資訊專欄INFORMATION COLUMN

摘要:如果截斷長度為,位置編碼的,下圖是的在中給出了一種新的相對位置編碼,幾乎是和經典的絕對位置編碼一一對應。只是把絕對位置編碼替換成相對位置編碼,在兩個任務上都有的效果提升,最終效果也基本和一致。
這一章我們主要關注transformer在序列標注任務上的應用,作為2017年后最熱的模型結構之一,在序列標注任務上原生transformer的表現并不盡如人意,效果比bilstm還要差不少,這背后有哪些原因? 解決這些問題后在NER任務上transformer的效果如何?完整代碼詳見ChineseNER
Hang(2019)在TENER的論文中給出了兩點原因
1. 三角函數絕對位置編碼只考慮距離沒有考慮方向
2. 距離表達在向量project以后也會消失
我們先來回顧下原生Transformer的絕對位置編碼, 最初編碼的設計是為了滿足幾個條件
于是便有了基于三角函數的編碼方式,在pos位置,維度是/(d_k/)的編碼中,第i個元素的計算如下
基于三角函數的絕對位置編碼是常數,并不隨模型更新。在Transformer中,位置編碼會直接加在詞向量上,輸入的詞向量Embedding是E,在self-attention中Q,K進行線性變換后計算attention,對value進行加權得到輸出如下
我們來對/(q_ik_j/)部分進行展開可以得到
其中位置交互是唯一可能包含相對位置信息的部分,如果不考慮線性變換/(w_k/),/(w_q/)只看三角函數位置編碼,會發現位置編碼內積是相對距離的函數,如下
不同維度/(d_k/),/(P_iP_j^T/)和/(/Delta/)的關系如下,會發現位置編碼內積是對稱并不包含方向信息,而BiLSTM是可以通過雙向LSTM引入方向信息的。對于需要全局信息的任務例如翻譯,sentiment analysis,方向信息可能并不十分重要,但對于局部優化的NER任務,因為需要判斷每個token的類型,方向信息的缺失影響更大。
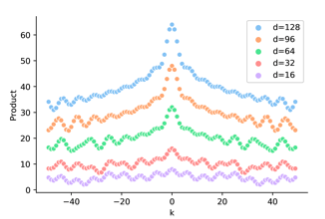
看完三角函數部分,我們把線性變換加上,下圖是加入隨機線性變換后/(P_iw_iw_j^TP_j^T/)和/(/Delta/)的關系,會發現位置編碼的相對距離感知消失了,有人會問那這位置編碼有啥用,這是加了個寂寞???

個人感覺上圖的效果是加入隨機變換得到,而/(W_i,W_j/)本身是trainable的,所以如果相對距離信息有用,/(W_iW_j^T/)未必學不到,這里直接用隨機/(W_i/)感覺并不完全合理。But Anyway這兩點確實部分解釋了原生transformer在NER任務上效果打不過BiLSTM的原因。下面我們來看下基于絕對位置編碼的缺陷,都有哪些改良
既然相對位置信息是在self-attention中丟失的,最直觀的方案就是顯式的在self-attention中把相對位置信息加回來。相對位置編碼有很多種構建方案,這里我們只回顧TENER之前相對經典的兩種(這里參考了蘇神的讓研究人員絞盡腦汁的Transformer位置編碼再一次膜拜大神~)。為了方便對比,我們把經典的絕對位置編碼計算的self-attenion展開再寫一遍
(shaw et al,2018) 提出的RPR可以說是相對位置編碼的起源,計算也最簡單,只保留了以上Attention的語義交互部分,把key的絕對位置編碼,替換成key&Query的相對位置編碼,同時在對value加權時也同時引入相對位置,得到如下
這里/(R_{ij}/)是query第i個字符和key/value第j個字符之間的相對距離j-i的位置編碼,query第2個字符和key第4個字符交互對應/(R_{-2}/)的位置編碼。這樣的編碼方式直接考慮了距離和方向信息。
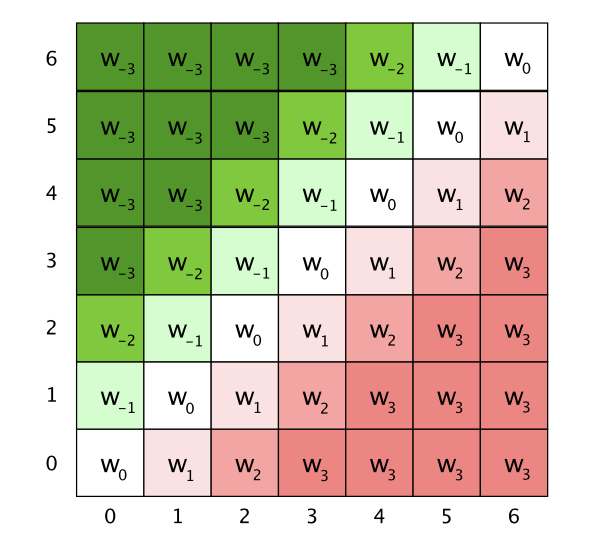
這里的位置編碼PE是trainable的變量,為了控制模型參數的大小,同時保證位置編碼可以generalize到任意文本長度,對相對位置做了截斷,畢竟當前字符確實不太可能和距離太遠的字符之前存在上下文交互,所以滑動窗口的設計也很合理。如果截斷長度為k,位置編碼PE的dim=2k+1,下圖是k=3的/(R_{ij}/)
(Dai et al,2019)在Transformer-XL中給出了一種新的相對位置編碼,幾乎是和經典的絕對位置編碼一一對應。
以上計算方案也被XLNET沿用,和RPR相比,Transfromer-XL
TENER是transformer在NER任務上的模型嘗試,文章沒有太多的亮點,更像是一篇用更合適的方法來解決問題的工程paper。沿用了Transformer-XL的相對位置編碼, 做了兩點調整,一個是key本身不做project,另一個就是在attention加權時沒用對attenion進行scale, 也就是以下的歸一化不再用/(/sqrt{d_k}/)對query和key的權重進行調整,得到的attenion會更加sharp。這個調整可以讓權重更多focus在每個詞的周邊范圍,更適用于局部建模的NER任務。
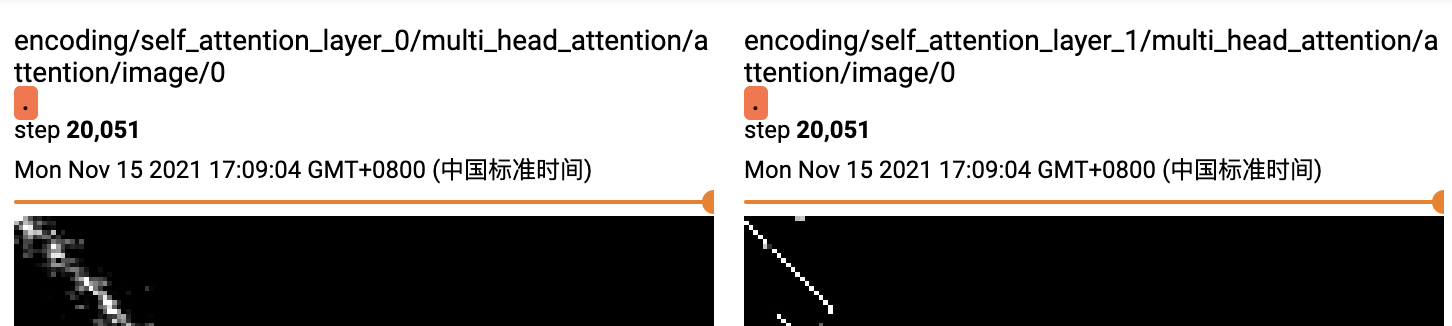
我們來直觀對比下,同樣的數據集和模型參數。絕對位置編碼和unscale的相對位置編碼attention的差異,這里都用了兩層的transformer,上圖是絕對位置編碼,下圖是unscale的相對位置編碼。可以明顯看到unscale的相對位置編碼的權重,在第一層已經學習到部分周圍信息后,第二層的attention范圍進一步縮小集中在詞周圍(一定程度上說明可能1層transfromer就夠用了),而絕對位置編碼則相對分散在整個文本域。

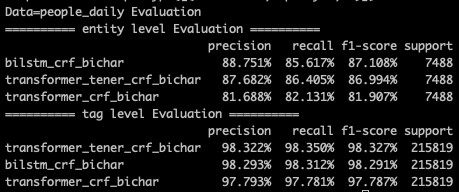
下面來對比下效果,transformer任務默認都是用的bichar輸入,所以我們也和bilstm_bichar進行對比,在原paper中作者除了對句子部分使用transformer來提取信息,還在token粒度做了一層transformer,不過這里為了更公平的和bilstm對比,我們只保留了句子層面的transformer。以下是分別在MSRA和PeopleDaily兩個任務上的效果對比。
只是把絕對位置編碼替換成相對位置編碼,在兩個任務上都有4~5%的效果提升,最終效果也基本和bilstm一致。這里沒做啥hyper search,參數給的比較小,整體上transformer任務擴大embedding,ffnsize效果會再有提升~

文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/123761.html

本文主要是給大家介紹了caffe的python插口生成deploy文件學習培訓及其用練習好一點的實體模型(caffemodel)來歸類新的圖片實例詳細說明,感興趣的小伙伴可以參考借鑒一下,希望可以有一定的幫助,祝愿大家多多的發展,盡早漲薪 caffe的python插口生成deploy文件 假如要將練習好一點的實體模型用于檢測新的圖片,那必然必須得一個deploy.prototxt文件,這一...
摘要:特意對前端學習資源做一個匯總,方便自己學習查閱參考,和好友們共同進步。 特意對前端學習資源做一個匯總,方便自己學習查閱參考,和好友們共同進步。 本以為自己收藏的站點多,可以很快搞定,沒想到一入匯總深似海。還有很多不足&遺漏的地方,歡迎補充。有錯誤的地方,還請斧正... 托管: welcome to git,歡迎交流,感謝star 有好友反應和斧正,會及時更新,平時業務工作時也會不定期更...
小編寫這篇文章的一個主要目的,主要是給大家去做一個解答,解答的內容主要還是python相關事宜,比如,可以用python正則表達式去匹配和提取中文漢字,那么,具體的內容做法是什么呢?下面就給大家詳細解答下。 python用正則表達式提取中文 Python re正則匹配中文,其實非常簡單,把中文的unicode字符串轉換成utf-8格式就可以了,然后可以在re中隨意調用 unicode中中...
摘要:方法的參數不但可以使相對于上下文根的路徑,而且可以是相對于當前的路徑。如和都是合法的路徑。 轉發與重定向區別是什么 在調用方法上 轉發 調用 HttpServletRequest 對象的方法 request.getRequestDispatcher(test.jsp).forward(req, resp); 重定向 調用 HttpServletResponse 對象的方法 res...
小編寫這篇文章的主要目的,主要是用來給大家解釋,Python Sklearn當中,一些實用的隱藏功能,大概有19條,這些實用的隱藏技能,會給我們的工作和生活帶來很大的便利性,具體下文就給大家詳細的介紹一下。 今天跟大家介紹19個Sklearn中超級實用的隱藏的功能,這些功能雖然不常見,但非常實用,它們可以直接優雅地替代手動執行的常見操作。接下來我們就一個一個介紹這些功能,希望對大家有所幫助!...

閱讀 1695·2021-11-24 09:39
閱讀 2469·2021-11-18 10:07
閱讀 3657·2021-08-31 09:40
閱讀 3316·2019-08-30 15:44
閱讀 2627·2019-08-30 12:50
閱讀 3648·2019-08-26 17:04
閱讀 1429·2019-08-26 13:49
閱讀 1262·2019-08-23 18:05



