資訊專欄INFORMATION COLUMN

摘要:填入規則如下圖所示配置代理參數配置代理參數在下方中配置代理參數如下配置完成后如下圖所示然后點擊按鈕,如果得到如下圖所示樣例,則表示成功。配置信息,如下圖所示配置權限類型配置權限類型配置權限可以分為兩種類別允許的權限拒絕的權限。
HDFS 作為底層存儲,本章節將以 HDFS 為例,進行說明。
首先需要分別在兩臺 NameNode 節點上開啟 HDFS Ranger 插件,并重啟集群,命令如下:
/srv/udp/1.0.0.0/hdfs/ranger-hdfs-plugin/enable-hdfs-plugin.sh 注:可通過 USDP 控制臺查看 HDFS 相關組件中,NameNode1、NameNode2 分別運行在集群的哪些節點上。
此時會在當前節點的如下目錄自動生成相關權限配置:
/srv/udp/1.0.0.0/hdfs/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.permissions.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.permissionsname>
<value>truevalue>
property>
<property>
<name>dfs.namenode.inode.attributes.provider.classname>
<value>org.apache.ranger.authorization.hadoop.RangerHdfsAuthorizervalue>
property>并自動在該目錄下生成軟鏈接:
/srv/udp/1.0.0.0/hdfs/share/hadoop/hdfs/lib
ranger-hdfs-plugin-impl -> /srv/udp/1.0.0.0/hdfs/ranger-hdfs-plugin/lib/ranger-hdfs-plugin-impl
ranger-hdfs-plugin-shim-1.2.0.jar -> /srv/udp/1.0.0.0/hdfs/ranger-hdfs-plugin/lib/ranger-hdfs-plugin-shim-1.2.0.jar
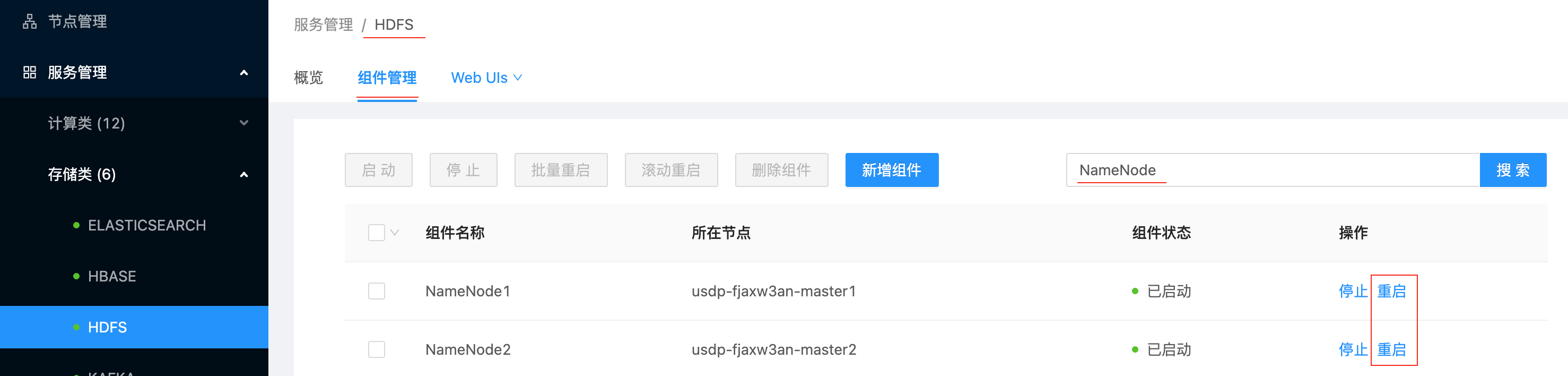
ranger-plugin-classloader-1.2.0.jar -> /srv/udp/1.0.0.0/hdfs/ranger-hdfs-plugin/lib/ranger-plugin-classloader-1.2.0.jar注意:此時,需要通過 USDP 控制臺重啟兩個NameNode
2. 在USDP控制臺完成兩個NameNode服務重啟進入左側導航欄 “服務管理”-“存儲類”-“HDFS” 中,點擊 “組件管理”,尋找到 “NameNode1”、“NameNode2” 組件后,點擊 “NameNode1”、“NameNode2” 組件對應的 “操作” 欄 重啟 按鈕。
請在云端內網環境中使用瀏覽器訪問 Ranger Web UI頁面。
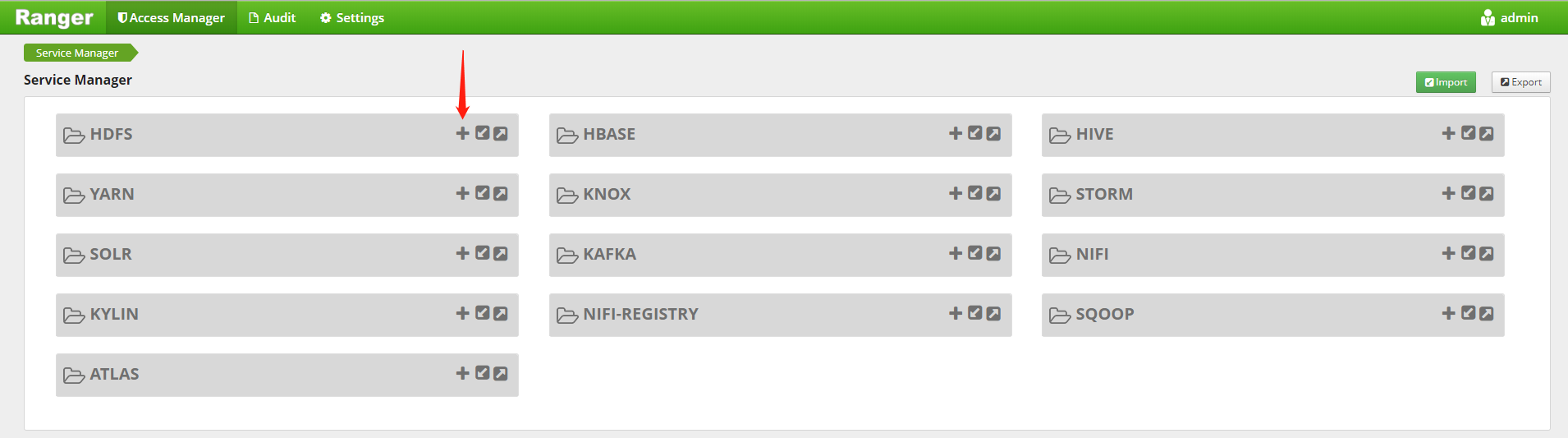
2. 添加 HDFS-Service在Service Manager頁面的 HDFS 條目中,點擊 + 按鈕進行創建 Service,如下圖所示:
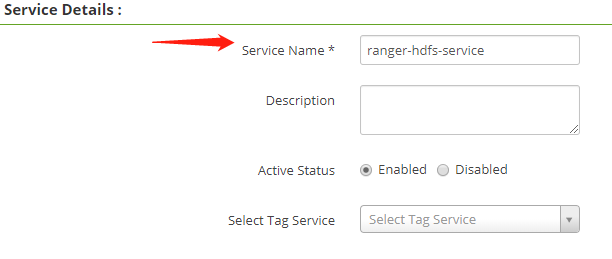
進入Create Service服務配置頁面,在 Service Name 輸入框中填入如下值:
ranger-hdfs-service注意: 此處必須填寫此值!
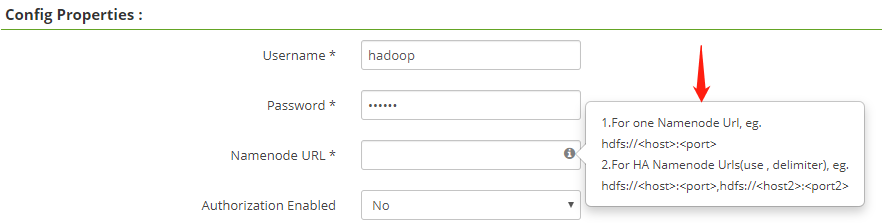
填入用戶名密碼為如下:
Username:hadoop
Password:hadoop在 NameNode URL 中填入如下配置:
hdfs://usdp-xxx-master1:8020,hdfs://usdp-xxx-master2:8020注意:請替換示例中主機名字符串中的“xxx”為正確的主機名字符串。
填入規則如下圖所示:
在下方 Add New Configuration 中配置代理參數如下:
policy.download.auth.users: hadoop配置完成后如下圖所示:
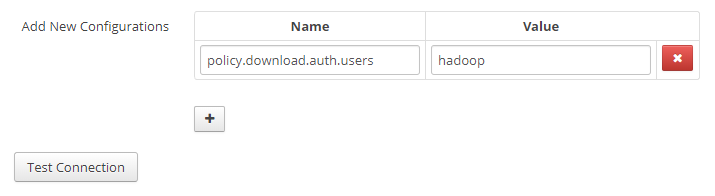
然后點擊 Test Connection 按鈕,如果得到如下圖所示樣例,則表示成功。
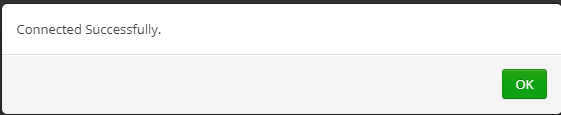
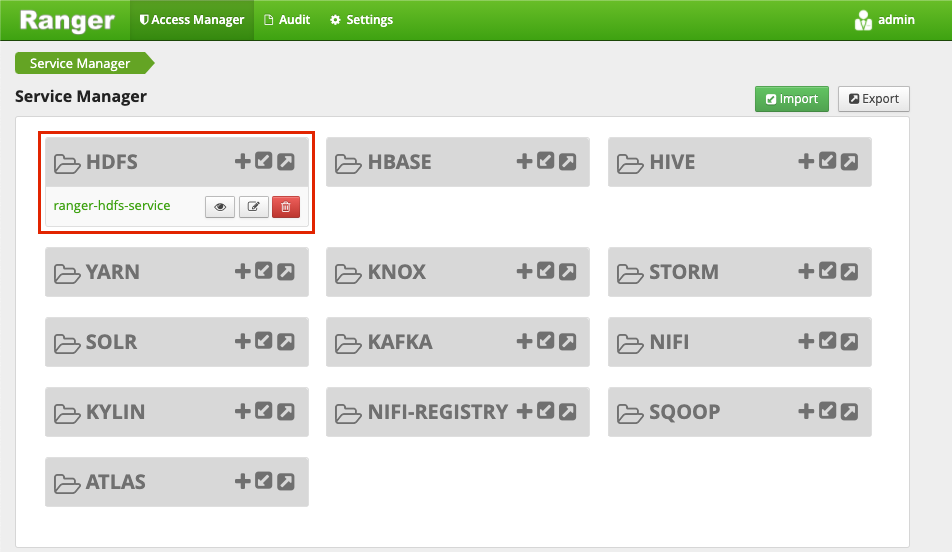
然后,點擊 Add 按鈕,此時Ranger Web UI的Service Manager頁面顯示如下:
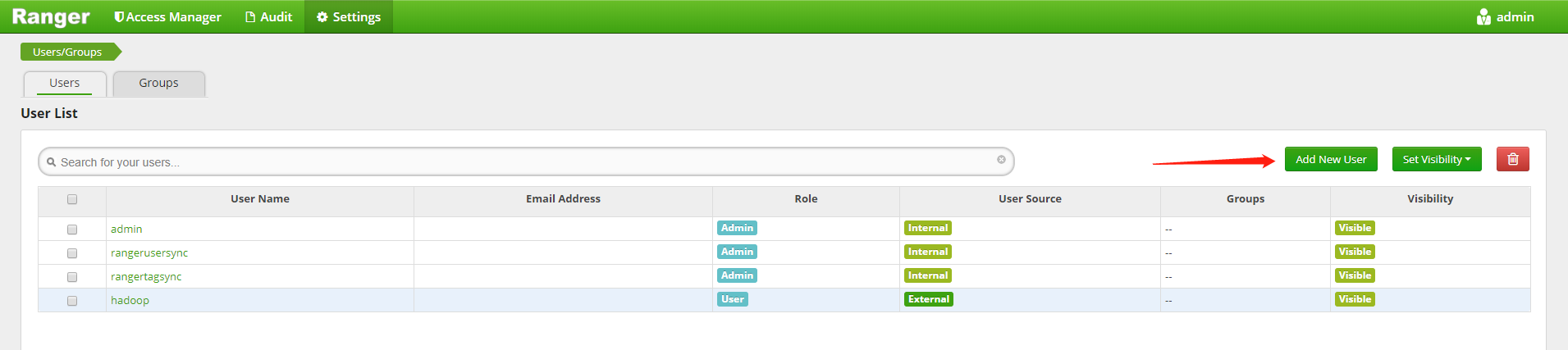
在 Ranger Web UI 中,點擊頂部導航欄 “Settings” 菜單,選擇“Users”標簽頁,點擊頁面右側的 Add New User 添加測試用戶,如下圖所示:
編輯內容,完成后點擊 Save 按鈕保存,如下圖所示:
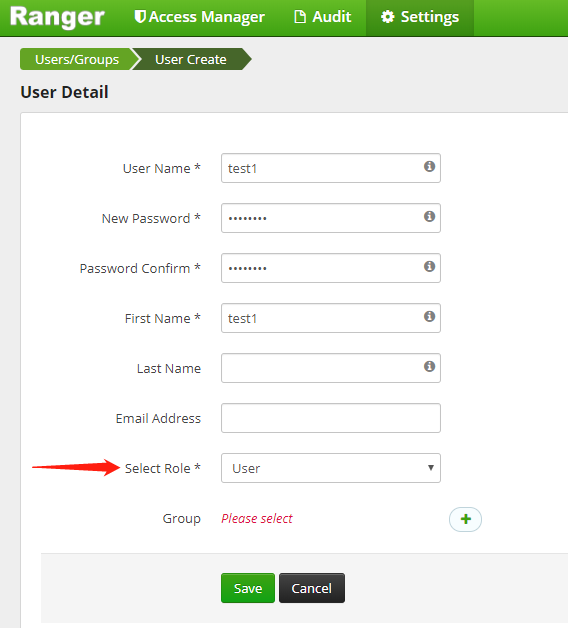
注:Select Role 中,選擇 User 類型,而非 Admin 類型。
2. 在 Linux 中添加用戶通過 ssh 在集群節點上,添加與上述配置相同的用戶test1,命令如下:
useradd test1使用如下命令,驗證剛添加的 test1 用戶是否擁有對應權限:
su -s /bin/bash test1 -c "/srv/udp/1.0.0.0/hdfs/bin/hdfs dfs -ls /"返回結果如下:
drwxrwxr-x - hadoop supergroup 0 2020-11-06 11:28 /flink-completed-jobs
drwxr-xr-x - hadoop supergroup 0 2020-11-06 11:30 /hbase
drwxr-xr-x - hadoop supergroup 0 2020-11-06 11:29 /kylin
drwxrwxr-x - hadoop supergroup 0 2020-11-06 11:28 /spark-logs
drwxr-xr-x - hadoop supergroup 0 2020-11-06 11:27 /tez
drwxrwx--- - hadoop supergroup 0 2020-11-06 11:28 /tmp
drwxr-xr-x - hadoop supergroup 0 2020-11-06 11:28 /user此時證明 test1 用戶對HDFS的根目錄擁有訪問權限。
接下來,以配置拒絕 test1 用戶訪問 HDFS 為例,進行示例說明。
1. 進入編輯頁面如下圖所示,進入HDFS條目的“ranger-hdfs-service”策略編輯頁面:
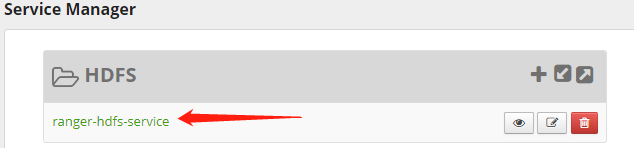
首先,刪除Ranger默認的權限策略,如下圖所示:

點擊右上角的 Add New Policy 即可添加自定義權限策略規則,如下圖所示:
在 Policy Name 屬性中,建議鍵入比較有標識度的規則名稱,例如:deny_test1_all,即,拒絕 test1 用戶所有對 HDFS 的操作。
同時,在 Resource Path 中輸入HDFS的根目錄:/ 并鍵入回車,同時,要確保 recursive 滑塊處于開啟狀態。
配置信息,如下圖所示:
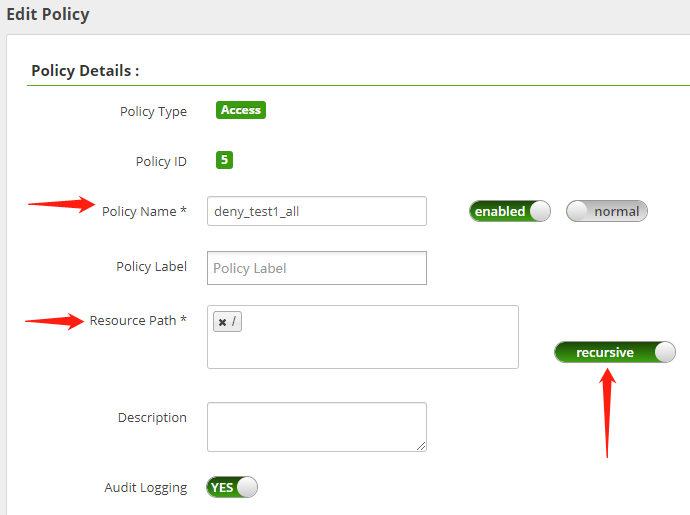
配置權限可以分為兩種類別:允許的權限、拒絕的權限。
本例中,以配置拒絕的權限為例進行說明,即拒絕 test1 用戶對 HDFS 根目錄及其子目錄下的所有操作。參考如下 “配置拒絕權限” 所示進行配置操作。
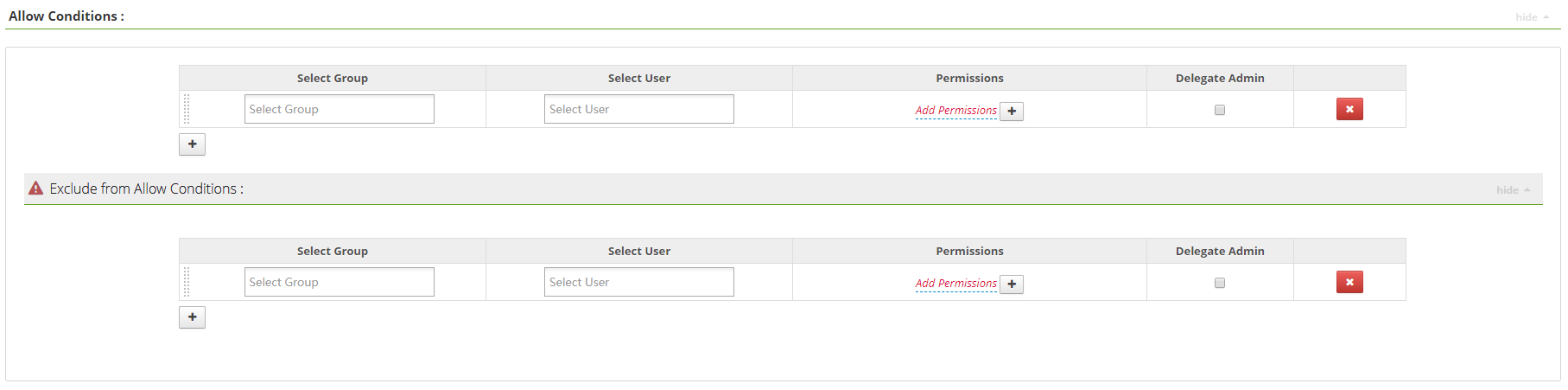
配置允許的權限,如下圖所示:
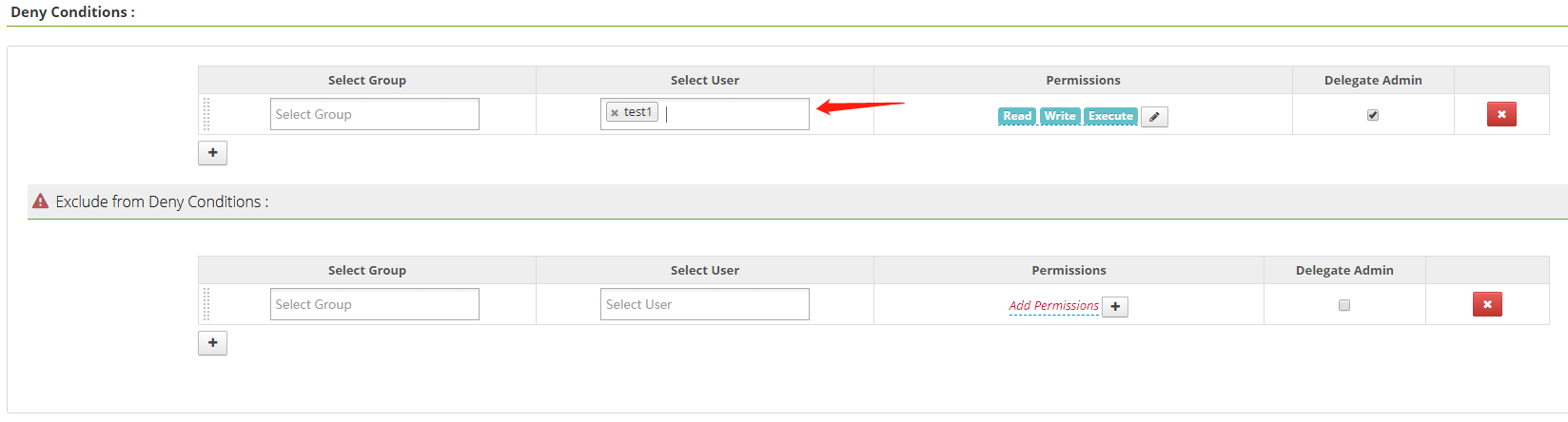
配置拒絕的權限,如下圖所示:
完成上述配置項填寫后,點擊 Add 按鈕保存,即已完成添加自定義策略配置,并回到權限策略概覽頁面,如下圖所示:

注:權限添加后,大約需要 1 分鐘左右即會生效。
接下來,通過 ssh 訪問集群中安裝了 HDFS 服務組件的“任意”節點,進行 shell 操作來驗證權限是否生效。
試驗命令如下:
su -s /bin/bash test1 -c "/srv/udp/1.0.0.0/hdfs/bin/hdfs dfs -ls /"若返回如下信息,說明當前節點本地無“test1”用戶
su: user test2 does not exist參見1.3.2節,執行 “useradd test1”添加test1用戶后再重試上述命令,返回結果如下:
ls: Permission denied: user=test1, access=EXECUTE, inode="/"此時證明權限配置已生效,test1用戶已無權訪問HDFS的任何目錄了。
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/127017.html

摘要:點擊創建集群按鈕開始創建集群資源點擊創建集群按鈕開始創建集群資源創建集群創建集群設置地域和可用區信息設置地域和可用區信息請根據您的需要,在創建集群向導中設置新集群所歸屬的地域及可用區信息。 集群創建本篇目錄開始創建集群資源開始部署集群服務和組件智能大數據平臺USDP集群的創建過程,分為兩個部分,即在公有云控制臺中,創建USDP的集群資源,待創建完成后,進入您獨享的USDP管理服務開始規劃并創...
摘要:企業微信截圖企業微信截圖兼容最廣的一站式智能大數據平臺涵蓋了等眾多開源大數據組件,支持對這些組件進行運維中臺建設數據開發業務可視化等全棧式大數據開發運維管理。通過一站式智能大數據平臺支持的等分布式運算框架,可以高效的進行機器學習應用開發。背景在大數據業務系統中,所有技術棧生態均是圍繞著存儲進行擴展的,目前開源的主流存儲技術棧主要包含如下 3 種類型:· HDFS:Hadoop 系列套件,包含...
摘要:機器學習機器學習通過算法對大量數據進行分析,挖掘出其中蘊含的規律,并用于事物預測或者分類,有大量的計算需求。通過一站式智能大數據平臺支持的等分布式運算框架,可以高效的進行機器學習應用開發。在大數據業務系統中,所有技術棧生態均是圍繞著存儲進行擴展的,目前開源的主流存儲技術棧主要包含如下 3 種類型:· HDFS:Hadoop 系列套件,包含 Hive、Hbase、Phoenix 等;· Ela...
在互聯網市場的頭部效應下,企業所面臨的競爭壓力越來越大,如何有效解決獲客成本高、用戶黏性低、變現能力弱等問題,正是越來越多的企業開始構建大數據平臺的初衷。但由于大數據解決方案所涉及的組件錯綜復雜、技術門檻較高,且初期投入的資源和后期的維護成本較大,十分考驗企業的大數據平臺組建和運維能力。因此,UCloud大數據團隊于近期上線了大數據智能平臺(UCloud Smart Data Platform,下...

摘要:功能簡介功能簡介功能簡介本篇目錄一功能點概述一功能點概述二支持的大數據生態服務二支持的大數據生態服務一功能點概述一功能點概述一功能點概述支持友好的瀏覽器管理控制臺支持集群節點管理,如節點監控資源使用率節點狀態等支持集群大數據服務的服 功能簡介本篇目錄一、功能點概述二、支持的大數據生態服務一、功能點概述支持友好的Web瀏覽器管理控制臺;支持集群節點管理,如節點監控、資源使用率、節點狀態等;支持...

閱讀 351·2024-11-07 18:25
閱讀 130597·2024-02-01 10:43
閱讀 914·2024-01-31 14:58
閱讀 879·2024-01-31 14:54
閱讀 82884·2024-01-29 17:11
閱讀 3176·2024-01-25 14:55
閱讀 2028·2023-06-02 13:36
閱讀 3108·2023-05-23 10:26

