資訊專欄INFORMATION COLUMN

摘要:此處補充說明下,不論是還是都不提供指定區間的刷盤策略,只提供一個方法,所以無法精確控制落盤數據的大小。
由前文可知,RocketMQ有幾個非常重要的概念:
既然是消息隊列,那消息的存儲的重要程度不言而喻,本節我們聚焦broker服務端,看下消息在broker端是如何存儲的,它的落盤策略是怎樣的,又是如何保證高效
另:后文的RocketMQ都是基于版本4.9.3
RocketMQ的普通單消息寫入流程如下
簡單可以分為三大塊:
其實消息的寫入準備工作也比較好理解,主要是消息狀態的檢查以及各類存儲狀態的檢查,可以參看上圖中的流程
根據上圖,在準備階段前,RocketMQ會判斷操作系統的Page Cache是否繁忙,他是怎么做到的呢?其實Java本身沒有提供接口或函數來查看Page Cache的狀態,但如果磁盤帶寬已經打滿,在Page Cache要將數據刷disk時,很有可能便陷入了阻塞,導致Page Cache資源緊張。而當我們的程序又有新的消息要寫入Page Cache時,反向阻塞寫入請求,我們說這時Page Cache就產生了回壓,也就是Page Cache相當繁忙,請求已經不能及時處理了。RocketMQ判斷Page Cache是否繁忙的條件也很簡單,就是監控某個請求加鎖后,寫入是否超過1秒,如果超時的話,新的請求會快速失敗
RocketMQ有一套相對復雜的消息協議編碼,大部分協議中的內容都是在加鎖前拼接生成
大部分消息協議項都是定長字段,變長字段如下:
此處rmq提供了2種加鎖方式
無論采用哪種策略,都是獨占鎖,即同一時刻只允許一個線程加鎖成功。具體采用哪種方式,可通過配置修改。
兩種加鎖適用不同的場景,方式1在高并發場景下,能保持平穩的系統性能,但在低并發下表現一般;而方式二正好相反,在高并發場景下,因為采用自旋,會浪費大量的cpu,但在低并發時,卻可以獲得很高的性能。
所以官方文檔中,為了提高性能,建議用戶在同步刷盤的時候采用獨占鎖,異步刷盤的時候采用自旋鎖。這個是根據加鎖時間長短決定的
上文提到,寫入消息的鎖是獨占鎖,也就意味著同一時刻,只能有一個線程進入,我們看一下鎖內都做了哪些操作
MappedFile文件的開辟是異步進行,有獨立的線程專門負責開辟文件。我們可以先看下文件開辟的簡單模型
也就是putMsg的線程會將開辟文件的請求委托給allocate file線程,然后進入阻塞,待allocate file線程將文件開辟完畢后,再喚醒putMsg線程
那此處我們便產生了2點疑問:
FileChannnel還是MappedByteBuffer,都是一件很快的操作,費盡周章的異步開辟真的有必要嗎?這兩個疑問將逐步說明
至此我們要引入一個非常重要的配置變量transientStorePoolEnable,該配置項只在異步刷盤(FlushDiskType == AsyncFlush)的場景下,才會生效
如果配置項中,將transientStorePoolEnable置為false,便稱為“開啟堆外緩沖池”。那么這個變量到底起到什么作用呢?

系統啟動時,會默認開辟5個(參數transientStorePoolSize控制)堆外內存DirectByteBuffer,循環利用。寫消息時,消息都暫存至此,通過線程CommitRealTimeService將數據定時刷到page cache,當數據flush到disk后,再將DirectByteBuffer歸還給緩沖池
而開辟過程是在broker啟動時進行的;如上圖所示,空間一旦開辟完畢后,文件都是預先創建好的,使用時直接返回文件引用即可,相當高效。但首次啟動需要大量開辟堆外內存空間,會拉長broker的啟動時長。我們看一下這塊開辟的源碼
/** * Its a heavy init method. */public void init() { for (int i = 0; i < poolSize; i++) { ByteBuffer byteBuffer = ByteBuffer.allocateDirect(fileSize); ...... availableBuffers.offer(byteBuffer); }}注釋中也標識了這是個重量級的方法,主要耗時點在ByteBuffer.allocateDirect(fileSize),其實開辟內存并不耗時,耗時集中在為內存區域賦0操作,以下是JDK中DirectByteBuffer源碼:
DirectByteBuffer(int cap) { // package-private super(-1, 0, cap, cap); ...... long base = 0; try { base = unsafe.allocateMemory(size); } catch (OutOfMemoryError x) { Bits.unreserveMemory(size, cap); throw x; } unsafe.setMemory(base, size, (byte) 0); ......}我們發現在開辟完內存后,開始執行了賦0操作unsafe.setMemory(base, size, 0)。其實可以利用反射巧妙地繞過這個耗時點
private static Field addr;private static Field capacity;static { try { addr = Buffer.class.getDeclaredField("address"); addr.setAccessible(true); capacity = Buffer.class.getDeclaredField("capacity"); capacity.setAccessible(true); } catch (NoSuchFieldException e) { e.printStackTrace(); }}public static ByteBuffer newFastByteBuffer(int cap) { long address = unsafe.allocateMemory(cap); ByteBuffer bb = ByteBuffer.allocateDirect(0).order(ByteOrder.nativeOrder()); try { addr.setLong(bb, address); capacity.setInt(bb, cap); } catch (IllegalAccessException e) { return null; } bb.clear(); return bb;}關閉堆外內存池的話,就會啟動MappedByteBuffer

我們再回顧一下本章剛開始提出的2個疑問:
FileChannnel還是MappedByteBuffer,都是一件很快的操作,費盡周章的異步開辟真的有必要嗎?第一個問題已經迎刃而解,即allocate線程通過異步創建下一個文件的方式,實現真正異步
本節討論的便是第二個問題,其實如果只是單純創建文件的話,的確是非常快的,不至于再使用異步操作。但RocketMQ對于新建文件有個文件預熱(通過配置warmMapedFileEnable啟停)功能,當然目的是為了磁盤提速,我么先看下源碼
org.apache.rocketmq.store.MappedFile#warmMappedFile
for (int i = 0, j = 0; i < this.fileSize; i += MappedFile.OS_PAGE_SIZE, j++) { byteBuffer.put(i, (byte) 0); // force flush when flush disk type is sync if (type == FlushDiskType.SYNC_FLUSH) { if ((i / OS_PAGE_SIZE) - (flush / OS_PAGE_SIZE) >= pages) { flush = i; mappedByteBuffer.force(); } }}簡單來說,就是將MappedByteBuffer每隔4K就寫入一個0 byte,然后將整個文件撐滿;如果刷盤策略是同步刷盤的話,還需要調用mappedByteBuffer.force(),當然這個操作是相當相當耗時的,所以也就需要我們進行異步處理。這樣也就解釋了第二個問題
但文件預熱真的有效嗎?我們不妨做個簡單的基準測試
public class FileWriteCompare { private static String filePath = "/Users/likangning/test/index3.data"; private static int fileSize = 1024 * 1024 * 1024; private static boolean warmFile = true; private static int batchSize = 4096; @Test public void test() throws Exception { File file = new File(filePath); if (file.exists()) { file.delete(); } file.createNewFile(); FileChannel fileChannel = FileChannel.open(file.toPath(), StandardOpenOption.WRITE, StandardOpenOption.READ); MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, fileSize); ByteBuffer byteBuffer = ByteBuffer.allocateDirect(batchSize); long beginTime = System.currentTimeMillis(); mappedByteBuffer.position(0); while (mappedByteBuffer.remaining() >= batchSize) { byteBuffer.position(batchSize); byteBuffer.flip(); mappedByteBuffer.put(byteBuffer); } System.out.println("time cost is : " + (System.currentTimeMillis() - beginTime)); }}簡單來說就是通過MappedByteBuffer寫入1G文件,在我本地電腦上,平均耗時在 550ms 左右
然后在MappedByteBuffer寫文件前加入預熱操作
private void warmFile(MappedByteBuffer mappedByteBuffer) { if (!warmFile) { return; } int pageSize = 4096; long begin = System.currentTimeMillis(); for (int i = 0, j = 0; i < fileSize; i += pageSize, j++) { mappedByteBuffer.put(i, (byte) 0); } System.out.println("warm file time cost " + (System.currentTimeMillis() - begin));}耗時情況如下:
warm file time cost 492time cost is : 125預熱后,寫文件的耗時縮短了很多,但預熱本身的耗時也幾乎等同于文件寫入的耗時了
以上是沒有強制刷盤的測試效果,如果強制刷盤(#force)的話,個人經驗是文件預熱一定會帶來性能的提升。從前兩天結束的第二屆中間件性能挑戰賽來看,文件預熱至少帶來10%以上的提升。但是同非強制刷盤一樣,文件預熱操作實在是太重了
整體來看,文件預熱后的寫入操作,確實能帶來性能上的提升,但是如果在系統壓力較大、磁盤吞吐緊張的場景下,勢必導致broker抖動,甚至請求超時,反而得不償失。明白了此層概念后,再通過大量benchmark來決定是否開啟此配置,做到有的放矢
經過以上整理分析后,文件寫入將變得非常輕;不論是DirectByteBuffer還是MappedByteBuffer都可以抽象為ByteBuffer,進而直接調用ByteBuffer.write()

對應如下配置
FlushDiskType == AsyncFlush && transientStorePoolEnable == false異步刷盤,且關閉緩沖池,對應的異步刷盤線程是FlushRealTimeService
上文可知,次策略是通過MappedByteBuffer寫入的數據,所以此時數據已經在 page cache 中了
我們總結一下刷盤的策略:
不響應中斷,固定500ms(可配置)刷盤,但刷盤的時候,如果發現未落盤數據不足16K(可配置),那么將進入下一個循環,如果滿16K的話,會將所有未落盤的數據落盤。此處補充說明下,不論是FileChannel還是MappedByteBuffer都不提供指定區間的刷盤策略,只提供一個force()方法,所以無法精確控制落盤數據的大小。
如果數據寫入量很少,一直沒有填充滿16K,就不會落盤了嗎?不是的,此處兜底的方案是,線程發現距離上次無條件全量刷盤已經超過10000ms(可配置),那么此時就會無條件觸發全量刷盤
與「固定頻率刷盤」比較相似,唯一不同點是,當前刷盤策略是響應中斷的,即每次有新的消息到來的時候,都會發送喚醒信號,如果刷盤線程正好處在500ms等待期間的話,將被喚醒。但此處的喚醒并非嚴謹的喚醒,有可能發送了喚醒信號,但刷盤線程并未成功響應,兜底方案便是500ms的重試。下面簡單黏貼一下等待、喚醒的代碼,不再贅述
org.apache.rocketmq.common.ServiceThread
// 喚醒public void wakeup() { if (hasNotified.compareAndSet(false, true)) { waitPoint.countDown(); // notify }}// 睡眠并響應喚醒protected void waitForRunning(long interval) { if (hasNotified.compareAndSet(true, false)) { this.onWaitEnd(); return; } //entry to wait waitPoint.reset(); try { waitPoint.await(interval, TimeUnit.MILLISECONDS); } catch (InterruptedException e) { log.error("Interrupted", e); } finally { hasNotified.set(false); this.onWaitEnd(); }}綜上,數據在page cache中最長的等待時間為(10000+500)ms
對應如下配置
FlushDiskType == AsyncFlush && transientStorePoolEnable == true異步刷盤,且開啟緩沖池,對應的異步刷盤線程是CommitRealTimeService
首先需要明確一點的是,當前配置下,在寫入階段,數據是直接寫入DirectByteBuffer的,這樣做的好處及弊端也非常鮮明。
DirectByteBuffer后便很快返回,減少了用戶態與內核態的切換開銷,性能非常高值得一提的是,此種刷盤模式,寫入動作使用的是FileChannel,且僅僅調用FileChannel.write()方法將數據寫入page cache,并沒有直接強制刷盤,而是將強制落盤的任務轉交給FlushRealTimeService線程來操作,而FlushRealTimeService線程最終也會調用FileChannel進行強制刷盤
在RocketMQ內部,無論采用什么刷盤策略,都是單一操作對象在寫入/讀取文件;即如果使用MappedByteBuffer寫文件,那一定會通過MappedByteBuffer刷盤,如果使用FileChannel寫文件,那一定會通過FileChannel 刷盤,不存在混合操作的情況
疑問:為什么RocketMQ不依賴操作系統的異步刷盤,而費勁周章的設計如此刷盤策略呢?
個人理解,作為一個成熟開源的組件,數據的安全性至關重要,還是要盡可能保證數據穩步有序落盤;OS的異步刷盤固然好使,但RocketMQ對其把控較弱,當操作系統crash或者斷電的時候,造成的數據丟失影響不可控
需要說明的是,如果FlushDiskType配置的是同步刷盤的話,那么此處數據一定已經被MappedByteBuffer寫入了pageCache,接下來要做的便是真正的落盤操作。與異步落盤相似,同步落盤要根據配置項Message.isWaitStoreMsgOK()(等待消息落盤)來分別說明
同步刷盤的落盤線程統一都是GroupCommitService

當前模式如圖所示,整體流程比較簡單,寫入線程僅僅負責喚醒落盤線程,然后便執行后續邏輯,線程不阻塞;落盤線程每次休息10ms(可被寫入線程喚醒)后,如果發現有數據未落盤,便將page cache中的數據強制force到磁盤
我們發現,其實相比較異步刷盤來說,同步刷盤輪訓的時間只有10ms,遠小于異步刷盤的500ms,也是比較好理解的。但當前模式寫入線程不會阻塞,也就是不會等待消息真正存儲到disk后再返回,如果此時反生操作系統crash或者斷電,那未落盤的數據便會丟失
個人感覺,將FlushDiskType已經設置為Sync,表明數據會強制落盤,卻又引入Message.isWaitStoreMsgOK(),來左右落盤策略,多多少少會給使用者造成使用及理解上的困惑
相比較上文,本小節便是數據需要真正存儲到disk后才進行返回。寫入線程在喚醒落盤線程后便進入阻塞,直至落盤線程將數據刷到disk后再將其喚醒
不過這里需要處理一個邊界問題,即舊CommitLog的tail,及新CommitLog的head。例如現在有2個寫入線程將數據寫入了page cache,而這2個請求一個落在前CommitLog的尾部,另外一個落在新CommitLog的頭部,這個時候,落盤線程需要檢測到這兩個消息的分布,然后依次將兩個CommitLog數據落盤
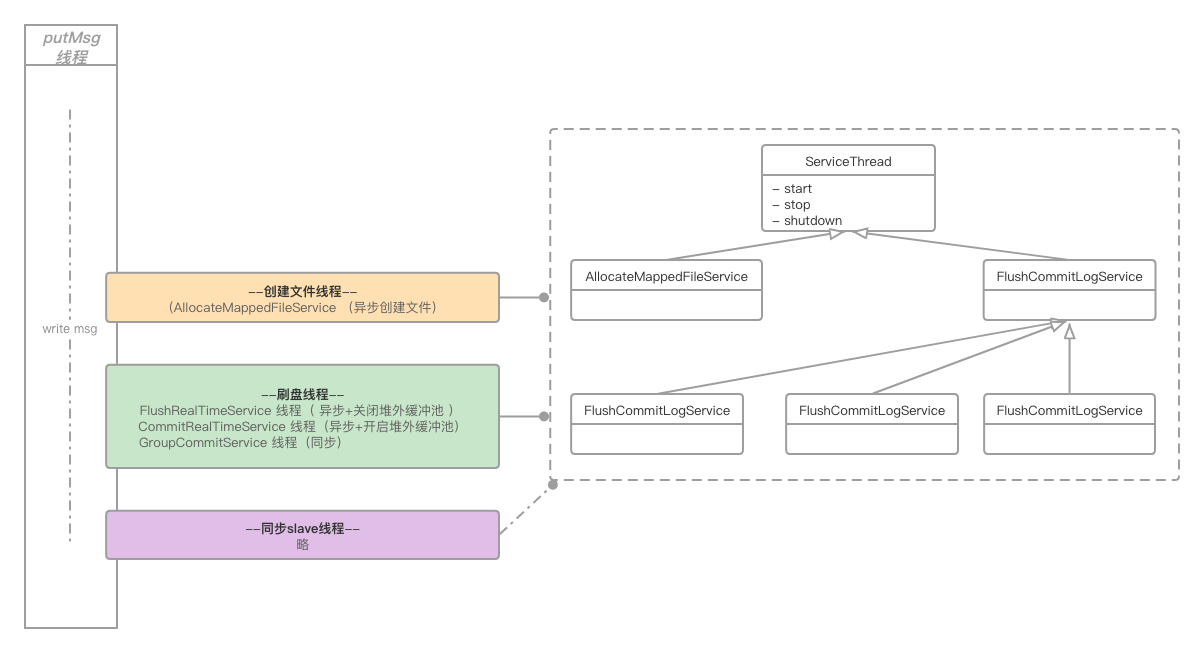
RocketMQ中所有的異步處理線程都繼承自抽象類org.apache.rocketmq.common.ServiceThread,此類定義了簡單的喚醒、通知模型,但并不嚴格保證喚醒,而是通過輪訓作為兜底方案。實測發現喚醒動作在數據量較大時,存在性能損耗,改為簡單的輪詢落盤模式,性能提高明顯
本章我們聚焦分析了一條消息在broker端落地的全過程,但整個流程還是比較復雜的,不過有些部分沒有提及(比如說消息在master落地后是如何同步至salve端的),主要是考慮這些部分跟存儲關聯度不是很強,放在一起思路容易發散,這些部分會放在后文專門開標題闡述
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://specialneedsforspecialkids.com/yun/123639.html
摘要:它是阿里巴巴于年開源的第三代分布式消息中間件。是一個分布式消息中間件,具有低延遲高性能和可靠性萬億級別的容量和靈活的可擴展性,它是阿里巴巴于年開源的第三代分布式消息中間件。上篇文章消息隊列那么多,為什么建議深入了解下RabbitMQ?我們講到了消息隊列的發展史:并且詳細介紹了RabbitMQ,其功能也是挺強大的,那么,為啥又要搞一個RocketMQ出來呢?是重復造輪子嗎?本文我們就帶大家來詳...
摘要:主流消息中間件介紹是由出品,是一個完全支持和規范的實現。主流消息中間件介紹是阿里開源的消息中間件,目前也已經孵化為頂級項目。 showImg(https://img-blog.csdnimg.cn/20190509221741422.gif);showImg(https://img-blog.csdnimg.cn/20190718204938932.png?x-oss-process=...
摘要:故事中的下屬們,就是消息生產者角色,屋子右面墻根那塊地就是消息持久化,呂秀才就是消息調度中心,而你就是消息消費者角色。下屬們匯報的消息,應該疊放在哪里,這個消息又應該在哪里才能找到,全靠呂秀才的驚人記憶力,才可以讓消息準確的被投放以及消費。 微信公眾號:IT一刻鐘大型現實非嚴肅主義現場一刻鐘與你分享優質技術架構與見聞,做一個有劇情的程序員關注可了解更多精彩內容。問題或建議,請公眾號留言...
摘要:故事中的下屬們,就是消息生產者角色,屋子右面墻根那塊地就是消息持久化,呂秀才就是消息調度中心,而你就是消息消費者角色。下屬們匯報的消息,應該疊放在哪里,這個消息又應該在哪里才能找到,全靠呂秀才的驚人記憶力,才可以讓消息準確的被投放以及消費。 微信公眾號:IT一刻鐘大型現實非嚴肅主義現場一刻鐘與你分享優質技術架構與見聞,做一個有劇情的程序員關注可了解更多精彩內容。問題或建議,請公眾號留言...

閱讀 713·2023-04-25 19:43
閱讀 3910·2021-11-30 14:52
閱讀 3784·2021-11-30 14:52
閱讀 3852·2021-11-29 11:00
閱讀 3783·2021-11-29 11:00
閱讀 3869·2021-11-29 11:00
閱讀 3557·2021-11-29 11:00
閱讀 6105·2021-11-29 11:00





