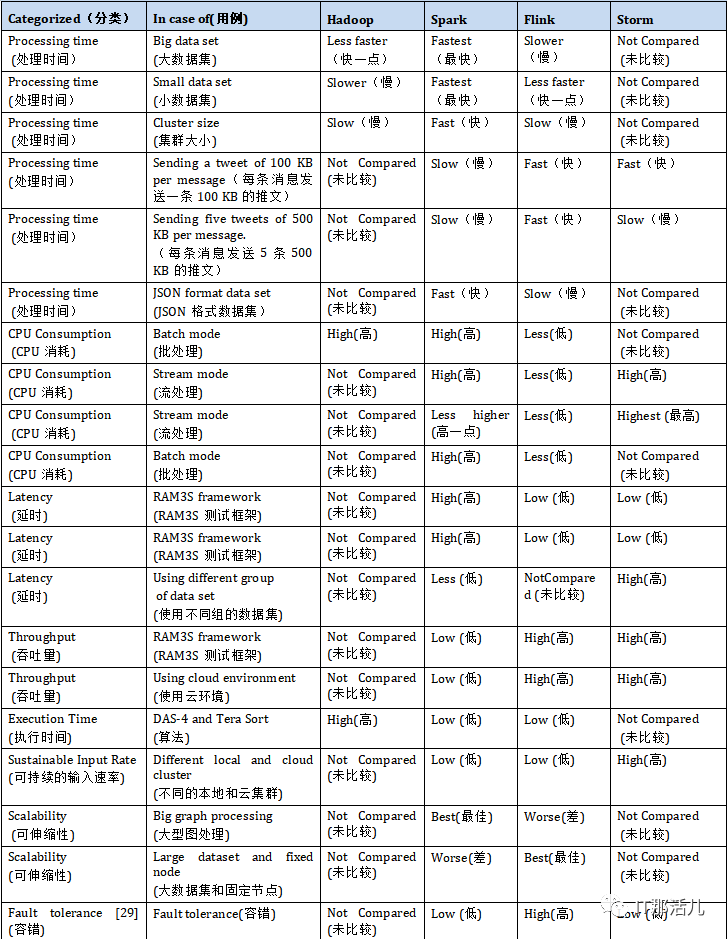
這項研究的結果表明,與其他框架相比,Flink表現最佳,因為它在八項指標中均達到了最佳性能。Spark在六個方面優于其他框架,Storm在四個方面優于其他框架。因此,公司,研究人員以及對該領域感興趣的個人的用戶可以根據他們希望使用的關鍵績效指標來選擇合適的框架,以便分析數據并獲得有效的結果。最后,他們將獲得高性能的計算(HPC)。
將來,通過在四個框架的性能中考慮這些度量,可以以任何對獲得HPC影響不大的度量來增強每個框架的機會。因此,我們希望看到其中一些框架有所增強,同時還包括能夠提供高性能的其他框架。
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/129749.html




