資訊專欄INFORMATION COLUMN

摘要:偽分布模式在單節(jié)點(diǎn)上同時啟動等個進(jìn)程,模擬分布式運(yùn)行的各個節(jié)點(diǎn)。完全分布式模式正常的集群,由多個各司其職的節(jié)點(diǎn)構(gòu)成。在之前在集群中存在單點(diǎn)故障。正確的下載鏈接會有,這個就是公司需要用戶在下載時提供的注冊信息。
每一次 Hadoop 生態(tài)的更新都是如此令人激動
像是 hadoop3x 精簡了內(nèi)核,spark3 在調(diào)用 R 語言的 UDF 方面,速度提升了 40 倍
所以該文章肯定得配備上最新的生態(tài)

OS :
組件:
可選項
- Hive
- Flume 1.9
- Sqoop 2
- kafka 2x
- Spark 3x
RDMS:
開發(fā)語言:
集群規(guī)劃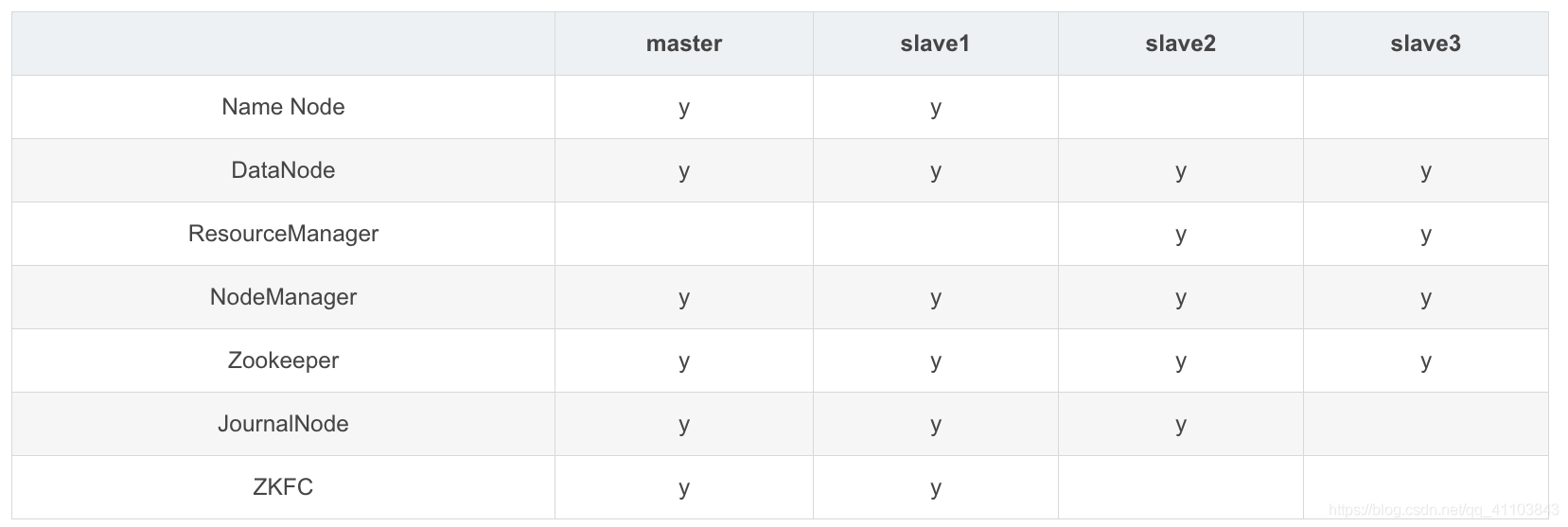
建議:Zookeeper、JournalNode 節(jié)點(diǎn)為奇數(shù)
- 防止由腦裂造成的集群不可用
- leader 選舉,要求 可用節(jié)點(diǎn)數(shù)量 > 總節(jié)點(diǎn)數(shù)量/2 ,節(jié)省資源
Hadoop 安裝有如下三種方式:
此文采用 HA方案 進(jìn)行部署
可選方案:
此文采用 多臺物理機(jī) 方案
共 4 臺物理設(shè)備
此文采用版本:Centos7.4 x64
建議:百度網(wǎng)盤 centos7.4 密碼: 8jwf
鏡像刻錄不進(jìn)行介紹
請參考:
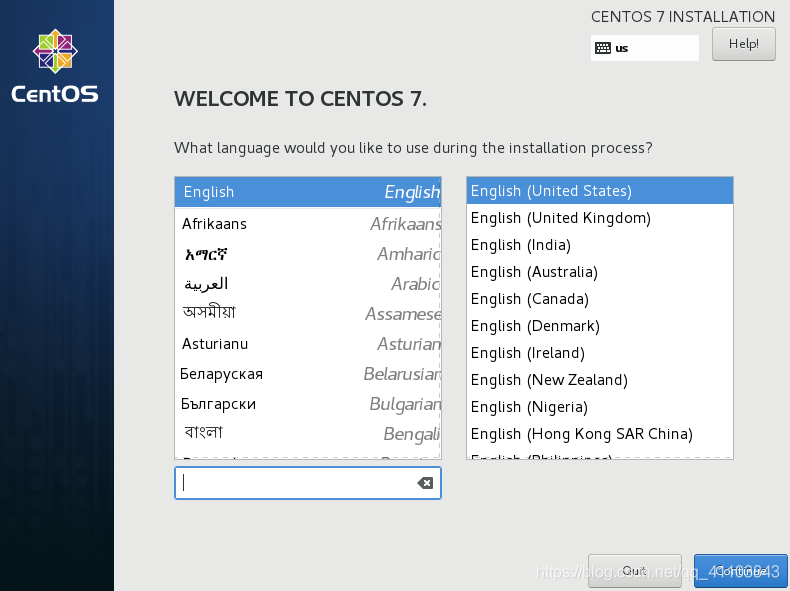
選擇語言:
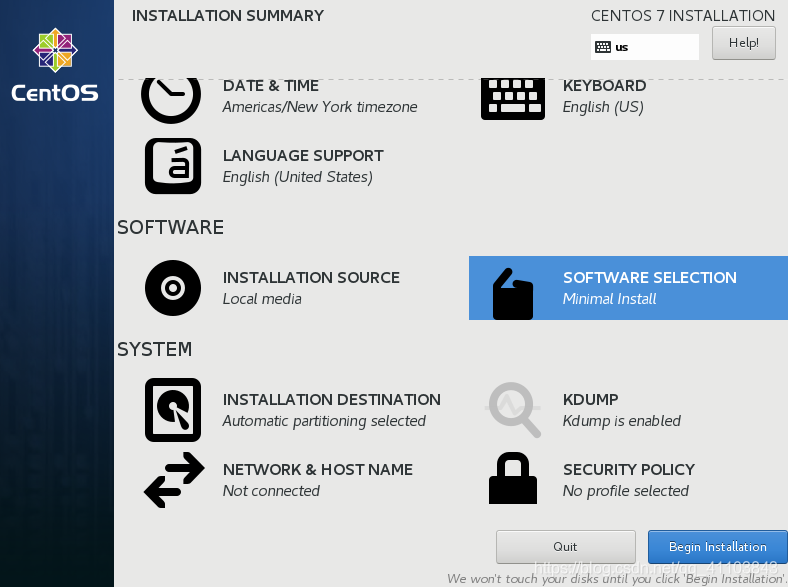
采用最小安裝方案
> >
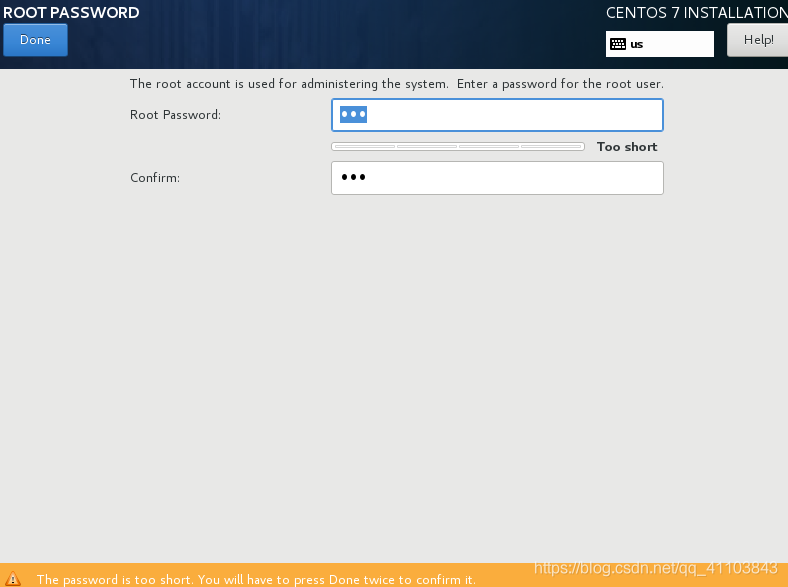
設(shè)置 root 密碼
點(diǎn)擊 ROOT PASSWORD 設(shè)置 root 密碼,不用添加用戶
> >
等待完成
完成之后點(diǎn)擊Reboot > >
該節(jié)點(diǎn)為虛擬機(jī)的朋友提供幫助
1)共享網(wǎng)絡(luò)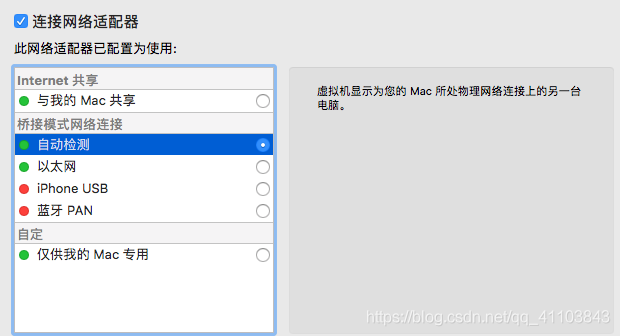
2)選擇橋接模式
1)查找配置文件
find / -name ifcfg-*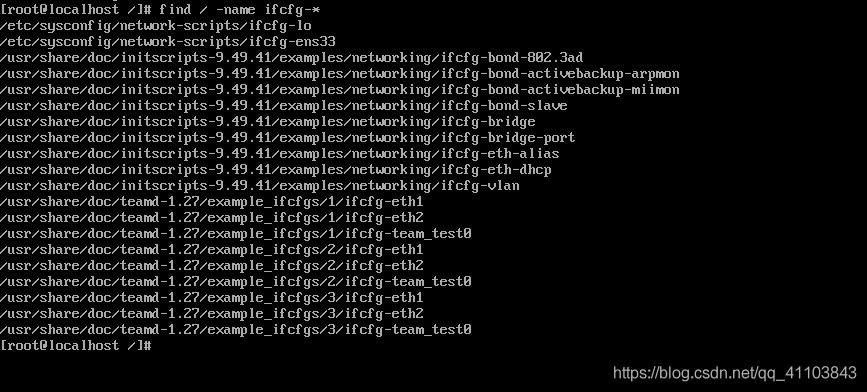
2)修改你 etc 目錄下,并以你網(wǎng)卡名結(jié)尾的文件
# 這里舉例我的vi /etc/sysconfig/network-scripts/ifcfg-ens33動態(tài) IP 修改操作:
- 啟用 dhcp
- 注釋 ipaddr 和 gateway
- onboot 設(shè)置為 yes
建議做如下修改
修改為靜態(tài) IP
# 修改BOOTPROTO="static" #dhcp改為staticONBOOT="yes" #開機(jī)啟用本配置# 添加IPADDR=192.168.x.x #靜態(tài)IPGATEWAY=192.168.x.x #默認(rèn)網(wǎng)關(guān)NETMASK=255.255.255.0 #子網(wǎng)掩碼DNS1=你本機(jī)的dns配置 #DNS 配置3)重啟服務(wù)
service network restart4)ping 一下我的博客試試
ping uiuing.com
安裝 net-tools
yum -y install net-tools查看 ip
ifconfig打開客戶端終端進(jìn)行 ssh 連接
ssh root@yourip此文采用版本:mysql5.7
登陸 centos
yum -y install gcc gcc-c++ ncurses ncurses-devel cmakeMysql5.7 版本更新后有很多變化,安裝必須要 BOOST 庫(版本需為 1.59.0)
boost 庫下載地址:boost
1)下載
wget https://jaist.dl.sourceforge.net/project/boost/boost/1.59.0/boost_1_59_0.tar.gz2)檢查 MD5 值,若不匹配則需要重新下載
md5sum boost_1_59_0.tar.gz3)解壓
tar -vxzf boost_1_59_0.tar.gz4)存儲
mv boost_1_59_0 /usr/local/boost_1_59_0安裝 wget
yum -y install wget官方下載地址:mysql
1)下載
wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.21.tar.gz2)檢查 MD5 值,若不匹配則需要重新下載
md5sum mysql-5.7.21.tar.gz1)解壓
tar -vxzf mysql-5.7.21.tar.gz2)編譯
cmake ./make3)安裝
make install啟動
systemctl start mysqld或者
systemctl start | stop查看 mysql 狀態(tài)
systemctl status mysqld或者
systemctl status開機(jī)自啟(可選)
systemctl enable mysqld重載配置(可選)
systemctl daemon-reload配置 root 密碼
1)生成默認(rèn)密碼
grep temporary password /var/log/mysqld.log
localhost 后面的就是你的 root 密碼
2)修改密碼
登陸 mysql
mysql -uroot -p你的密碼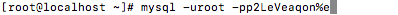
修改密碼
ALTER USER root@localhost IDENTIFIED BY 你的密碼;注意:mysql 5.7 默認(rèn)安裝了密碼安全檢查插件(validate_password),默認(rèn)密碼檢查策略要求密碼必須包含:大小寫字母、數(shù)字和特殊符號,并且長度不能少于8位
以后可以用 update 更新密碼
use mysql;update user set password=PASSWORD(你的密碼) where user=root;flush privileges;添加遠(yuǎn)程用戶(可選)
GRANT ALL PRIVILEGES ON *.* TO 用戶名@% IDENTIFIED BY 密碼 WITH GRANT OPTION;use mysql;UPDATE user SET Host=% WHERE User=用戶名;flush privileges;配置文件:/etc/my.cnf
日志文件:/var/log/mysqld.log
服務(wù)啟動腳本:/usr/lib/systemd/system/mysqld.service
socket 文件:/var/run/mysqld/mysqld.pid
此文采用版本:JDK8
安裝文本編輯器 vim
yum -y install vimJDK 官方下載地址:oracle jdk
使用命令下載:
wget https://download.oracle.com/otn/java/jdk/8u291-b10/d7fc238d0cbf4b0dac67be84580cfb4b/jdk-8u291-linux-x64.tar.gz?AuthParam=1619936099_3a37c8b389365d286242f4b1aa4967b0因為 oracle 公司不允許直接通過 wget 下載官網(wǎng)上的 jdk 包
正確做法:
通過搜索引擎搜索 jdk 官網(wǎng)下載, 進(jìn)入 oracle 官網(wǎng)
勾選 accept licence agreement ,并選擇你系統(tǒng)對應(yīng)的版本
點(diǎn)擊對應(yīng)的版本下載,彈出如下下載框,然后復(fù)制下載鏈接
這個復(fù)制的鏈接結(jié)算我們 wget 命令的地址。
正確的下載鏈接會有”AuthParam“,這個就是 oracle 公司需要用戶在下載時提供的注冊信息。而且這個信息是用時間限制的,過了一段時間后就會失效,如果你想再次下載 jdk 包,只能再次重復(fù)上面的操作。
檢查大小
ls -lht
查看文件名(用于解壓)
ls創(chuàng)建文件夾
mkdir /usr/local/java解壓
tar -zxvf 你的jdk包名 -C /usr/local/java/查看文件名(用于配置環(huán)境變量)
ls /usr/local/java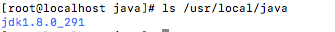
打開配置文件
vi /etc/profile在末尾添加
# jdk8 # 添加jdk地址變量 JAVA_HOME=/usr/local/java # 添加jre地址變量 JRE_HOME=${JAVA_HOME}/jre # 添加java官方庫地址變量 CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib # 添加PATH地址變量 PATH=${JAVA_HOME}/bin:$PATH # 使變量生效 export JAVA_HOME JRE_HOME CLASSPATH PATH刷新配置文件
source /etc/profile添加軟鏈接(可選)
ln -s /usr/local/java/jdk1.8.0_291/bin/java /usr/bin/java檢查
java -version
此文采用版本:Python3.6
我們已經(jīng)掌握了二進(jìn)制包安裝的方法,所以我們直接通過 yum 來安裝 Python
yum -y install python36依賴:python36-libs
安裝 pip3(默認(rèn)已安裝)
yum install python36-pip -y檢查
python3 --version
此文采用版本:Scala2.11.7
請確保已安裝JDK8或者JDK11
Scala 官方下載地址:Scala
使用命令下載:
wget https://downloads.lightbend.com/scala/2.11.7/scala-2.11.7.tgz檢查大小
ls -lht查看文件名(用于解壓)
ls創(chuàng)建文件夾
mkdir /usr/local/scala解壓
tar -zxvf 你的jdk包名 -C /usr/local/scala/查看文件名(用于配置環(huán)境變量)
ls /usr/local/scala
打開配置文件
vi /etc/profile在末尾添加
# scala 2.11.7 # 添加scala執(zhí)行文件地址變量 SCALA_HOME=/usr/local/scala/scala-2.11.7 # 添加PATH地址變量 PATH=$PATH:$SCALA_HOME/bin # 使變量生效 export SCALA_HOME PATH刷新配置文件
source /etc/profile檢查
scala -version
使用虛擬機(jī)的朋友請直接克隆
切記要返回第四步驟更改各節(jié)點(diǎn)ip,不然會發(fā)生ip沖突
1)備份
前往根目錄
cd /備份
tar cvpzf backup.tgz / --exclude=/proc --exclude=/lost+found --exclude=/mnt --exclude=/sys --exclude=backup.tgz備份完成后,在文件系統(tǒng)的根目錄將生成一個名為“backup.tgz”的文件,它的尺寸有可能非常大。你可以把它燒錄到 DVD 上或者放到你認(rèn)為安全的地方去
在備份命令結(jié)束時你可能會看到這樣一個提示:’tar: Error exit delayed from previous
errors’,多數(shù)情況下你可以忽略
2)準(zhǔn)備
別忘了到其他設(shè)備下重新創(chuàng)建那些在備份時被排除在外的目錄(如果不存在):
mkdir procmkdir lost+foundmkdir mntmkdir sys3)復(fù)刻
可選前提:
到其他物理機(jī)上恢復(fù)文件
tar xvpfz backup.tgz -C /恢復(fù) SELinux 文件屬性
restorecon -Rv /1)修改 hostname
到各設(shè)備下執(zhí)行
# 設(shè)備 1 (立即生效)hostnamectl set-hostname master# 設(shè)備 2 (立即生效)hostnamectl set-hostname slave1# 設(shè)備 3 (立即生效)hostnamectl set-hostname slave2# 設(shè)備 4 (立即生效)hostnamectl set-hostname slave32)配置 host 文件
查看各設(shè)備 ip(到各設(shè)備下執(zhí)行)
ifconfig到 master 下打開 host 文件
vim /etc/hosts末尾追加
master設(shè)備的ip masterslave1設(shè)備的ip masterslave2設(shè)備的ip masterslave3設(shè)備的ip master3)通過 scp 傳輸 host 文件
scp 語法:scp 文件名 遠(yuǎn)程主機(jī)用戶名@遠(yuǎn)程主機(jī)名或ip:存放路徑
到 master 下執(zhí)行
scp /etc/hosts root@SlaveIP:/etc/注意:請按照 slave 個數(shù),對其 ip 枚舉傳輸
ping 一下
ping -c 4 slave1能 ping 通就沒問題
以下操作均在master下執(zhí)行
1)到各設(shè)備下生成密鑰
ssh-keygen -t rsa一路回車
到 master 生成公鑰
cd ~/.ssh/ && cat id_rsa.pub > authorized_keys之后將各設(shè)備的密鑰全復(fù)制到authorized_keys文件里
2)通過 scp 傳輸公鑰
到 master 下執(zhí)行
scp authorized_keys root@SlaveNumbe:~/.ssh/注意:請按照之前設(shè)置的 hostname ,對其 ip 枚舉傳輸
例如: scp authorized_keys root@slave1:~/.ssh/
注意,如果各節(jié)點(diǎn)下沒有 ~/.ssh/ 目錄則會配置失敗
檢查
ssh slave1
中斷該 ssh 連接(可選)
exit該配置主要方便客戶端遠(yuǎn)程操作
無論是用虛擬機(jī)進(jìn)行學(xué)習(xí)的朋友,還是工作的朋友都強(qiáng)烈推薦
以下操作均在客戶端(MAC OS)上執(zhí)行
修改 hots 文件
sudo vim /etc/hosts將 master 設(shè)備下/etc/hosts 之前追加的內(nèi)容,copy 追加到客戶端 hosts 末尾
ping 一下,能 ping 通就沒問題
免密鑰 ssh 登陸
客戶端生產(chǎn)密鑰:
sudo ssh-keygen -t rsa打開密鑰
vim ~/.ssh/id_rsa到 master 內(nèi)向各節(jié)點(diǎn)申請同步
scp authorized_keys root@SlaveNumbe:~/.ssh/windows ssh 目錄:C:/Users/your_userName.ssh
檢查
ssh master
此文采用版本 ZooKeepr3.6.3
官方下載地址:Zookeeper記得下載帶bin字樣的
從客戶端上下載 壓縮包
到 master 節(jié)點(diǎn)上創(chuàng)建 zookeeper 文件夾
mkdir /usr/local/zookeeper從客戶端上傳到 master
scp 你下載的Zookeeper路徑 root@master:/usr/local/zookeeper以下操作切換至master節(jié)點(diǎn)上
解壓
cd /usr/local/zookeeper tar xf apache-zookeeper-3.6.3-bin.tar.gz打開配置文件
vim /etc/profile在末尾添加
# ZooKeeper3.6.3 # 添加zookeeper地址變量 ZOOKEEPER_HOME=/usr/local/zookeeper/apache-zookeeper-bin.3.6.3 # 添加PATH地址變量 PATH=$ZOOKEEPER_HOME/bin:$PATH # 使變量生效 export ZOOKEEPER_HOME PATH刷新配置文件
source /etc/profile創(chuàng)建數(shù)據(jù)目錄
mkdir /zookeepermkdir /zookeeper/datamkdir /zookeeper/logs# 同步# 自行枚舉添加配置文件
cp $ZOOKEEPER_HOME/conf/zoo_sample.cfg $ZOOKEEPER_HOME/conf/zoo.cfgvim $ZOOKEEPER_HOME/conf/zoo.cfg修改和添加
tickTime=2000initLimit=10syncLimit=5dataDir=/zookeeper/datadataLogDir=/zookeeper/logsclientPort=2181server.1=master:2888:3888server.2=slea1:2888:3888server.3=slea2:2888:3888server.4=slea3:2888:3888:observer到 master 下執(zhí)行請根據(jù)節(jié)點(diǎn)個數(shù)枚舉執(zhí)行
同步文件
scp /etc/profile root@slave1:/etc/scp -r /zookeeper root@slave1:/scp -r /usr/local/zookeeper root@slave1:/usr/local/配置節(jié)點(diǎn)標(biāo)識
參考資資料:leader 選舉
ssh master "echo "9" > /zookeeper/data/myid"ssh slave1 "echo "1" > /zookeeper/data/myid"ssh slave2 "echo "2" > /zookeeper/data/myid"ssh slave3 "echo "3" > /zookeeper/data/myid"防火墻配置
#開放端口firewall-cmd --add-port=2181/tcp --permanentfirewall-cmd --add-port=2888/tcp --permanentfirewall-cmd --add-port=3888/tcp --permanent#重新加載防火墻配置firewall-cmd --reload節(jié)點(diǎn)批量執(zhí)行
# master節(jié)點(diǎn)ssh master "firewall-cmd --add-port=2181/tcp --permanent && firewall-cmd --add-port=2888/tcp --permanent && firewall-cmd --add-port=3888/tcp --permanent && firewall-cmd --reload "# slave1節(jié)點(diǎn) 其他請自行枚舉執(zhí)行ssh slave1 "firewall-cmd --add-port=2181/tcp --permanent && firewall-cmd --add-port=2888/tcp --permanent && firewall-cmd --add-port=3888/tcp --permanent && firewall-cmd --reload "啟動 ZooKeeper
sh $ZOOKEEPER_HOME/bin/zkServer.sh start編寫批量啟動 shell
vim /bin/zk && chmod 777 /bin/zk#! /bin/shcase $1 in"start"){ echo -e "/e[32m---------------------------------------------------------------------------/033[0m" echo -e "/e[32m...master-start.../033[0m" ssh master "sh $ZOOKEEPER_HOME/bin/zkServer.sh start" echo -e "/e[32m...slave1-start.../033[0m" ssh slave1 "sh $ZOOKEEPER_HOME/bin/zkServer.sh start" echo -e "/e[32m...slave2-start.../033[0m" ssh slave2 "sh $ZOOKEEPER_HOME/bin/zkServer.sh start" echo -e "/e[32m...slave3-start.../033[0m" ssh slave3 "sh $ZOOKEEPER_HOME/bin/zkServer.sh start" echo -e "/e[32m...all-start-end.../033[0m" echo -e "/e[32m---------------------------------------------------------------------------/033[0m"};;"stop"){ echo -e "/e[32m---------------------------------------------------------------------------/033[0m" echo -e "/e[32m...master-stop.../033[0m" ssh master "sh $ZOOKEEPER_HOME/bin/zkServer.sh stop" echo -e "/e[32m...slave1-start.../033[0m" ssh slave1 "sh $ZOOKEEPER_HOME/bin/zkServer.sh stop" echo -e "/e[32m...slave2-start.../033[0m" ssh slave2 "sh $ZOOKEEPER_HOME/bin/zkServer.sh stop" echo -e "/e[32m...slave3-start.../033[0m" ssh slave3 "sh $ZOOKEEPER_HOME/bin/zkServer.sh stop" echo -e "/e[32m...all-stop-end.../033[0m" echo -e "/e[32m---------------------------------------------------------------------------/033[0m"};;"status"){ echo -e "/e[32m---------------------------------------------------------------------------" echo -e "/e[32m...master-status.../033[0m" ssh master "sh $ZOOKEEPER_HOME/bin/zkServer.sh status" echo -e "/e[32m...slave1-start.../033[0m" ssh slave1 "sh $ZOOKEEPER_HOME/bin/zkServer.sh status" echo -e "/e[32m...slave2-start.../033[0m" ssh slave2 "sh $ZOOKEEPER_HOME/bin/zkServer.sh status" echo -e "/e[32m...slave3-start.../033[0m" ssh slave3 "sh $ZOOKEEPER_HOME/bin/zkServer.sh status" echo -e "/e[32m...all-status-end.../033[0m" echo -e "/e[32m---------------------------------------------------------------------------/033[0m"};;esac命令
# 啟動zk start# 查看狀態(tài)zk status# 關(guān)閉zk stop啟動之后 MODE 和我的顯示一樣就算成功了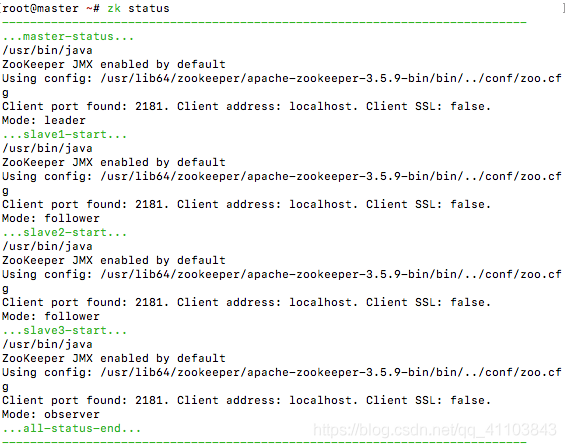
此文采用版本 Hadoop3.2.2
官方下載地址:Hadoop
從客戶端上下載 壓縮包
到 master 節(jié)點(diǎn)上創(chuàng)建 Hadoop 文件夾
mkdir /usr/local/hadoop從客戶端上傳到 master
scp 你下載的hadoop路徑 root@master:/usr/local/hadoop以下操作切換至master節(jié)點(diǎn)上
解壓
cd /usr/local/hadoop tar xf hadoop包名打開配置文件
vim /etc/profile在末尾添加
# Hadoop 3.2.2 # 添加hadoop地址變量 HADOOP_HOME=/usr/local/hadoop/hadoop-3.3.0 # 添加PATH地址變量 PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin # 使變量生效 export HADOOP_HOME PATH# IF HADOOP >= 3x / for root # HDFS HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root HDFS_ZKFC_USER=root # YARN YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root # run export HDFS_DATANODE_USER HADOOP_SECURE_DN_USER HDFS_NAMENODE_USER HDFS_SECONDARYNAMENODE_USER HDFS_ZKFC_USER YARN_RESOURCEMANAGER_USER HADOOP_SECURE_DN_USER YARN_NODEMANAGER_USER請自行使用scp將文件同步至各節(jié)點(diǎn)
刷新配置文件
source /etc/profile創(chuàng)建數(shù)據(jù)目錄
mkdir /hadoopmkdir /hadoop/journaldatamkdir /hadoop/hadoopdata# 同步# 自行枚舉添加 Jdk 環(huán)境
打開文件
vim /usr/local/hadoop/hadoop-3.3.0/etc/hadoop/hadoop-env.sh添加或修改
export JAVA_HOME=/usr/local/java接下來我們要修改的文件:
前往配置文件目錄
cd /usr/local/hadoop/hadoop-3.3.0/etc/hadoop/core-site.xml
fs.defaultFS hdfs://jed hadoop.tmp.dir /hadoop/hadoopdata ha.zookeeper.quorum master:2181,slave1:2181,slave2:2181,slave3:2181 hdfs-site.xml
dfs.replication 2 dfs.nameservices jed dfs.ha.namenodes.jed nn1,nn2 dfs.namenode.rpc-address.jed.nn1 master:9000 dfs.namenode.http-address.jed.nn1 master:50070 dfs.namenode.rpc-address.jed.nn2 slave1:9000 dfs.namenode.http-address.jed.nn2 slave1:50070 dfs.namenode.shared.edits.dir qjournal://master:8485;slave1:8485;slave2:8485/jed dfs.journalnode.edits.dir /hadoop/journaldata dfs.ha.automatic-failover.enabled true dfs.client.failover.proxy.provider.jed org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider dfs.ha.fencing.methods sshfence shell(/bin/true) dfs.ha.fencing.ssh.private-key-files /var/root/.ssh/id_rsa dfs.ha.fencing.ssh.connect-timeout 20000 mapred-site.xml
mapreduce.framework.name yarn mapreduce.jobhistory.address master:10020 mapreduce.jobhistory.webapp.address master:19888 yarn.app.mapreduce.am.env HADOOP_MAPRED_HOME=${HADOOP_HOME} mapreduce.map.env HADOOP_MAPRED_HOME=${HADOOP_HOME} mapreduce.reduce.env HADOOP_MAPRED_HOME=${HADOOP_HOME} yarn-site.xml
yarn.resourcemanager.ha.enabled true yarn.resourcemanager.cluster-id Cyarn yarn.resourcemanager.ha.rm-ids rm1,rm2 yarn.resourcemanager.hostname.rm1 slave2 yarn.resourcemanager.webapp.address.rm1 slave2 yarn.resourcemanager.hostname.rm2 slave3 yarn.resourcemanager.webapp.address.rm2 slave3 yarn.resourcemanager.zk-address master:2181,slave1:2181,slave2:2181,slave3:2181 yarn.nodemanager.aux-services mapreduce_shuffle yarn.log-aggregation-enable true yarn.log-aggregation.retain-seconds 86400 yarn.resourcemanager.recovery.enabled true yarn.resourcemanager.store.class org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore workers注意!在Hadoop3x以前的版本是 slaves 文件
masterslave1slave2slave3使用 scp 分發(fā)給其他節(jié)點(diǎn)
scp -r /usr/local/hadoop slave1:/usr/local/請自行枚舉執(zhí)行
使用之前的 zk 腳本啟動 zeekeeper 集群
zk start分別在每個 journalnode 節(jié)點(diǎn)上啟動 journalnode 進(jìn)程
# master slave1 slave2hadoop-daemon.sh start journalnode在第一個 namenode 節(jié)點(diǎn)上格式化文件系統(tǒng)
hadoop namenode -format同步兩個 namenode 的元數(shù)據(jù)
查看你配置的 hadoop.tmp.dir 這個配置信息,得到 hadoop 工作的目錄,我的是/hadoop/hadoopdata/
把 master 上的 hadoopdata 目錄發(fā)送給 slave1 的相同路徑下,這一步是為了同步兩個 namenode 的元數(shù)據(jù)
scp -r /hadoop/hadoopdata slave1:/hadoop/也可以在 slave1 執(zhí)行以下命令:
hadoop namenode -bootstrapStandby格式化 ZKFC(任選一個 namenode 節(jié)點(diǎn)格式化)
hdfs zkfc -formatZK啟動 hadoop 集群
start-all.sh相關(guān)命令請前往 $HADOOP_HOME/sbin/ 查看
啟動 mapreduce 任務(wù)歷史服務(wù)器
mr-jobhistory-daemon.sh start historyserver編寫 jps 集群腳本
vim /bin/jpall && chmod 777 /bin/jpall#! /bin/sh echo -e "/e[32m---------------------------------------------------------------------------/033[0m" echo -e "/e[32m...master-jps.../033[0m" ssh master "jps" echo -e "/e[32m...slave1-jps.../033[0m" ssh slave1 "jps" echo -e "/e[32m...slave2-jps.../033[0m" ssh slave2 "jps" echo -e "/e[32m...slave3-jps.../033[0m" ssh slave3 "jps" echo -e "/e[32m...all-jps-end.../033[0m" echo -e "/e[32m---------------------------------------------------------------------------/033[0m"運(yùn)行
jpall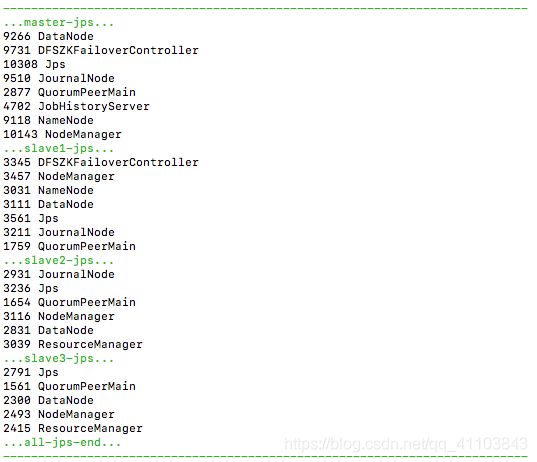
查看各節(jié)點(diǎn)的主備狀態(tài)
hdfs haadmin -getServiceState nn1查看 HDFS 狀態(tài)
hdfs dfsadmin -reportWEB 訪問可以直接瀏覽器: IP:50070
上傳一個文件
hdfs dfs -put test.outcheck
hdfs dfs -ls /user/root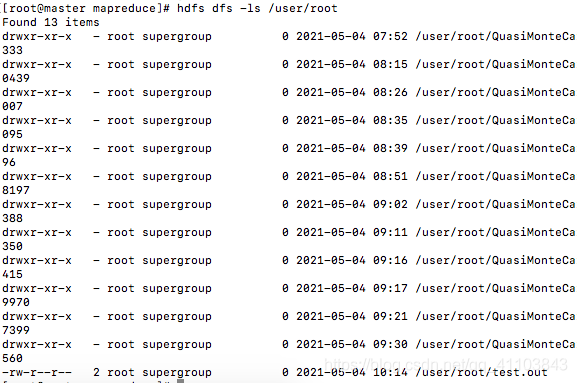
hadoop fs -rm -r -skipTrash /user/root/test.out刪除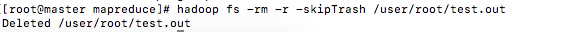
我們使用 hadoop 自帶的圓周率測試
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar pi 5 5運(yùn)行結(jié)果
查看進(jìn)程
jps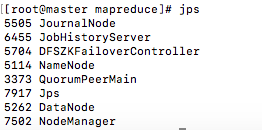
殺死進(jìn)程
kill -9 5114現(xiàn)在 master 已不是 namenode 了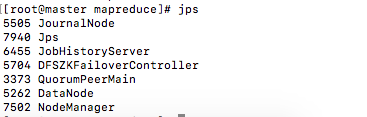
現(xiàn)在 slave1 變成了主節(jié)點(diǎn)
恢復(fù) master 節(jié)點(diǎn)
hadoop-daemon.sh start namenode
master 變成了 standby,什么 HA 具備
刪除所有節(jié)點(diǎn)中 hadoop 的工作目錄(core-site.xml 中配置的 hadoop.tmp.dir 那個目錄)
如果你在 core-site.xml 中還配置了 dfs.datanode.data.dir 和 dfs.datanode.name.dir 這兩個配置,那么把這兩個配置對應(yīng)的目錄也刪除
刪除所有節(jié)點(diǎn)中 hadoop 的 log 日志文件,默認(rèn)在 HADOOP_HOME/logs 目錄下
刪除 zookeeper 集群中所關(guān)于 hadoop 的 znode 節(jié)點(diǎn)
圖中的紅色框中 rmstore 這個節(jié)點(diǎn)不能刪除,刪除另外兩個就可以
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://specialneedsforspecialkids.com/yun/123650.html

閱讀 713·2023-04-25 19:43
閱讀 3910·2021-11-30 14:52
閱讀 3784·2021-11-30 14:52
閱讀 3852·2021-11-29 11:00
閱讀 3783·2021-11-29 11:00
閱讀 3869·2021-11-29 11:00
閱讀 3557·2021-11-29 11:00
閱讀 6105·2021-11-29 11:00