資訊專欄INFORMATION COLUMN

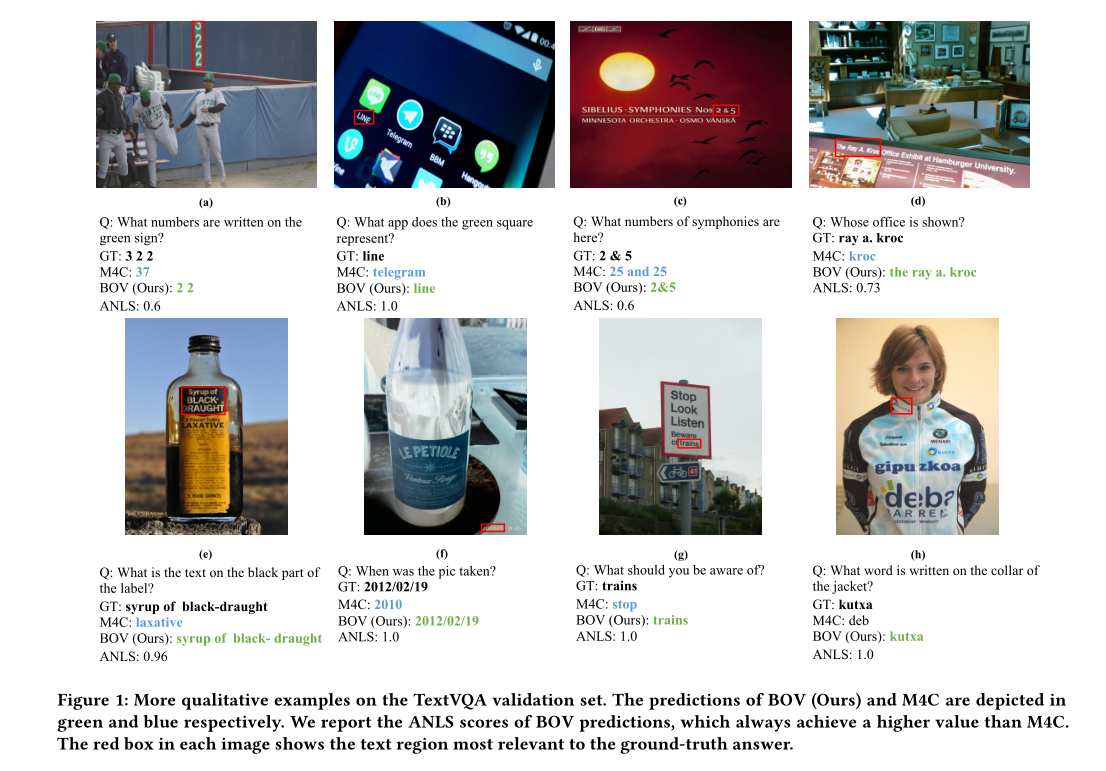
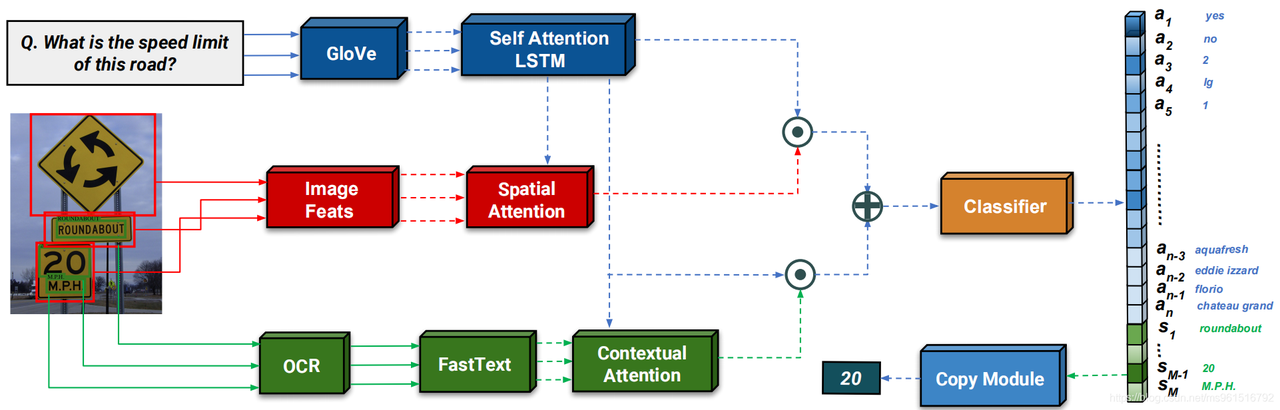
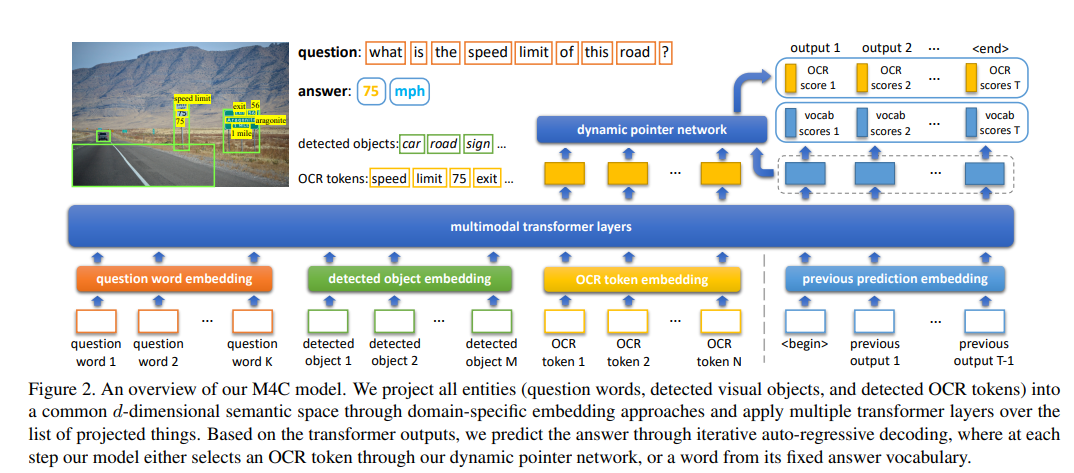
摘要:模塊基于預(yù)訓(xùn)練模型進(jìn)行識別,識別出的結(jié)果與一起經(jīng)過注意力機(jī)制得到加權(quán)的空間注意力,得到的結(jié)果與進(jìn)行組合。五六結(jié)論將融入的前向處理流程,構(gòu)建了一個魯棒且準(zhǔn)確的模型參考博客
?論文題目:Beyond OCR + VQA: Involving OCR into the Flow for Robust and Accurate TextVQA
?論文鏈接:https://dl.acm.org/doi/abs/10.1145/3474085.3475606
![]()
![]()
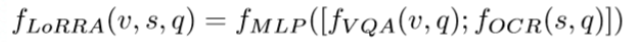
![]()
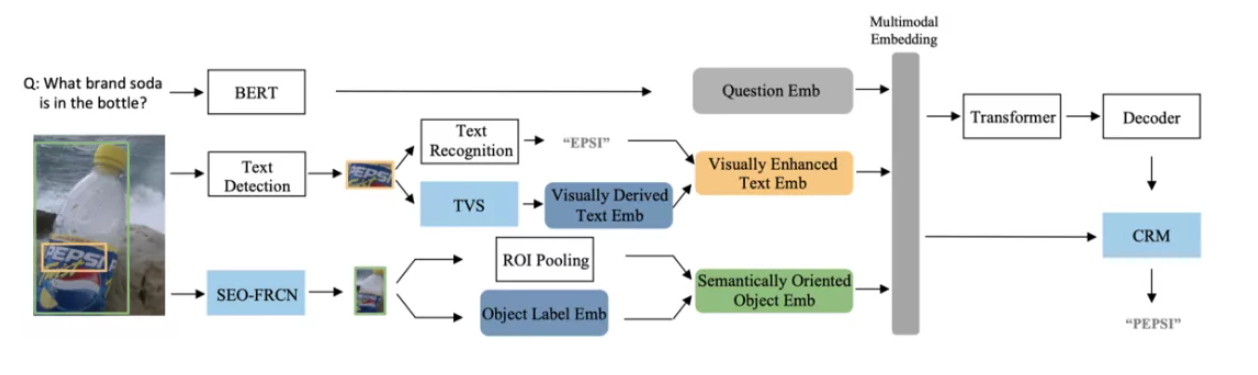
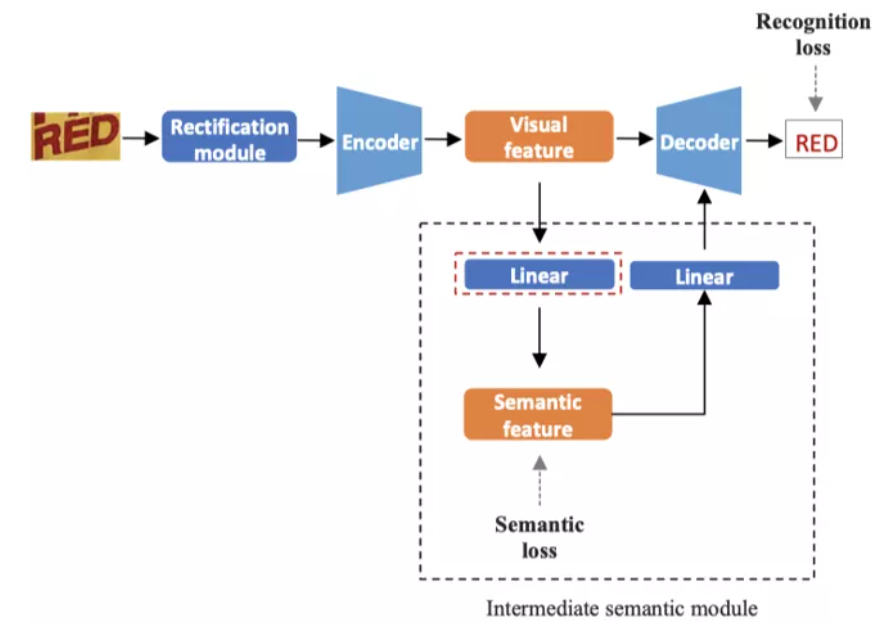
![]()
?
![]()
![]()

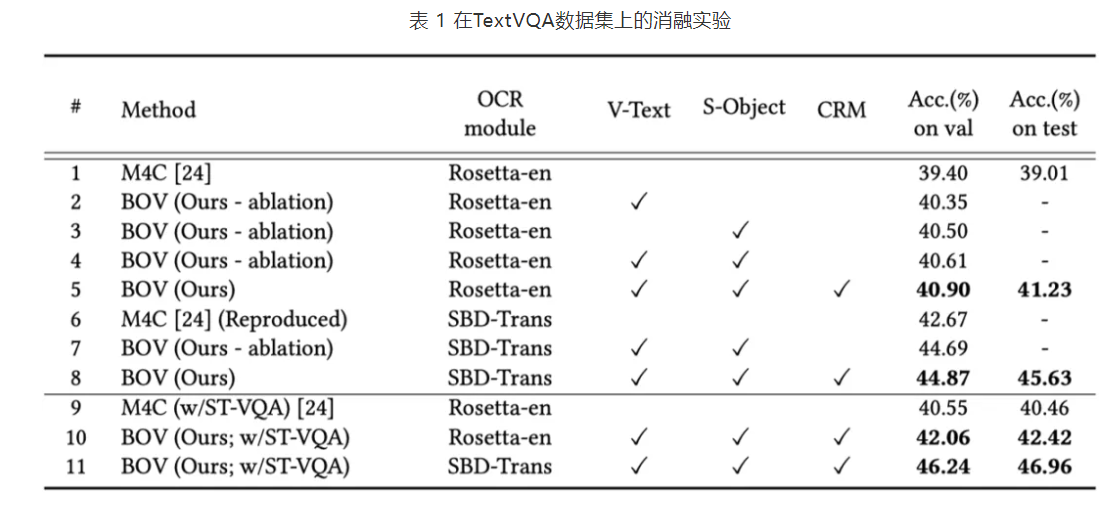
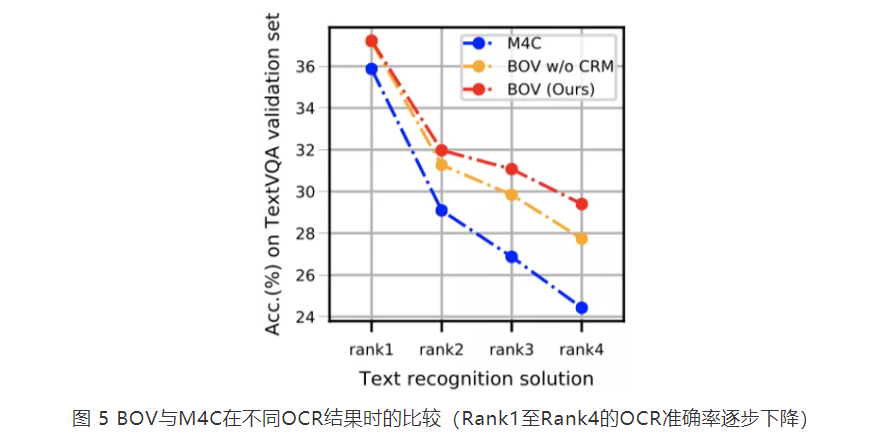
?
?
?
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/125370.html
摘要:因為深度學(xué)習(xí)的正統(tǒng)觀念在該領(lǐng)域已經(jīng)很流行了。在機(jī)器和深度學(xué)習(xí)空間中進(jìn)行的大多數(shù)數(shù)學(xué)分析傾向于使用貝葉斯思想作為參數(shù)。如果我們接受了目前深度學(xué)習(xí)的主流觀點(diǎn)任何一層的微分都是公平的,那么或許我們應(yīng)該使用存儲多種變體的復(fù)分析。 深度學(xué)習(xí)只能使用實(shí)數(shù)嗎?本文簡要介紹了近期一些將復(fù)數(shù)應(yīng)用于深度學(xué)習(xí)的若干研究,并指出使用復(fù)數(shù)可以實(shí)現(xiàn)更魯棒的層間梯度信息傳播、更高的記憶容量、更準(zhǔn)確的遺忘行為、大幅降低的網(wǎng)...

閱讀 3735·2023-01-11 11:02
閱讀 4244·2023-01-11 11:02
閱讀 3050·2023-01-11 11:02
閱讀 5181·2023-01-11 11:02
閱讀 4737·2023-01-11 11:02
閱讀 5534·2023-01-11 11:02
閱讀 5313·2023-01-11 11:02
閱讀 3990·2023-01-11 11:02


