
摘要:如果編寫的并發程序出現問題時,很難通過調試來解決相應的問題,此時,需要一行行的檢查代碼,這個時候,如果充分理解并掌握了Java的內存模型,你就能夠很快分析并定位出問題所在。
本文分享自華為云社區??《 【高并發】如何解決可見性和有序性問題?這次徹底懂了!》??,作者:冰 河 。
今天,我們先來看看在Java中是如何解決線程的可見性和有序性問題的,說到這,就不得不提一個Java的核心技術,那就是——Java的內存模型。
如果編寫的并發程序出現問題時,很難通過調試來解決相應的問題,此時,需要一行行的檢查代碼,這個時候,如果充分理解并掌握了Java的內存模型,你就能夠很快分析并定位出問題所在。
什么是Java內存模型?
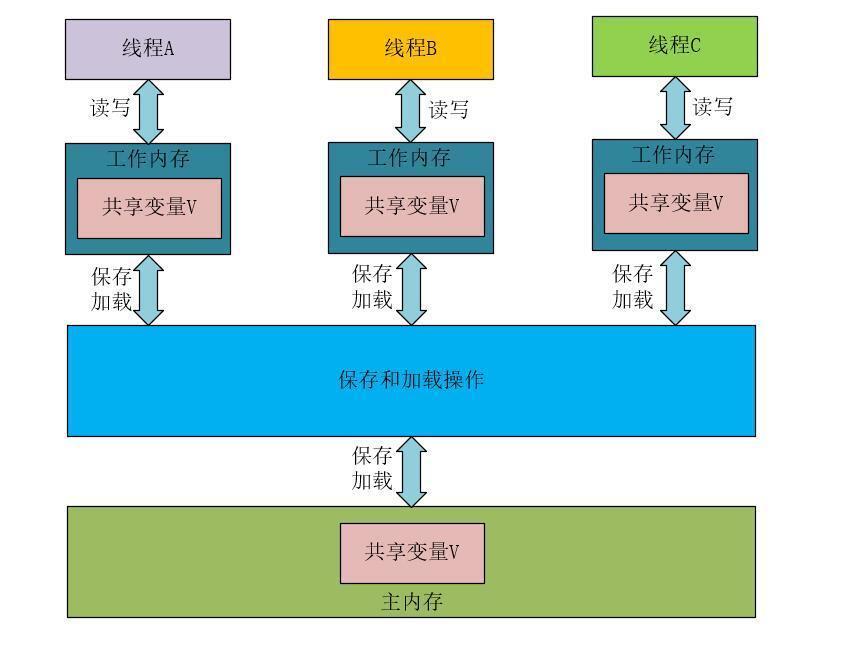
在內存里,Java內存模型規定了所有的變量都存儲在主內存(物理內存)中,每條線程還有自己的工作內存,線程對變量的所有操作都必須在工作內存中進行。不同的線程無法訪問其他線程的工作內存里的內容。我們可以使用下圖來表示在邏輯上 線程、主內存、工作內存的三者交互關系。
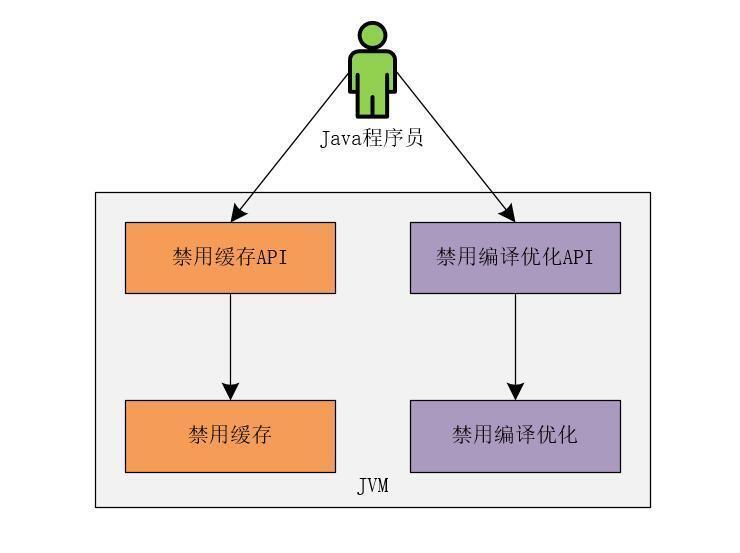
現在,我們都理解了緩存導致了可見性問題,編譯優化導致了有序性問題。也就是說解決可見性和有序性問題的最直接的辦法就是禁用緩存和編譯優化。但是,如果只是簡單的禁用了緩存和編譯優化,那我們寫的所謂的高并發程序的性能也就高不到哪去了!甚至會和單線程程序的性能沒什么兩樣!有時,由于競爭鎖的存在,可能會比單線程程序的性能還要低。
那么,既然不能完全禁用緩存和編譯優化,那如何解決可見性和有序性的問題呢?其實,合理的方案應該是按照需要禁用緩存和編譯優化。什么是按需禁用緩存和編譯優化呢?簡單點來說,就是需要禁用的時候禁用,不需要禁用的時候就不禁用。有些人可能會說,這不廢話嗎?其實不然,我們繼續向下看。
何時禁用和不禁用緩存和編譯優化,可以根據編寫高并發程序的開發人員的要求來合理的確定(這里需要重點理解)。所以,可以這么說,為了解決可見性和有序性問題,Java只需要提供給Java程序員按照需要禁用緩存和編譯優化的方法即可。
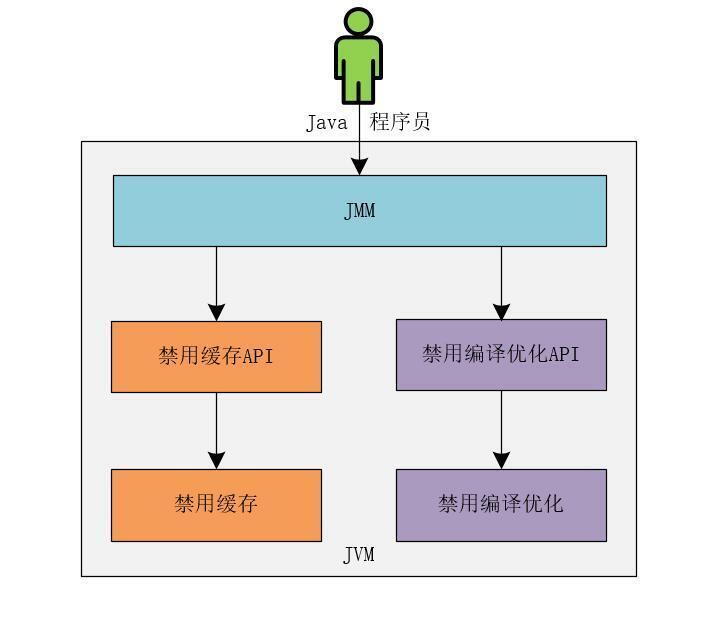
Java內存模型是一個非常復雜的規范,網上關于Java內存模型的文章很多,但是大多數說的都是理論,理論說多了就成了廢話。這里,我不會太多的介紹Java內存模型那些晦澀難懂的理論知識。 其實,作為開發人員,我們可以這樣理解Java的內存模型:Java內存模型規范了Java虛擬機(JVM)如何提供按需禁用緩存和編譯優化的方法。
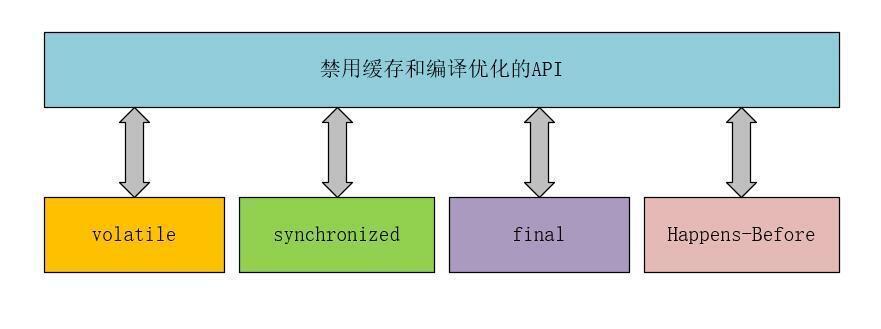
說的具體一些,這些方法包括:volatile、synchronized和final關鍵字,以及Java內存模型中的Happens-Before規則。
volatile為何能保證線程間可見?
volatile關鍵字不是Java特有的,在C語言中也存在volatile關鍵字,這個關鍵字最原始的意義就是禁用CPU緩存。
例如,我們在程序中使用volatile關鍵字聲明了一個變量,如下所示。
volatile int count = 0
此時,Java對這個變量的讀寫,不能使用CPU緩存,必須從內存中讀取和寫入。
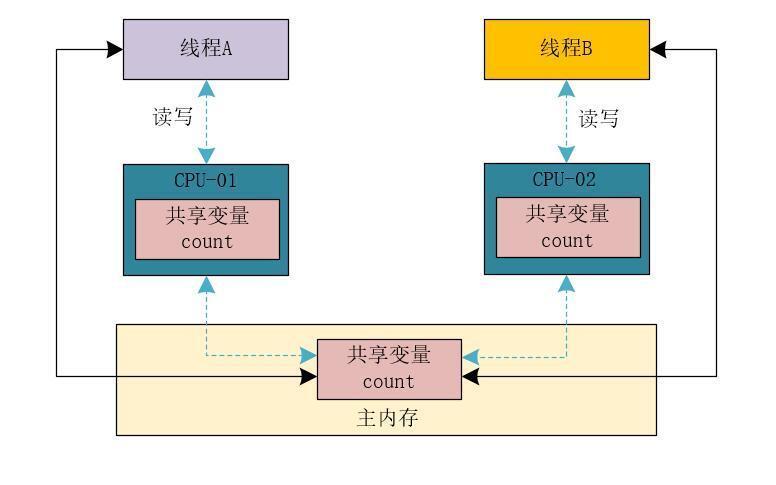
藍色的虛線箭頭代表禁用了CPU緩存,黑色的實線箭頭代表直接從主內存中讀寫數據。
接下來,我們一起來看一個代碼片段,如下所示。
【示例一】
class VolatileExample {
int x = 0;
volatile boolean v = false;
public void writer() {
x = 1;
v = true;
}
public void reader() {
if (v == true) {
//x的值是多少呢?
}
}
}以上示例來源于:http://www.cs.umd.edu/~pugh/java/memoryModel/jsr-133-faq.html#finalWrong
這里,假設線程A執行writer()方法,按照volatile會將v=true寫入內存;線程B執行reader()方法,按照volatile,線程B會從內存中讀取變量v,如果線程B讀取到的變量v為true,那么,此時的變量x的值是多少呢??
這個示例程序給人的直覺就是x的值為1,其實,x的值具體是多少和JDK的版本有關,如果使用的JDK版本低于1.5,則x的值可能為1,也可能為0。如果使用1.5及1.5以上版本的JDK,則x的值就是1。
看到這個,就會有人提出問題了?這是為什么呢?其實,答案就是在JDK1.5版本中的Java內存模型中引入了Happens-Before原則。
Happens-Before原則
我們可以將Happens-Before原則總結成如下圖所示。
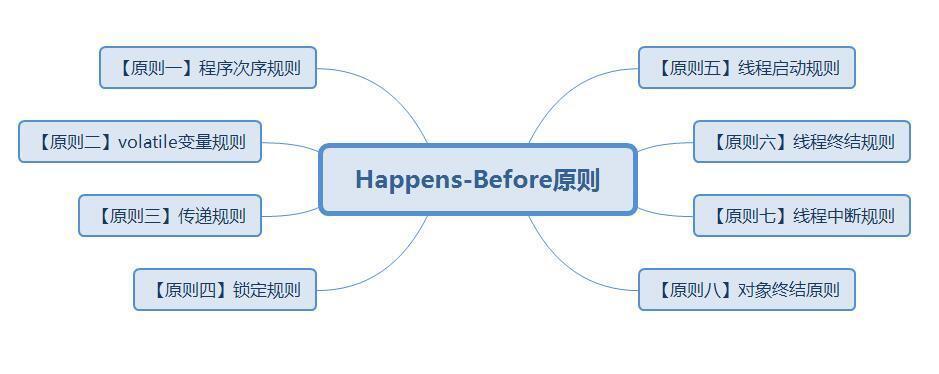
接下來,我們就結合案例程序來說明Java內存模型中的Happens-Before原則。
【原則一】程序次序規則
在一個線程中,按照代碼的順序,前面的操作Happens-Before于后面的任意操作。
例如【示例一】中的程序x=1會在v=true之前執行。這個規則比較符合單線程的思維:在同一個線程中,程序在前面對某個變量的修改一定是對后續操作可見的。
【原則二】volatile變量規則
對一個volatile變量的寫操作,Happens-Before于后續對這個變量的讀操作。
也就是說,對一個使用了volatile變量的寫操作,先行發生于后面對這個變量的讀操作。這個需要大家重點理解。
【原則三】傳遞規則
如果A Happens-Before B,并且B Happens-Before C,則A Happens-Before C。
我們結合【原則一】、【原則二】和【原則三】再來看【示例一】程序,此時,我們可以得出如下結論:
(1)x = 1 Happens-Before 寫變量v = true,符合【原則一】程序次序規則。
(2)寫變量v = true Happens-Before 讀變量v = true,符合【原則二】volatile變量規則。
再根據【原則三】傳遞規則,我們可以得出結論:x = 1 Happens-Before 讀變量v=true。
也就是說,如果線程B讀取到了v=true,那么,線程A設置的x = 1對線程B就是可見的。換句話說,就是此時的線程B能夠訪問到x=1。
其實,Java 1.5版本的 java.util.concurrent并發工具就是靠volatile語義來實現可見性的。
【原則四】鎖定規則
對一個鎖的解鎖操作 Happens-Before于后續對這個鎖的加鎖操作。
例如,下面的代碼,在進入synchronized代碼塊之前,會自動加鎖,在代碼塊執行完畢后,會自動釋放鎖。
【示例二】
public class Test{
private int x = 0;
public void initX{
synchronized(this){ //自動加鎖
if(this.x < 10){
this.x = 10;
}
} //自動釋放鎖
}
}我們可以這樣理解這段程序:假設變量x的值為10,線程A執行完synchronized代碼塊之后將x變量的值修改為10,并釋放synchronized鎖。當線程B進入synchronized代碼塊時,能夠獲取到線程A對x變量的寫操作,也就是說,線程B訪問到的x變量的值為10。
【原則五】線程啟動規則
如果線程A調用線程B的start()方法來啟動線程B,則start()操作Happens-Before于線程B中的任意操作。
我們也可以這樣理解線程啟動規則:線程A啟動線程B之后,線程B能夠看到線程A在啟動線程B之前的操作。
我們來看下面的代碼。
【示例三】
//在線程A中初始化線程B
Thread threadB = new Thread(()->{
//此處的變量x的值是多少呢?答案是100
});
//線程A在啟動線程B之前將共享變量x的值修改為100
x = 100;
//啟動線程B
threadB.start();
上述代碼是在線程A中執行的一個代碼片段,根據【原則五】線程的啟動規則,線程A啟動線程B之后,線程B能夠看到線程A在啟動線程B之前的操作,在線程B中訪問到的x變量的值為100。
【原則六】線程終結規則
線程A等待線程B完成(在線程A中調用線程B的join()方法實現),當線程B完成后(線程A調用線程B的join()方法返回),則線程A能夠訪問到線程B對共享變量的操作。
例如,在線程A中進行的如下操作。
【示例四】
Thread threadB = new Thread(()-{
//在線程B中,將共享變量x的值修改為100
x = 100;
});
//在線程A中啟動線程B
threadB.start();
//在線程A中等待線程B執行完成
threadB.join();
//此處訪問共享變量x的值為100【原則七】線程中斷規則
對線程interrupt()方法的調用Happens-Before于被中斷線程的代碼檢測到中斷事件的發生。
例如,下面的程序代碼。在線程A中中斷線程B之前,將共享變量x的值修改為100,則當線程B檢測到中斷事件時,訪問到的x變量的值為100。
【示例五】
//在線程A中將x變量的值初始化為0
private int x = 0;
public void execute(){
//在線程A中初始化線程B
Thread threadB = new Thread(()->{
//線程B檢測自己是否被中斷
if (Thread.currentThread().isInterrupted()){
//如果線程B被中斷,則此時X的值為100
System.out.println(x);
}
});
//在線程A中啟動線程B
threadB.start();
//在線程A中將共享變量X的值修改為100
x = 100;
//在線程A中中斷線程B
threadB.interrupt();
}
【原則八】對象終結原則
一個對象的初始化完成Happens-Before于它的finalize()方法的開始。
例如,下面的程序代碼。
【示例六】
public class TestThread {
public TestThread(){
System.out.println("構造方法");
}
@Override
protected void finalize() throws Throwable {
System.out.println("對象銷毀");
}
public static void main(String[] args){
new TestThread();
System.gc();
}
}?運行結果如下所示。
構造方法
對象銷毀
再說final關鍵字
使用final關鍵字修飾的變量,是不會被改變的。但是在Java 1.5之前的版本中,使用final修飾的變量也會出現錯誤的情況,在Java 1.5版本之后,Java內存模型對使用final關鍵字修飾的變量的重排序進行了一定的約束。只要我們能夠提供正確的構造函數就不會出現問題。
例如,下面的程序代碼,在構造函數中將this賦值給了全局變量global.obj,此時對象初始化還沒有完成,此時對象初始化還沒有完成,此時對象初始化還沒有完成,重要的事情說三遍!!線程通過global.obj讀取的x值可能為0。
【示例七】
final x = 0;
public FinalFieldExample() { // bad!
x = 3;
y = 4;
// bad construction - allowing this to escape
global.obj = this;
}
以上示例來源于:http://www.cs.umd.edu/~pugh/java/memoryModel/jsr-133-faq.html#finalWrong
Java內存模式的底層實現
主要是通過內存屏障(memory barrier)禁止重排序的, 即時編譯器根據具體的底層體系架構, 將這些內存屏障替換成具體的 CPU 指令。 對于編譯器而言,內存屏障將限制它所能做的重排序優化。 而對于處理器而言, 內存屏障將會導致緩存的刷新操作。 比如, 對于volatile, 編譯器將在volatile字段的讀寫操作前后各插入一些內存屏障。





