ElasticSearch全文搜索進(jìn)階
點(diǎn)擊上方“IT那活兒”,關(guān)注后了解更多內(nèi)容,不管IT什么活兒,干就完了!!!
索引(index) -- Elasticsearch通過索引的方式對(duì)邏輯數(shù)據(jù)進(jìn)行邏輯存儲(chǔ)。索引類似于關(guān)系型數(shù)據(jù)庫中的表,索引的結(jié)構(gòu)是為了進(jìn)行快速有效的全文索引,索引不保存原始值。可將索引多帶帶放在一臺(tái)主機(jī)或分散在多個(gè)主機(jī)上,每個(gè)索引至少有一個(gè)或多個(gè)分片,每個(gè)分片可以有多個(gè)副本。
文檔?????????????????? -- 文檔是存儲(chǔ)在Elasticsearch中的主要實(shí)體,一個(gè)文檔就是索引所對(duì)應(yīng)的一條記錄。Elasticsearch的文檔有不同的結(jié)構(gòu),但相同的字段必須是相同類型。文檔可以有多個(gè)字段,每個(gè)字段可能在一個(gè)文檔中多次出現(xiàn),這類字段稱為多值字段。字段的類型可以是數(shù)值、文本或日期,復(fù)雜類型的字段可以包含其他文檔或數(shù)組。映射 -- 文檔寫進(jìn)索引前需要進(jìn)行分析,即寫入的文本如何分割為詞條、詞條是否又會(huì)被過濾,這樣的分析行為就是映射,映射規(guī)則一般由用戶自定義。 非結(jié)構(gòu)化索引即不需要?jiǎng)?chuàng)建索引結(jié)構(gòu)既可寫入數(shù)據(jù)到索引中,但實(shí)際上在Elasticsearch底層會(huì)進(jìn)行結(jié)構(gòu)化操作,如下示例創(chuàng)建空索引。2.2 不指定id插入數(shù)據(jù),則會(huì)自動(dòng)生成id。 更新文檔時(shí)的數(shù)據(jù)其實(shí)是不會(huì)被修改的,而是通過覆蓋的形式進(jìn)行更新,即更新文檔的版本號(hào),版本號(hào)+1。如下查看結(jié)果數(shù)據(jù)已更新: 同樣也可以局部更新數(shù)據(jù),即更新文檔中的指定字段。更新時(shí),先查詢這個(gè)文檔的數(shù)據(jù),然后進(jìn)行覆蓋操作。步驟為:先從舊文檔中檢索、修改、刪除舊文檔、索引新文檔。如下,通過_update標(biāo)識(shí)局部更新數(shù)據(jù): 通過DELETE可以刪除文檔數(shù)據(jù),文檔刪除后并不會(huì)立即從磁盤移除,而是將狀態(tài)標(biāo)記為已刪除,Elasticsearch會(huì)在滿足特定條件后自動(dòng)進(jìn)行已刪除內(nèi)容的清理。如下返回信息中result:deleted即已刪除,同時(shí)_version也+1了。5.1 搜索全部數(shù)據(jù),默認(rèn)返回10條數(shù)據(jù)記錄。5.2 通過關(guān)鍵字搜索數(shù)據(jù)。 5.3 GET方式通過id搜索數(shù)據(jù)。 DSL(Domain Specific Language)是Elasticsearch提供的查詢語言,支持復(fù)雜、強(qiáng)大的查詢,DSL以JSON請(qǐng)求體的形式進(jìn)行查詢。 全文搜索,查詢firstname為Blake或Vera的員工。 Elasticsearch也支持聚合操作,類似SQL中的group by操作。如下對(duì)age字段進(jìn)行聚合操作,31歲的員工有61位,39歲的員工有60位。
1. routing -- 當(dāng)文檔在集群中保存時(shí),文檔應(yīng)該存儲(chǔ)在哪個(gè)節(jié)點(diǎn)呢?隨機(jī)還是輪詢?Elasticsearch采用如下計(jì)算方式來確定文檔應(yīng)該存儲(chǔ)到的節(jié)點(diǎn)位置。計(jì)算公式:Shard = hash(routing) % number_of_primary_shardsRouting值可以是任意字符串,默認(rèn)是_id,也可以自定義。Routing字符串通過hash函數(shù)生成一個(gè)數(shù)字,然后除以主分片的數(shù)量得到一個(gè)余數(shù),余數(shù)的范圍是0到number_of_primary_shards-1,這個(gè)數(shù)字就是文檔所存儲(chǔ)的節(jié)點(diǎn)位置。2. 寫操作 -- 索引的新建、刪除都是寫操作,必須在主分片上成功執(zhí)行才可復(fù)制到副分片上。下圖展示了在主副分片上新建索引和刪除文檔的必要步驟:1)客戶端向NODE1節(jié)點(diǎn)發(fā)送新建索引或刪除文檔的請(qǐng)求。2)NODE1節(jié)點(diǎn)使用文檔的_id確定文檔屬于分片0,分片0存放在NODE3節(jié)點(diǎn),于是將請(qǐng)求轉(zhuǎn)發(fā)到NODE3節(jié)點(diǎn)上。NODE3在主分片上執(zhí)行請(qǐng)求,執(zhí)行成功后就轉(zhuǎn)發(fā)請(qǐng)求到NODE1和NODE2的副節(jié)點(diǎn)上。當(dāng)所有的副節(jié)點(diǎn)執(zhí)行成功,NODE3返回執(zhí)行成功到請(qǐng)求節(jié)點(diǎn),請(qǐng)求節(jié)點(diǎn)在返回給客戶端。客戶端收到執(zhí)行成功后,文檔的修改已應(yīng)用于所有的主分片,即修改生效。3. 搜索單個(gè)文檔 -- 文檔可以從主副分片中檢索,讀請(qǐng)求時(shí),為了負(fù)載的均衡,請(qǐng)求節(jié)點(diǎn)會(huì)將請(qǐng)求發(fā)送到不同的分片,即循環(huán)遍歷所有的分片副本。當(dāng)一個(gè)文檔已在主分片上保存,但同步到副分片還未完成,此時(shí)搜索該文檔時(shí),副分片返回文檔未找到,主分片成功返回文檔。 1)客戶端向NODE1節(jié)點(diǎn)發(fā)送get請(qǐng)求。 2)NODE1節(jié)點(diǎn)通過_id確定文檔屬于分片0,分片0在三個(gè)節(jié)點(diǎn)上都存在,將請(qǐng)求轉(zhuǎn)發(fā)到NODE2節(jié)點(diǎn)。 3)NODE2節(jié)點(diǎn)返回文檔給NODE1節(jié)點(diǎn),NODE1節(jié)點(diǎn)返回文檔給客戶端。4. 全文搜索 -- 文檔通常分散在各個(gè)節(jié)點(diǎn)上,如何在分布式的情況下進(jìn)行全文搜索。通常分為兩個(gè)階段:搜索和取回。
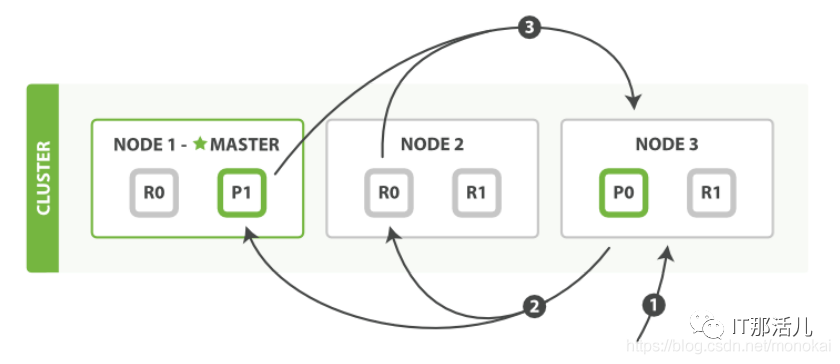
4.1 搜索過程:
1)客戶端發(fā)送搜索請(qǐng)求到NODE3,NODE3創(chuàng)建長度為from+size的空優(yōu)先級(jí)隊(duì)列。
2)轉(zhuǎn)發(fā)搜索請(qǐng)求到索引中每個(gè)主副分片,每個(gè)分片在本地執(zhí)行查詢,并將查詢結(jié)果放到from+size的有序本地優(yōu)先級(jí)隊(duì)列中。
3)每個(gè)分片向NODE3節(jié)點(diǎn)返回文檔的id和優(yōu)先級(jí)隊(duì)列中所有文檔的排序值,NODE3把這些排序值合并到自己的優(yōu)先級(jí)隊(duì)列中并產(chǎn)生全局的排序結(jié)果。
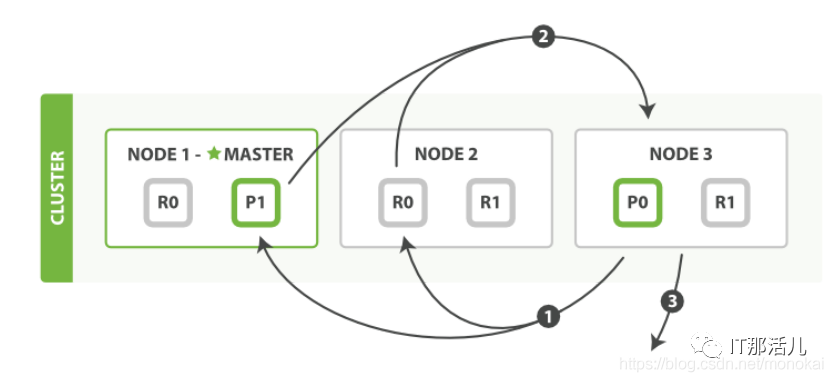
4.2 取回過程:
1)協(xié)調(diào)節(jié)點(diǎn)識(shí)別出需要取回的文檔,并且向相關(guān)分片發(fā)出get請(qǐng)求。
2)每個(gè)分片加載文檔并返回給協(xié)調(diào)節(jié)點(diǎn)。
3)直到所有的文檔都被取回,協(xié)調(diào)節(jié)點(diǎn)將結(jié)果返回給客戶端。
1. 元數(shù)據(jù) -- 文檔中不僅有數(shù)據(jù),還有關(guān)于文檔信息的元數(shù)據(jù),元數(shù)據(jù)包括三個(gè)節(jié)點(diǎn)信息,分別是 _index、_type、_id。_index:即文檔存儲(chǔ)的位置。
實(shí)際上,數(shù)據(jù)是存儲(chǔ)和索引在分片上,索引是把分片組織在一起的邏輯空間。
_type:即文檔類型。
可以使用對(duì)象來表示一些事物,每個(gè)對(duì)象都屬于一個(gè)類,類定義了屬性或與對(duì)象關(guān)聯(lián)的數(shù)據(jù)。Elasticsearch使用相同類型的文檔表示相同的事物,因?yàn)槠鋽?shù)據(jù)結(jié)構(gòu)是相同的。
每個(gè)類型都有自己的映射或結(jié)果定義,所有類型下的文檔被存儲(chǔ)在同一個(gè)索引下。
_id:即文檔唯一標(biāo)識(shí)。
_id僅僅是一個(gè)字符串,與_index、_type組合時(shí),就可以在elasticsearch中唯一標(biāo)識(shí)一個(gè)文檔。創(chuàng)建文檔時(shí),可以自定義_id,也可以有Elasticsearch自動(dòng)生成一個(gè)32位長度的_id。
2.1 pretty -- 在查詢url中使用pretty參數(shù),返回的json格式的內(nèi)容更易查看。2.2 指定響應(yīng)字段 -- 如果不需要全部的字段,可以指定返回的字段。3. 判斷文檔是否存在 -- 可以使用head命令。4.1 批量查詢,如果文檔存在,則found值為true,否則為false。 4.2 _bulk操作 -- 批量插入數(shù)據(jù)。 批量請(qǐng)求時(shí)需要占用較多的內(nèi)存,請(qǐng)求量越大,其他請(qǐng)求可用的內(nèi)存就越小。一般會(huì)存在一個(gè)最佳的bulk請(qǐng)求值,超過這個(gè)值,性能可能不會(huì)提升,反而會(huì)降低。Bulk請(qǐng)求的最佳值并非固定值,取決于硬件性能、文檔的大小和復(fù)雜度、索引和搜索的負(fù)載。當(dāng)然,這個(gè)最佳值是可以被找到的。批量搜索文檔時(shí),隨著文檔大小或數(shù)量的增長,性能隨之降低。一般建議在1000~5000個(gè)文檔之間,若文檔是在太大,可使用較小的批次。
創(chuàng)建索引和插入數(shù)據(jù),Elasticsearch都會(huì)自動(dòng)進(jìn)行類型判斷,當(dāng)然也可以指定字段的類型,否則自動(dòng)判斷的類型和實(shí)際需求可能是不符的。5.1 自動(dòng)判斷的規(guī)則如下:| JSON type | Field type |
|---|
| Boolean: true or false | boolean |
| Whole number: 123 | long |
| Floating point: 123.45 | double |
| String, valid date: 2014-09-15??? | date |
String: foo bar
| string
|
5.2 Elasticsearch支持的類型如下:| Task Details | Vital Task |
|---|
| Boolean | boolean |
Whole number
| byte , short , integer , long |
Floating point
| float , double |
Date
| date |
String
| string , text , keyword |
- String -- 最新版本不再支持string,使用text和keyword。
- text -- 全文搜索一個(gè)字段時(shí),如Email內(nèi)容、小說文本、產(chǎn)品描述,使用text類型。text類型的字段內(nèi)容會(huì)被分析,在生成倒排索引以前,字符串會(huì)被分析器分成各個(gè)詞項(xiàng)。
- keyword -- 適用于結(jié)構(gòu)化的字段,如Email地址、IP地址、狀態(tài)碼等。需要對(duì)字段進(jìn)行過濾、排序、聚合時(shí),只能通過精確值搜索到keyword類型的字段。
6.1 term查詢,用于精確匹配指定的值,如日期、數(shù)字、布爾值、字符串等。 6.2 terms查詢,允許字段指定多個(gè)匹配值,類似于SQL中的in條件。 6.3 range查詢,指定范圍查詢數(shù)據(jù),gt:大于、gte:大于等于、lt:小于、lte:小于等于。6.4 exist查詢,查詢文檔中是否包含指定字段。6.5 match查詢,適用于全文本查詢或精確查詢。match查詢一個(gè)全文本的字段時(shí),會(huì)在查詢前使用分析器對(duì)被查詢的字符進(jìn)行分析。若使用match查詢一個(gè)指定的值,如數(shù)字、日期、字符串或布爾值,則將查詢出指定的值。
7. 分詞 -- 將文本轉(zhuǎn)化為一系列的單詞。如:太陽從東方升起-->太陽/從/東方/升起。可以指定分詞器進(jìn)行分詞,也可以指定索引分詞。中文分詞與英文分詞是有區(qū)別的,在英文中空格可以作為分隔符,而中文沒有明顯的詞匯分界點(diǎn)。中文分詞器有IK、jieba、thulac,但常用的是IK分詞器。IK Aanlyzer是開源的,基于java開發(fā)的輕量級(jí)的中文分詞工具包。它采用了特有的“正向迭代最細(xì)粒度切分算法”,高速處理能力可達(dá)到每秒80萬字,采用多子處理器分析模式,支持?jǐn)?shù)字(日期、數(shù)量詞、科學(xué)計(jì)數(shù)法)、字母(URL、Email)、中文詞匯(地名、姓名)的分詞處理。需要多帶帶安裝IK分詞器插件,插件下載后解壓到/elasticsearch/plugins/ik目錄,重啟elasticsearch即可。a. 新建索引student,增加字段name、age、address、hobby。8.3 邏輯”or”多詞搜索并高亮顯示,默認(rèn)”or”搜索。8.5 通過mininum_should_match指定匹配度來搜索。8.6 組合搜索,must--必須包含,must_not--不能包含,should--如果包含。8.7 權(quán)重,在查詢時(shí)可以增加權(quán)重來影響結(jié)果數(shù)據(jù)的得分,權(quán)重越大排序越靠前。
本文來源:IT那活兒(上海新炬王翦團(tuán)隊(duì))

文章版權(quán)歸作者所有,未經(jīng)允許請(qǐng)勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請(qǐng)注明本文地址:http://specialneedsforspecialkids.com/yun/129636.html



