資訊專欄INFORMATION COLUMN

摘要:客戶端庫,為需要監控的服務生成相應的并暴露給。根據配置文件,對接收到的警報進行處理,發出告警。再創建一個來告訴需要監控帶有為的背后的一組的。
Prometheus 是一套開源的系統監控報警框架。它的設計靈感源于 Google 的 borgmon 監控系統,由SoundCloud 在 2012 年創建,后作為社區開源項目進行開發,并于 2015 年正式發布。2016 年,Prometheus 正式加入 Cloud Native Computing Foundation(CNCF),成為受歡迎度僅次于 Kubernetes 的項目,目前已廣泛應用于Kubernetes集群監控系統中,大有成為Kubernetes集群監控標準方案的趨勢。
強大的多維度數據模型:
圖片源于Prometheus官方文檔
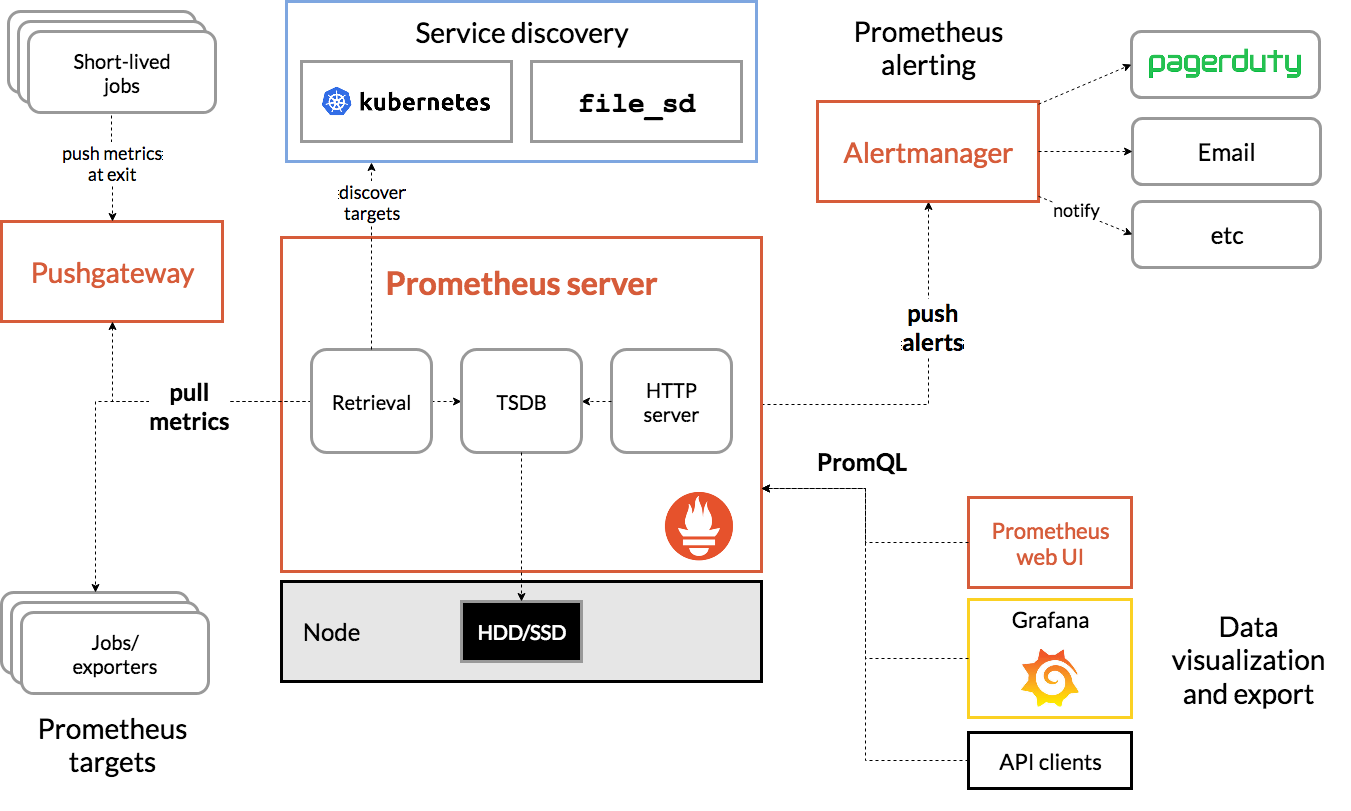
上圖為Prometheus的架構圖,包含了Prometheus的核心模塊及生態圈中的組件,簡要介紹如下:
如上圖可見,Prometheus 的主要模塊包括:Prometheus server exporters Pushgateway PromQL Alertmanager 以及圖形界面,其大概的工作流程是:
Prometheus 工作的核心,是使用 Pull (抓取)的方式去搜集被監控對象的 Metrics 數據(監控指標數據),然后,再把這些數據保存在一個 TSDB (時間序列數據庫,比如 OpenTSDB、InfluxDB 等)當中,以便后續可以按照時間進行檢索。
Prometheus非常適合記錄純時間序列的數據。它既適用于面向服務器等硬件指標的監控,也適用于高動態的面向服務架構的監控。對于現在流行的微服務,Prometheus的多維度數據收集和數據篩選查詢語言也是非常的強大。Prometheus是為服務的可靠性而設計的,當服務出現故障時,它可以使你快速定位和診斷問題。它的搭建過程對硬件和服務沒有很強的依賴關系。
Prometheus重視可靠性,即使在故障情況下,您也可以隨時查看有關系統的可用統計信息。如果您需要100%的準確度,例如按請求計費,Prometheus不是一個好的選擇,因為收集的數據可能不夠詳細和完整。
總之,在需要高可用性的業務場景,Prometheus是一個非常好的選擇,但對于高精度、高準確率的業務場景,Prometheus并非最佳選擇。
為了在 Prometheus 的配置和使用中可以更加順暢,我們對 Prometheus 中的數據模型、metric 類型以及 instance 和 job 等概念做個簡要介紹。
Prometheus 中存儲的數據為時間序列,是由 metric 的名字和一系列的標簽(鍵值對)唯一標識的,不同的標簽則代表不同的時間序列。
Prometheus 客戶端庫主要提供四種主要的 metric 類型,分別如下:
一種累加的 metric,典型的應用如:請求的個數,結束的任務數, 出現的錯誤數等等。
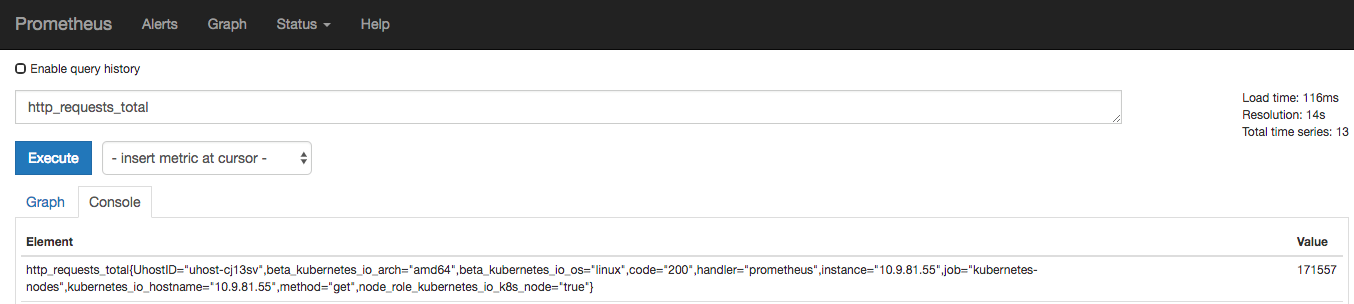
例如,查詢 http_requests_total{method="get" job="kubernetes-nodes" handler="prometheus"} 返回 8,10 秒后,再次查詢,則返回 14。
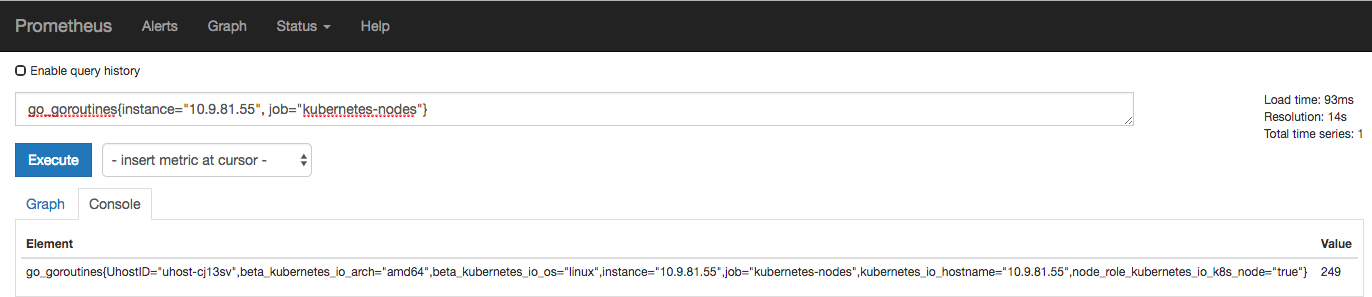
一種常規的 metric,典型的應用如:溫度,運行的 goroutines 的個數。例如:go_goroutines{instance="10.9.81.55" job="kubernetes-nodes"} 返回值 147,10 秒后返回 124。
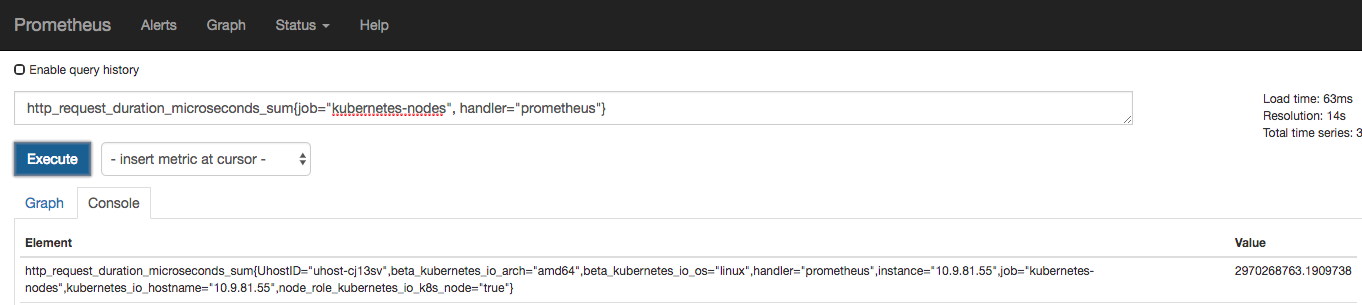
可以理解為柱狀圖,典型的應用如:請求持續時間,響應大小。可以對觀察結果采樣,分組及統計。
例如,查詢 http_request_duration_microseconds_sum{job="kubernetes-nodes" handler="prometheus"} 時,返回結果如下:
類似于 Histogram 典型的應用如:請求持續時間,響應大小。提供觀測值的 count 和 sum 功能。提供百分位的功能,即可以按百分比劃分跟蹤結果。
instance: 一個多帶帶 scrape 的目標, 一般對應于一個進程。
jobs: 一組同類型的 instances
例如,一個 api-server 的 job 可以包含4個 instances:
job: api-server
當 scrape 目標時,Prometheus 會自動給這個 scrape 的時間序列附加一些標簽以便更好的分別,例如:instance,job。
對于一套Kubernetes集群而言,需要監控的對象大致可以分為以下幾類:
在Kubernetes中部署Prometheus,除了手工方式外,CoreOS開源了Prometheus-Operator以及kube-Prometheus項目,使得在K8S中安裝部署Prometheus變得異常簡單。下面我們介紹下如何在UK8S中部署Kube-Prometheus。
Prometheus-operator的本職就是一組用戶自定義的CRD資源以及Controller的實現,Prometheus Operator這個controller有BRAC權限下去負責監聽這些自定義資源的變化,并且根據這些資源的定義自動化的完成如Prometheus Server自身以及配置的自動化管理工作。
在K8S中,監控metrics基本最小單位都是一個Service背后的一組pod,對應Prometheus中的target,所以prometheus-operator抽象了對應的CRD類型" ServiceMonitor ",這個ServiceMonitor通過 sepc.selector.labes來查找對應的Service及其背后的Pod或endpoints,通過sepc.endpoint來指明Metrics的url路徑。
以下面的CoreDNS舉例,需要pull的Target對象Namespace為kube-system,kube-app是他們的labels,port為metrics。
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: coredns
name: coredns
namespace: monitoring
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 15s
port: metrics
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
k8s-app: kube-dns ssh到任意一臺Master節點,克隆kube-prometheus項目。該項目源自CoreOS開源的kube-prometheus,與原始項目相比,主要作為以下優化:
yum install git -y
git clone --depth=1 -b kube-prometheus https://github.com/ucloud/uk8s-demo.git在manifests目錄下有UK8S目錄,這批配置文件主要用于為UK8S中的controller-manager、schduler、etcd手動創建endpoints和svc,便于Prometheus Server通過ServiceMonitor來采集這三個組件的監控數據。
cd /uk8s-demo/manifests/uk8s
# 修改以下兩個文件,將其中的IP替換為你自己UK8S Master節點的內網IP
vi controllerManagerAndScheduler_ep.yaml
vi etcd_ep.yaml上面提到要修改controllerManagerAndScheduler_ep.yaml和etcd_ep.yaml這兩個文件,這里解釋下原因。
由于UK8S的ETCD、Scheduler、Controller-Manager都是通過二進制部署的,為了能通過配置"ServiceMonitor"實現Metrics的抓取,我們必須要為其在K8S中創建一個SVC對象,但由于這三個組件都不是Pod,因此我們需要手動為其創建Endpoints。
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: etcd
name: etcd
namespace: kube-system
subsets:
- addresses:
- ip: 10.7.35.44 # 替換成master節點的內網IP
nodeName: etc-master2
ports:
- name: port
port: 2379
protocol: TCP
- addresses:
- ip: 10.7.163.60 # 同上
nodeName: etc-master1
ports:
- name: port
port: 2379
protocol: TCP
- addresses:
- ip: 10.7.142.140 #同上
nodeName: etc-master3
ports:
- name: port
port: 2379
protocol: TCP 先創建一個名為monitor的NameSpace,Monitor創建成功后,直接部署Operator,Prometheus Operateor以Deployment的方式啟動,并會創建前面提到的幾個CRD對象。
# 創建Namespace
kubectl apply -f 00namespace-namespace.yaml
# 創建Secret,給到Prometheus Server抓取ETCD數據時使用
kubectl -n monitoring create secret generic etcd-certs --from-file=/etc/kubernetes/ssl/ca.pem --from-file=/etc/kubernetes/ssl/etcd.pem --from-file=/etc/kubernetes/ssl/etcd-key.pem
# 創建Operator
kubectl apply -f operator/
# 查看operator啟動狀態
kubectl get po -n monitoring
# 查看CRD
kubectl get crd -n monitoring比較關鍵的有Prometheus Server、Grafana、 AlertManager、ServiceMonitor、Node-Exporter等,這些鏡像已全部修改為UHub官方鏡像,因此拉取速度相對比較快。
kubectl apply -f adapter/
kubectl apply -f alertmanager/
kubectl apply -f node-exporter/
kubectl apply -f kube-state-metrics/
kubectl apply -f grafana/
kubectl apply -f prometheus/
kubectl apply -f serviceMonitor/
kubectl apply -f uk8s/我們可以通過以下命令來查看應用拉取狀態。
kubectl -n monitoring get po由于默認所有的SVC 類型均為ClusterIP,我們將其改為LoadBalancer,方便演示。
kubectl edit svc/prometheus-k8s -n monitoring
# 修改為type: LoadBalancer
[root@10-9-52-233 manifests]# kubectl get svc -n monitoring
# 獲取到Prometheus Server的EXTERNAL-IP及端口可以看到,所有K8S組件的監控指標均已獲取到。
我們先來部署一組Pod及SVC,該鏡像里的主進程會在8080端口上輸出metrics信息。
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-app
spec:
replicas: 3
selector:
matchLabels:
app: example-app
template:
metadata:
labels:
app: example-app
spec:
containers:
- name: example-app
image: uhub.service.ucloud.cn/uk8s_public/instrumented_app:latest
ports:
- name: web
containerPort: 8080
---
kind: Service
apiVersion: v1
metadata:
name: example-app
labels:
app: example-app
spec:
selector:
app: example-app
ports:
- name: web
port: 8080 再創建一個ServiceMonitor來告訴prometheus server需要監控帶有label為app: example-app的svc背后的一組pod的metrics。
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: example-app
labels:
team: frontend
spec:
selector:
matchLabels:
app: example-app
endpoints:
- port: web
打開瀏覽器訪問Prometheus Server,進入target發現已經監聽起來了,對應的config里也有配置生成和導入。
該文檔只適用于kubernetes 1.14以上的版本,如果你的kubernetes版本為1.14以下,可以使用release-0.1.
實時文檔歡迎訪問https://docs.ucloud.cn/uk8s/monitor/prometheus/README
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/126277.html
摘要:添加接收人監控中心支持添加郵箱及微信兩種告警,需要注意的是,添加郵箱告警的話,需要預先配置發件服務器。由于監控中心配置了一條告警規則,只要企業微信的信息填寫正確,一般分鐘以內均可從企業微信中獲取到告警信息。監控中心概述監控中心是UK8S提供的產品化監控方案,提供基于Prometheus的產品解決方案,涵蓋Prometheus集群的全生命周期管理,以及告警規則配置、報警設置等功能,省去了自行搭...
摘要:宋體本文從拉勾網的業務架構日志采集監控服務暴露調用等方面介紹了其基于的容器化改造實踐。宋體此外,拉勾網還有一套自研的環境的業務發布系統,不過這套發布系統未適配容器環境。寫在前面 拉勾網于 2019 年 3 月份開始嘗試將生產環境的業務從 UHost 遷移到 UK8S,截至 2019 年 9 月份,QA 環境的大部分業務模塊已經完成容器化改造,生產環境中,后臺管理服務已全部遷移到 UK8...
摘要:詳細請見產品價格產品概念使用須知名詞解釋漏洞修復記錄集群節點配置推薦模式選擇產品價格操作指南集群創建需要注意的幾點分別是使用必讀講解使用需要賦予的權限模式切換的切換等。UK8S概覽UK8S是一項基于Kubernetes的容器管理服務,你可以在UK8S上部署、管理、擴展你的容器化應用,而無需關心Kubernetes集群自身的搭建及維護等運維類工作。了解使用UK8S為了讓您更快上手使用,享受UK...

摘要:為什么在節點直接起容器網絡不通為什么在節點直接起容器網絡不通為什么在節點直接起容器網絡不通使用自己的插件,而直接用起的容器并不能使用該插件,因此網絡不通。 UK8S 集群常見問題本篇目錄1. UK8S 完全兼容原生 Kubernetes API嗎?2. UK8S 人工支持3. UK8S對Node上發布的容器有限制嗎?如何修改?4. 為什么我的容器一起來就退出了?5. Docker 如何調整日...
摘要:宋體自年被開源以來,很快便成為了容器編排領域的標準。宋體年月,樂心醫療的第一個生產用集群正式上線。所以于年推出后,樂心醫療的運維團隊在開會討論之后一致決定盡快遷移到。Kubernetes 自 2014 年被 Google 開源以來,很快便成為了容器編排領域的標準。因其支持自動化部署、大規模可伸縮和容器化管理等天然優勢,已經被廣泛接納。但由于 Kubernetes 本身的復雜性,也讓很多企業的...

閱讀 3514·2023-04-25 20:09
閱讀 3720·2022-06-28 19:00
閱讀 3035·2022-06-28 19:00
閱讀 3058·2022-06-28 19:00
閱讀 3132·2022-06-28 19:00
閱讀 2859·2022-06-28 19:00
閱讀 3014·2022-06-28 19:00
閱讀 2610·2022-06-28 19:00




