資訊專欄INFORMATION COLUMN

寫該文章的目的,主要是為大家講解一下:如何利用Python語言實(shí)現(xiàn)郵件自動下載以及附件解析功能,下文附上了比較詳細(xì)的代碼,感興趣的話,可以仔細(xì)閱讀哦。
開始碼代碼之前,我們先來了解一下三種郵件服務(wù)協(xié)議:
1、SMTP協(xié)議
SMTP(Simple Mail Transfer Protocol),即簡單郵件傳輸協(xié)議。相當(dāng)于中轉(zhuǎn)站,將郵件發(fā)送到客戶端。
2、POP3協(xié)議
POP3(Post Office Protocol 3),即郵局協(xié)議的第3個版本,是電子郵件的第一個離線協(xié)議標(biāo)準(zhǔn)。該協(xié)議把郵件下載到本地計(jì)算機(jī),不與服務(wù)器同步,缺點(diǎn)是更易丟失郵件或多次下載相同的郵件。
3、IMAP協(xié)議
IMAP(Internet Mail Access Protocol),即交互式郵件存取協(xié)議。該協(xié)議連接遠(yuǎn)程郵箱直接操作,與服務(wù)器內(nèi)容同步。
然后介紹一下email包
這個包的中心組件是代表電子郵件消息的“對象模型”。應(yīng)用程序主要通過在message子模塊中定義的對象模型接口與這個包進(jìn)行交互。應(yīng)用程序可以使用此API來詢問有關(guān)現(xiàn)有電子郵件的問題、構(gòu)造新的電子郵件,或者添加或移除自身也使用相同對象模型接口的電子郵件子組件。也就是說,遵循電子郵件消息及其MIME子組件的性質(zhì),電子郵件對象模型是所有提供EmailMessage API的對象所構(gòu)成的樹狀結(jié)構(gòu)。
接下來我們通過具體的代碼實(shí)現(xiàn)一個登錄郵箱客戶端,下載郵件,解析郵件附件內(nèi)容的功能。
首先我們需要定義一個郵件解析的類,該類需要三個變量:
1、郵箱所屬的imap服務(wù)地址;
2、郵箱賬號;
3、郵箱密碼【注:不同郵箱需要不同的安全策略,例如qq郵箱需要短信驗(yàn)證,獲取登錄授權(quán)碼,而不是明文密碼去登錄遠(yuǎn)程客戶端】
class Email_parse:
def __init__(self,remote_server_url,email_url,password):
# imap服務(wù)地址
self.remote_server_url = remote_server_url
# 郵箱賬號
self.email_url = email_url
# 郵箱密碼
self.password = password
然后定義類中入口函數(shù),登錄遠(yuǎn)程,默認(rèn)獲取第一頁所有的郵件。我們獲取郵件的主題,并打印出來【不同郵件主題的編碼可能不同,二進(jìn)制需要轉(zhuǎn)碼才能正確顯示】
def main_parse_Email(self):
"""入口函數(shù),登錄imap服務(wù)"""
server = imaplib.IMAP4_SSL(self.remote_server_url, 993)
server.login(self.email_url, self.password)
server.select('INBOX')
status,data = server.search(None,"ALL")
if status != 'OK':
raise Exception('read email error')
emailids = data[0].split()
mail_counts = len(emailids)
print("count:",mail_counts)
# 郵件的遍歷是按時間從后往前,這里我們選擇最新的一封郵件
for i in range(mail_counts - 1, mail_counts - 2, -1):
status, edata = server.fetch(emailids[i], '(RFC822)')
msg = email.message_from_bytes(edata[0][1])
#獲取郵件主題title
subject = email.header.decode_header(msg.get('subject'))
if type(subject[-1][0]) == bytes:
title = subject[-1][0].decode(str(subject[-1][1]))
elif type(subject[-1][0]) == str:
title = subject[-1][0]
print("title:", title)
其中,msg變量保存的就是郵件的主體,接下來因?yàn)闀貜?fù)用到msg和tilte,我們將構(gòu)造一個類函數(shù)返回msg和title。
def get_email_title(msg):
subject = email.header.decode_header(msg.get('subject'))
if type(subject[-1][0]) == bytes:
title = subject[-1][0].decode(str(subject[-1][1]))
elif type(subject[-1][0]) == str:
title = subject[-1][0]
print("title:", title)
return title
解析郵件,我們分為兩部分,郵件正文【HTML】和附件【xlsx等】,判斷有附件,我們就保存到固定的路徑下。表格的解析不再贅述了,pandas之類的包足以搞定。
def get_att(msg):
"""獲取附件并下載"""
filename = Email_parse.get_email_name(msg)
for part in msg.walk():
file_name = part.get_param("name")
if file_name:
data = part.get_payload(decode=True)
if data != None:
att_file = open('./src/' + filename, 'wb')
att_file.write(data)
att_file.close()
else:
pass
郵件正文內(nèi)容,我們直接解析html,將文本內(nèi)容直接保存到.txt文件中,方便讀取。
def get_text_from_HTML(msg):
"""獲取郵件中的html"""
filename = Email_parse.get_email_name(msg)
current_title = Email_parse.get_email_title(msg)
print("filename:",filename,type(filename))
for part in msg.walk():
if not part.is_multipart():
result = part.get_payload(decode=True)
result = result.decode('gbk')
f = open(f'./src/{current_title}.txt','w')
f.write(result)
f.close()
return result
完整代碼如下:
import email
import imaplib
from email.header import decode_header
import pandas as pd
import datetime
class Email_parse:
def __init__(self,remote_server_url,email_url,password):
self.remote_server_url = remote_server_url
self.email_url = email_url
self.password = password
def get_att(msg):
filename = Email_parse.get_email_name(msg)
for part in msg.walk():
file_name = part.get_param("name")
if file_name:
data = part.get_payload(decode=True)
if data != None:
att_file = open('./src/' + filename, 'wb')
att_file.write(data)
att_file.close()
else:
pass
def get_email_title(msg):
subject = email.header.decode_header(msg.get('subject'))
if type(subject[-1][0]) == bytes:
title = subject[-1][0].decode(str(subject[-1][1]))
elif type(subject[-1][0]) == str:
title = subject[-1][0]
print("title:", title)
return title
def get_email_name(msg):
for part in msg.walk():
file_name = part.get_param("name")
if file_name:
h = email.header.Header(file_name)
dh = email.header.decode_header(h)
filename = dh[0][0]
if dh[0][1]:
value, charset = decode_header(str(filename, dh[0][1]))[0]
if charset:
filename = value.decode(charset)
print("附件名稱:", filename)
return filename
def main_parse_Email(self):
server = imaplib.IMAP4_SSL(self.remote_server_url, 993)
server.login(self.email_url, self.password)
server.select('INBOX')
status,data = server.search(None,"ALL")
if status != 'OK':
raise Exception('read email error')
emailids = data[0].split()
mail_counts = len(emailids)
print("count:",mail_counts)
for i in range(mail_counts - 1, mail_counts - 2, -1):
status, edata = server.fetch(emailids[i], '(RFC822)')
msg = email.message_from_bytes(edata[0][1])
subject = email.header.decode_header(msg.get('subject'))
if type(subject[-1][0]) == bytes:
title = subject[-1][0].decode(str(subject[-1][1]))
elif type(subject[-1][0]) == str:
title = subject[-1][0]
print("title:", title)
Email_parse.get_att(msg)
Email_parse.get_text_from_HTML(msg)
def get_text_from_HTML(msg):
filename = Email_parse.get_email_name(msg)
current_title = Email_parse.get_email_title(msg)
print("filename:",filename,type(filename))
for part in msg.walk():
if not part.is_multipart():
result = part.get_payload(decode=True)
result = result.decode('gbk')
f = open(f'./src/{current_title}.txt','w')
f.write(result)
f.close()
return result
if __name__ == "__main__":
remote_server_url = 'imap.qq.com'
email_url = "*********@qq.com"
password = "**********"
demo = Email_parse(remote_server_url,email_url,password)
demo.main_parse_Email()
運(yùn)行結(jié)果:
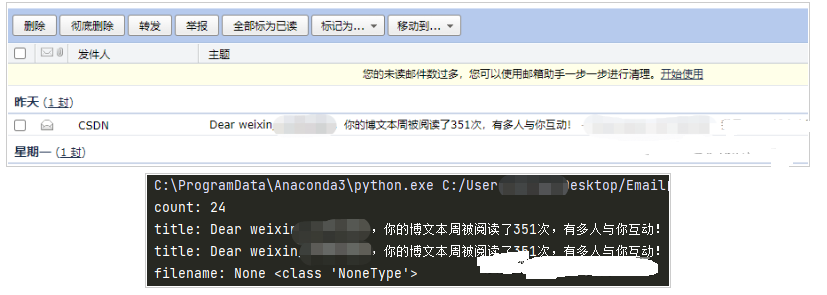
上文就是關(guān)于如何利用Python語言實(shí)現(xiàn)郵件自動下載以及附件解析功能的詳細(xì)解答,希望能給各位讀者帶來更多的幫助。
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/127552.html
這兩天和朋友談到軟件測試的發(fā)展:這一行的變化確實(shí)蠻大,從開始最基礎(chǔ)的功能測試,到現(xiàn)在自動化、性能、安全乃至于以后可能出現(xiàn)的大數(shù)據(jù)測試、AI測試崗位需求逐漸增多。我也在軟件測試這行摸爬滾打了十年了,正好有朋友問我:如何快速成為互聯(lián)網(wǎng)時代優(yōu)秀的測試工程師呢?趁著最近終于有了些閑余時間,遂總結(jié)了下自動化測試的成長線路圖和職業(yè)必備技能,希望可以幫助各位少走彎路、破繭成蝶、邁向成功。 下面我來分享下自動化測...

Python在自動化辦公方面,用處還是比較的大的,如果使用起來的話,其辦公的效率會大大的提高。特別是我們在做報表的時候,使用python更加的簡潔方便,那么,怎么實(shí)現(xiàn)報表自動化呢?我們制作完報表之后,怎么才能夠自動發(fā)送到郵箱呢?下面給大家詳細(xì)解答下。 項(xiàng)目背景 作為數(shù)據(jù)分析師,我們需要經(jīng)常制作統(tǒng)計(jì)分析圖表。但是報表太多的時候往往需要花費(fèi)我們大部分時間去制作報表。這耽誤了我們利用大量的時間去...
摘要:年月日,研究人員通過郵件列表披露了容器逃逸漏洞的詳情,根據(jù)的規(guī)定會在天后也就是年月日公開。在號當(dāng)天已通過公眾號文章詳細(xì)分析了漏洞詳情和用戶的應(yīng)對之策。 美國時間2019年2月11日晚,runc通過oss-security郵件列表披露了runc容器逃逸漏洞CVE-2019-5736的詳情。runc是Docker、CRI-O、Containerd、Kubernetes等底層的容器運(yùn)行時,此...
摘要:在這里真心感謝一直在支持我的那幾個粉絲,謝謝你們的持續(xù)關(guān)注點(diǎn)贊。果然,第三個包也是按的步差來的,而為零不變,也不變。函數(shù)里面的話就是個循環(huán)咯,當(dāng)條件不滿足時就一直加,知道條件滿足為止。我每天都會抽時間給我的粉絲解答,給與一些學(xué)習(xí)資源。 目錄 前言 準(zhǔn)備工作 分析(x0) 分析(x1) 分析(...
閱讀 911·2023-01-14 11:38
閱讀 878·2023-01-14 11:04
閱讀 740·2023-01-14 10:48
閱讀 1982·2023-01-14 10:34
閱讀 942·2023-01-14 10:24
閱讀 819·2023-01-14 10:18
閱讀 499·2023-01-14 10:09
閱讀 572·2023-01-14 10:02




